Elasticsearch7.14版本集群架构升级之冷热集群
原创
Elasticsearch7.14版本集群架构升级之冷热集群
原创
空洞的盒子
发布于 2024-07-24 17:48:48
发布于 2024-07-24 17:48:48
Elasticsearch节点角色(node role)
master
具备主节点角色,拥有控制集群的权限。当节点被授予该角色时,则表明该节点有资格被选举为主节点。
node.roles: [ master ]用途
负责轻量化整个集群范围内的操作,例如创建或删除索引、跟踪哪些节点是集群的一部分以及决定将哪些分片分配给哪些节点。
voting-only
在master角色中,有另外个角色voting-only,需要注意的是该角色主要用于集群中选举主节点时投票使用。并不实际承担主节点的其他职责(如管理集群元数据和协调集群操作)。在一定程度上能够简化主节点的负载,让主节点更专注于集群的管理。
node.roles: [ data, master, voting_only ]用途
1. 主节点选举:
• voting-only 节点参与主节点的选举投票,以确保选举过程更加稳定和可靠。然而,它们不会实际承担主节点职责。
2. 集群稳定性:
• 添加 voting-only 节点可以帮助达到所需的最低主节点数(minimum_master_nodes),从而提高集群的稳定性,特别是在主节点数量较少的情况下。
3. 简化主节点负载:
• 通过分离选举投票和实际主节点职责,可以减轻主节点的负载,使其专注于集群管理任务。
data
具备数据节点角色,数据节点用于数据的保存,并执行与数据相关的操作,例如:CRUD,搜索聚合等。具备data角色后,该节点将拥有数据节点的最高权限。将拥有任何数据节点的功能。
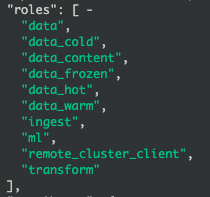
node.roles: [ data ]如果我们需要对节点指定特定的数据层,例如指定为data_content,data_hot,data_warm,data_cold, ordata_frozen,则此时节点将不在具有通用数据角色 data角色。
data_content
data_content 角色的节点专门用于存储和处理内容数据。这些节点通常用于存储活跃数据集和频繁查询的数据,例如,网站内容、用户信息等。
node.roles: [ data_content ]用途
1. 存储活跃数据:
• data_content 节点适用于存储需要频繁访问和更新的活跃数据集。它们通常配置有较高的性能参数以处理频繁的读写操作。
2. 提高查询性能:
• 由于这些节点存储的是活跃内容数据,它们通常需要较高的查询性能来满足低延迟和高吞吐量的查询需求。
3. 简化数据管理:
• 将内容数据与冷数据、热数据等分开存储,有助于简化数据管理和优化资源配置。
data_hot
data_hot 角色的节点专门用于存储和处理最近索引和频繁查询的数据。data_hot 节点通常用于处理高写入速率和低延迟查询的数据场景,如实时日志数据、近期交易数据等。用于该角色的节点一般以SSD硬盘作为存储介质。以此来满足实时,低延迟等业务场景。
node.roles: [ data_hot ]用途
1. 高写入速率:
• data_hot 节点用于处理频繁的写操作,包括实时数据索引和写入。这些节点通常配置有高性能的硬件,以支持快速的数据写入和索引构建。
2. 低延迟查询:
• 由于存储的是最近和活跃的数据,data_hot 节点需要提供快速的查询响应时间,以满足低延迟查询的需求。
3. 短期存储:
• data_hot 节点上的数据通常只保留较短的时间,然后通过索引生命周期管理(ILM)策略移动到 data_warm 或 data_cold 节点。
data_warm
当热数据层的索引不在频繁更新,或只有少量请求时,我们可以为节点赋予data_warm角色,用于存放这类数据。data_warm 角色的节点用于存储不再频繁访问但仍需要保留的旧数据。这些节点通常配置在相对较低成本的硬件上,适用于存储已经从 data_hot 节点转移过来的数据。data_warm 角色在数据生命周期管理(ILM)中扮演重要角色,帮助优化存储成本和查询性能。
node.roles: [ data_warm ]用途
1. 存储旧数据:
• data_warm 节点存储那些仍需要保留但访问频率较低的数据。数据从 data_hot 节点转移到 data_warm 节点,以优化存储和查询效率。
2. 优化存储成本:
• 这些节点通常配置在成本较低但容量较大的硬件上,以减少存储开销。
3. 分散查询负载:
• 通过将访问频率较低的数据转移到 data_warm 节点,可以减轻 data_hot 节点的负载,从而提高整个集群的查询性能。
data_cold
data_cold 角色的节点专门用于存储很少访问的历史数据。这些节点的主要用途是优化存储成本,同时仍然保持数据的可访问性。data_cold 节点通常配置在低成本的硬件上,适合长期存储需要保留但很少查询的数据。
node.roles: [ data_cold ]用途
1. 存储历史数据:
• data_cold 节点用于存储访问频率非常低的历史数据。这些数据在业务上仍然有价值,但查询频率极低。
2. 优化存储成本:
• 这些节点通常配置在低成本的硬件上,以最小化存储开销,同时确保数据在需要时仍然可用。
3. 长期数据保留:
• data_cold 节点适合存储需要长期保留的数据,如法律合规要求的数据归档。
data_frozen
data_frozen 角色的节点专门用于存储几乎不访问的归档数据。如果我们需要对节点赋予data_frozen冻结层角色,建议使用专门的节点作为frozen节点.
node.roles: [ data_frozen ]ingest
具有ingest角色的节点。主要用于文档的预处理与加工,带有 ingest 角色的节点能够执行 Ingest 管道,这是在文档索引之前对其进行变换和处理的一种方式。Ingest 管道允许你在数据进入 Elasticsearch 之前对其进行一系列的处理,如解析、转换、或丰富数据。如果预处理的流程较为复杂,建议配置专用的ingest node。
用途
1. 预处理文档:
• 在将文档索引到 Elasticsearch 之前,可以通过 Ingest 管道对其进行预处理。例如,你可以解析日志行、提取字段、进行数据清理和格式化等。
2. 复杂的数据处理:
• 使用各种 Ingest 处理器来执行复杂的数据处理任务,如正则表达式解析、Grok 解析、日期处理、字段重命名、字段删除、字段添加等。
3. 减轻客户端的负担:
• 将数据处理逻辑从客户端转移到 Elasticsearch,可以简化客户端应用程序的代码和逻辑。
ml
Elasticsearch支持运行机器学习学习任务,如果我们需要执行相关机器学习API时,需要对节点授予ml角色,以表明该节点为机器学习节点。在配置ml角色时,建议在节点上同时配置remote_cluster_client角色。避免机器学习作业在使用跨集群搜索数据时报错。所有需要跨集群搜索的所有符合的节点都需要授予remote_cluster_client该角色。
node.roles: [ ml, remote_cluster_client]remote_cluster_client
remote_cluster_client 角色的节点用于与远程集群进行通信和协调。这种角色通常在跨集群搜索(CCS)和跨集群复制(CCR)等场景中使用,允许一个集群作为客户端连接到另一个远程集群,以便进行查询或复制操作。
node.roles: [ remote_cluster_client]用途
1. 跨集群搜索(Cross-Cluster Search, CCS):
• 允许在一个本地集群中搜索和查询远程集群的数据。remote_cluster_client 角色的节点负责与远程集群建立连接并执行查询。
2. 跨集群复制(Cross-Cluster Replication, CCR):
• 允许在一个集群中将数据索引复制到另一个远程集群。remote_cluster_client 角色的节点在这种场景中负责与远程集群通信,进行数据复制。
3. 统一查询和管理:
• 通过配置远程集群,使用 remote_cluster_client 角色的节点可以在本地集群上执行跨集群操作,简化了分布式数据查询和管理的复杂性。
transform
transform 角色的节点用于管理和执行数据转换任务。数据转换(Transforms)是 Elasticsearch 中的一种功能,用于将数据从一种格式或结构转换为另一种格式或结构。transform 角色在数据转换任务的创建、执行和管理过程中扮演关键角色。
node.roles: [ transform, remote_cluster_client ]用途
1. 数据聚合和汇总:
• transform 角色节点可以将原始数据聚合成总结数据。例如,可以将日志数据聚合成每日或每小时的统计数据。
2. 数据透视:
• 通过数据转换,可以将平面的记录转换为多维数据(如透视表),以便更好地分析和可视化数据。
3. 实时和批处理转换:
• transform 角色节点支持实时数据转换和批处理数据转换,能够适应不同的应用场景和需求。
4. 复杂的计算和处理:
• 数据转换可以包含复杂的计算和处理逻辑,将原始数据转换为更有用和结构化的格式。
Elasticsearch单一模式集群
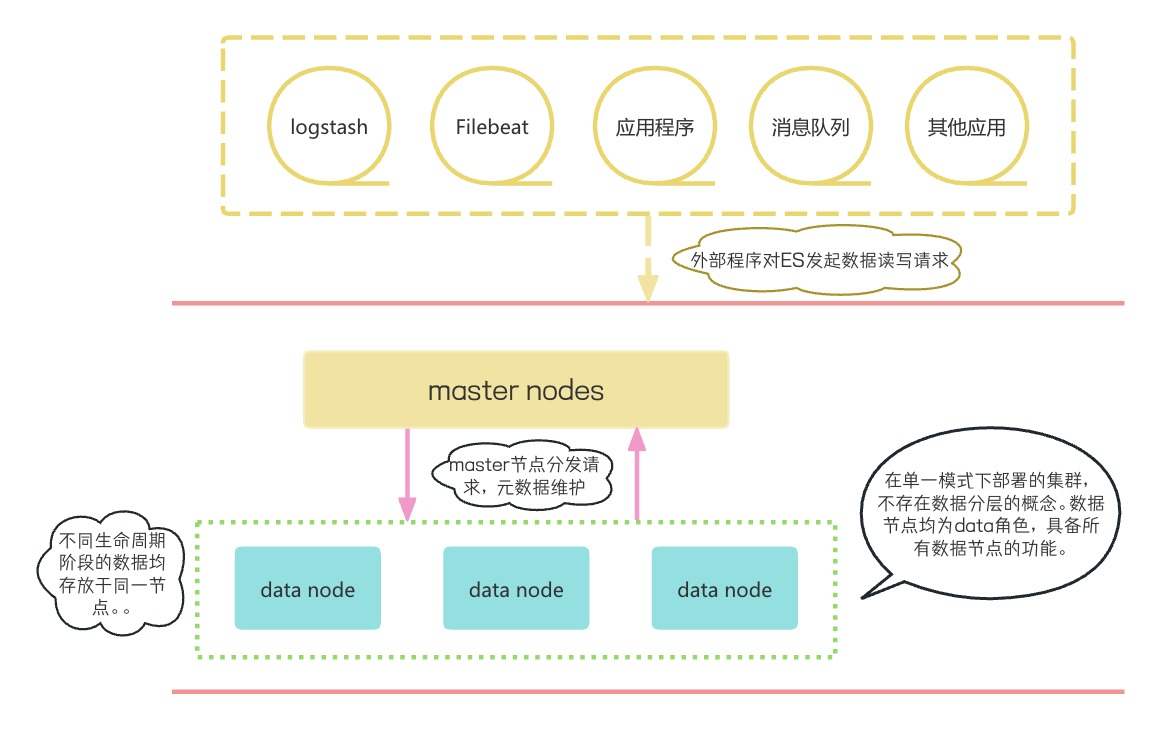
单一模式集群
在单一模式集群中,数据节点统一为通用数据角色,node.role统一配置为data。在进行角色配置时,使用如下方式:
#在elasticsearch.yml中添加如下配置,即可将节点配置为通用数据角色。
node.data: true配置完成后启动ES服务,即可发现,该数据节点拥有全部数据层角色。
在单一模式集群下,索引不存在数据分层概念,处于不同生命周期阶段的索引数据均存储于同一层数据节点。所有的数据操作均在通用数据节点上完成。例如:新数据的写入,快照的备份等。
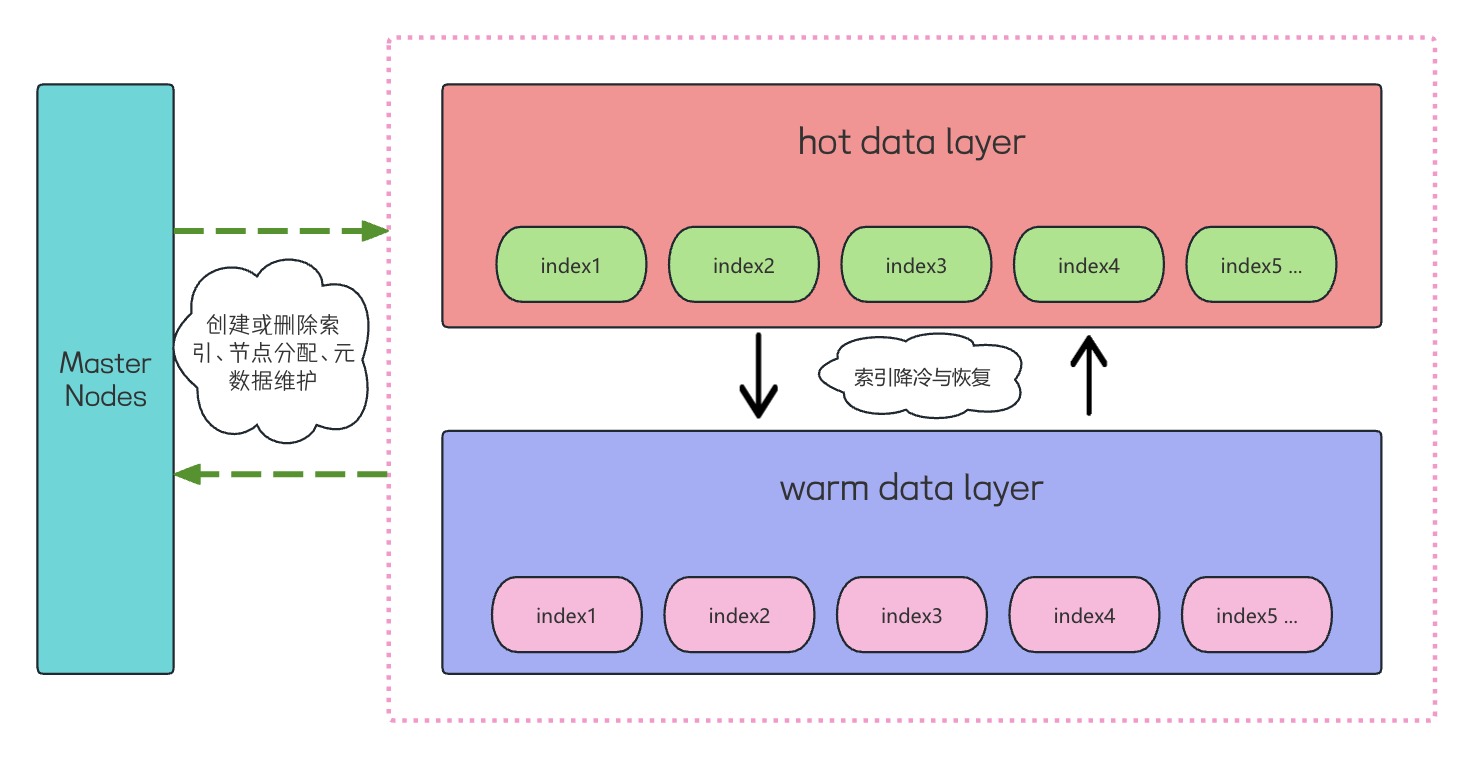
Elasticsearch冷热集群
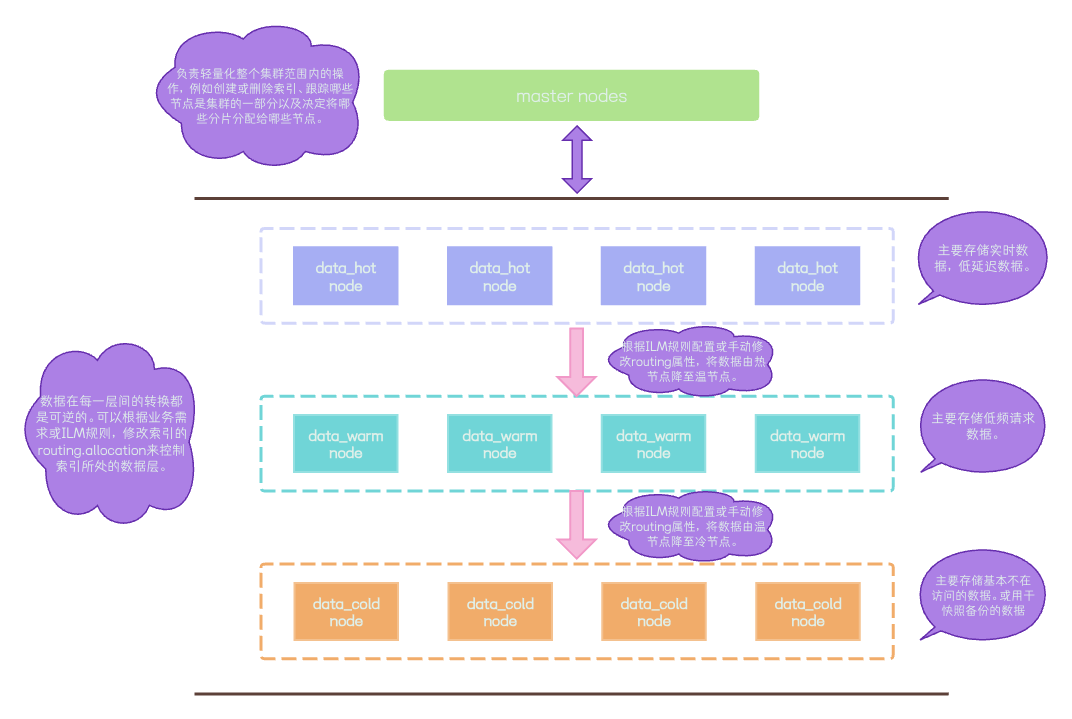
冷热集群示意图
在冷热模式下,我们在集群中引入了热数据层,温数据层,与冷数据层。在一般生产环境中,只需要使用到热数据层与温数据层。根据业务系统的需要,我们可以针对性的定义ILM生命周期策略,规则中可以约束达到什么阈值或条件,索引进行不同的生命周期动作,例如:索引降冷,索引冻结等操作。如果我们的集群没有进行ILM生命周期的配置,我们也可以使用手动修改cluster.routing.allocation路由参数值来对索引进行降冷或其他操作。
热数据层节点角色配置
在elasticsearch.yml中添加一下内容:
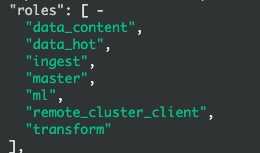
node.roles: [data_content,data_hot,remote_cluster_client,ingest,transform,ml]这里我们使用静态方式对节点角色进行约束。
如果我们的集群是热数据节点与主节点混合部署共用同一台节点时,我们还需要为节点添加master角色。
node.roles: [master,data_content,data_hot,remote_cluster_client,ingest,transform,ml]角色添加完成后,我们重启elasticsearch服务。重启后,热节点角色如图:
冷数据层节点角色配置
在elasticsearch.yml中添加一下内容:
node.roles: [data_content,data_warm,remote_cluster_client,ingest,transform,ml]角色添加完成后,我们重启elasticsearch服务。重启后,冷节点角色如图:
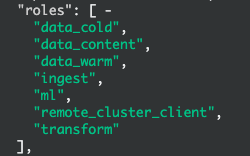
注意事项
- 冷热集群中使用的node.role属于静态指定节点角色,在配置时,不能与
node.data:true;node.master:true;同时使用。如果原有yml文件中配置了这两行,需要注释后,在进行node.role配置。 - 在进行角色配置更新时,节点的修改本着先修改数据节点,后修改主节点的原则。避免由于先修改主节点角色导致集群失联,影响业务系统对elasticsearch集群的使用。
- 修改集群中节点的角色需要重启节点上的elasticsearch服务,重启后需要进行分片恢复,建议在业务低峰期操作变更。
Elasticsearch索引降冷与恢复
索引数据降冷示意图
索引手动降冷
在集群升级为冷热分层的架构之后,我们可以使用以下语句对存量索引进行手动降冷。
PUT indexname/_settings
{
"index.routing.allocation.include._tier_preference": "data_warm"
}索引的降冷与恢复是可逆的,主要通过修改索引routing数据层的属性实现。
ILM生命周期策略
如果需要使用ILM生命周期策略对索引进行全自动化的托管,请大家移步我的https://cloud.tencent.com/developer/article/2356835文章进行了解。
关键概念理解
node.role:节点的角色,用于控制节点在集群中所拥有的权限。根据我们的业务场景需求,对节点配置相应的角色,以保证集群具备良好的性能与稳定的运行。
index.routing.allocation.include._tier_preference:用于将索引分配给集群中的可用层。根据我们指定的配置,将索引分片分布至相应的节点上。本质上是用于控制索引分片在指定存储层级(tier)之间的优先级。该参数是索引路由分配(allocation)的配置之一,通过指定不同的层级,可以灵活地管理数据在集群中的分布和存储。例如:将该参数值设置为hot,那么索引在节点上分配时,就会优先分配至符合条件的data_hot节点。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号