打造垂直领域内容的问答机器人
原创

简介
在大模型问世之后,其中一个最核心的功能就是问答机器人。但是若直接将问题抛给 ChatGPT,仍然解决不了以下限制:
- 相关的关联数据需要联网。
- 相关的关联数据是 GPT 也不知道的私密数据。
而在前面介绍RAG 检索增强生成的时候也同样提到了这一点。
应用场景
垂直领域内容的问答机器人的应用场景非常多,比如金融、医疗、电商等。
如果是针对于互联网相关的从业人员,比如开发、测试、产品等,我们还可以让其帮助我们进行以下多种类型的工作:
- 公司知识库检索。
- 需求分析。
- 用例评审、测试用例生成
- 代码生成。
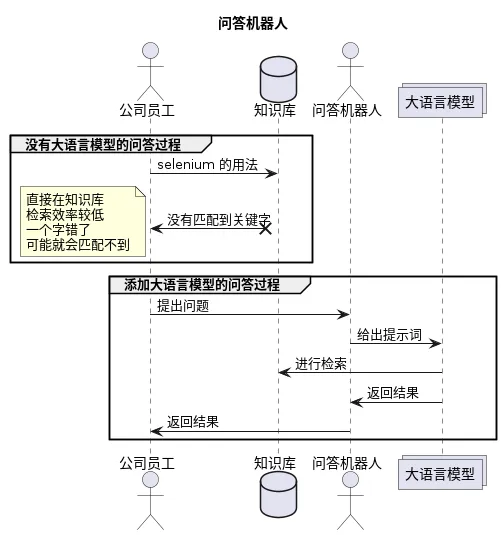
实践演练
那么如果要完成一个垂直领域内容的问答机器人,其实也是有多种方式的:
- openai 官方在 2023 年末做了一次重大更新,推出了官方的 assistant,可以通过官方的 assistant 完成一个问答机器人。
- 其他方式,比如通过 RAG 结合向量数据库,或结合 LangChain 等人工智能应用框架完成。
使用官方的 assistant
点击查看官方 assistant 使用教程
如果使用 assistant 创建一个垂直领域内容的问答机器人,那么主要需要的,就是 Retrieval 的能力,注意这个能力至少需要 gpt-3.5-turbo-1106(支持较新版本)或 gpt-4-turbo-preview 型号。
- 编写好 Instructions,注意角色设定越详细越清楚越好。
- 将 Retrieval 的配置打开,再将需要给机器人检索的文件上传上去(注意,文件越大 token 消费越高)。
- 输入想要检索的信息的 prompt。
- 即可获取到文档内的信息内容。
- 注意,上传的文件有格式限制,支持的格式为官方支持的格式
通过编写代码实现
import time
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# 1. 绑定课程文件
file = client.files.create(
file=open("课程数据.md", "rb"),
purpose='assistants'
)
# 2. 创建课程处理机器人
assistant = client.beta.assistants.create(
instructions="你是一个课程维护者,你需要清楚的知道课程名称以及其对应的url地址。",
model="gpt-4-turbo-preview",
tools=[{"type": "retrieval"}],
file_ids=[file.id]
)
# 3. 创建一个线程
thread = client.beta.threads.create()
# 4. 创建一条消息
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="请告诉我超时处理对应的视频地址"
)
# 5. 提问
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions="你是一个课程维护者,你需要清楚的知道课程名称以及其对应的url地址。",
)
# 6. 循环查询问题是否已经解决完成
def wait_on_run(run, thread):
while run.status == "queued" or run.status == "in_progress":
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id,
)
time.sleep(0.5)
return run
wait_on_run(run, thread)
# 6. 获取历史消息
messages = client.beta.threads.messages.list(thread_id=thread.id).model_dump_json(indent=2)
print(messages)其他方式
- 结合向量数据库完成。
- 结合 LangChain 等人工智能应用框架完成。
总结
- 垂直领域内容的问答机器人的产品需求。
- 垂直领域内容的问答机器人的实现方案。
- 使用官方 assistant 实现垂直领域的问答机器人。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者
