YOLO11-pose关键点检测:DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,结合C3k2二次创新
原创
YOLO11-pose关键点检测:DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,结合C3k2二次创新
原创
💡💡💡本文独家改进:DCNv4更快收敛、更高速度、更高性能,完美和YOLO11结合,助力涨点
DCNv4优势:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DCNv 4实现了三倍以上的前向速度。
💡💡💡如何跟YOLO11结合:1)和C3k2创新性结合
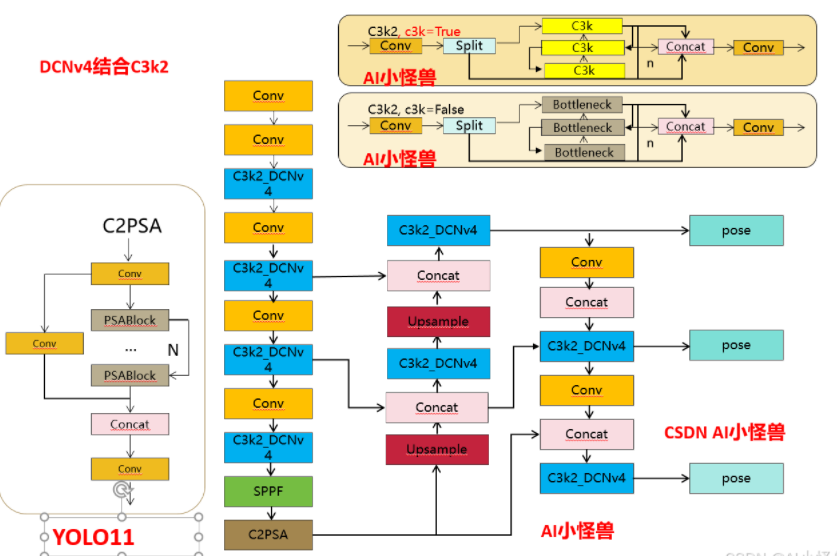
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。
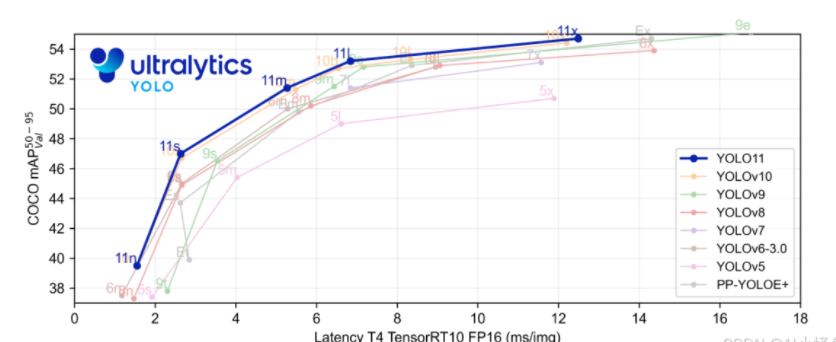

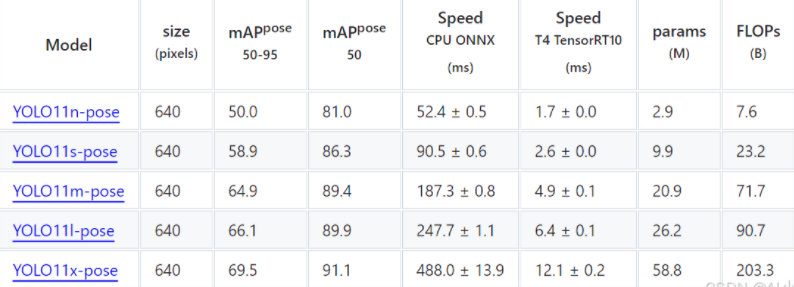
pose官方在COCO数据集上做了更多测试:
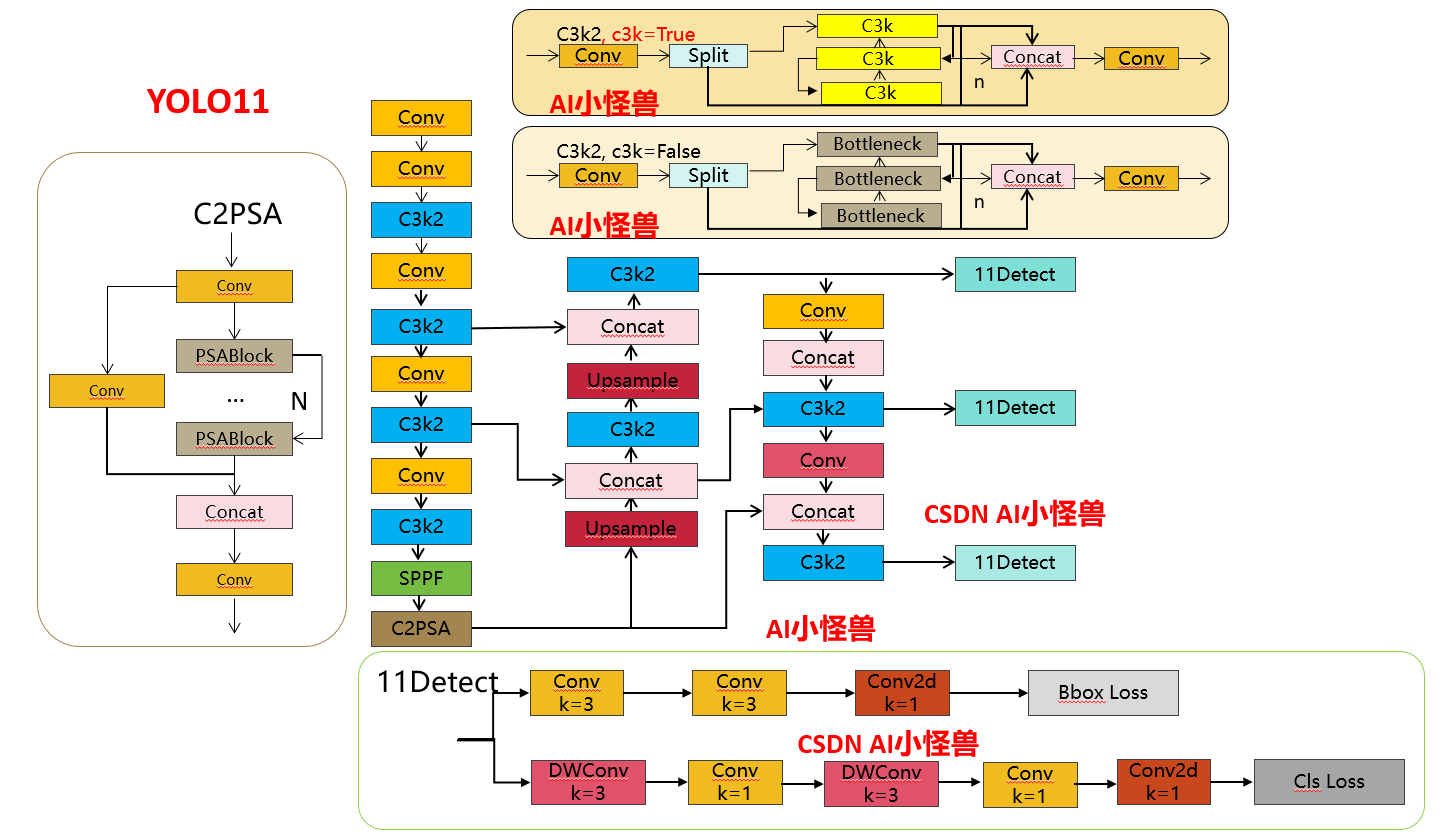
结构图如下:
2. 手势关键点数据集介绍
2.1数据集介绍
数据集大小300张:训练集236张,验证集64张
关键点共21个
# 关键点的类别
keypoint_class = ['Ulna', 'Radius', 'FMCP','FPIP', 'FDIP', 'MCP5','MCP4', 'MCP3', 'MCP2','PIP5', 'PIP4', 'PIP3'
,'PIP2', 'MIP5', 'MIP4','MIP3', 'MIP2', 'DIP5','DIP4', 'DIP3', 'DIP2']标记后的数据格式如下:一张图片对应一个json文件
2.2 生成适合yolo格式的关键点数据集
labelme2yolo-keypoint
生成的txt内容如下:
0 0.48481 0.47896 0.70079 0.77886 0.31308 0.70597 2 0.42206 0.70695 2 0.54954 0.59785 2 0.67569 0.53278 2 0.76420 0.48288 2 0.28402 0.46282 2 0.35865 0.44521 2 0.43395 0.43102 2 0.52642 0.43836 2 0.26486 0.42270 2 0.34941 0.39188 2 0.44782 0.37818 2 0.55680 0.39628 2 0.21731 0.34051 2 0.33884 0.27495 2 0.47094 0.25196 2 0.62351 0.29746 2 0.20674 0.29403 2 0.33620 0.20108 2 0.48018 0.16879 2 0.65654 0.24070 2 讲解:
第一个0代表:框的类别,因为只有hand一类,所以为0
0.48481 0.47896 0.70079 0.77886 代表:归一化后的 框的中心点横纵坐标、宽、高
0.31308 0.70597 2代表:归一化后的 第一个关键点的横纵坐标、关键点可见性
关键点可见性理解:0代表不可见、1代表遮挡、2代表可见
3.3生成的yolo数据集如下
hand_keypoint:
-images:
--train: png图片
--val:png图片
-labels:
--train: txt文件
--val:txt文件3.原理介绍

论文: https://arxiv.org/pdf/2401.06197.pdf
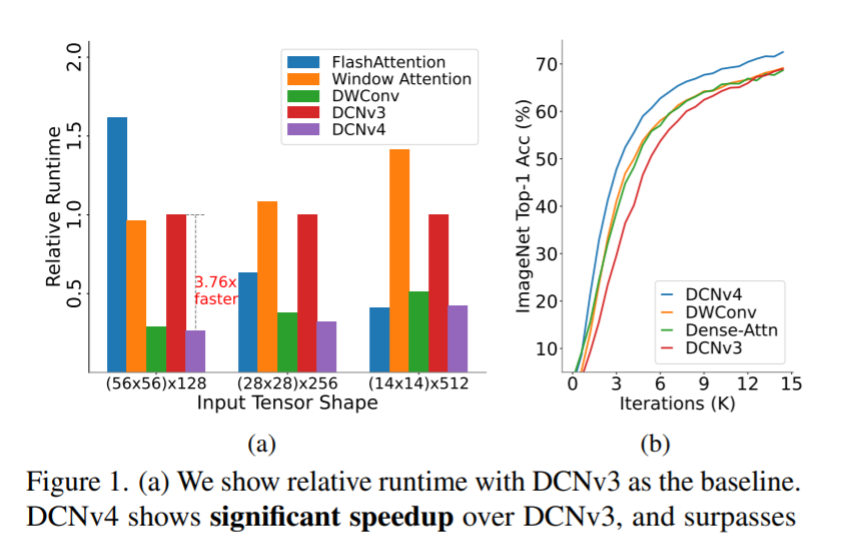
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。
4.YOLO11-pose魔改提升精度
4.1原始结果
Pose mAP50 为 0.871
YOLO11-pose summary (fused): 300 layers, 3,199,712 parameters, 0 gradients, 7.8 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:04<00:00, 1.23s/it]
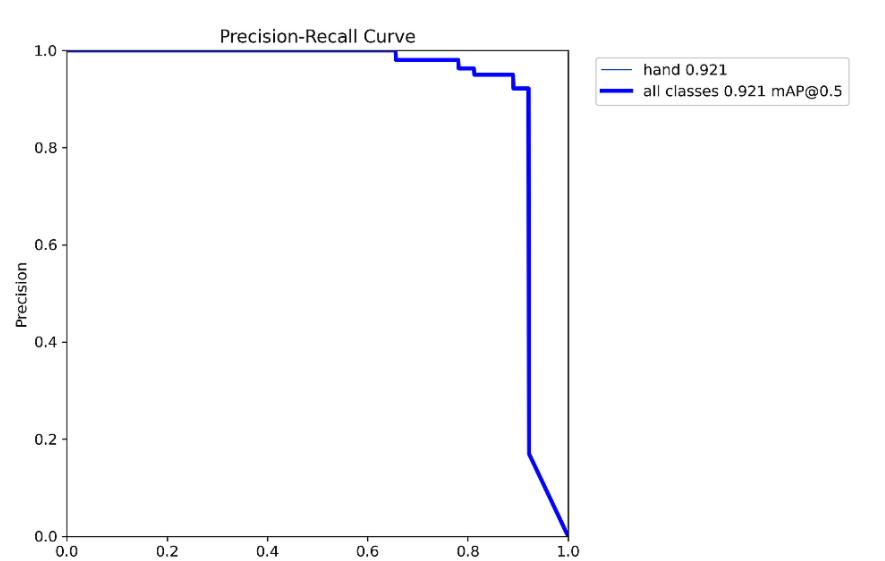
all 64 64 0.999 1 0.995 0.668 0.922 0.922 0.871 0.638PosePR_curve.png
4.2 DCNv4结合C3k2
Pose mAP50 有原先的 0.871 提升至0.885
YOLO11-pose-C3k2_DCNv4 summary (fused): 330 layers, 3,186,368 parameters, 0 gradients, 7.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.97s/it]
all 64 64 0.999 1 0.995 0.697 0.921 0.922 0.921 0.571PosePR_curve.png
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
