【Datawhale AI 夏令营】Intel LLM Hackathon 天池挑战赛 本地环境搭建
原创【Datawhale AI 夏令营】Intel LLM Hackathon 天池挑战赛 本地环境搭建
原创
IT蜗壳-Tango
修改于 2024-07-15 23:00:55
代码可运行
修改于 2024-07-15 23:00:55
文章被收录于专栏:机器学习
运行总次数:0
代码可运行
本机环境
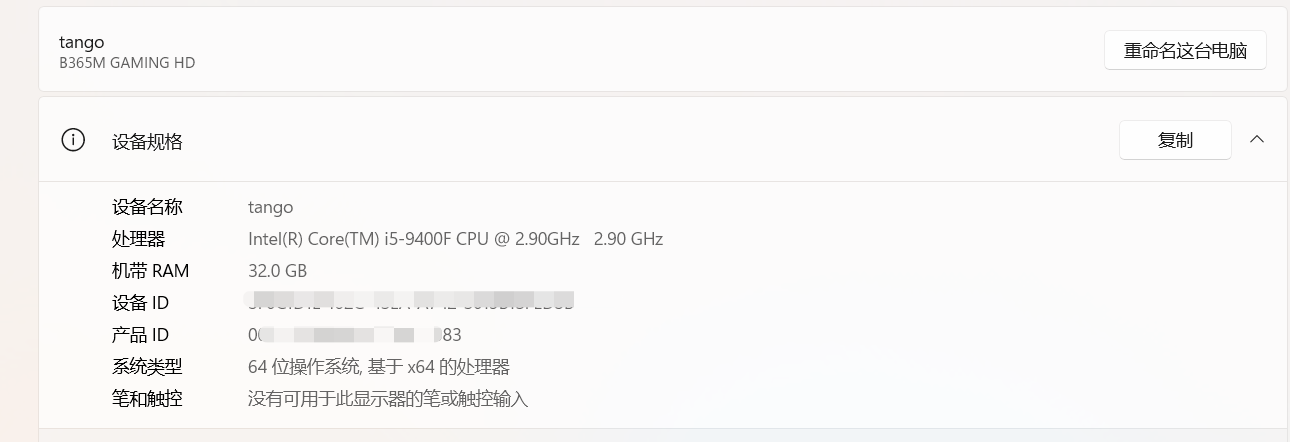
image-20240715212828302
创建本地环境
- 安装miniconda
- 安装pytorch
- jupyterlab
创建虚拟环境
conda create -n ipex_env python=3.10 -y激活虚拟环境
conda activate ipex_env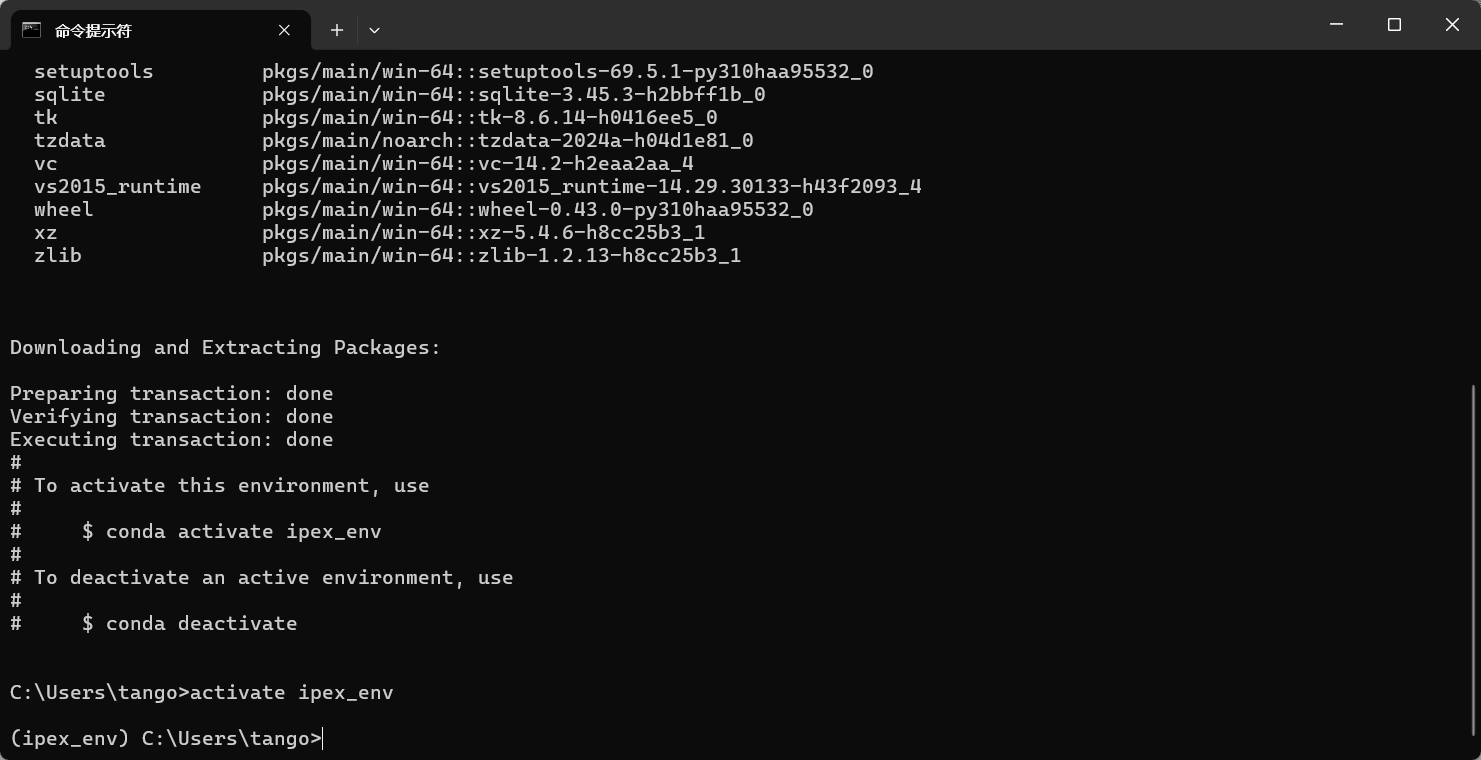
image-20240715213117093
安装pytorch
官网:PyTorch
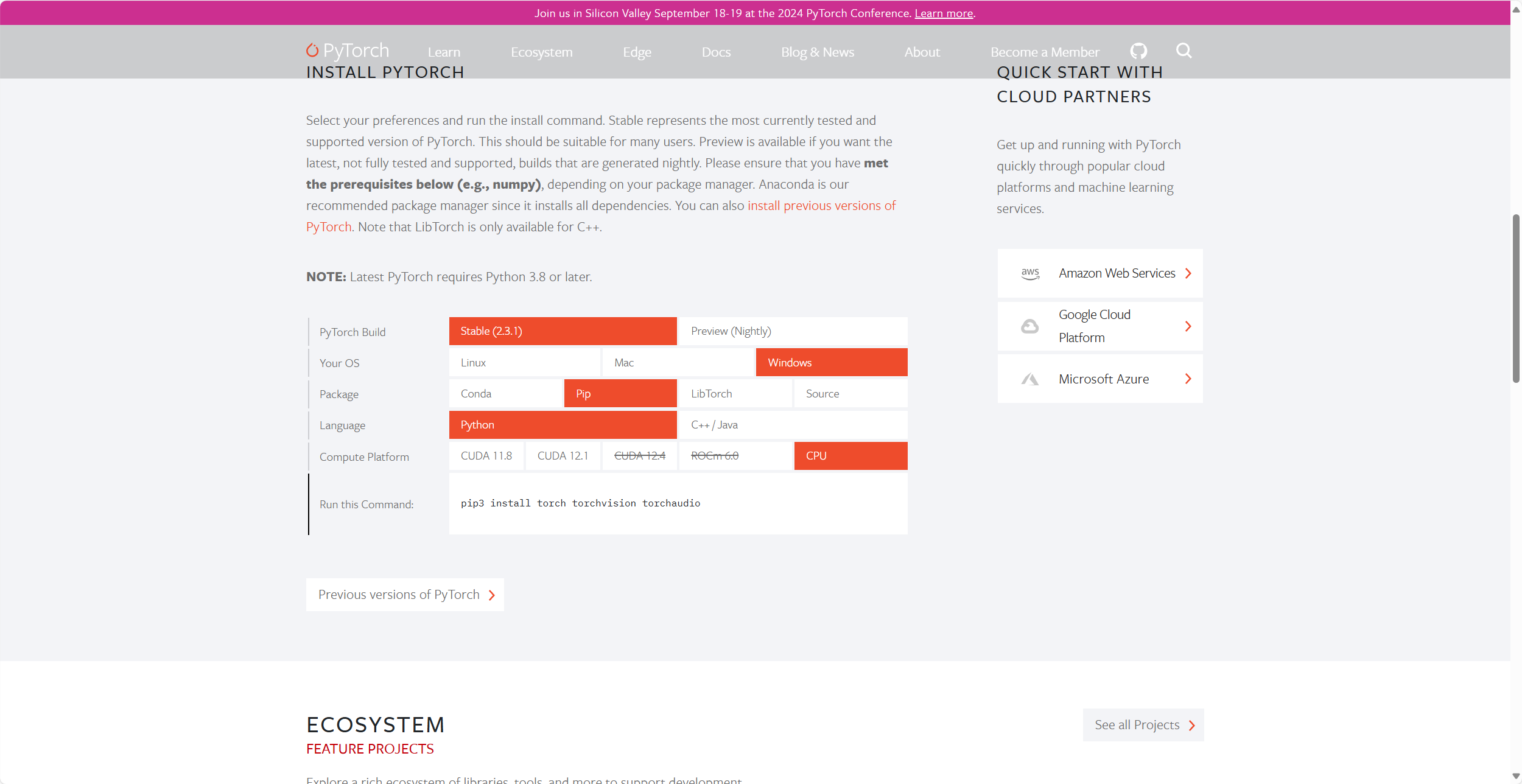
image-20240715213412711
pip3 install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple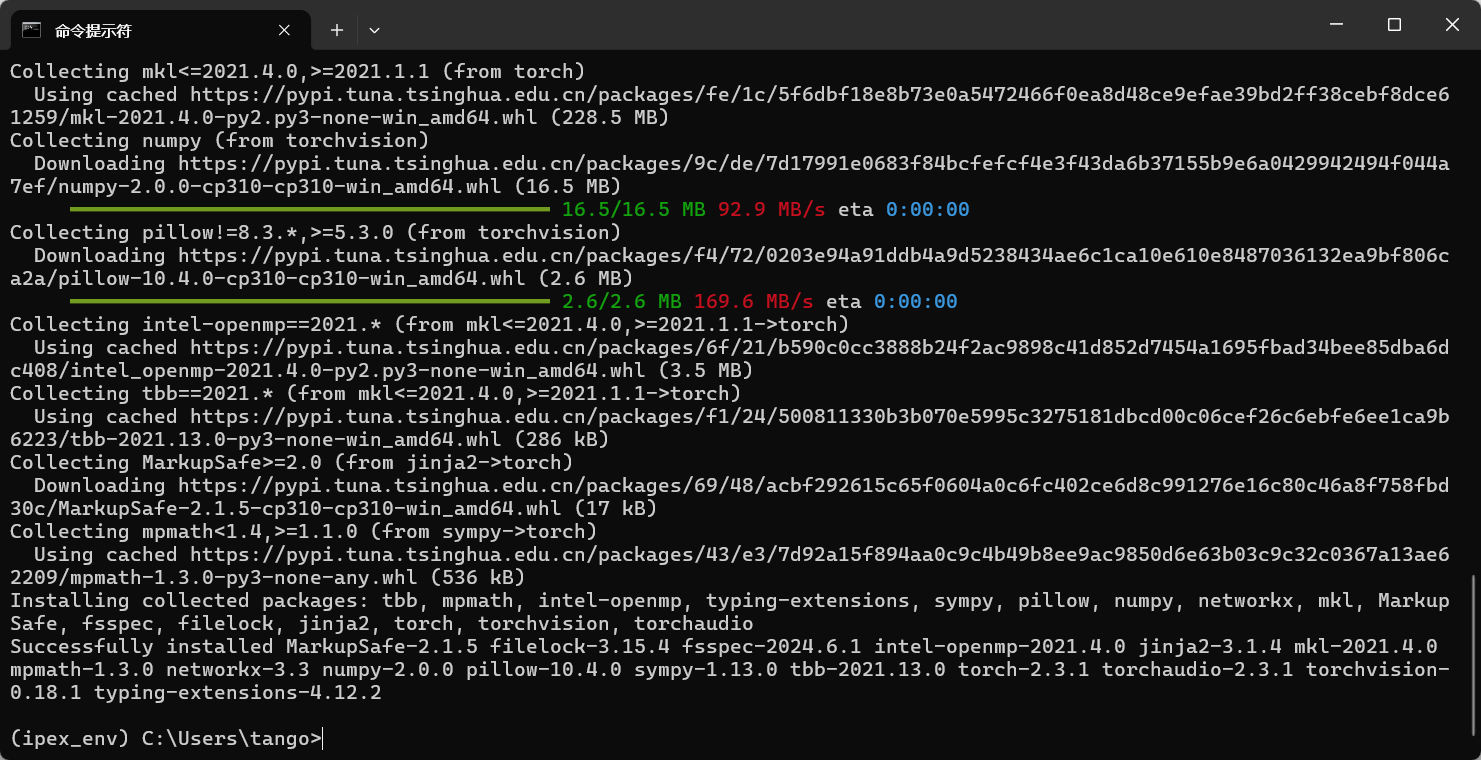
image-20240715213615043
安装如下几个第三方库
ipex-llm==2.1.0b20240711
py-cpuinfo
gradio
streamlit
modelscope==1.12.0
transformers==4.37.0
accelerate==0.27.2
jupyterlab # 可选
ipykernel # 可选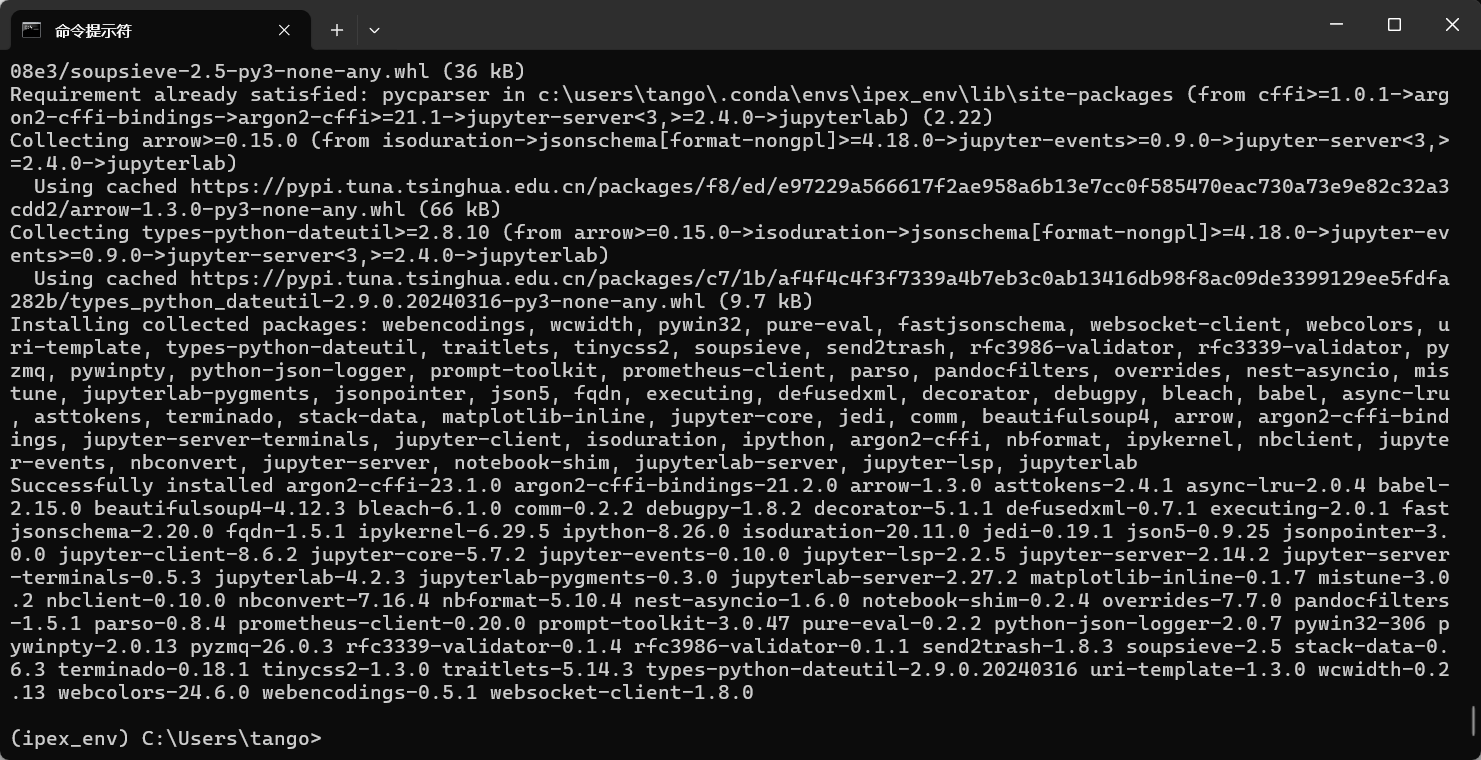
image-20240715214116952
将刚刚创建的虚拟环境注册到我们的jupyterlab中
python -m ipykernel install --name=ipex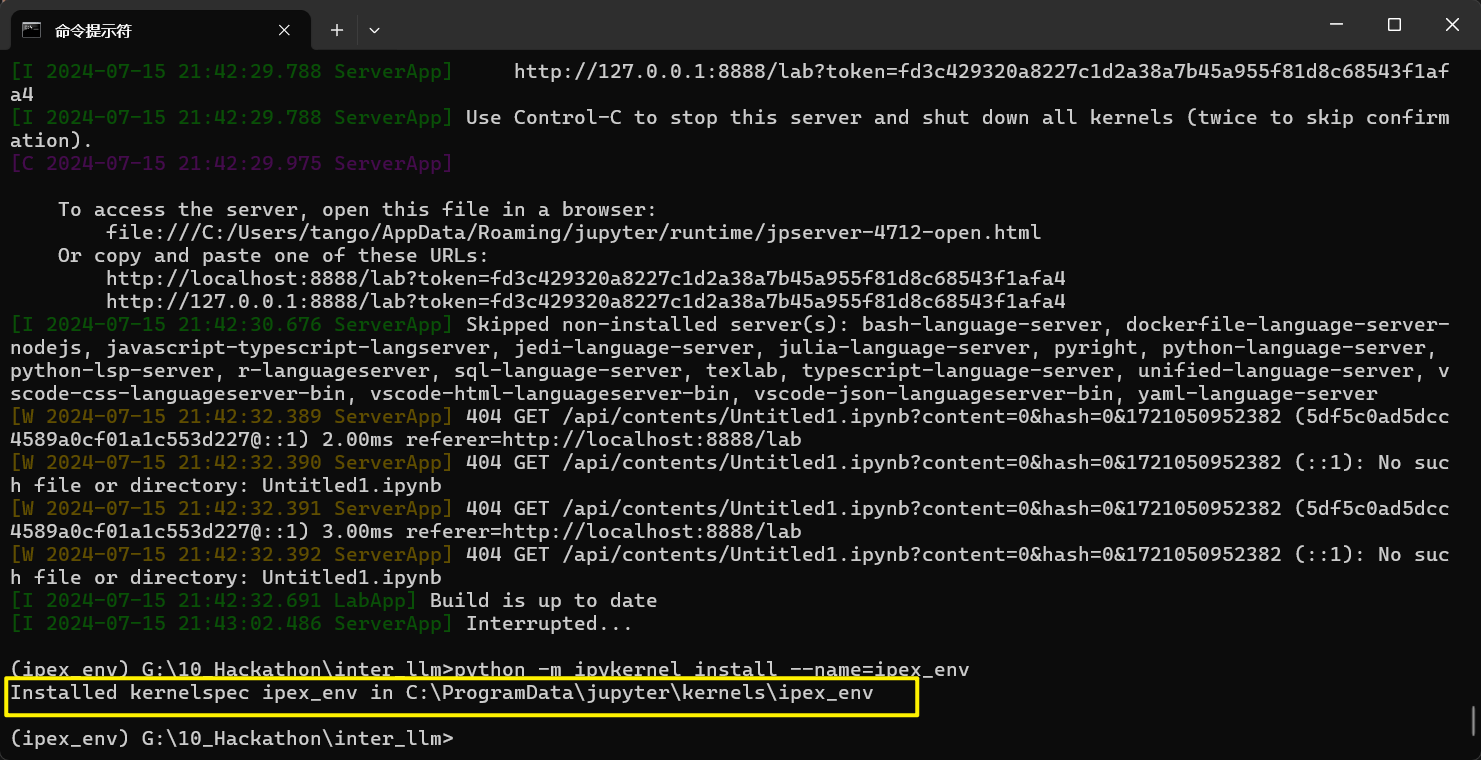
image-20240715214401200
这时我么你可以在jupyterlab中看到我们注册好的环境
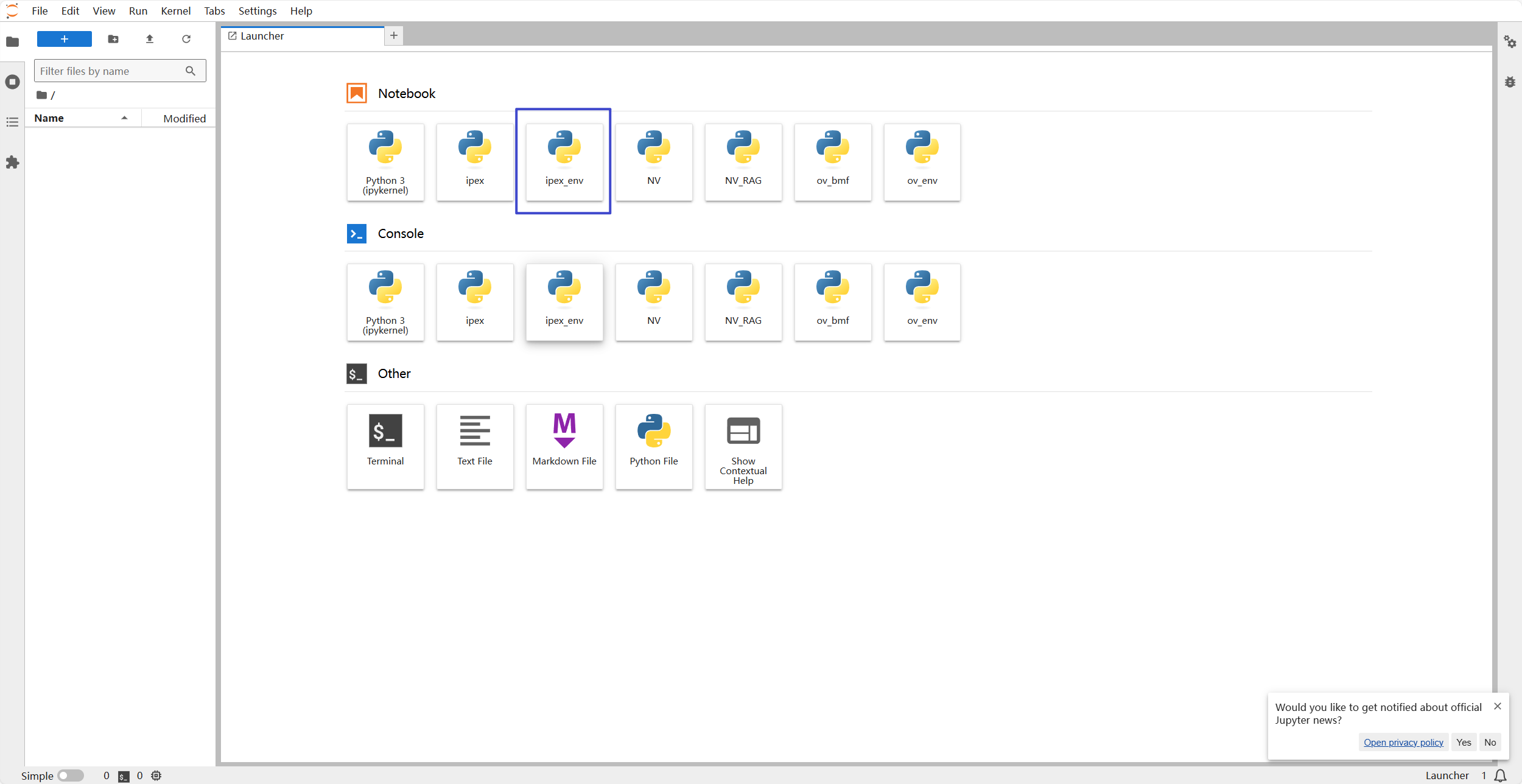
image-20240715214553584
在本地环境验证baseline1
下载模型
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
# 第一个参数表示下载模型的型号,第二个参数是下载后存放的缓存地址,第三个表示版本号,默认 master
model_dir = snapshot_download('Qwen/Qwen2-1.5B-Instruct', cache_dir='qwen2chat_src', revision='master')量化成int4
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
import os
if __name__ == '__main__':
model_path = os.path.join(os.getcwd(),"qwen2chat_src/Qwen/Qwen2-1___5B-Instruct")
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_low_bit='sym_int4', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model.save_low_bit('qwen2chat_int4')
tokenizer.save_pretrained('qwen2chat_int4')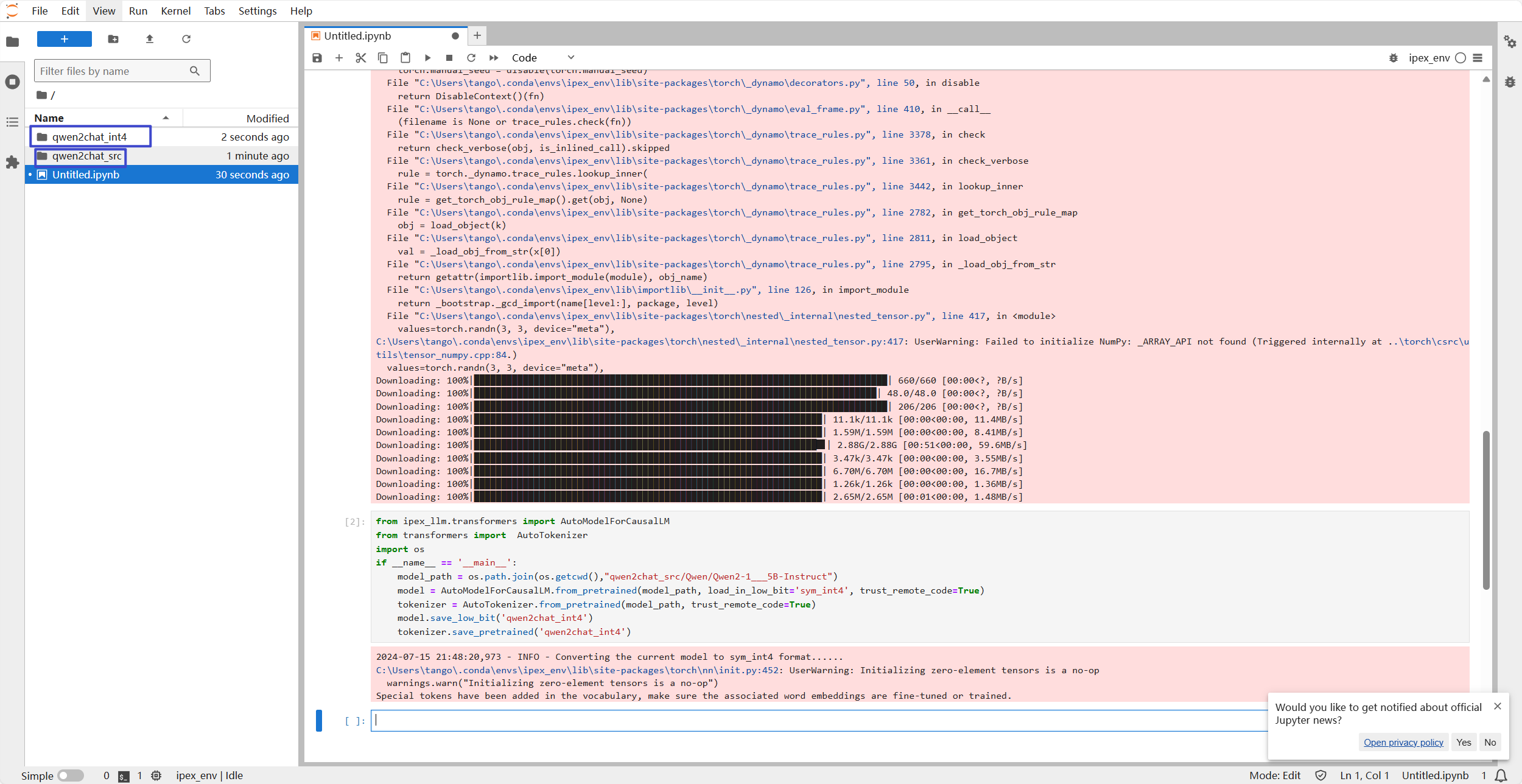
image-20240715214856847
看到左侧有两个文件夹,基本问题就不是很大了。
生成一次全部输出结果的脚本
生成运行脚本
%%writefile ./run.py
# 导入必要的库
import os
# 设置OpenMP线程数为8,优化CPU并行计算性能
os.environ["OMP_NUM_THREADS"] = "8"
import torch
import time
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
# 指定模型加载路径
load_path = "qwen2chat_int4"
# 加载低位(int4)量化模型,trust_remote_code=True允许执行模型仓库中的自定义代码
model = AutoModelForCausalLM.load_low_bit(load_path, trust_remote_code=True)
# 加载对应的分词器
tokenizer = AutoTokenizer.from_pretrained(load_path, trust_remote_code=True)
# 定义输入prompt
prompt = "给我讲一个芯片制造的流程"
# 构建符合模型输入格式的消息列表
messages = [{"role": "user", "content": prompt}]
# 使用推理模式,减少内存使用并提高推理速度
with torch.inference_mode():
# 应用聊天模板,将消息转换为模型输入格式的文本
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 将文本转换为模型输入张量,并移至CPU (如果使用GPU,这里应改为.to('cuda'))
model_inputs = tokenizer([text], return_tensors="pt").to('cpu')
st = time.time()
# 生成回答,max_new_tokens限制生成的最大token数
generated_ids = model.generate(model_inputs.input_ids,
max_new_tokens=512)
end = time.time()
# 初始化一个空列表,用于存储处理后的generated_ids
processed_generated_ids = []
# 使用zip函数同时遍历model_inputs.input_ids和generated_ids
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids):
# 计算输入序列的长度
input_length = len(input_ids)
# 从output_ids中截取新生成的部分
# 这是通过切片操作完成的,只保留input_length之后的部分
new_tokens = output_ids[input_length:]
# 将新生成的token添加到处理后的列表中
processed_generated_ids.append(new_tokens)
# 将处理后的列表赋值回generated_ids
generated_ids = processed_generated_ids
# 解码模型输出,转换为可读文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 打印推理时间
print(f'Inference time: {end-st:.2f} s')
# 打印原始prompt
print('-'*20, 'Prompt', '-'*20)
print(text)
# 打印模型生成的输出
print('-'*20, 'Output', '-'*20)
print(response)
image-20240715215015450
打开新的终端,激活环境,并运行刚刚生成的脚本
点击notebook右侧的加号
image-20240715215105650
选择终端
image-20240715215121405
输入以下代码
conda activate ipex_env
python run.py正常情况下会看到如下输出

image-20240715215451350
用流式的方式输出
%%writefile ./run_stream.py
# 设置OpenMP线程数为8
import os
os.environ["OMP_NUM_THREADS"] = "8"
import time
from transformers import AutoTokenizer
from transformers import TextStreamer
# 导入Intel扩展的Transformers模型
from ipex_llm.transformers import AutoModelForCausalLM
import torch
# 加载模型路径
load_path = "qwen2chat_int4"
# 加载4位量化的模型
model = AutoModelForCausalLM.load_low_bit(load_path, trust_remote_code=True)
# 加载对应的tokenizer
tokenizer = AutoTokenizer.from_pretrained(load_path, trust_remote_code=True)
# 创建文本流式输出器
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# 设置提示词
prompt = "给我讲一个芯片制造的流程"
# 构建消息列表
messages = [{"role": "user", "content": prompt}]
# 使用推理模式
with torch.inference_mode():
# 应用聊天模板,添加生成提示
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 对输入文本进行编码
model_inputs = tokenizer([text], return_tensors="pt")
print("start generate")
st = time.time() # 记录开始时间
# 生成文本
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512, # 最大生成512个新token
streamer=streamer, # 使用流式输出
)
end = time.time() # 记录结束时间
# 打印推理时间
print(f'Inference time: {end-st} s')
image-20240715215608761
在终端运行以下命令
python .\run_stream.py
image-20240715215741901
可以看到如上画面。
用gradio界面显示
%%writefile ./run_gradio_stream.py
import gradio as gr
import time
import os
from transformers import AutoTokenizer, TextIteratorStreamer
from ipex_llm.transformers import AutoModelForCausalLM
import torch
from threading import Thread, Event
# 设置环境变量
os.environ["OMP_NUM_THREADS"] = "8" # 设置OpenMP线程数为8,用于控制并行计算
# 加载模型和tokenizer
load_path = "qwen2chat_int4" # 模型路径
model = AutoModelForCausalLM.load_low_bit(load_path, trust_remote_code=True) # 加载低位模型
tokenizer = AutoTokenizer.from_pretrained(load_path, trust_remote_code=True) # 加载对应的tokenizer
# 将模型移动到GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检查是否有GPU可用
model = model.to(device) # 将模型移动到选定的设备上
# 创建 TextIteratorStreamer,用于流式生成文本
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# 创建一个停止事件,用于控制生成过程的中断
stop_event = Event()
# 定义用户输入处理函数
def user(user_message, history):
return "", history + [[user_message, None]] # 返回空字符串和更新后的历史记录
# 定义机器人回复生成函数
def bot(history):
stop_event.clear() # 重置停止事件
prompt = history[-1][0] # 获取最新的用户输入
messages = [{"role": "user", "content": prompt}] # 构建消息格式
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) # 应用聊天模板
model_inputs = tokenizer([text], return_tensors="pt").to(device) # 对输入进行编码并移到指定设备
print(f"\n用户输入: {prompt}")
print("模型输出: ", end="", flush=True)
start_time = time.time() # 记录开始时间
# 设置生成参数
generation_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=512, # 最大生成512个新token
do_sample=True, # 使用采样
top_p=0.7, # 使用top-p采样
temperature=0.95, # 控制生成的随机性
)
# 在新线程中运行模型生成
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
generated_text = ""
for new_text in streamer: # 迭代生成的文本流
if stop_event.is_set(): # 检查是否需要停止生成
print("\n生成被用户停止")
break
generated_text += new_text
print(new_text, end="", flush=True)
history[-1][1] = generated_text # 更新历史记录中的回复
yield history # 逐步返回更新的历史记录
end_time = time.time()
print(f"\n\n生成完成,用时: {end_time - start_time:.2f} 秒")
# 定义停止生成函数
def stop_generation():
stop_event.set() # 设置停止事件
# 使用Gradio创建Web界面
with gr.Blocks() as demo:
gr.Markdown("# Qwen 聊天机器人")
chatbot = gr.Chatbot() # 聊天界面组件
msg = gr.Textbox() # 用户输入文本框
clear = gr.Button("清除") # 清除按钮
stop = gr.Button("停止生成") # 停止生成按钮
# 设置用户输入提交后的处理流程
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
bot, chatbot, chatbot
)
clear.click(lambda: None, None, chatbot, queue=False) # 清除按钮功能
stop.click(stop_generation, queue=False) # 停止生成按钮功能
if __name__ == "__main__":
print("启动 Gradio 界面...")
demo.queue() # 启用队列处理请求
demo.launch() # 兼容魔搭情况下的路由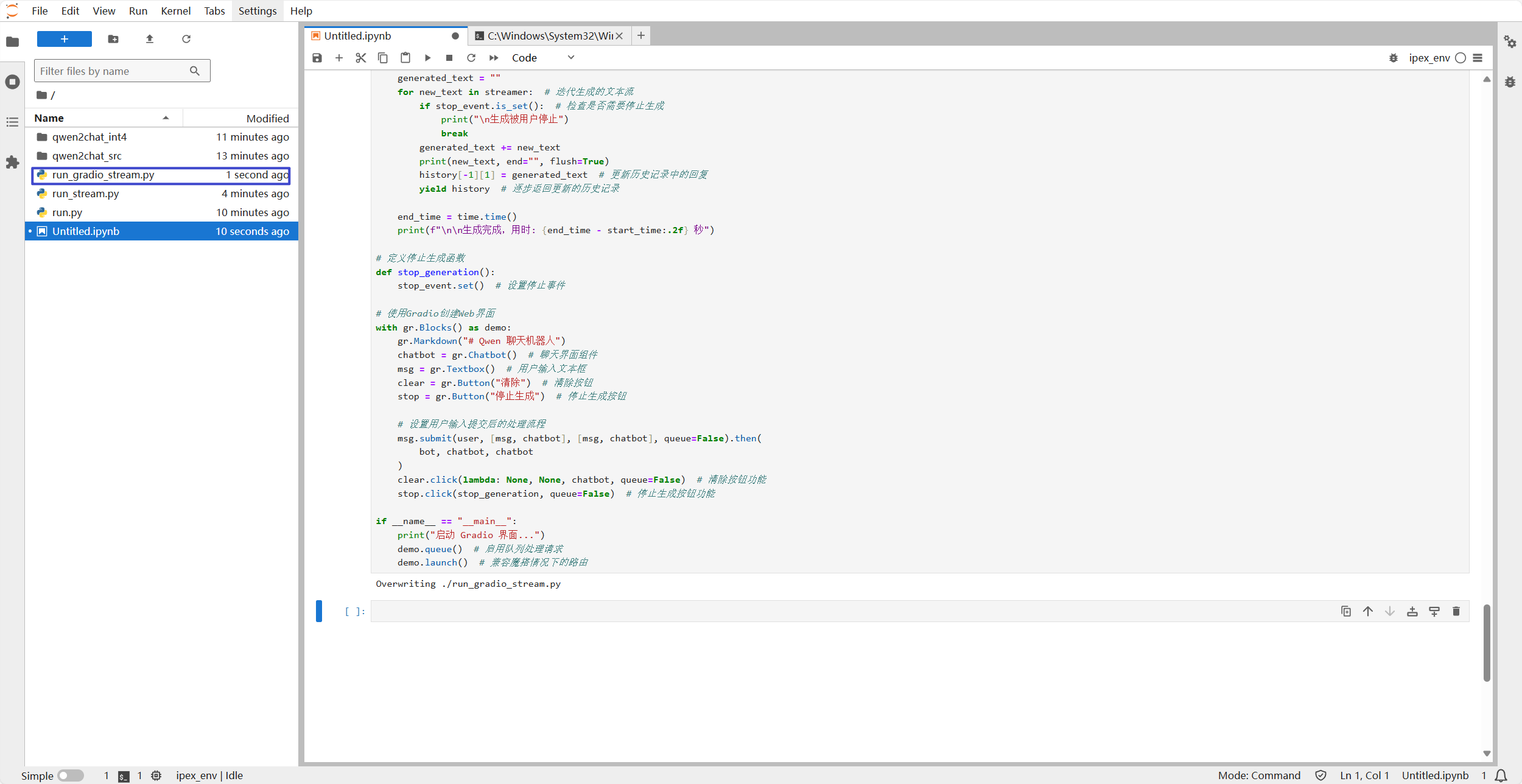
image-20240715220030011
生成好之后运行以下命令
python .\run_gradio_stream.py会看到如下画面,点击框中的链接可以看到一个web界面
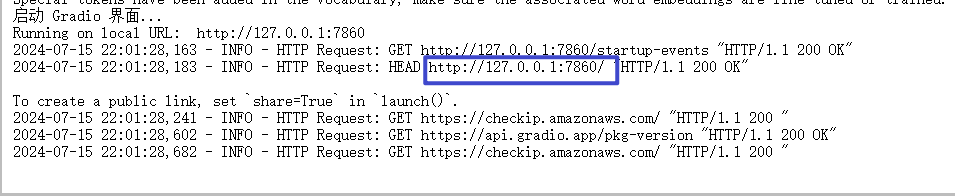
image-20240715220210885
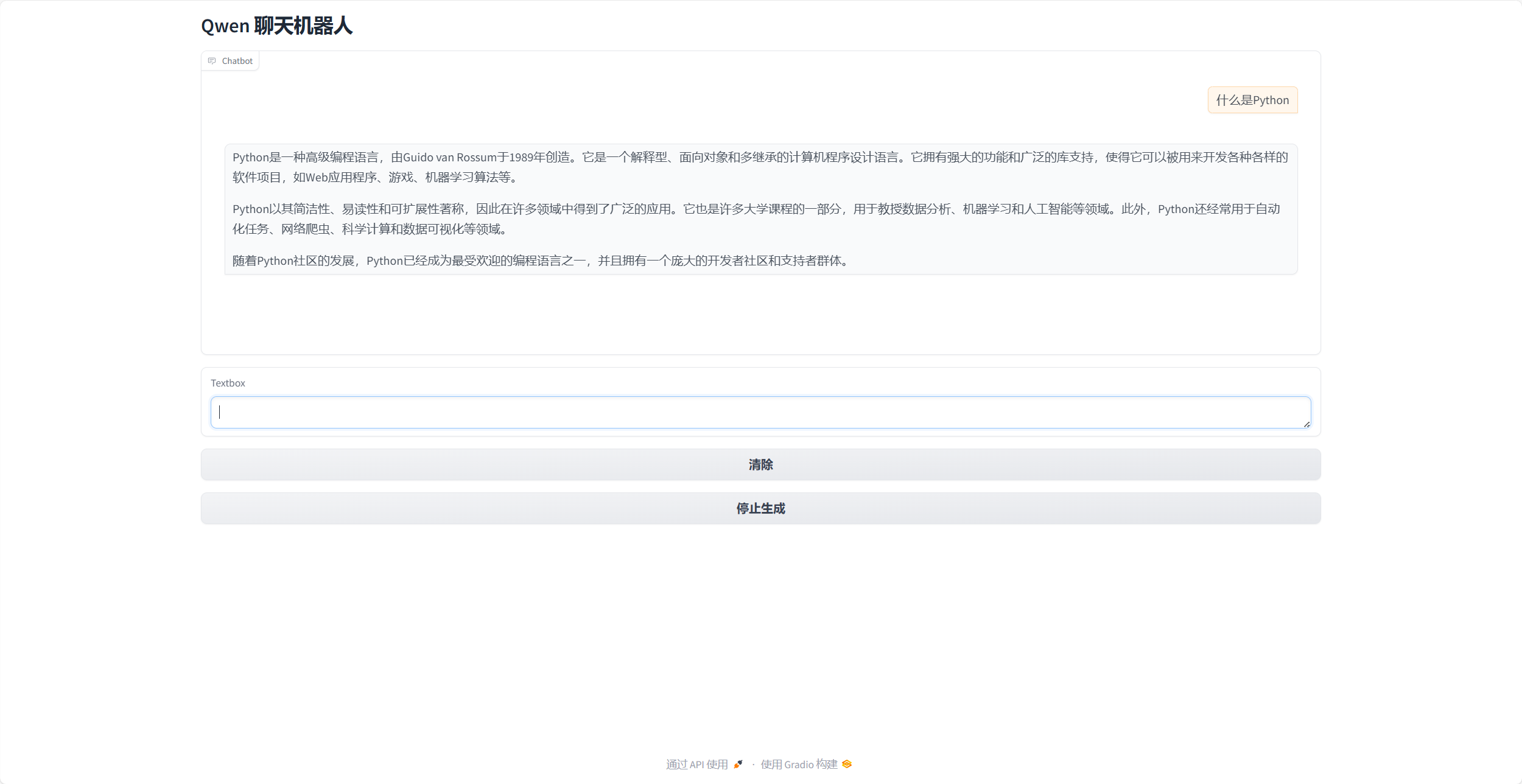
image-20240715220251513
用streamlit的方式运行
%%writefile ./run_streamlit_stream.py
# 导入操作系统模块,用于设置环境变量
import os
# 设置环境变量 OMP_NUM_THREADS 为 8,用于控制 OpenMP 线程数
os.environ["OMP_NUM_THREADS"] = "8"
# 导入时间模块
import time
# 导入 Streamlit 模块,用于创建 Web 应用
import streamlit as st
# 从 transformers 库中导入 AutoTokenizer 类
from transformers import AutoTokenizer
# 从 transformers 库中导入 TextStreamer 类
from transformers import TextStreamer
# 从 ipex_llm.transformers 库中导入 AutoModelForCausalLM 类
from ipex_llm.transformers import AutoModelForCausalLM
# 导入 PyTorch 库
import torch
# 指定模型路径
load_path = "qwen2chat_int4"
# 加载低比特率模型
model = AutoModelForCausalLM.load_low_bit(load_path, trust_remote_code=True)
# 从预训练模型中加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(load_path, trust_remote_code=True)
# 定义回调函数,用于逐步更新生成的文本
def stream_callback(text, message_placeholder, full_response):
# 更新完整响应
full_response += text
# 在 Streamlit 界面上显示带有光标的响应
message_placeholder.markdown(full_response + "▌")
return full_response
# 定义生成响应函数
def generate_response(prompt, message_placeholder):
# 将用户的提示转换为消息格式
messages = [{"role": "user", "content": prompt}]
# 应用聊天模板并进行 token 化
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt")
# 创建 TextStreamer 对象,跳过提示和特殊标记
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# 初始化一个空字符串用于存储完整响应
full_response = ""
# 定义回调函数
def callback(text):
nonlocal full_response
# 调用 stream_callback 函数更新响应
full_response = stream_callback(text, message_placeholder, full_response)
# 设置 TextStreamer 的回调函数
streamer.on_text_chunk = callback
# 使用推理模式生成响应
with torch.inference_mode():
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
streamer=streamer,
)
# 初始化一个空列表,用于存储处理后的 generated_ids
processed_generated_ids = []
# 使用 zip 函数同时遍历 model_inputs.input_ids 和 generated_ids
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids):
# 计算输入序列的长度
input_length = len(input_ids)
# 从 output_ids 中截取新生成的部分
# 这是通过切片操作完成的,只保留 input_length 之后的部分
new_tokens = output_ids[input_length:]
# 将新生成的 token 添加到处理后的列表中
processed_generated_ids.append(new_tokens)
# 将处理后的列表赋值回 generated_ids
generated_ids = processed_generated_ids
# 解码生成的 token 为文本
response_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
return response_text
# Streamlit 应用部分
# 设置应用标题
st.title("大模型聊天应用")
# 初始化聊天历史,如果不存在则创建一个空列表
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示聊天历史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 用户输入部分
if prompt := st.chat_input("你想说点什么?"):
# 将用户消息添加到聊天历史
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# 创建空的占位符用于显示生成的响应
with st.chat_message("assistant"):
message_placeholder = st.empty()
# 调用模型生成响应
response = generate_response(prompt, message_placeholder)
# 在占位符中显示响应
message_placeholder.markdown(response)
# 将助手的响应添加到聊天历史
st.session_state.messages.append({"role": "assistant", "content": response})
image-20240715220405908
生成好之后,运行以下命令
streamlit run run_streamlit_stream.py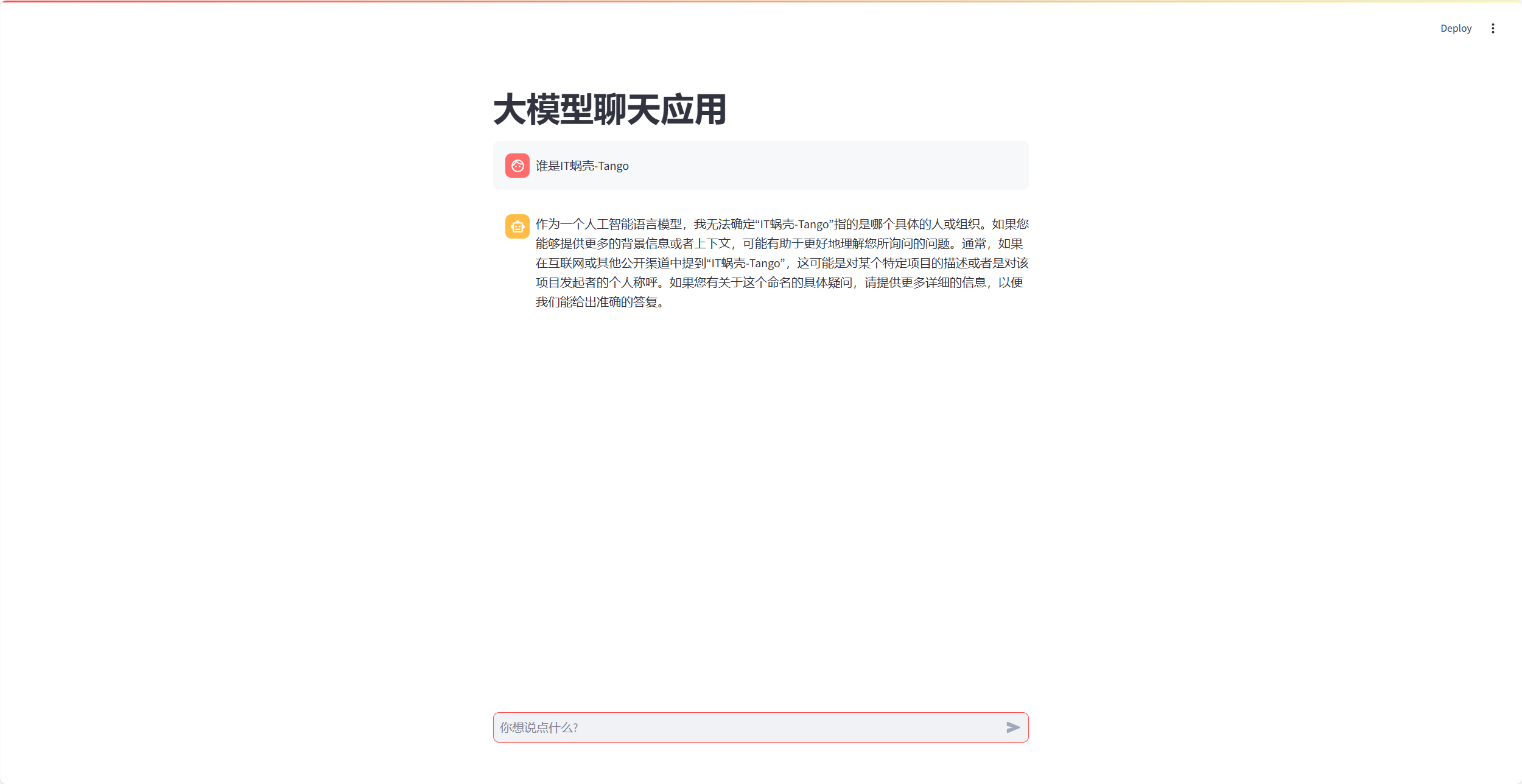
image-20240715220603567
总结
至此,完成了本地环境的baseline1的环境搭建。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
GPU 云服务器
GPU 云服务器(Cloud GPU Service,GPU)是提供 GPU 算力的弹性计算服务,具有超强的并行计算能力,作为 IaaS 层的尖兵利器,服务于生成式AI,自动驾驶,深度学习训练、科学计算、图形图像处理、视频编解码等场景。腾讯云随时提供触手可得的算力,有效缓解您的计算压力,提升业务效率与竞争力。
腾讯云开发者
