【AI绘画】Midjourney前置指令/blend、/info、/subscribe详解

【AI绘画】Midjourney前置指令/blend、/info、/subscribe详解

CSDN-Z
发布于 2024-10-17 18:05:21
发布于 2024-10-17 18:05:21
💯前言
- 在本文中,我们将继续介绍Midjourney中其他的前置指令。之前我们已经在Midjourney前置指令/settings设置详解和Midjourney前置/imagine与单图指令详解中深入解析了/settings和/imagine这两个指令。接下来,我们将继续深入/blend、/info和/subscribe前置指令的功能和使用方法。相信通过本篇文章,能够帮助你更好地掌握Midjourney前置指令的强大功能,提升AI绘画创作体验!
- Midjourney官方使用手册
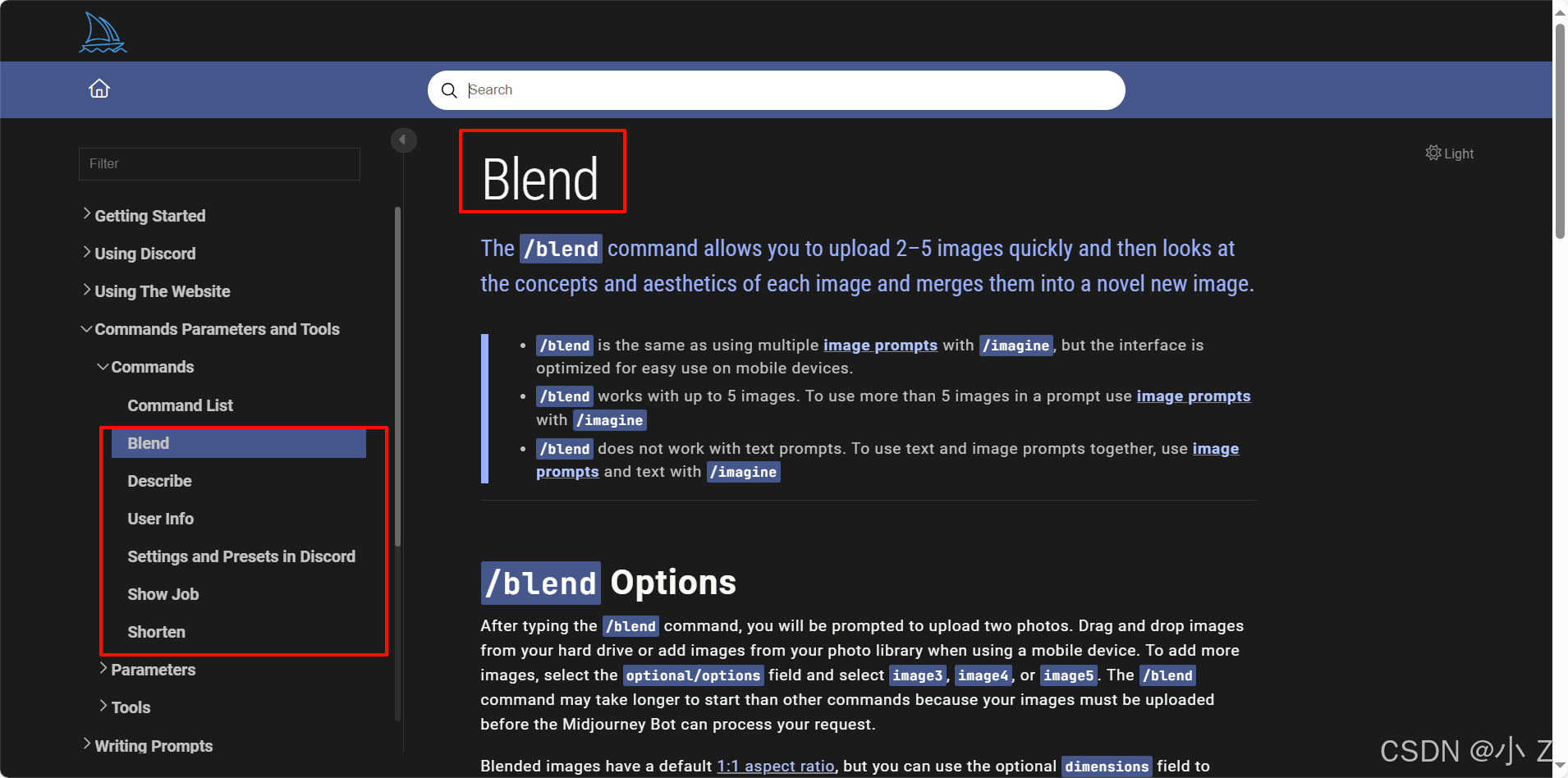
💯Midjourney前置指令/blend
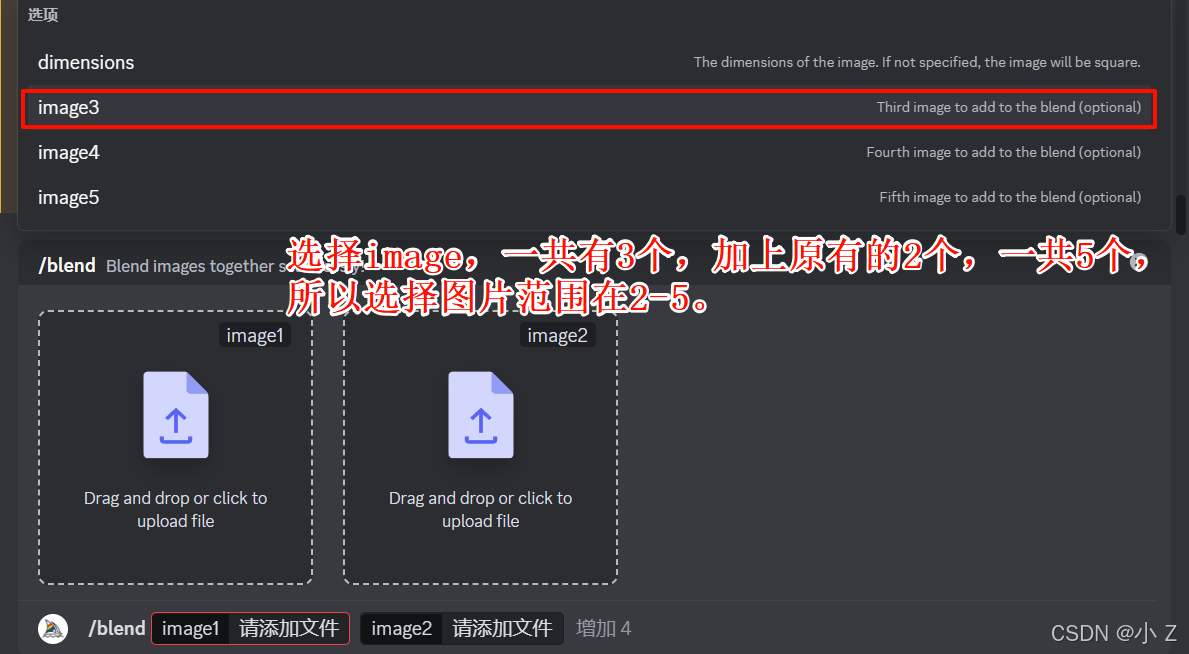
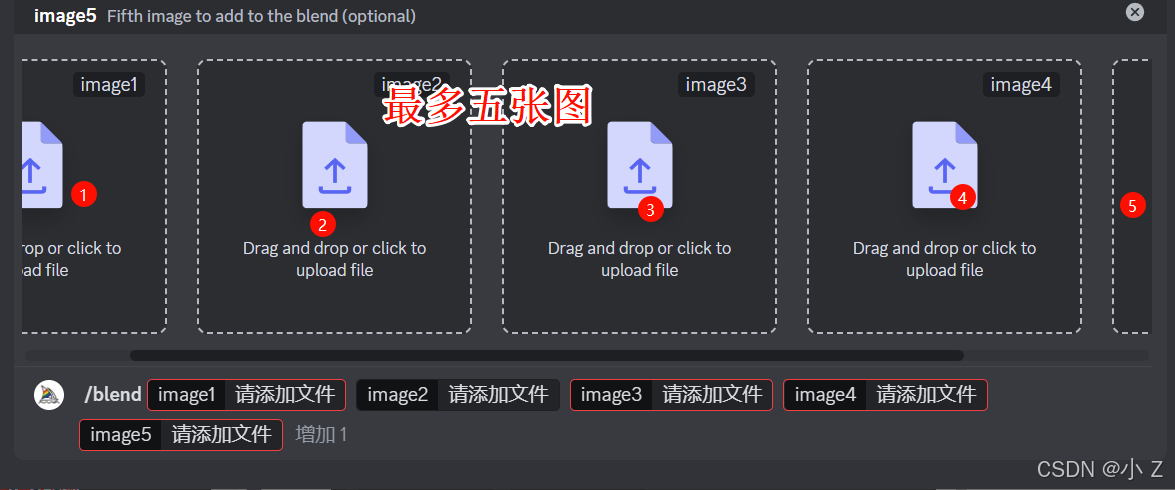
/blend允许您快速上传2-5张图片,然后根据他们的概念与美学特征进行混合。
- 首先要介绍的命令是/blend。顾名思义,blend在英文中是“混合”的意思,因此我们通常称之为“混合命令”。这个命令的主要功能是让你上传2到5张图片,然后Midjourney会根据这些图片的特征进行融合。它的工作原理类似于一个搅拌机,将几张图片的特征混合在一起,最终生成一张包含所有图片特征的全新图像。
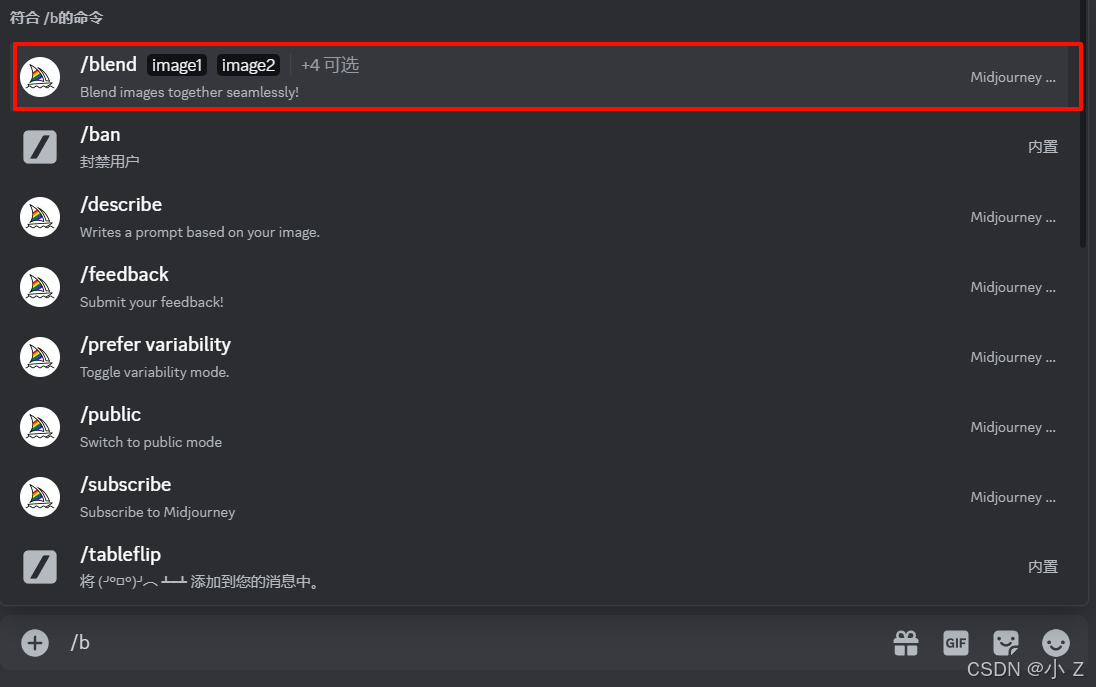
- 选择/blend后,聊天区会显示一个新的界面,这就是我们接下来要详细介绍的内容。
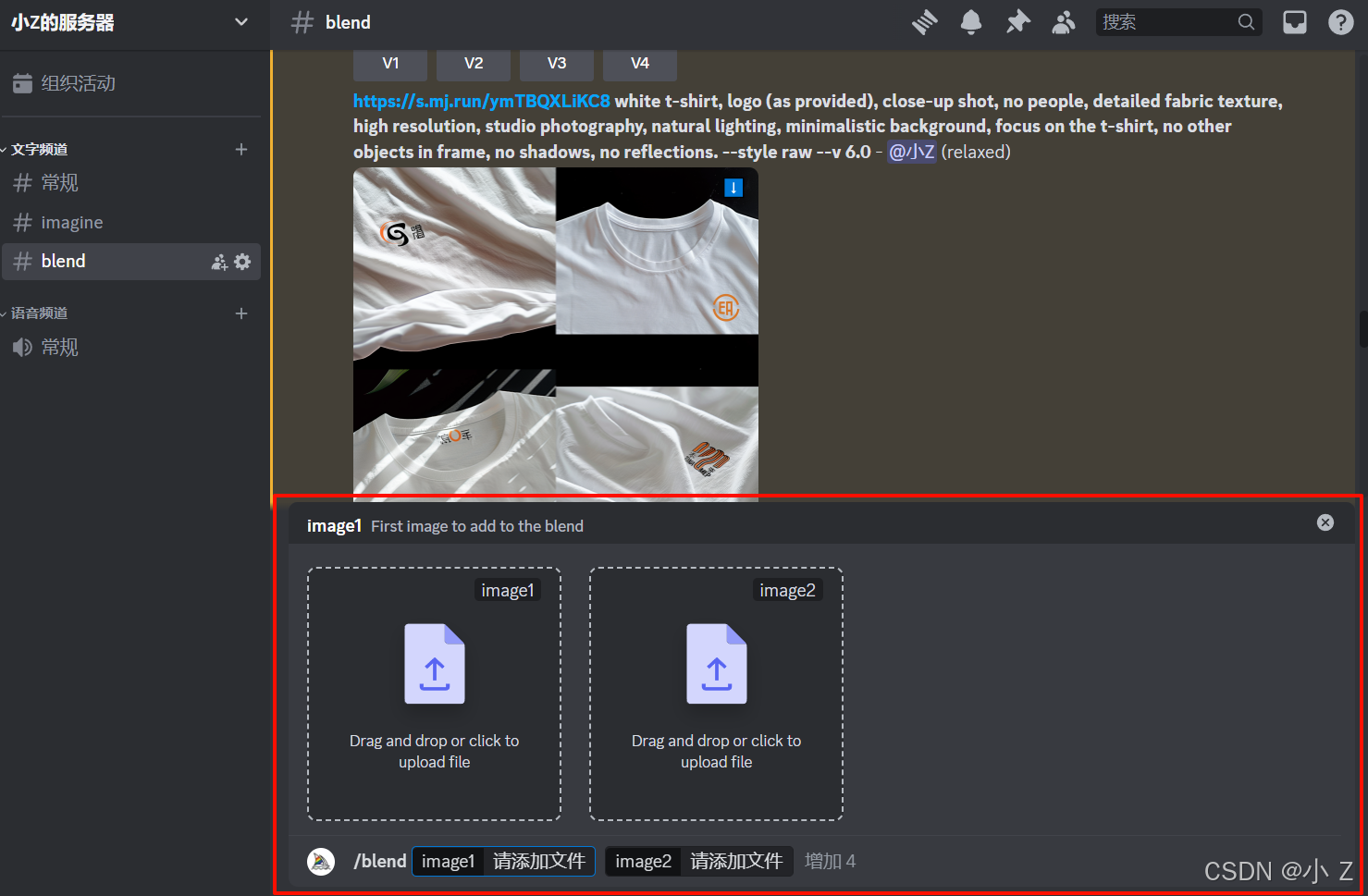
混合模式基本使用
- 这里是下文使用到的两张素材图:


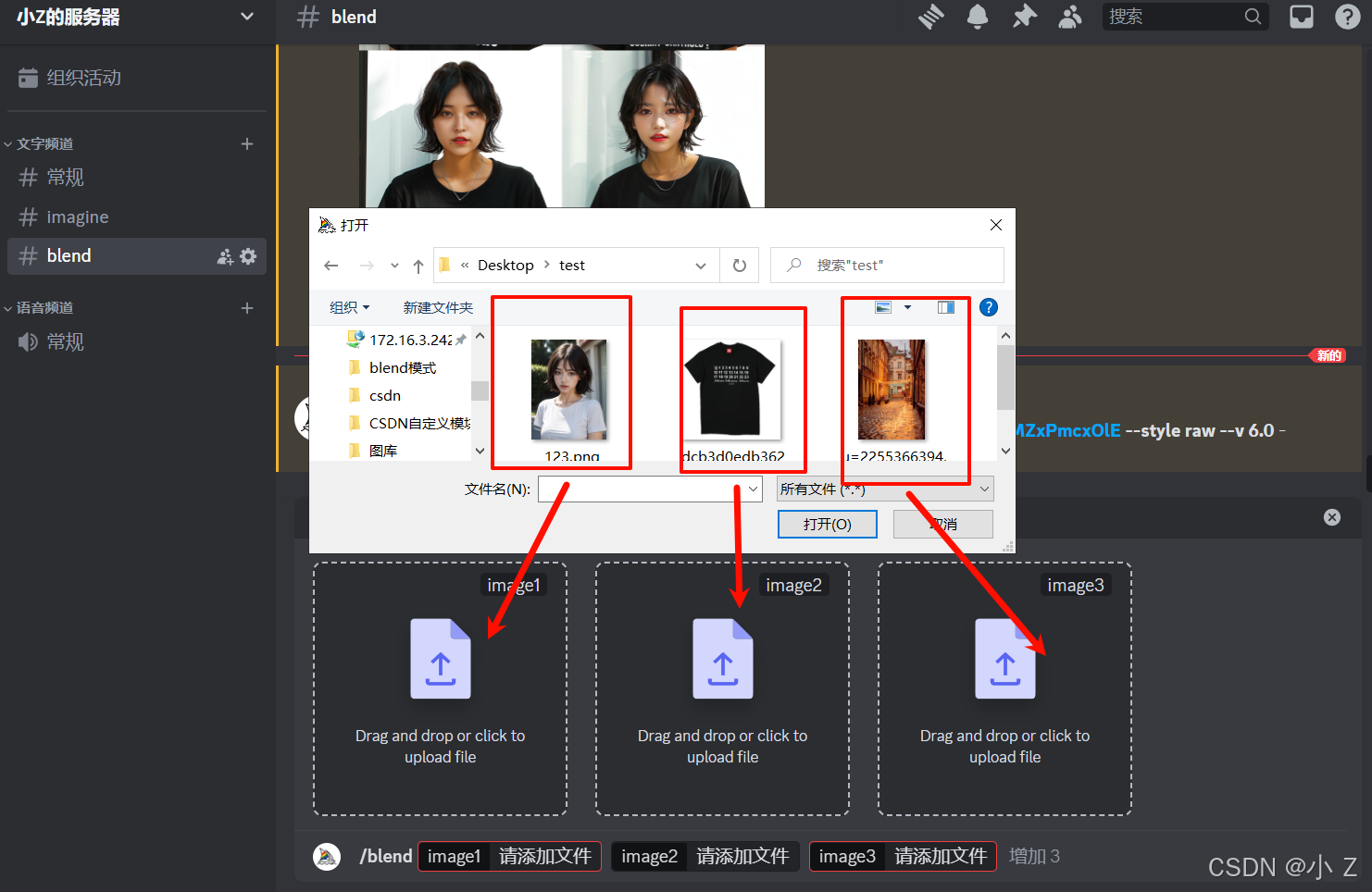
- 通过使用/blend命令进入混合模式后,我们可以直接从本地上传两张图片(这与/imagine模式有所不同,/imagine引用图片需要提供图片的在线地址,而/blend则支持本地图片的上传)。
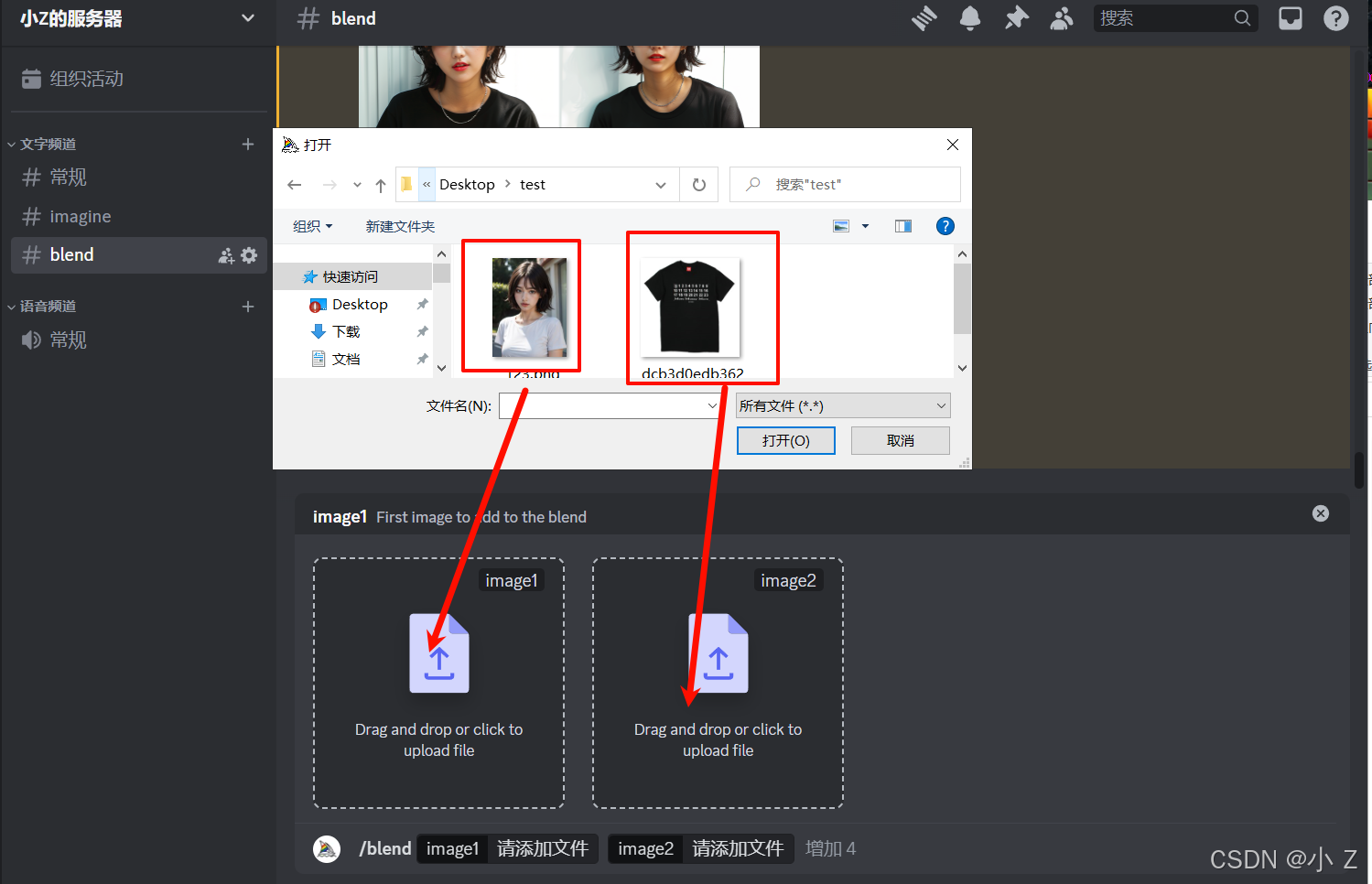
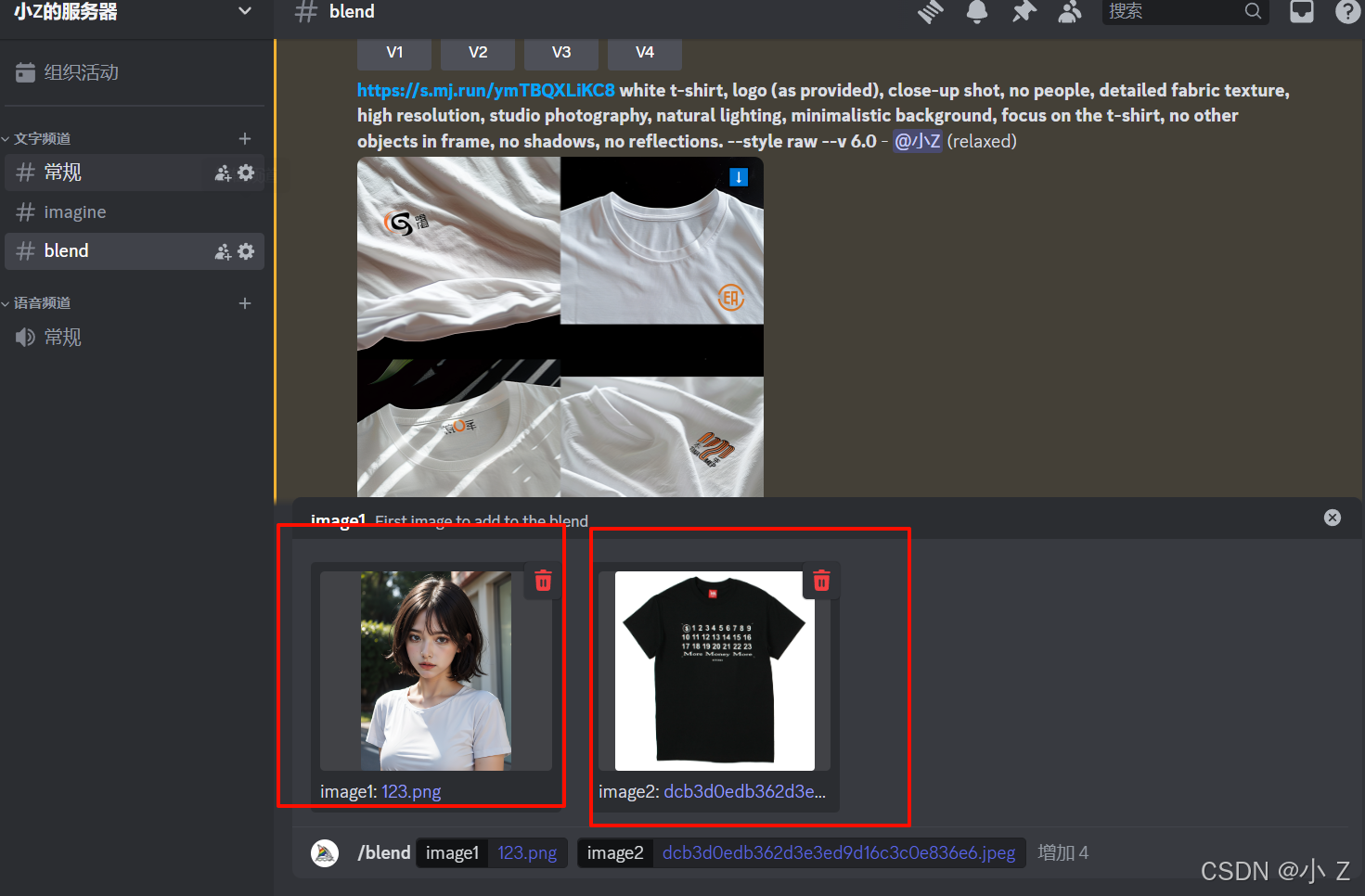
- 在这张图中,我们可以看到生成的是一位短发女孩的正面照,占据了画面的大部分。她穿着一件黑色T恤,T恤的前面有一连串的数字。通过/blend命令生成的图片将两张图片的特征融合在一起,因此这张图片同时包含了这两张图片的主要元素。女孩的脸型和短发特征明显,但由于AI算法的限制,脸部和T恤上的数字并未被完全还原。然而,正如我们之前提到的,AI通过融合概念和美学特征生成了这张新的图片。这就像是使用搅拌机混合不同材料,最终得到的就是这种效果。
新增图片槽位
- 正如我们之前提到的,/blend命令可以上传2到5张图片。在初始界面中,我们看到默认有2个图片槽位。如果你想添加新的图片槽位,可以通过将鼠标单击后面的空白区域来实现。这样就可以为更多图片的上传预留位置,进一步丰富混合效果。
- 我们这里再多新增一张背景图做测试,看看这三张图会如何融合。

- 和前面一样的步骤,在/blend模式下将图片上传
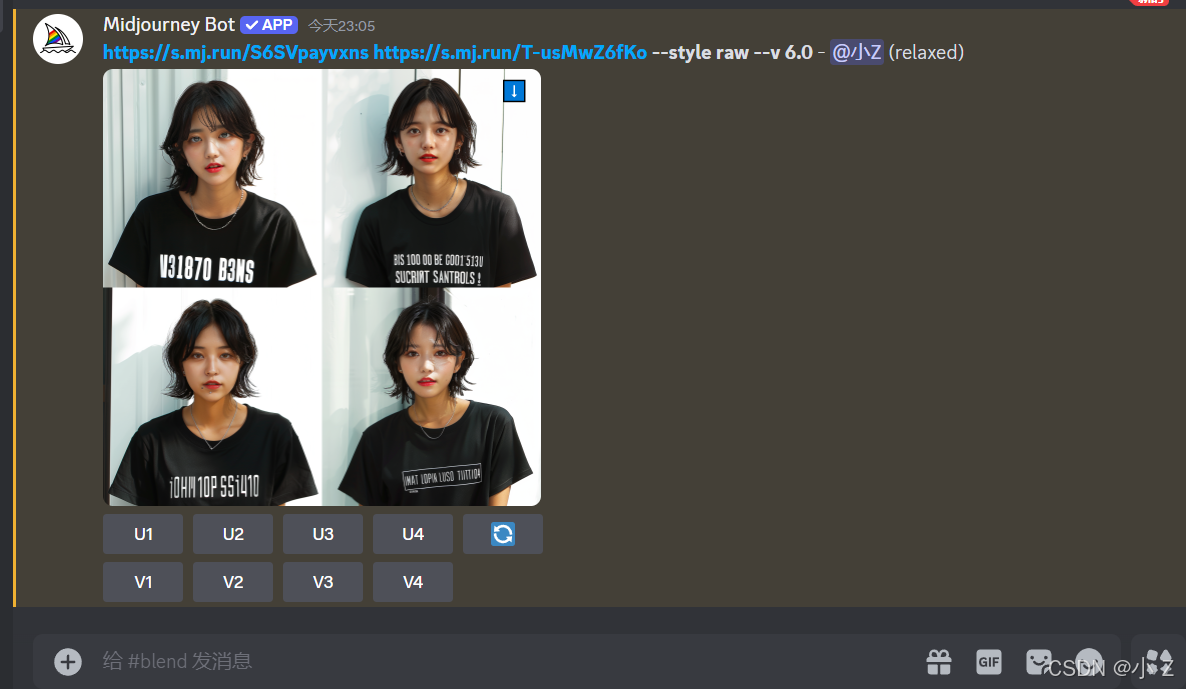
- 在最终的结果中,我们可以看到上传的三张图片的元素都得到了体现:一位身着黑色T恤的短发女孩站在街上。然而,生成的四张图中,只有第二张的效果相对较好,其他几张图中的黑色T恤上的数字似乎并没有很好地融入衣服的图层中,显得像是浮在表面,而不是衣服自带的设计。
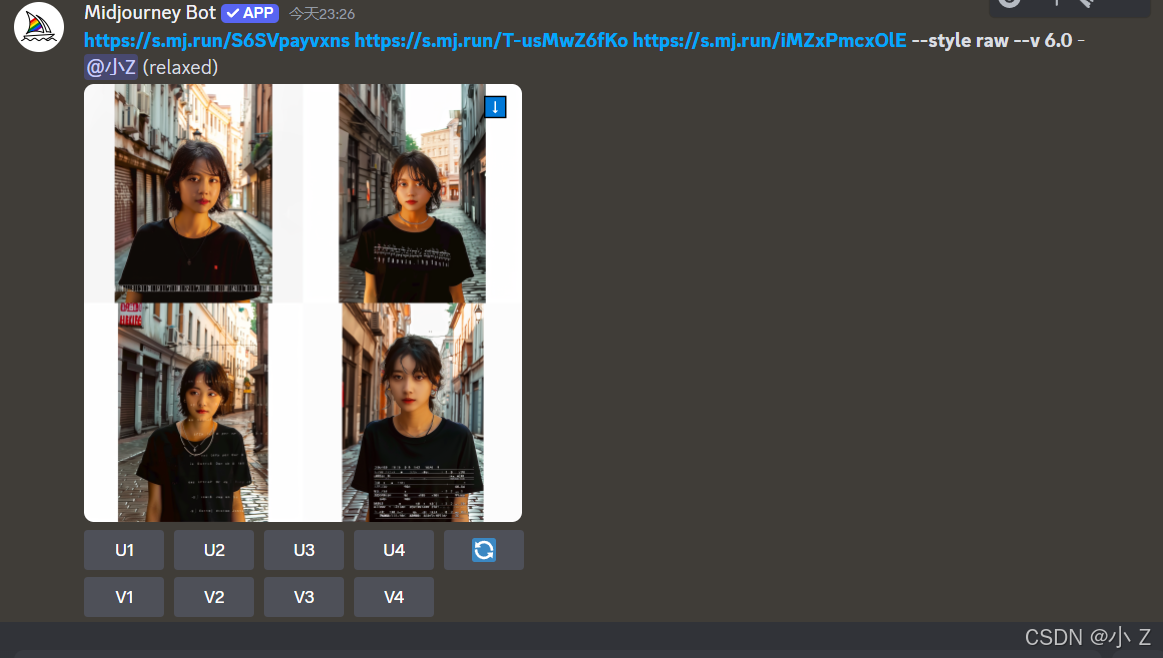
- 在生成的图片中我们发现有些还特征它融到一起去了。比如说这个光线把人的脸部渲染的一侧被阳光照射的效果,这正是混合模式下带来的不确定性。
- 这种不确定性有时是一个优点,有时却可能是缺点。优点在于它能够为画面增添创意性,带来意想不到的效果;但缺点在于你无法完全控制AI最终生成的图片会以何种方式进行混合。因为在混合过程中,AI需要综合考虑多个维度,包括形状、颜色和内容概念等,这些都可能影响最终的效果。
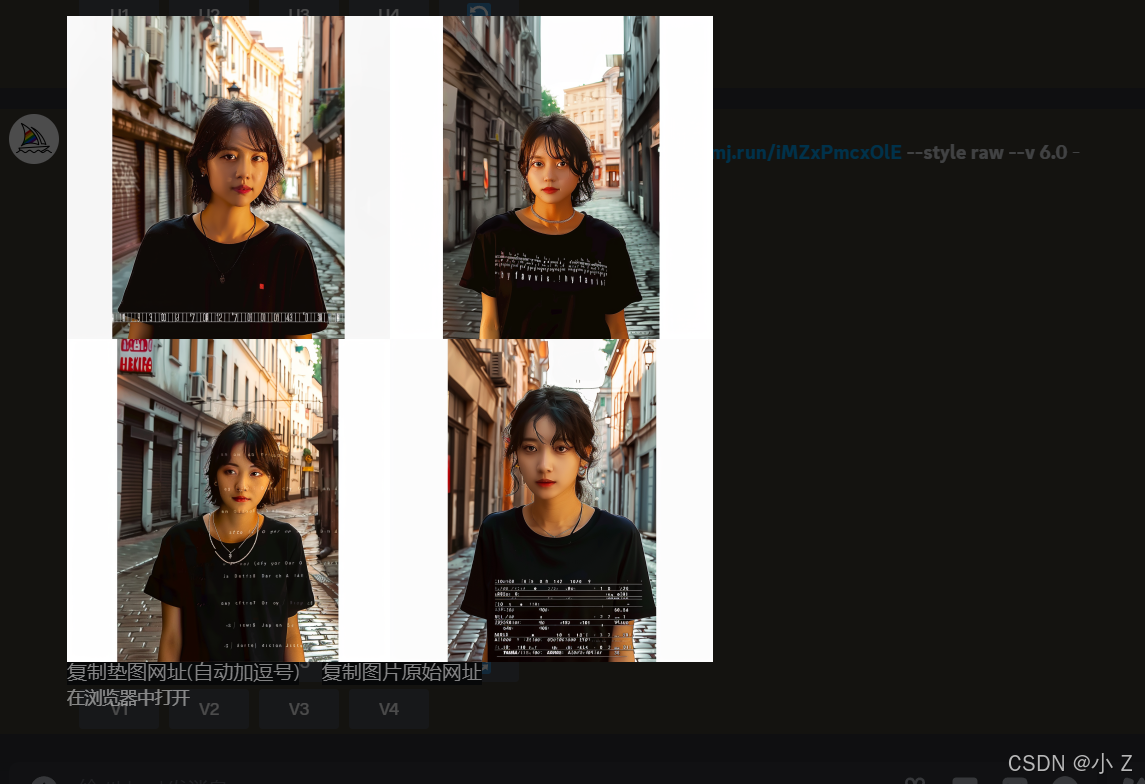
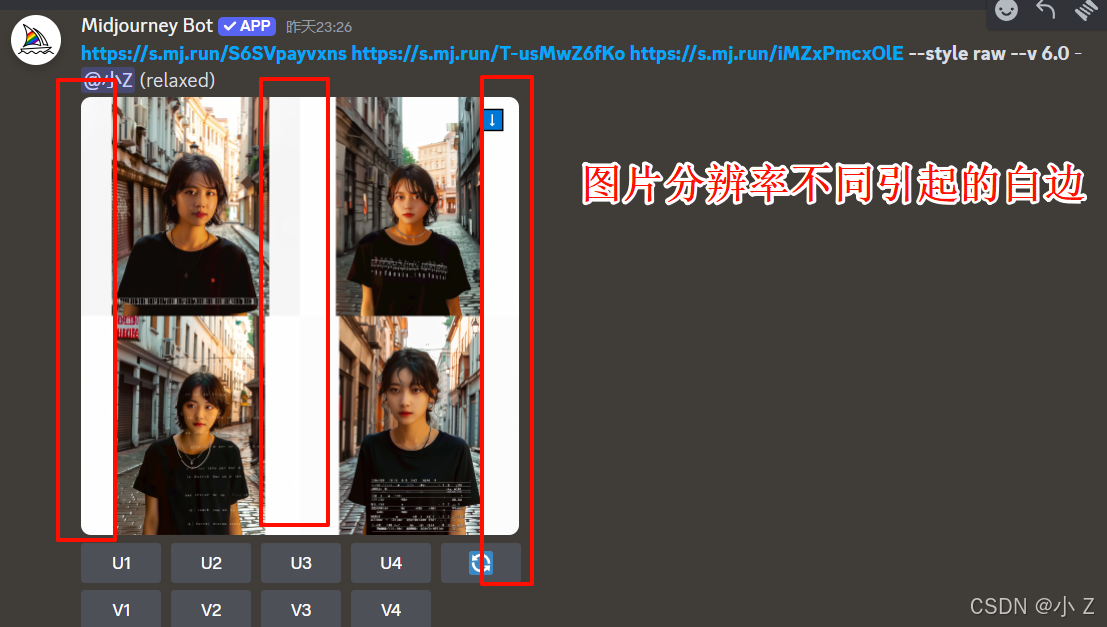
- 我们还注意到,生成的图片中出现了巨大的白边,这在我们之前使用/imagine命令生成的图片中并未遇到过。出现这种情况的主要原因是我们所提供的三张图片的分辨率不同,如果我们没有一开始设定生成图片的分辨率,Midjourney在处理这些图像时未能很好地协调融合后的分辨率,因此空白部分就显示为白色。
- 那么我们可以通过什么避免Midjourney生成多余的白边呢,接下来的生成图片的尺寸设置可以很好的解决这个问题。
选择生成图片的尺寸
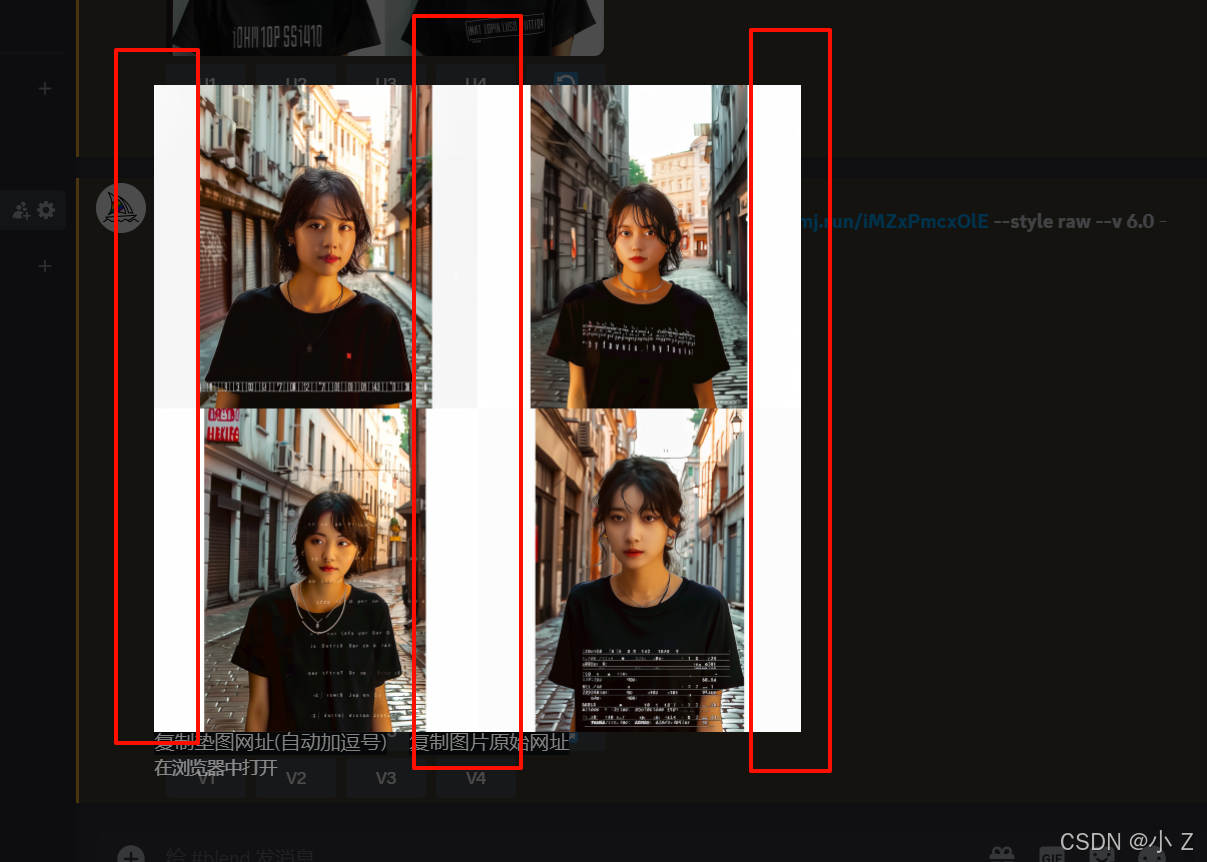
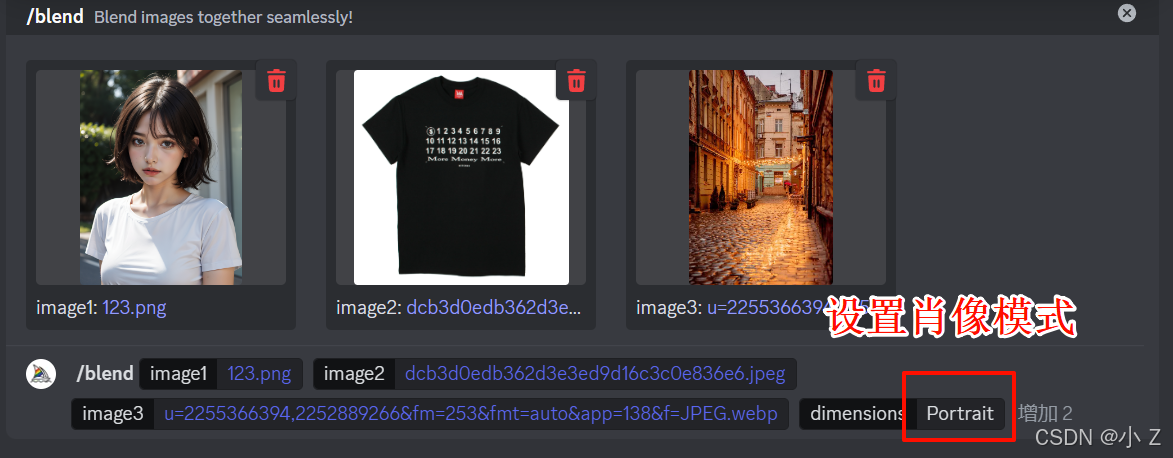
- 通过上述测试,我们发现除了可以新增图片槽位image外,还可以添加一个名为“dimensions”的选项。
- “dimensions”选项用于设置生成图片的尺寸和比例。通过调整这个参数,可以更精确地控制最终图片的分辨率和画面比例,通过这一选项我们规定了最终图片的分辨率,这样Midjourney就不会出现因为所提供的图片分辨率不同而导致生成的图片有白边的情况了
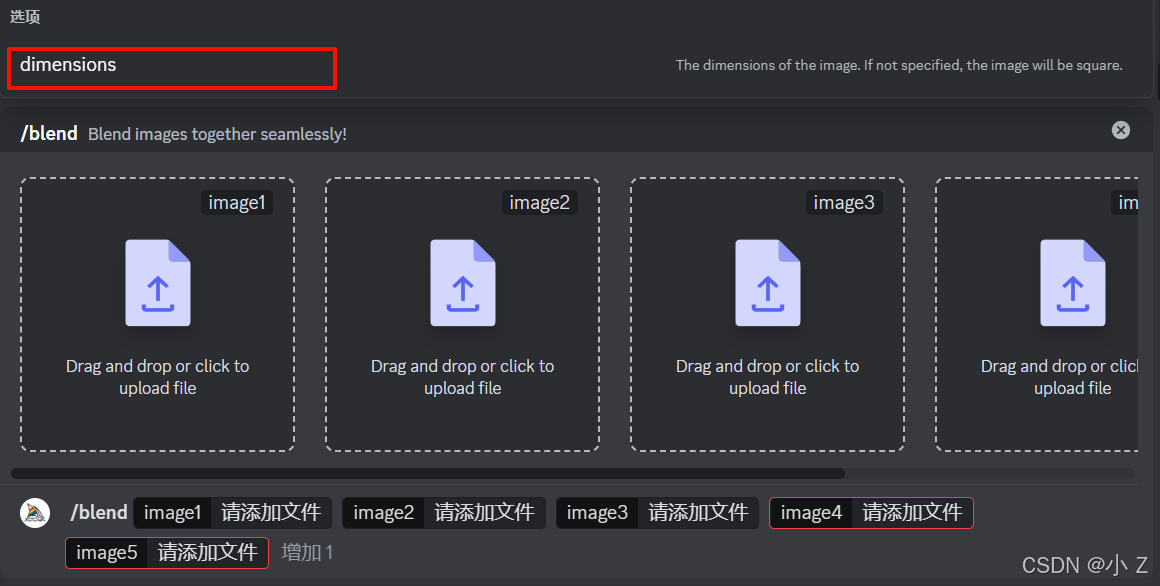
- 选中dimensions后我们发现有三个选项可供选择。分别是Portrait、Square、Landscape。
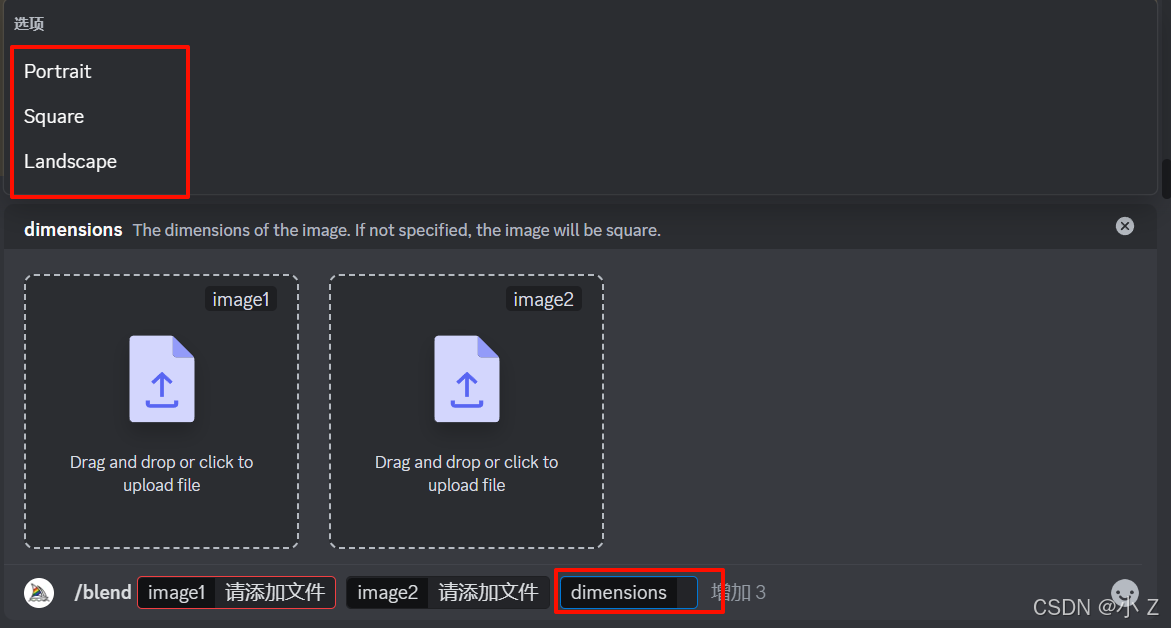
- 目前来看,“dimensions”选项并不像我们熟悉的/imagine设置的后置指令“--ar”那样,可以自由地选择和设置分辨率。它只提供了三个固定的选项供你选择:protrait的中文名是肖像的意思,最后他指定这个搅拌出来的图片比例是2比3,square是正方形的意思,最后他会指定生成出来的图片是1比1的比例。 landscape是风景的意思,最后他会让生成出来图片大概保持在3比2的比。

模式 | 特点 | 分辨率 |
|---|---|---|
protrait | 竖屏模式,适合用于垂直方向较长的图片,如人物半身照或竖幅风景图。 | 2:3 |
square | 形模式,适合生成正方形图片,这种比例在社交媒体平台上很常见,适用于各种内容的均衡展示。 | 1:1 |
landscape | 屏模式,适合用于水平方向较长的图片,如全景风景图或宽幅的场景图。 | 3:2 |
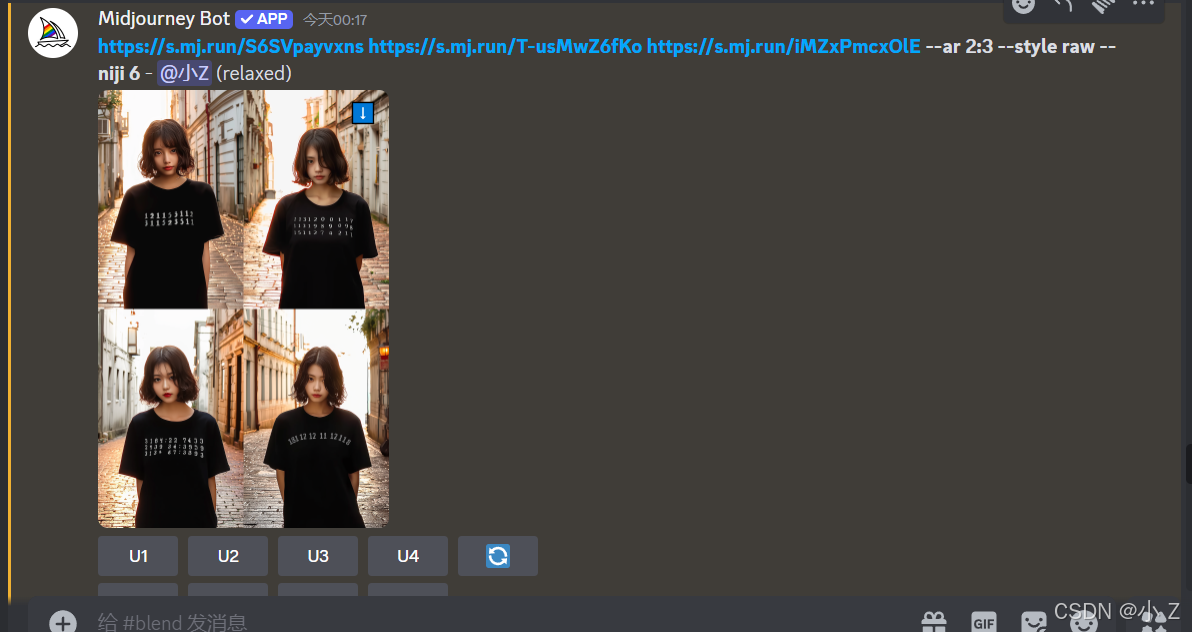
- 鉴于我们之前遇到的情况,选择“肖像”(Portrait)设置会更适合当前的需求。这个设置将生成一张比例为2:3的图片,更好地避免之前遇到的白边问题。
- 开启肖像模式后,分辨率2:3,成功消除了白边的影响,使得图片更美观。
/blend使用注意事项
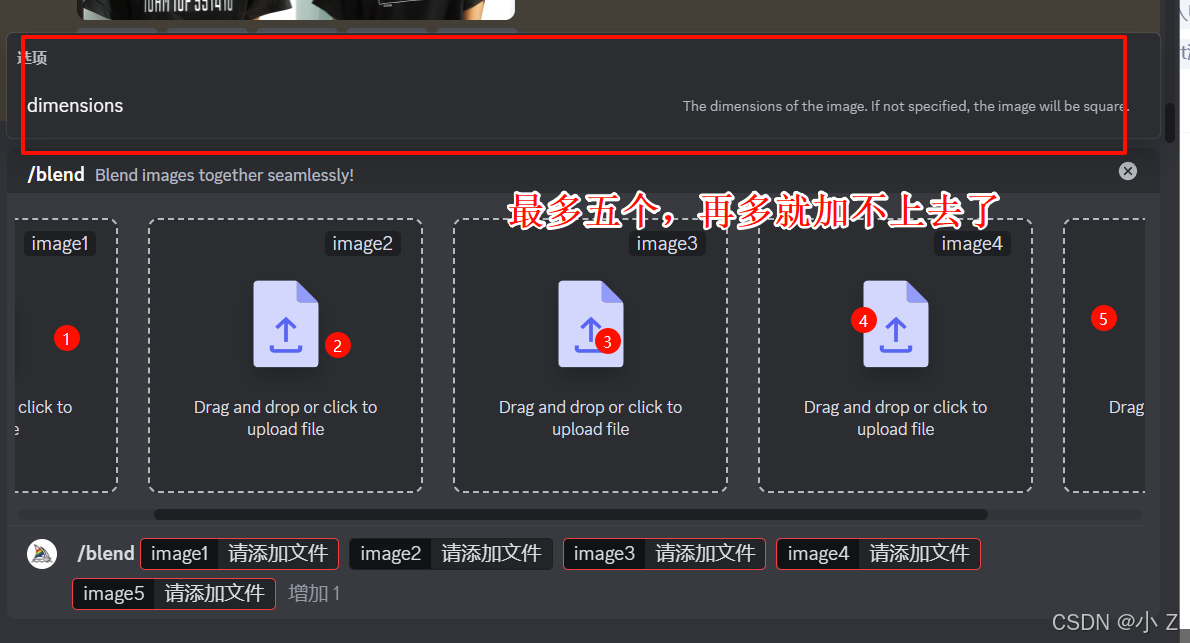
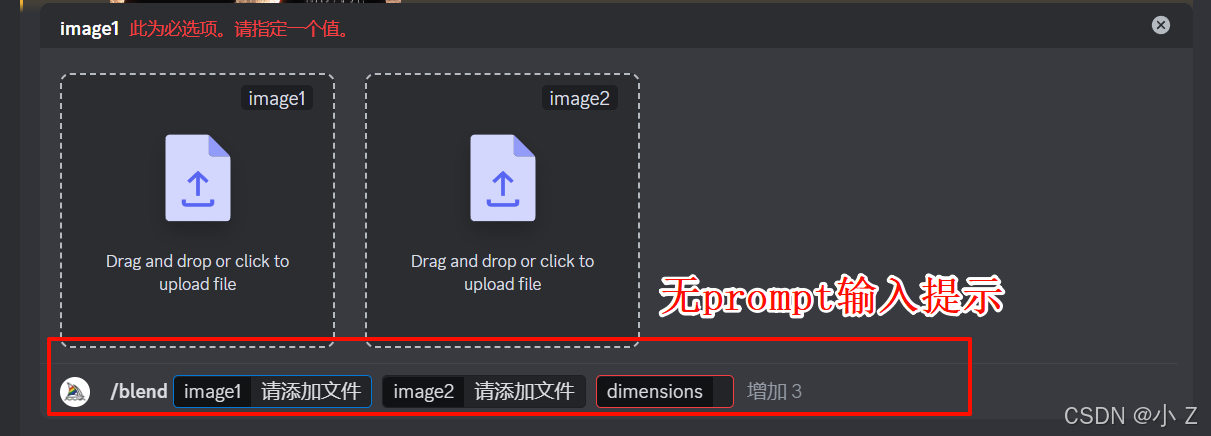
- /blend只能混合图片,不能添加文本提示词。
- 上传图片尺寸有要求,最好与生成的结果尺寸一致。否则容易出现白边
- 最多只能上传五张图片。如果需要使用超过五张图片混合,使用/imagine命令图生图。
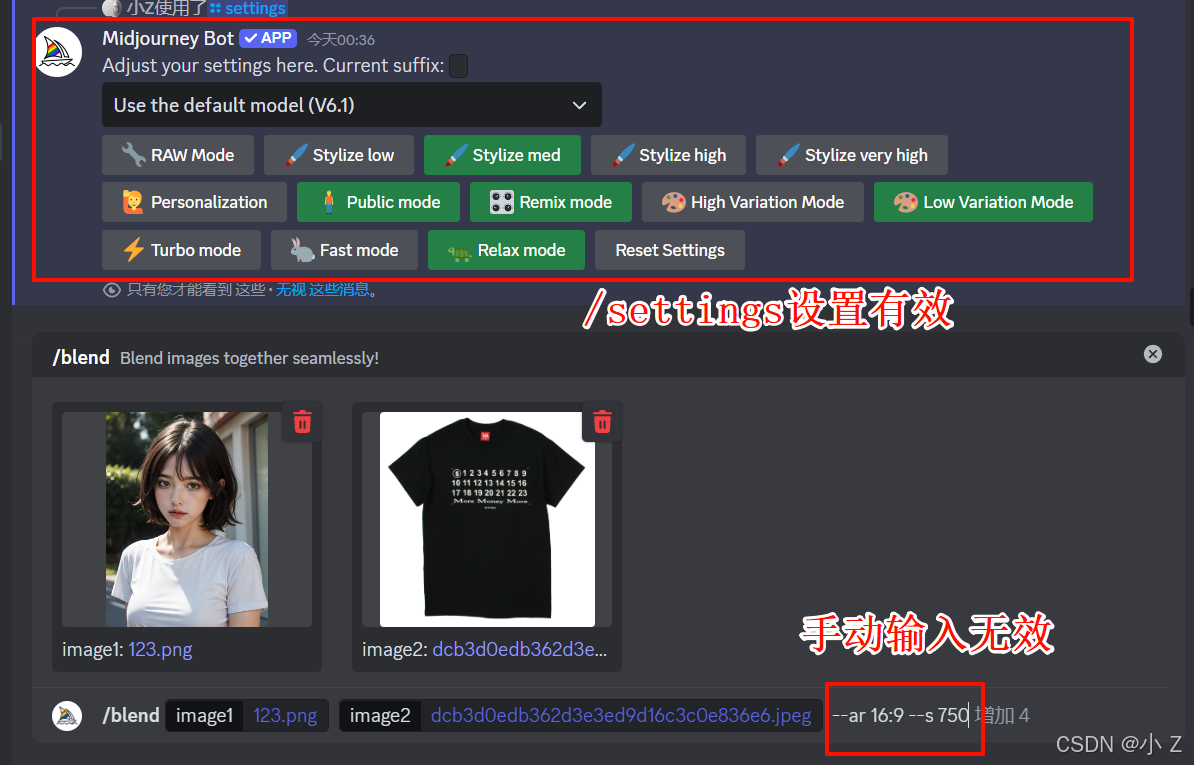
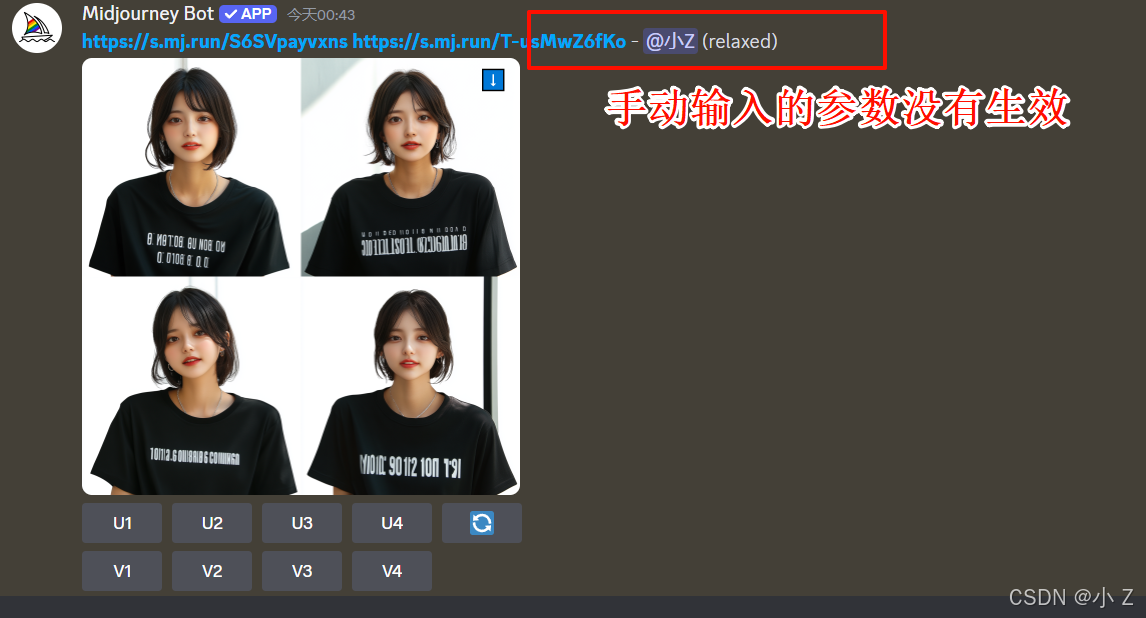
- /setting里以及其他自定义的尾缀在/blend里依然有效,但无法主动设置
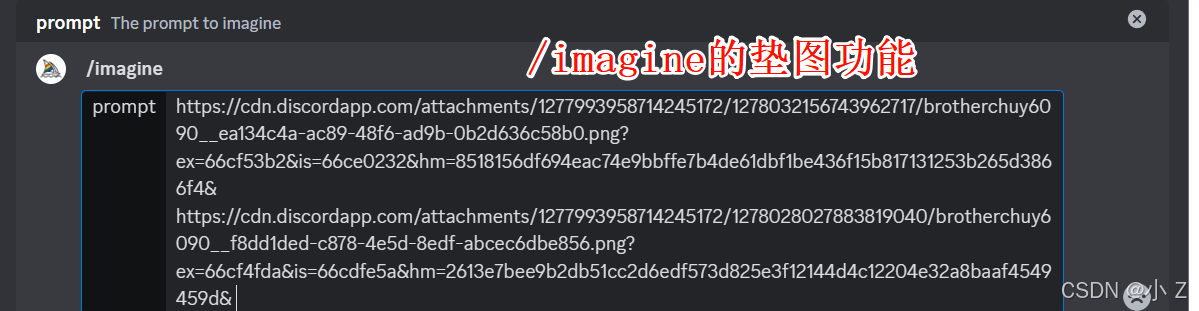
- 绝大多数情况下,我们用/imagine实现垫图生图
💯账户管理相关的前置指令(与生图效果无关)
- 在 Midjourney 的使用过程中,如何进行账户信息的管理也很重要。通过一些便捷的前置指令,例如:/info、/subscribe你可以快速获取账号的状态、订阅详情等关键数据。这些指令不会影响图像生成的效果,但能够帮助你有效管理账户,保证创作体验。
- Midjourney官方使用手册
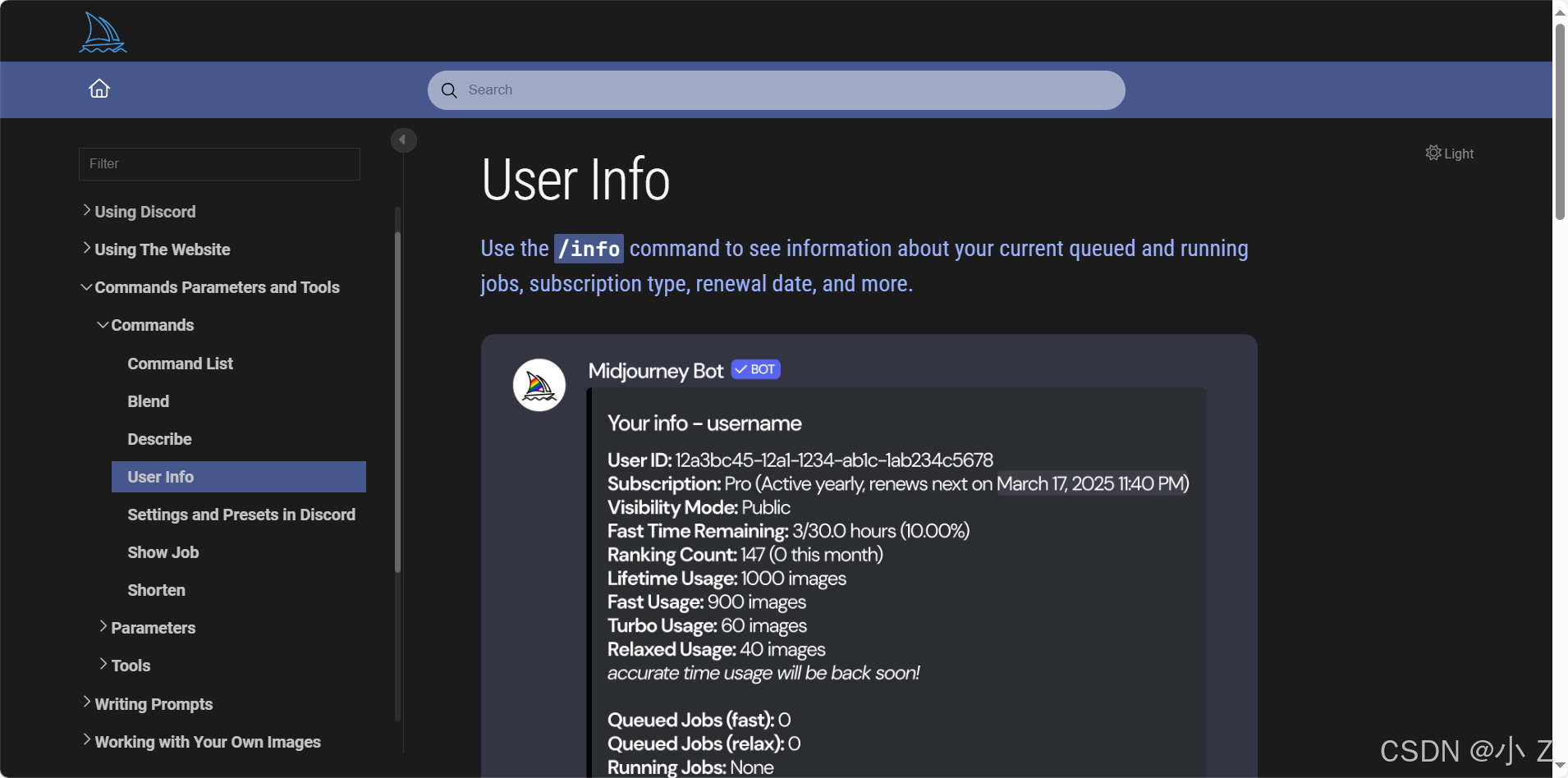
Midjourney前置指令/info
- /info 命令获取与账号相关的重要信息。这些信息包括用户的 ID、当前订阅状态、生成图像的模式、以及快速生成时间的剩余情况。
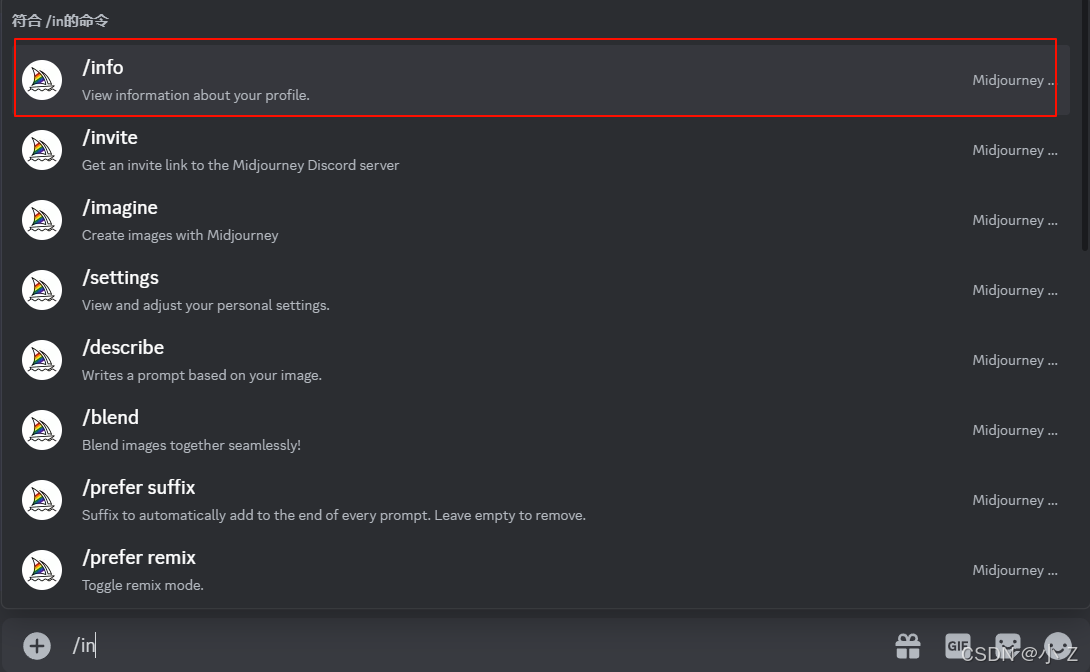
- 另外,系统还会显示用户已经生成的图像数量,分别在快速模式和放松模式下的统计数据。最值得关注的两项内容是快速生成时间的剩余百分比和订阅续订的时间。这些信息可以帮助用户更好地管理和规划自己的图像生成任务。
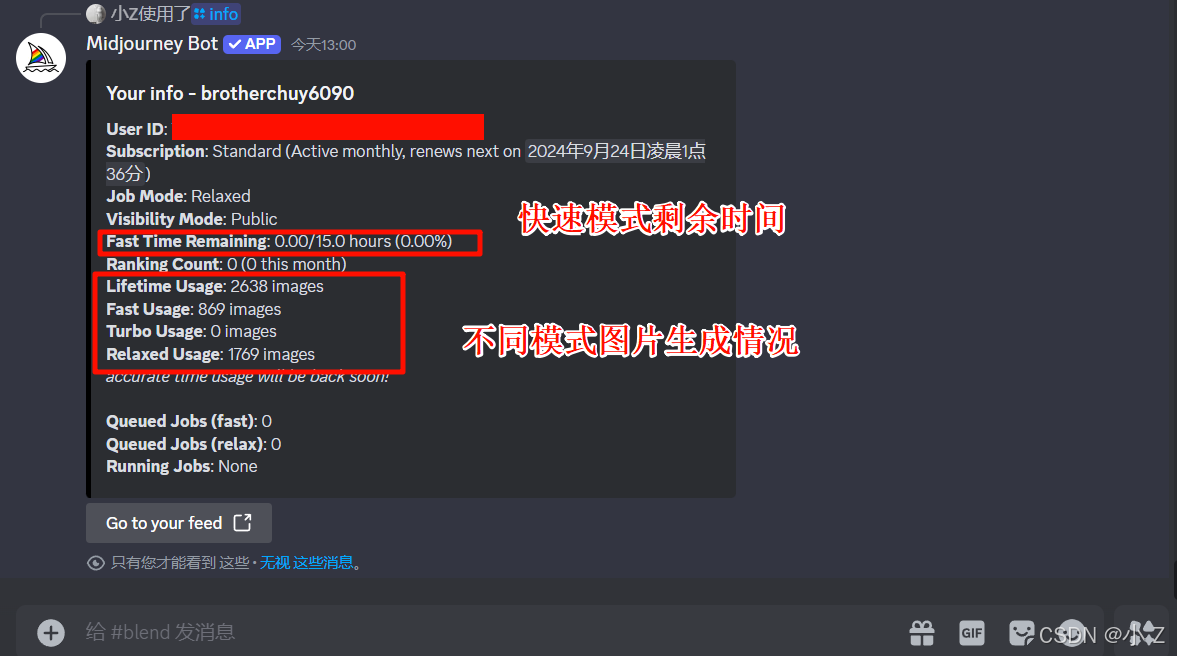
- /info 命令主要用于查看账户的相关信息,与实际图像的生成过程无直接关系。它帮助用户了解账户状态,但并不影响或参与图像生成的操作。
Midjourney前置指令/subscrib
- /subscribe 是 Midjourney 的一个付费功能。通过点击这个命令,你可以管理账号的订阅状态。
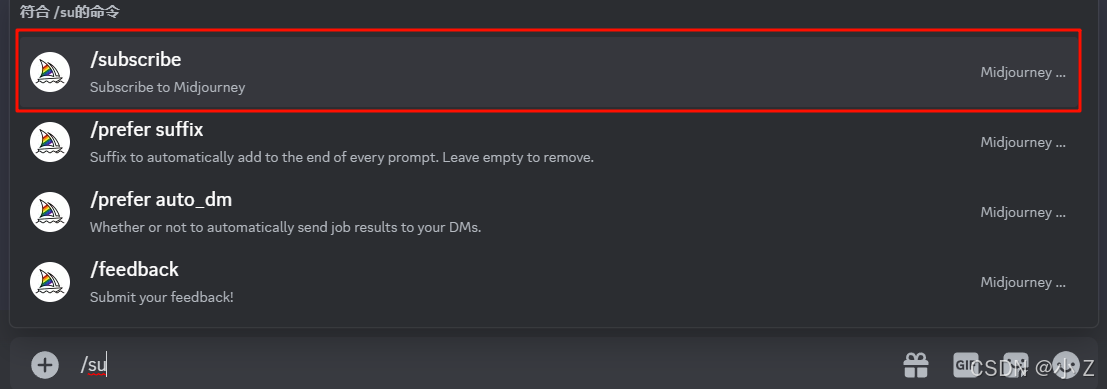
- 点击后会弹出一个界面,在这个界面里你可以选择并购买相应的会员服务,以便解锁更多功能和特权。
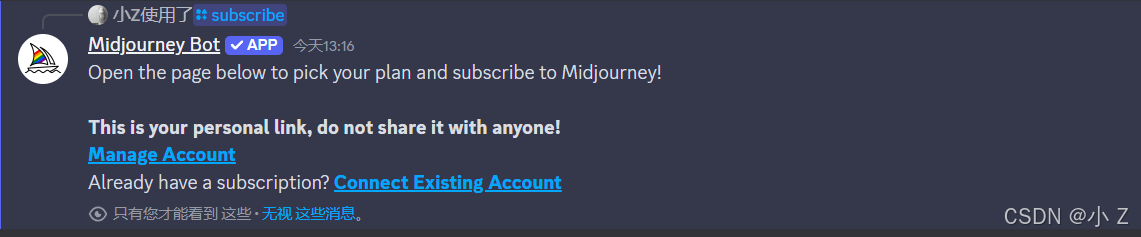
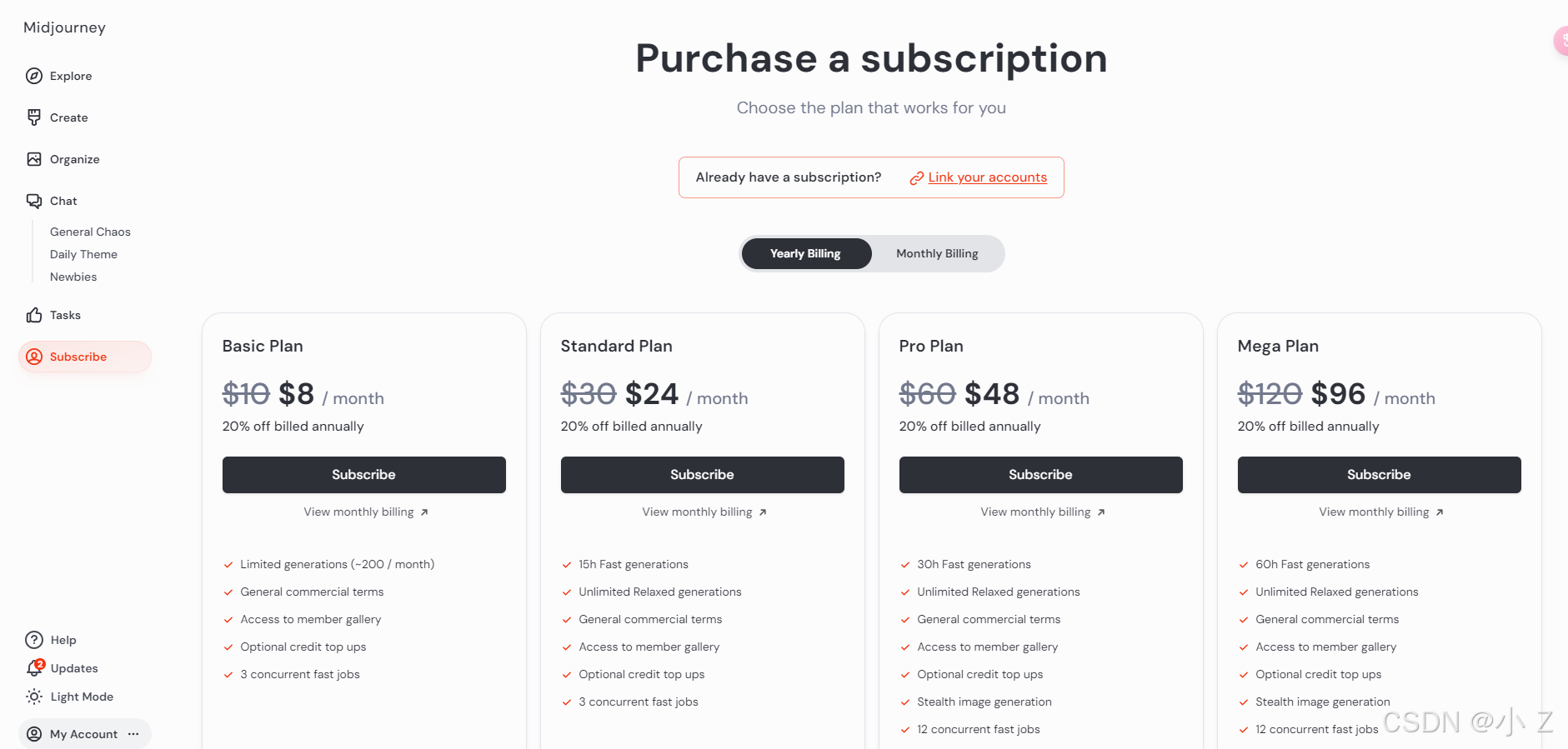
- 总结来说,/subscribe 指令主要用于管理和购买 Midjourney 的订阅服务,与图像生成的参数设置无关。
💯小结
本文主要介绍了 Midjourney 的几个关键前置指令,包括 /blend、/info 和 /subscribe。通过对这些指令的深入了解,相信读者能够更好地使用Midjourney 平台的功能,从而提升创作效率与生图效果。
- 展望未来,AI 绘画不仅为艺术创作带来了全新的可能性,还在不断推动艺术与技术的深度融合。AI 通过独特的算法和强大的计算能力,能够迅速生成富有创意的图像,这为艺术家和设计师提供了前所未有的工具和灵感。同时,随着 AI 技术的进步,我们可以预见,未来的艺术创作将更加智能化、多样化,AI 将成为人类创意的强大助手,为艺术的表达方式带来更多革新。
- AI 绘画的意义不仅在于它的技术层面,更在于它对艺术表达和创意实现的无限可能。它让更多人能够参与到艺术创作中,同时也在不断挑战和扩展传统艺术的边界。未来,AI 绘画将继续在艺术领域发挥重要作用,助力艺术家们探索新的创作空间,推动艺术的发展迈向更广阔的天地。
/*
* 提示:该行代码过长,系统自动注释不进行高亮。一键复制会移除系统注释
* import torch, torch.nn as nn, torch.optim as optim; from torch.utils.data import Dataset, DataLoader; from torchvision import transforms, utils; from PIL import Image; import numpy as np, cv2, os, random; class PaintingDataset(Dataset): def __init__(self, root_dir, transform=None): self.root_dir = root_dir; self.transform = transform; self.image_files = os.listdir(root_dir); def __len__(self): return len(self.image_files); def __getitem__(self, idx): img_name = os.path.join(self.root_dir, self.image_files[idx]); image = Image.open(img_name).convert('RGB'); if self.transform: image = self.transform(image); return image; class ResidualBlock(nn.Module): def __init__(self, in_channels): super(ResidualBlock, self).__init__(); self.conv_block = nn.Sequential(nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1), nn.InstanceNorm2d(in_channels), nn.ReLU(inplace=True), nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1), nn.InstanceNorm2d(in_channels)); def forward(self, x): return x + self.conv_block(x); class Generator(nn.Module): def __init__(self): super(Generator, self).__init__(); self.downsampling = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=1, padding=3), nn.InstanceNorm2d(64), nn.ReLU(inplace=True), nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), nn.InstanceNorm2d(128), nn.ReLU(inplace=True), nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1), nn.InstanceNorm2d(256), nn.ReLU(inplace=True)); self.residuals = nn.Sequential(*[ResidualBlock(256) for _ in range(9)]); self.upsampling = nn.Sequential(nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1), nn.InstanceNorm2d(128), nn.ReLU(inplace=True), nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1), nn.InstanceNorm2d(64), nn.ReLU(inplace=True), nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=3), nn.Tanh()); def forward(self, x): x = self.downsampling(x); x = self.residuals(x); x = self.upsampling(x); return x; class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__(); self.model = nn.Sequential(nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), nn.InstanceNorm2d(128), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), nn.InstanceNorm2d(256), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1), nn.InstanceNorm2d(512), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=1)); def forward(self, x): return self.model(x); def initialize_weights(model): for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)): nn.init.normal_(m.weight.data, 0.0, 0.02); elif isinstance(m, nn.InstanceNorm2d): nn.init.normal_(m.weight.data, 1.0, 0.02); nn.init.constant_(m.bias.data, 0); device = torch.device("cuda" if torch.cuda.is_available() else "cpu"); generator = Generator().to(device); discriminator = Discriminator().to(device); initialize_weights(generator); initialize_weights(discriminator); transform = transforms.Compose([transforms.Resize(256), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]); dataset = PaintingDataset(root_dir='path_to_paintings', transform=transform); dataloader = DataLoader(dataset, batch_size=16, shuffle=True); criterion = nn.MSELoss(); optimizerG = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999)); optimizerD = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999)); def generate_noise_image(height, width): return torch.randn(1, 3, height, width, device=device); for epoch in range(100): for i, data in enumerate(dataloader): real_images = data.to(device); batch_size = real_images.size(0); optimizerD.zero_grad(); noise_image = generate_noise_image(256, 256); fake_images = generator(noise_image); real_labels = torch.ones(batch_size, 1, 16, 16, device=device); fake_labels = torch.zeros(batch_size, 1, 16, 16, device=device); output_real = discriminator(real_images); output_fake = discriminator(fake_images.detach()); loss_real = criterion(output_real, real_labels); loss_fake = criterion(output_fake, fake_labels); lossD = (loss_real + loss_fake) / 2; lossD.backward(); optimizerD.step(); optimizerG.zero_grad(); output_fake = discriminator(fake_images); lossG = criterion(output_fake, real_labels); lossG.backward(); optimizerG.step(); with torch.no_grad(): fake_image = generator(generate_noise_image(256, 256)).detach().cpu(); grid = utils.make_grid(fake_image, normalize=True); utils.save_image(grid, f'output/fake_painting_epoch_{epoch}.png'); def apply_style_transfer(content_img, style_img, output_img, num_steps=500, style_weight=1000000, content_weight=1): vgg = models.vgg19(pretrained=True).features.to(device).eval(); for param in vgg.parameters(): param.requires_grad = False; content_img = Image.open(content_img).convert('RGB'); style_img = Image.open(style_img).convert('RGB'); content_img = transform(content_img).unsqueeze(0).to(device); style_img = transform(style_img).unsqueeze(0).to(device); target = content_img.clone().requires_grad_(True).to(device); optimizer = optim.LBFGS([target]); content_layers = ['conv_4']; style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']; def get_features(image, model): layers = {'0': 'conv_1', '5': 'conv_2', '10': 'conv_3', '19': 'conv_4', '28': 'conv_5'}; features = {}; x = image; for name, layer in model._modules.items(): x = layer(x); if name in layers: features[layers[name]] = x; return features; def gram_matrix(tensor): _, d, h, w = tensor.size(); tensor = tensor.view(d, h * w); gram = torch.mm(tensor, tensor.t()); return gram; content_features = get_features(content_img, vgg); style_features = get_features(style_img, vgg); style_grams = {layer: gram_matrix(style_features[layer]) for layer in style_features}; for step in range(num_steps): def closure(): target_features = get_features(target, vgg); content_loss = torch.mean((target_features[content_layers[0]] - content_features[content_layers[0]])**2); style_loss = 0; for layer in style_layers: target_gram = gram_matrix(target_features[layer]); style_gram = style_grams[layer]; layer_style_loss = torch.mean((target_gram - style_gram)**2); style_loss += layer_style_loss / (target_gram.shape[1] ** 2); total_loss = content_weight * content_loss + style_weight * style_loss; optimizer.zero_grad(); total_loss.backward(); return total_loss; optimizer.step(closure); target = target.squeeze().cpu().clamp_(0, 1); utils.save_image(target, output_img);
*/本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号