拟某款抽卡手游的6月份封测报告
原创拟某款抽卡手游的6月份封测报告
原创
数据准备
数据由python生成带有特征的数据提供使用:
- 表一、包括用户的基本信息:
usr_info_list :
包括用户名uid、 手机号phone 、所在城市city、 性别gender、 年龄age、 游戏内的等级levels、 月度消费usr_amount 、以及用户最常用的3种社区forums
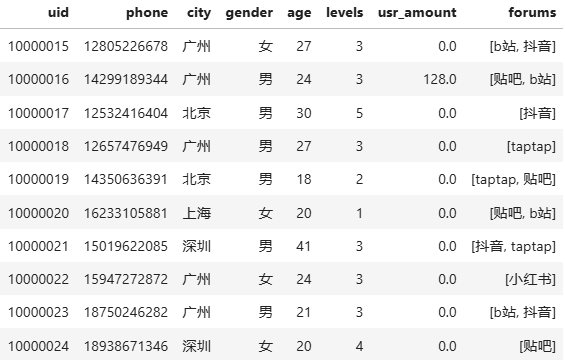
这些字段由以下基本特征
phone:生成125~195开头的11位号码
city:生成北上广深4坐城市
age:年龄在8~100区间
gender:男女比例 7:3
levels:游戏账号等级1~5
usr_amount: 用户月度总消费
forums: 每人最多在里面选择常用的3种流媒体社区 : ['b站','抖音','贴吧','taptap','虎扑',"微博",'小红书']
部分数据生成代码:
# 时间权值
ll=pd.Series(date_list).dt.dayofweek
week_val=ll.values # 星期几
week_index=ll.index.values # 对应位置
for indx,val in zip(week_index,week_val):
if val in(6,5,4):
rights[indx]=(np.random.choice([1,2,3,4,5],1,p=[0.1,0.3,0.3,0.2,0.1]))
target_index=np.argwhere((date_list>=ver_date_start) & (date_list<=ver_date_end))
# 各段年龄段的权值
rights=np.concatenate([right1,right2,right3,right4,right5,right6])
rights=rights/sum(rights)
age_list=np.random.choice(range(8,101),len(amount_list),p=rights)
# ……其他字段类似
```- 表二、 详细消费信息表:
tb_detail_cos
用户uid、单笔消费金额detail_comsume 、发生消费的时间datetime_comsume
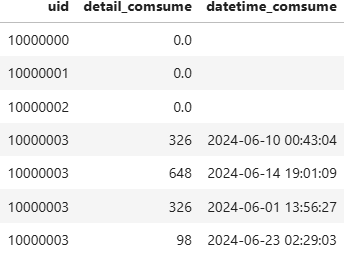
detail_comsume与datetime_comsume记录的是每次发生交易的金额与时间
detail_comsume :每个用户随机消费 消费金额为固定的30,68,98,128,326,648这几个档次
datetime_comsume:时间为整个6月份,其中版本更新的日期为2024-06-14~2024-06-20
部分数据生成代码:
# 抽卡行为权值
# gacha 用户抽取次数应符合正态分布
# mean用户平均抽取
pay_usr_num=usr_cnt-int(usr_cnt*free_usr_rate) # 付费用户数
# 按照标准正态分布的模板 mean=0 std=1
scaled_normal = np.random.normal(0, 1, pay_usr_num)
# 缩放和平移这个分布到标准分布的期望的范围
mean=mean_times # mean_times 平均抽取次数 std_dev 标准差
gacha = mean*10 + std_dev * scaled_normal # 避免出现负数先放大10倍
gacha=gacha/10 # 还原原来大小
gacha = [max(x,1) for x in gacha] # 付费用户至少1次消费
gacha = np.round(gacha).astype(int)- 表三、用户状态表原表:
- 表四、用户状态表增量表:
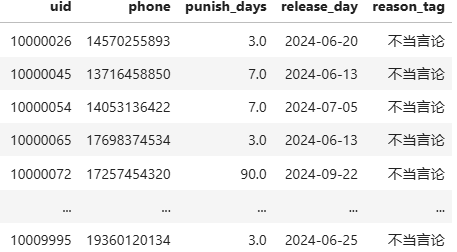
最后一张表存放新增与更新的用户信息字段内容与表三一致
包括用户名uid、 手机号phone、封禁时长、解封日期、封禁原因
封禁时长:3天、7天、90天、360天、3600天
禁封理由:不当言论、使用游戏漏洞、使用第三方插件、非法账号
完整数据生成
# 由表tb_detail_cos的uid字段和datetime_comsume字段为入参生成表格
# 生成 4.5%的封号人员
# 为了避免与事实表冲突,封禁期间内产生了交易,设置解封日期都在充值日期之后
# 封号天数会根据封禁理由产生权值变化:
def usr_status(mnt,df,df_uid,df_datetime):
tags={'不当言论':{3:20,7:10,90:2,360:0,360*10:0},
'使用游戏漏洞谋益':{3:0,7:20,90:10,360:5,360*10:1},
'使用第三方插件':{3:5,7:5,90:10,360:20,360*10:2},
'非法账号':{3:0,7:0,90:0,360:10,360*10:20}}
# 各tag权值
tags_right=[20,2,8,1]
tags_right=[right/sum(tags_right) for right in tags_right]
# 被banned的tag
ban_reason=[]
re_df=df[[df_uid,df_datetime]].groupby(df_uid).max()
usr=list(re_df.index)
tmpdatetime=re_df.values.flatten()
# 封禁列表
num=len(usr)
ban_num=round(num*0.045+0.01)
idx_ban=list(np.random.choice(range(num),ban_num,replace=False))
punish_days=np.zeros(num)
for idx in range(len(tmpdatetime)):
if tmpdatetime[idx]<'1970-01-01':
if idx in idx_ban:
first_monthday=f'2024-{mnt:0>2}-01'
date_list=pd.date_range(first_monthday,pd.Timestamp(first_monthday)+pd.offsets.MonthEnd(0))
datelt=list(pd.date_range(first_monthday,pd.Timestamp(first_monthday)+pd.offsets.MonthEnd(0)))
day_random=np.random.choice(datelt).strftime('%Y-%m-%d')
# 获取tag
tag=np.random.choice(list(tags.keys()),p=tags_right)
ban_reason.append(tag)
# 处罚天数与释放日期计算
tag_right=list(tags[tag].values())
tag_right=[right/sum(tag_right) for right in tag_right]
days_ban=np.random.choice(list(tags[tag].keys()),p=tag_right)
# 修改天数与日期
punish_days[idx]=days_ban
tmpdatetime[idx]=(pd.Timestamp(day_random)+pd.DateOffset(days=int(days_ban))).strftime('%Y-%m-%d')
else:
ban_reason.append('-')
tmpdatetime[idx]='1970-01-01'
else:
if idx in idx_ban:
# 获取tag
tag=np.random.choice(list(tags.keys()),p=tags_right)
ban_reason.append(tag)
# 处罚天数权值计算
tag_right=list(tags[tag].values())
tag_right=[right/sum(tag_right) for right in tag_right]
days_ban=np.random.choice(list(tags[tag].keys()),p=tag_right)
# 计算释放日期
punish_days[idx]=days_ban
tmpdatetime[idx]=(pd.Timestamp(tmpdatetime[idx])+pd.DateOffset(days=int(days_ban))).strftime('%Y-%m-%d')
else:
tmpdatetime[idx]=pd.Timestamp(tmpdatetime[idx]).strftime('%Y-%m-%d')
ban_reason.append('-')
usr_status=pd.DataFrame({
'uid':usr,
'punish_days':punish_days,
'release_day':tmpdatetime,
'reason_tag':ban_reason
})
return usr_status最后将生成的四份数据DataFrame表格全部转换为tsv文件,并上传至HDFS
建表部分
使用以下语句生成数据库表
create table if not exists usr_info_list(
uid string,
phone string,
city string,
gender string,
age int,
levels int,
usr_amount float,
forums string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
"input.regex" = "([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t\\[([^\\t]*)\\]"
);
create table if not exists detail_usr_comsume_list(
uid string,
consume float,
usr_datetime string
)row format delimited
fields terminated by '\t';
create table if not exists usr_org_st(
uid string,
phone string,
punish_days int,
release_day date,
reason_tag string
)row format delimited
fields terminated by '\t';
create table if not exists usr_st_tb_add(
uid string,
phone string,
punish_days int,
release_day date,
reason_tag string
)
row format delimited
fields terminated by '\t';
load data inpath "hdfs://node_main:8020/user/tmp/proj4/usr_info_list.tsv" into table usr_info_list;
load data inpath "hdfs://node_main:8020/user/tmp/proj4/detail_usr_comsume_list.tsv" into table detail_usr_comsume_list;
load data inpath "hdfs://node_main:8020/user/tmp/proj4/usr_org_st.tsv" into table usr_org_st;
load data inpath "hdfs://node_main:8020/user/tmp/proj4/usr_st_tb_add.tsv" into table usr_st_tb_add;数据查询前的配置调优工作
1、确认hadoop与hive环境中堆栈的大小是否合适
hadoop-env.sh
export HADOOP_HEAPSIZE_MAX=6144
export HADOOP_HEAPSIZE_MIN=4096hive-env.sh
export HIVE_HEAPSIZE=20482、需要设置hiveserver2的高可用性与内存配置
hive-site.xml
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>3、开启动态插入与查询优化相关的配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.groupby.skewindata=true;
set hive.stats.column.autogather=false; HIVE分析部分
计算总体信息
create table general_tb as
select *,(usr_cnt-pay_cnt) as not_pay_cnt
from(
select sum(usr_amount) as GMV,
avg(usr_amount) avg_amount,
count(uid) usr_cnt,
sum(if(age>17,1,0)) as adult_cnt,
count(if(usr_amount>0,1,NULL)) as pay_cnt
from usr_info_list
)t;按日期时间分层
-- 日期
create table comsume_per_date as
select usr_date,
if(dayofweek(usr_date)=1,7,dayofweek(usr_date)-1)as week_day,
sum(consume) as day_consume
from(
select uid,consume,date(usr_datetime) as usr_date
from detail_usr_comsume_list
where consume >0
)t
group by usr_date
order by usr_date asc;
-- 时间
create table comsume_per_hour as
select hour(usr_datetime) as hour,count(*) as cnt,
round(avg(consume),1) as avg_consume,
sum(consume) as sum_consume
from detail_usr_comsume_list
where consume>0
group by hour(usr_datetime);按照性别分层
create table gender_info as
select gender,count(*),
round(avg(usr_amount),1) as avg_amount,
round(sum(usr_amount),1 )as sum_amount
from usr_info_list_PT
group by gender;按照年龄分组
create table if not exists ages_info as
select age_tag,count(uid) as usr_cnt,
round(avg(usr_amount),1) as avg_amount_per_tag,
sum(usr_amount) as sum_amount_per_tag
from(
select
case when age < 16 then '少年' when age between 16 and 21 then '青少年'
when age between 22 and 35 then '年轻工薪青年'
when age between 36 and 50 then '中年'
else '老年' end as age_tag,usr_amount,uid
from usr_info_list_PT
)t
group by age_tag;按等级分层
create table level_info as
select levels,count(*)as lv_cnt,
round(avg(usr_amount),1) as avg_amount,
sum(usr_amount) as sum_amount
from usr_info_list
group by levels;按照城市分组
select city,count(uid),sum(usr_amount) as avg_amount,round(avg(usr_amount),1) as sum_amount
,sum(if(gender='男',1,0)) as male_cnt,sum(if(gender='女',1,0)) as female_cnt
from usr_info_list_pt
group by city;按照社区分组
create table forums_info as
select parts,
sum(if(gender='男',1,0)) as male,sum(if(gender='女',1,0)) as female,
count(city) city_cnt,
round(avg(age),1) as avg_age,
round(avg(levels),1) as avg_level,
round(avg(usr_amount),1) as avg_amount,
round(sum(usr_amount),1 )as sum_amount
from usr_info_list_PT lateral view explode(split(forums," ")) fm as parts
group by parts;更新维度表
-- 更新6月份表格
create table usr_st_tb_tmp as
select a.uid,a.phone,a.punish_days,a.release_day,a.reason_tag
from usr_st_tb_add a
union
select /*+STREAMTABLE(b)*/ b.uid,
b.phone,
if(c.punish_days>0,c.punish_days,b.punish_days),
if(c.release_day>'1970-01-01',c.release_day,b.release_day),
if(c.reason_tag<>'-',c.reason_tag,b.reason_tag)
from usr_org_st b left join usr_st_tb_add c
using(uid);
-- 覆盖更新至状态表
insert overwrite table usr_st_tb
select *
from usr_st_tb_tmp可视化部分
PowerBI通过ODBC连接到HIVE的数据库
总体概况
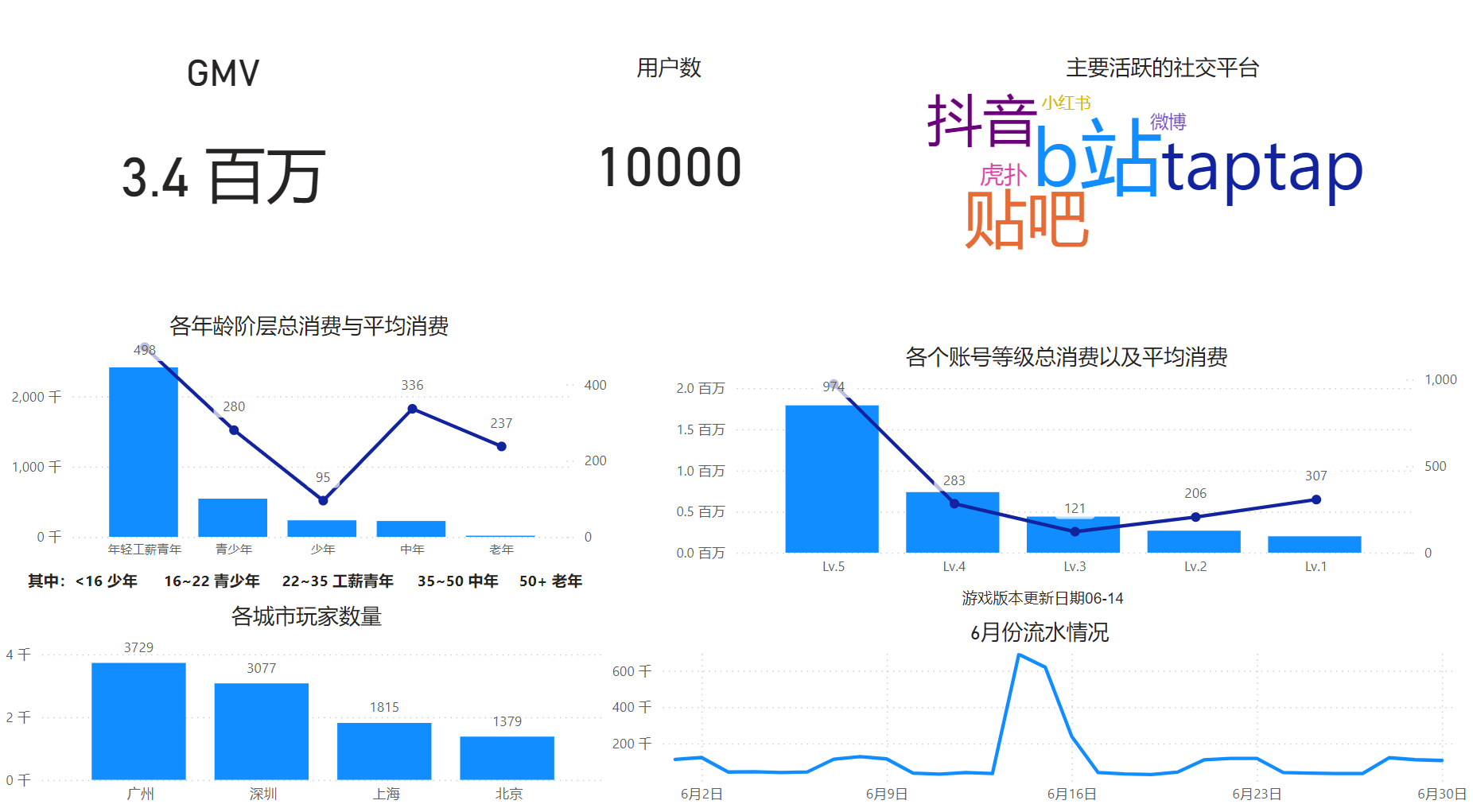
流水分析
新建度量值
更新日 = CALCULATE(sum(comsume_per_date[day_consume]),FILTER(comsume_per_date, comsume_per_date[usr_date] in {DATE(2024,06,14),DATE(2024,06,15),DATE(2024,06,16)}))
更新日之外 = CALCULATE(sum(comsume_per_date[day_consume]),FILTER(comsume_per_date,not comsume_per_date[usr_date] in {DATE(2024,06,14),DATE(2024,06,15),DATE(2024,06,16)}))
工作日消费 = CALCULATE([更新日之外],'comsume_per_date'[week_day] in {4,3,2,1})
周末消费 = CALCULATE([更新日之外],'comsume_per_date'[week_day] in {5,6,7})
add_rate = [周末消费]/[工作日消费]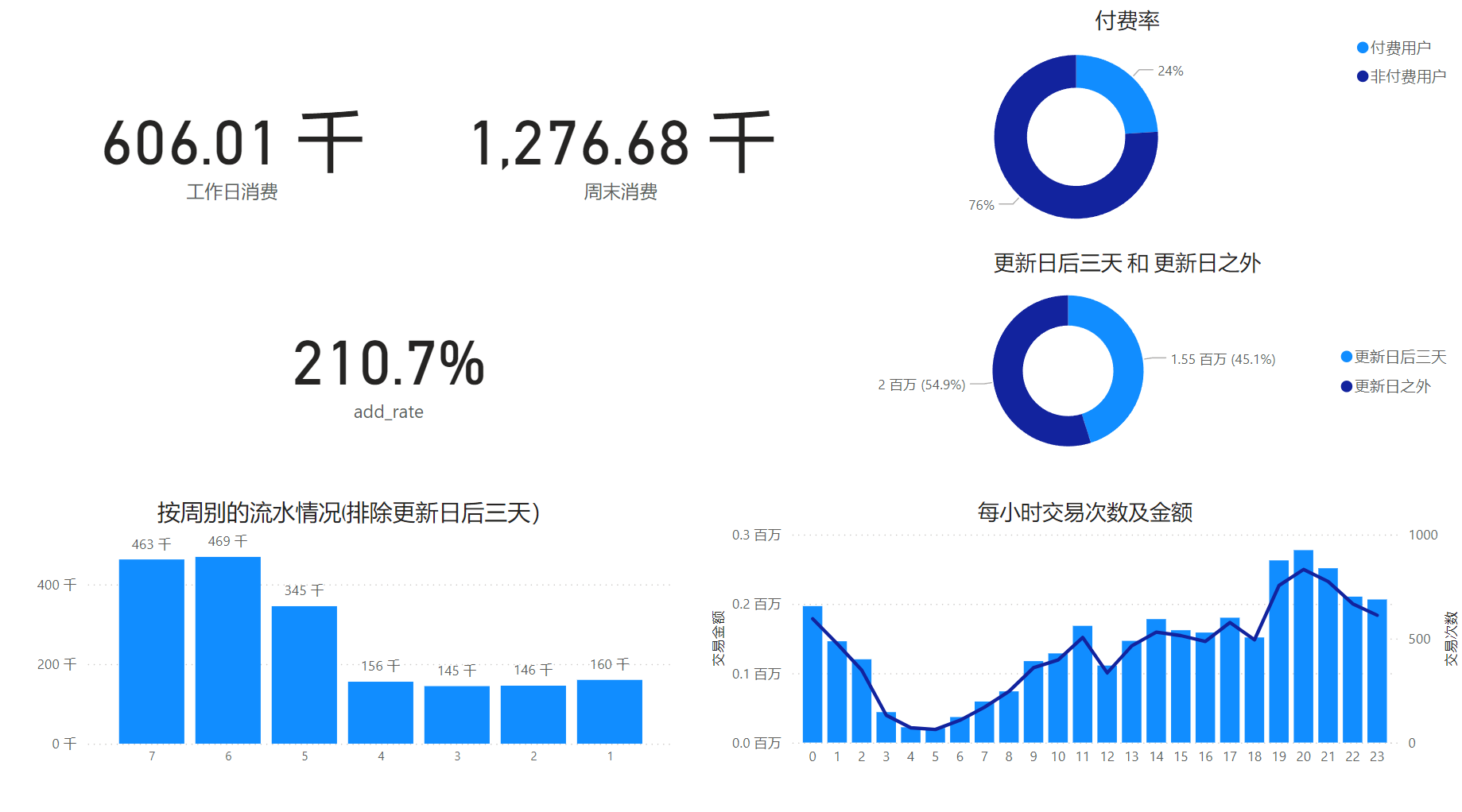
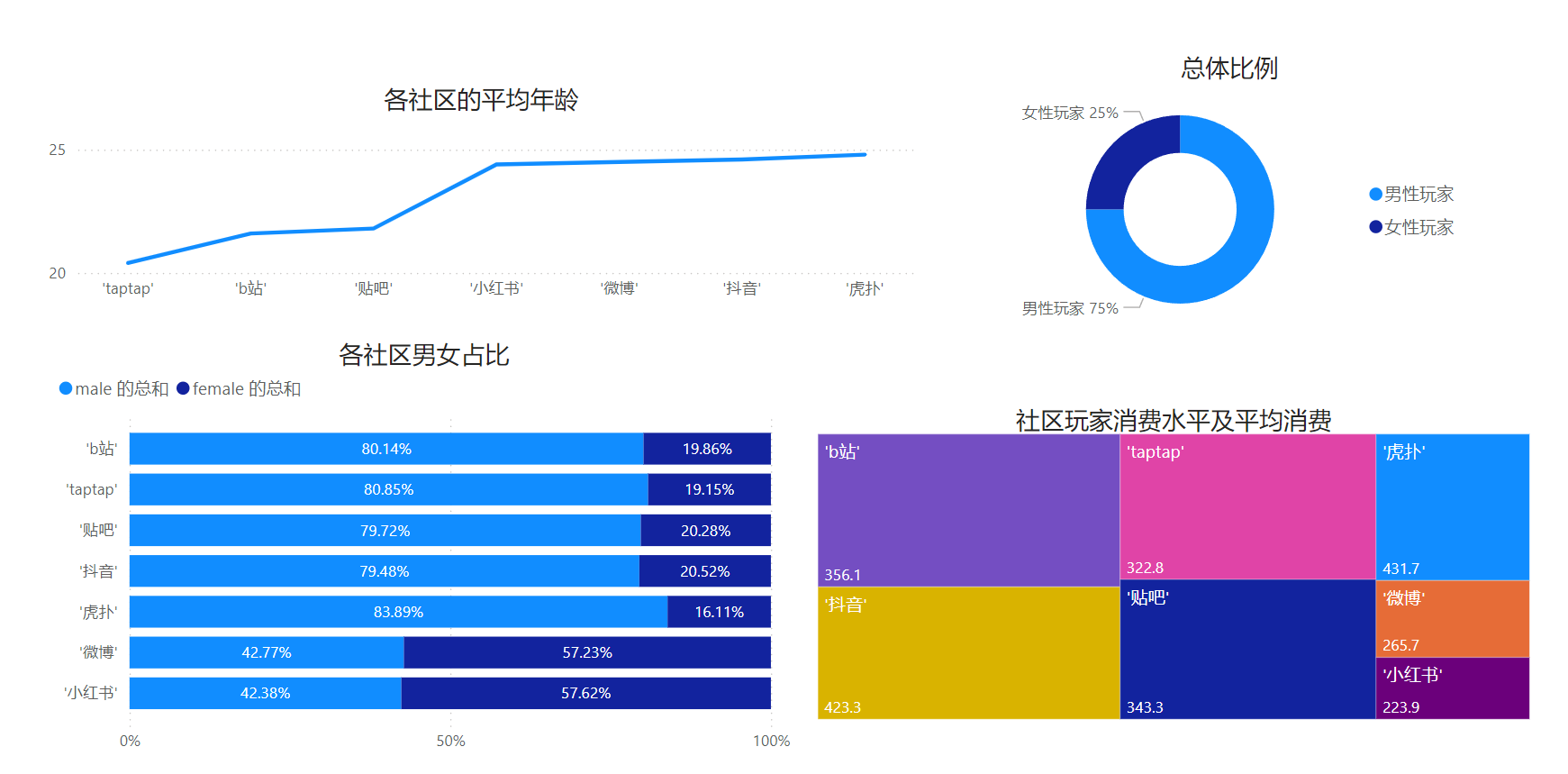
社区分析
列表更新
新建封禁比例的度量值,并筛选出封禁部分的玩家封禁原因比例
# 封禁比例
banned_rate = CALCULATE(SUM('usr_status_info'[tag_cnt]),filter(all('usr_status_info'),[reason_tag]<>"-")) /CALCULATE(sum('usr_status_info'[tag_cnt]),all('usr_status_info'))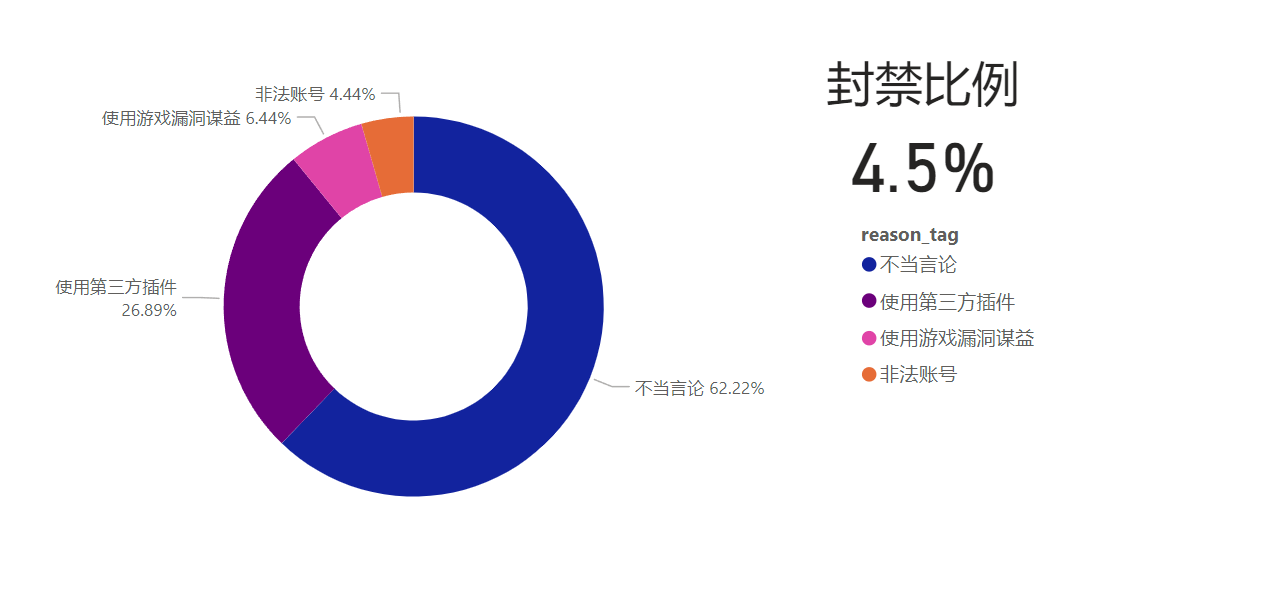
建议部分
- 宣发对象
由【图1、[各年龄阶层总消费与平均消费]】和【图二、[社区玩家消费水平与平均水平]、[各社区男女占比]】可知,核心用户为20~25岁,使用B站,taptap、贴吧、抖音流媒体社区居多的年轻男性工薪青年。
而使用虎扑的群体虽然较少,但是总体付费意愿最高也符合核心用户的年龄特征,可以加大宣传投入。
- 用户运营维护
由【图1、各账号等级消费及平均消费】,游戏内的核心消费用户以高等级lv5的用户为主,lv1~lv3消费水平最低,其中lv1的消费欲望优秀仅次于lv5,但逐级消退。建议收集新入坑玩家的意见。
- 游戏产能投放建议
版本更新后三天的流水占一个月总流水的47% ,并且周末时间的付费水平超出工作日的2倍,用户在晚上7点开始到11点的交易额达到高峰,建议版本宣发时间调整至周末,并且在晚上7点前完成游戏的更新维护工作。考虑到可能出现的BUG,建议预留时间。
- 线下运营场地选择:
广东地区玩家数较多,为了保证线下活动的活跃度可以优先考虑。
- 客服人员审核建议:
用于封号人员的申诉时资源分配建议,
可以根据封号人员四种人员占比与部门客服数量和解决问题的速度,合理分配资源。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
