【赵渝强老师】Hive的体系架构
原创

在Hadoop体系中提供数据分析引擎Hive。它允许使用SQL语句来分析处理数据,而不需要编程复杂的Java程序。同时Hive提供了丰富的数据模型来创建各种表结构,帮助数据分析人员建立数据模型。视频讲解如下:
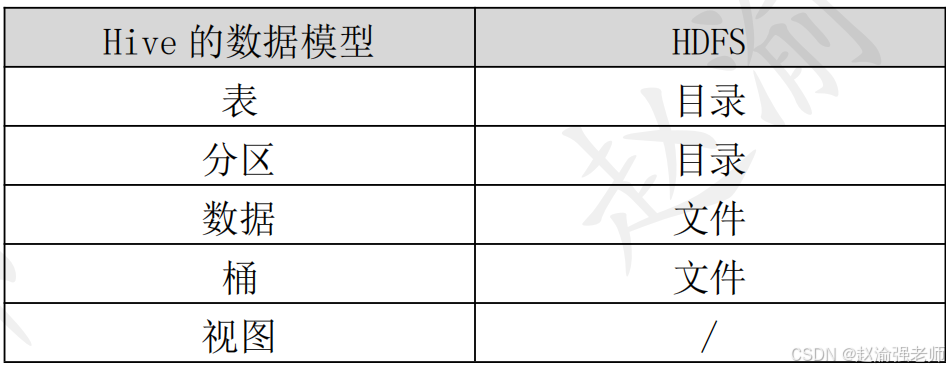
Hive是基于Hadoop之上的数据仓库平台,提供了数据仓库的相关功能。Hive最早起源于FaceBook,2008年FaceBook将Hive贡献给了Apache,成为了Hadoop体系中的一个组成部分。Hive支持的语言是HQL语言,即:Hive Query Language,它是SQL语言的一个子集。随着Hive版本的提高,HQL语言支持的SQL语法也会越来越多。从另一个方面来看,可以把Hive理解为一个翻译器,默认的行为是Hive on MapReduce,也是在Hive中执行的HQL语句会被转换成一个MapReduce任务运行在Yarn之上,从而处理HDFS中的数据。下表对比的它们之间的对应关系。
Hive的底层主要依赖于HDFS和Yarn。Hive将数据存入HDFS中,并将执行的SQL语句转换成MapReduce运行在Yarn上。下图说明了Hive的体系架构。
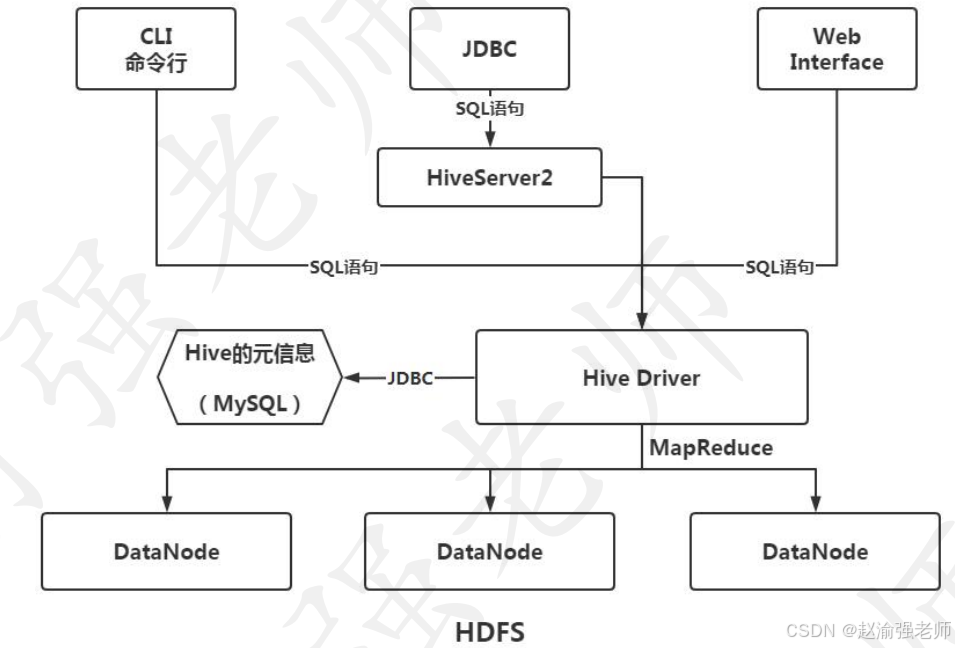
Hive的核心是其执行引擎Hive Driver,可以把它理解成是一个翻译器。通过Hive Driver可以把SQL语句转换成MapReduce处理HDFS中的数据。由于Hive需要将数据模型的元信息保存下来,因此Hive需要一个关系型数据库的支持,官方推荐使用MySQL来存储Hive的元信息。
元信息指的是:表名、列名、列的类型、分区、桶的信息等等。通过配置JDBC相关参数,在创建表的同时由Hive Driver将元信息存入MySQL中。
Hive提供了三种不同的方式来执行SQL:
- Hive CLI命令行方式
CLI是Command Line Interface的缩写,它是Hive的命令行客户端。Hive CLI的使用方式基本上与MySQL的命令行客户端一样,开发人员可以直接在命令行中书写SQL语句。
- 通过JDBC方式
Hive可以被当成一个关系型数据库来使用。因此可以使用标准的JDBC程序来访问Hive,从而执行SQL语句。但是开发JDBC程序需要有数据库服务器的支持,因此Hive提供了HiveServer2。通过这个Server,JDBC程序可以将SQL最终提交给Hive Driver执行。
默认配置下HiveServer2的端口是10000,而Hive数据库的名称是default。
- 使用Hive Web Interface
Hive提供基于Web的客户端来执行SQL。但是从Hive 2.3版本开始,Hive Web Interface就被废弃了,原因是它所提供的功能太过于简单。如果要使用Web客户端,建议使用HUE。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
