YOLO11-seg分割:原创自研 | 自研独家创新DSAM注意力 ,基于BiLevelRoutingAttention注意力升级
原创
YOLO11-seg分割:原创自研 | 自研独家创新DSAM注意力 ,基于BiLevelRoutingAttention注意力升级
原创
AI小怪兽
发布于 2024-10-22 13:07:11
发布于 2024-10-22 13:07:11
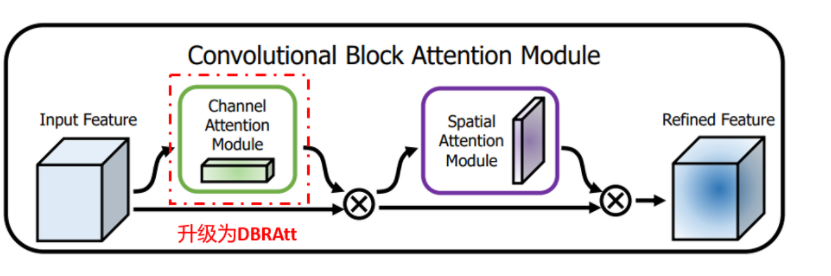
💡💡💡本文原创自研改进:提出新颖的注意力DSAM(Deformable Bi-level Spatial Attention Module),创新度极佳,适合科研创新,效果秒杀CBAM,Channel Attention+Spartial Attention升级为新颖的 Deformable Bi-level Attention+Spartial Attention
💡💡💡BRA注意力问题点:由可变形点选择的键值对缺乏语义相关性。BiFormer中的查询感知稀疏注意力旨在让每个查询聚焦于top-k路由区域。然而,在计算注意力时,选定的键值对受到太多无关查询的影响,减弱了对更重要查询的注意力。
💡💡💡本文改进:DSAM结合C2PSA进行二次创新;
💡💡💡Mask mAP50 从原始的0.673 提升至0.677
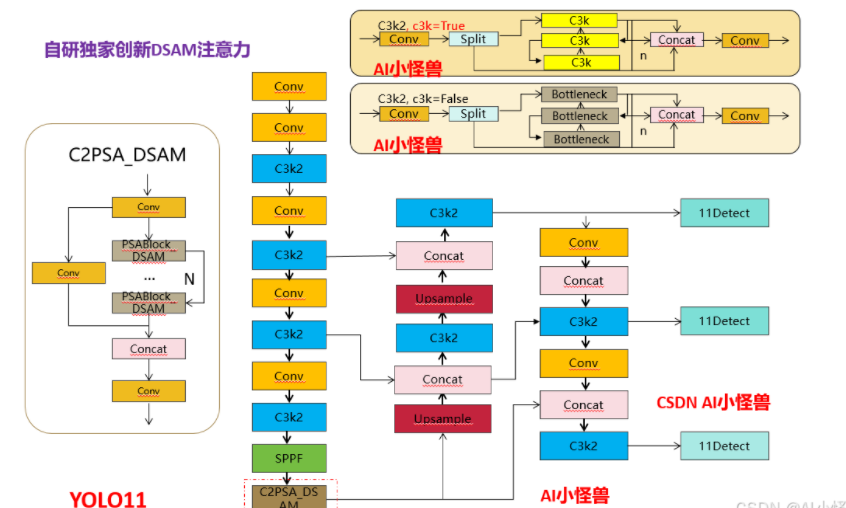
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。
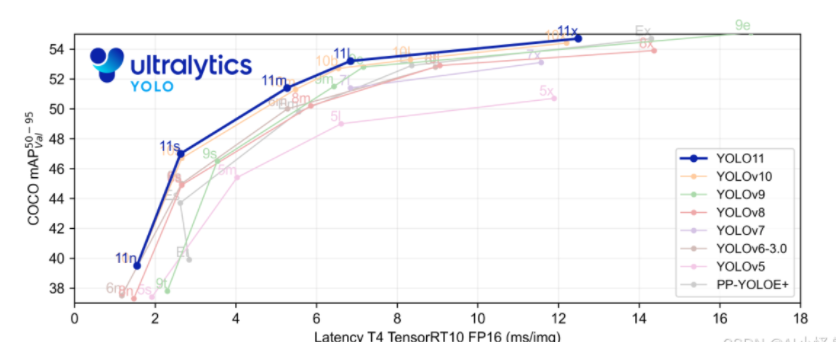

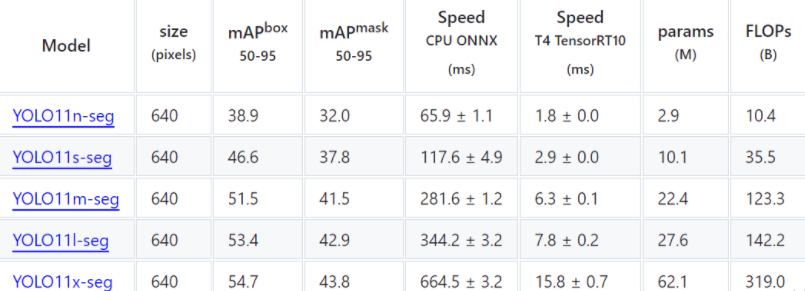
Segmentation 官方在COCO数据集上做了更多测试:
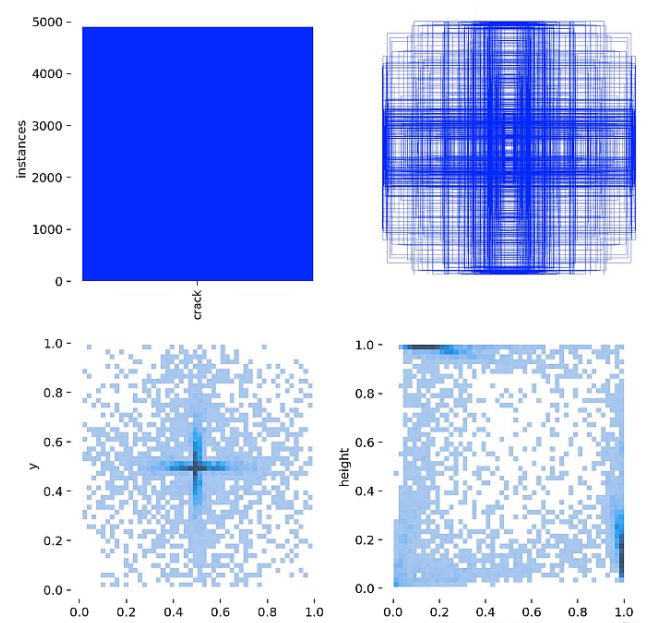
2.数据集介绍
道路裂纹分割数据集是一个全面的4029张静态图像集合,专门为交通和公共安全研究而设计。它非常适合自动驾驶汽车模型开发和基础设施维护等任务。该数据集包括训练、测试和验证集,有助于精确的裂缝检测和分割。
训练集3712张,验证集200张,测试集112张

标签可视化:
3.如何训练YOLO11-seg模型
3.1 修改 crack-seg.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Crack-seg dataset by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/segment/crack-seg/
# Example usage: yolo train data=crack-seg.yaml
# parent
# ├── ultralytics
# └── datasets
# └── crack-seg ← downloads here (91.2 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/ultralytics-seg/data/crack-seg # dataset root dir
train: train/images # train images (relative to 'path') 3717 images
val: valid/images # val images (relative to 'path') 112 images
test: test/images # test images (relative to 'path') 200 images
# Classes
names:
0: crack3.2 如何开启训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11-seg.yaml')
#model.load('yolov8n.pt') # loading pretrain weights
model.train(data='data/crack-seg.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)3.3 训练结果可视化
YOLO11-seg summary (fused): 265 layers, 2,834,763 parameters, 0 gradients, 10.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 7/7 [00:07<00:00, 1.06s/it]
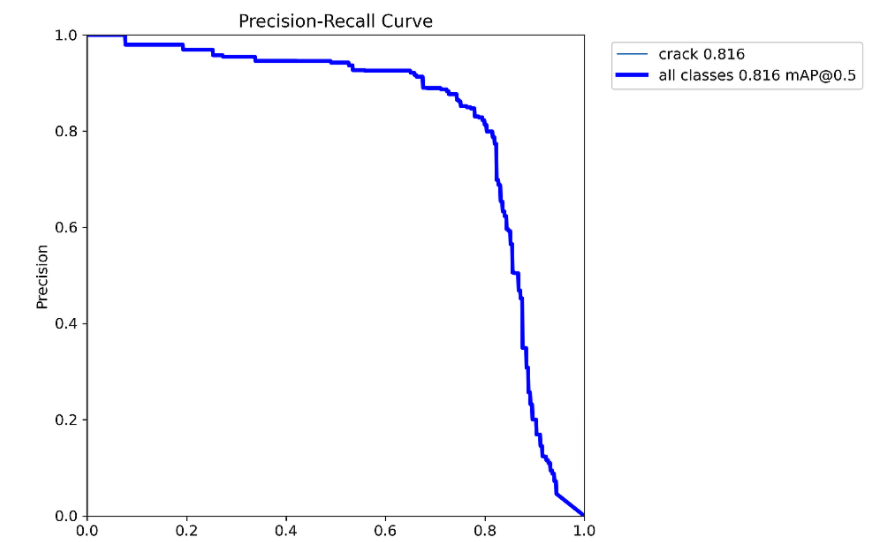
all 200 249 0.83 0.784 0.816 0.632 0.746 0.707 0.673 0.228Mask mAP50 为 0.673
MaskPR_curve.png

添加描述
BoxPR_curve.png
3.4 自研独家创新DSAM注意力


具有各种注意力模块的视觉变换器在视觉任务上展现出了卓越的性能。虽然在图像分类中使用稀疏自适应注意力(如DAT)取得了显著成果,但在针对语义分割任务进行微调时,由可变形点选择的键值对缺乏语义相关性。BiFormer中的查询感知稀疏注意力旨在让每个查询聚焦于top-k路由区域。然而,在计算注意力时,选定的键值对受到太多无关查询的影响,减弱了对更重要查询的注意力。为解决这些问题,我们提出了可变形双级路由注意力(DBRA)模块
具有各种注意力模块的视觉变换器在视觉任务上展现出了卓越的性能。虽然在图像分类中使用稀疏自适应注意力(如DAT)取得了显著成果,但在针对语义分割任务进行微调时,由可变形点选择的键值对缺乏语义相关性。BiFormer中的查询感知稀疏注意力旨在让每个查询聚焦于top-k路由区域。然而,在计算注意力时,选定的键值对受到太多无关查询的影响,减弱了对更重要查询的注意力。为解决这些问题,我们提出了可变形双级路由注意力(DBRA)模块
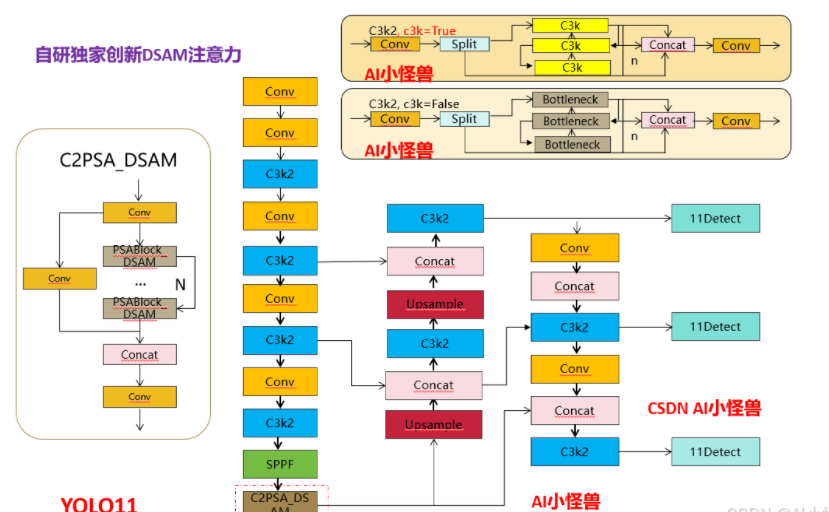
将channel Attention Module替换为Deformable Bi-leve Attention,命名为 Deformable Bi-leve Spatial Attention Module简称DSAM
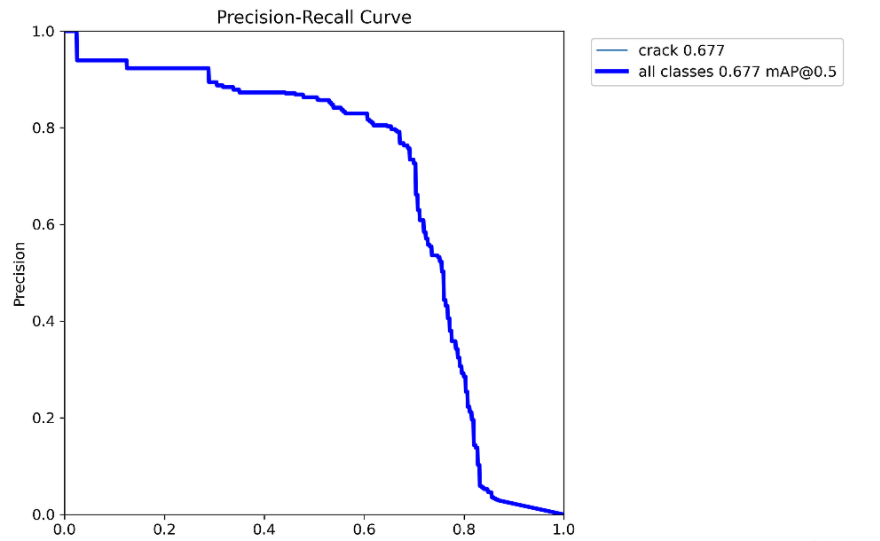
YOLO11-seg-C2PSA_DSAM summary (fused): 302 layers, 3,122,259 parameters, 0 gradients, 19.6 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 7/7 [00:13<00:00, 1.97s/it]
all 200 249 0.849 0.739 0.802 0.648 0.788 0.671 0.677 0.234
Mask mAP50 从原始的0.673 提升至0.677
MaskPR_curve.png
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号