SHAP (SHapley Additive exPlanations)及kernelshap预测单样本/全局情况和shapviz可视化学习
原创
SHAP (SHapley Additive exPlanations)及kernelshap预测单样本/全局情况和shapviz可视化学习
原创
凑齐六个字吧
发布于 2025-01-10 14:59:30
发布于 2025-01-10 14:59:30
在上一期推文中学习了如何结合DALEX和shapviz 对单样本进行预测并进行可视化分析。
上期推文:SHAP(SHapley Additive exPlanations)及DALEX预测单样本变量情况和shapviz可视化学习 https://mp.weixin.qq.com/s/hGt63KXvWE_T7JPwLHJbtw
本次将探索kernelshap与shapviz 的结合,用于单样本及全局预测及可视化分析。
kernelshap包有两个关键的函数,分别是kernelshap 和 permshap。

精确Kernel shap是permutation shap的一种近似,对于特征数量最多为8的情况,由于精确计算通常足够快速,推荐使用permshap。当特征数量较多时,kernelshap会切换到一种较快且近似精确的算法,因此在此类情况下推荐使用 kernelshap。对于二阶及以下的交互模型,精确置换SHAP和精确Kernel SHAP 的SHAP值是一致的。当将完整训练数据作为背景数据集时,permshap和kernelshap的结果与additive_shap 的结果完全一致。
分析步骤
1.导入
示例数据可以从百度云盘下载:TCGA_HNSC_practice.Rdata 链接: https://pan.baidu.com/s/1ICh4i9dyjtB3SuBefRxYRg 提取码: iitg
rm(list = ls())
library(kernelshap)
library(ggplot2)
library(ranger)
library(shapviz)
load("TCGA_HNSC_practice.Rdata")2.数据预处理
采用OS(二分类,0和1分别代表生存和死亡)作为结局指标
colnames(meta)
head(meta)[1:3,1:8]
meta$OS <- factor(meta$OS)
# 提取数据,去除NA
# 要注意在建立模型的时候变量可以使非数字
# shap解释变量的时候一定要把变量内容设定为数字
dat <- na.omit(meta[,c(2,8,11,12,17,41:43)])
head(dat)
dat[,-1] <- data.frame(lapply(dat[,-1], as.numeric))
dat$age <- ifelse(dat$age > 60, 1,0)
dat$day_completion <- ifelse(dat$day_completion > 15, 1,0)
dat$month_completion <- ifelse(dat$month_completion > 6, 1,0)
dat$lymph_count <- ifelse(dat$lymph_count > 20, 1,0)
dat$`T` <- ifelse(dat$`T` > 2, 1,0)
dat$`N` <- ifelse(dat$`N` > 1, 1,0)
dat$`M` <- ifelse(dat$`M` > 0, 1,0)
str(dat)
# 使用randomForest/ranger去构建随机森林树模型
library(randomForest)
model <- randomForest(OS ~.,data =dat)
library(ranger)
model <- ranger(OS ~ age + day_completion + month_completion + lymph_count + `T` + `N` +`M`,
data = dat,classification = TRUE,
probability = TRUE,
num.trees = 100,
seed = 20) # 设置输出概率
model
xvars <- c("age", "day_completion", "month_completion",
"lymph_count","T","N","M")3.kernelshap+shapviz
# 1) Sample rows to be explained
# 数据量不大,笔者使用全部数据
set.seed(10)
# X <- dat[sample(nrow(diamonds), 1000), xvars] # 官方代码,建议1000个样本
X <- dat[, xvars]
# 2) Optional: Select background data. If unspecified, 200 rows from X are used
# bg_X <- dat[sample(nrow(dat), 200), ]
# 3) Crunch SHAP values
# Note: Since the number of features is small, we use permshap()
ps <- permshap(model, X) #, bg_X = bg_X)
ps
# SHAP values of first observations:
# $`0`
# age day_completion month_completion lymph_count T
# [1,] 0.01530288 -0.02829701 -0.02270137 0.015690372 -0.01515734
# [2,] 0.04099188 0.07402535 0.03189634 0.009485131 0.11013120
# N M
# [1,] 0.03507547 0.001203453
# [2,] -0.00196143 0.001408363
#
# $`1`
# age day_completion month_completion lymph_count T
# [1,] -0.01530288 0.02829701 0.02270137 -0.015690372 0.01515734
# [2,] -0.04099188 -0.07402535 -0.03189634 -0.009485131 -0.11013120
# N M
# [1,] -0.03507547 -0.001203453
# [2,] 0.00196143 -0.001408363
# Kernel SHAP gives almost the same:
ks <- kernelshap(model, X, bg_X = bg_X)
ks4.shapviz可视化
# 4) Analyze with {shapviz}
ps <- shapviz(ps)
# 重要性分析
sv_importance(ps,kind = "bar") # "bar", "beeswarm", "both", "no"
sv_importance(ps,kind = "beeswarm")+ theme_bw()
# 依赖图
sv_dependence(ps, "day_completion")
# 瀑布图
sv_waterfall(ps, row_id = 1) +
theme(axis.text = element_text(size = 11))
# 力图
sv_force(ps, row_id = 1)采用了二分类结局变量之后图片会分成0(生存)和1(死亡)两组,并展示了不同变量在这两组中shap值的情况。颜色由深紫色(代表特征值低)到橙色(特征值高)变化,颜色条标志不同特征值的大小。我们回溯一下具体的结果,就拿T分期来说,T是分成了二分类数据,其中T3/4为1,其余为0,N2/3为1,其余为0,再结合一下这个结果,我们可以发现在存活分组中T值为1的样本的SHAP值更低,而T值为0的样本SHAP值更高,说明T分期更低的样本在存活分组中的贡献更高。
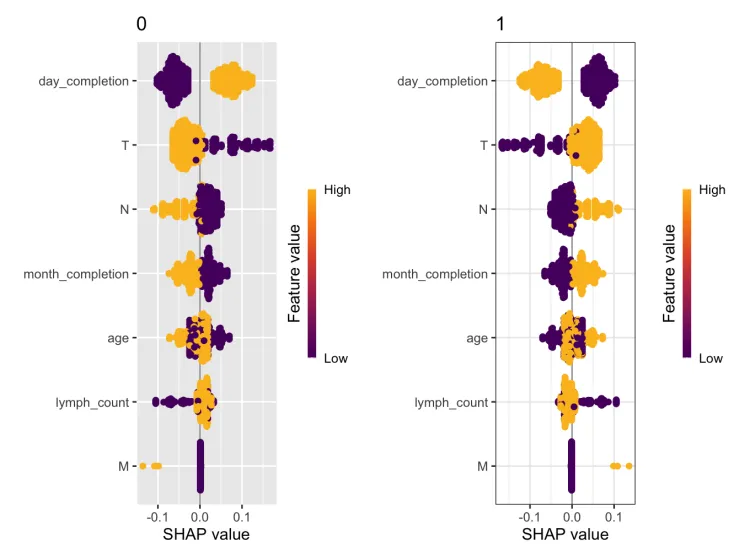
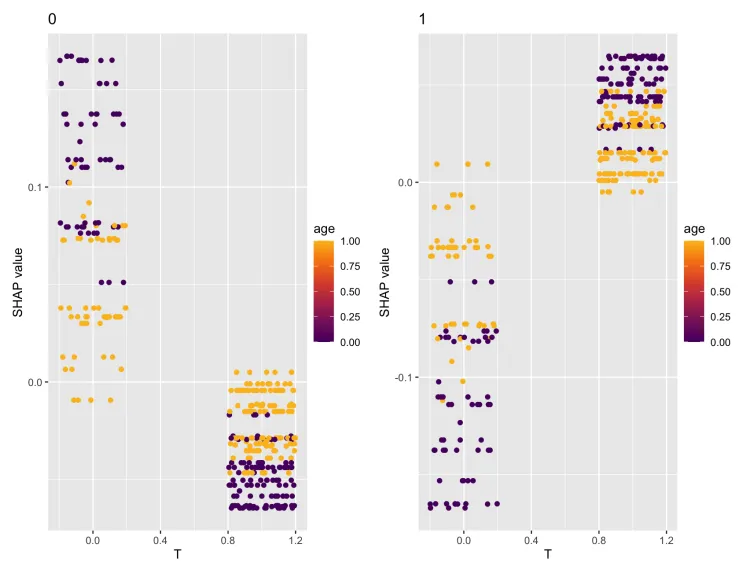
图中展示了特征T对分类结果(0和1)的SHAP值贡献以及特征age作为颜色变量的分布情况。在分类为0的样本中,较低的T值对分类结果有显著的正向贡献,尤其是在age较高(颜色偏黄)的样本中,而较高的T值对分类结果的贡献趋于零或负向。在分类为1的样本中,较高的T值对分类结果有显著的正向贡献,同样这种贡献在age较高的样本中更加明显,而较低的T值对分类结果有负向影响。此外,age作为一个交互变量,在两种分类中都起到了放大T对预测结果影响的作用,高age值会增强T对分类结果的正负贡献。这表明T和age之间存在重要的交互关系,例如较低分期(低T值)的高龄患者更可能分类为0,而较高分期(高T值)的高龄患者更倾向于分类为1。(其实这里的示例数据有点不好,应该改成连续型变量会更直观,至少要把age改成连续型的)
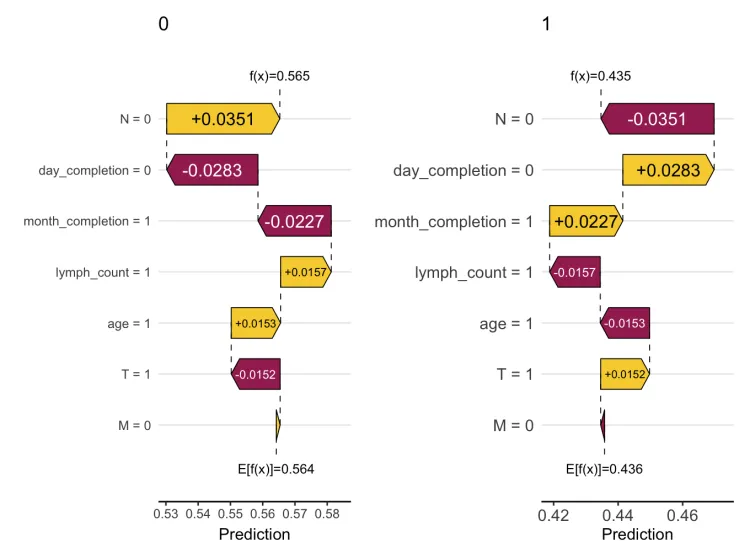
经典单样本瀑布图和力图
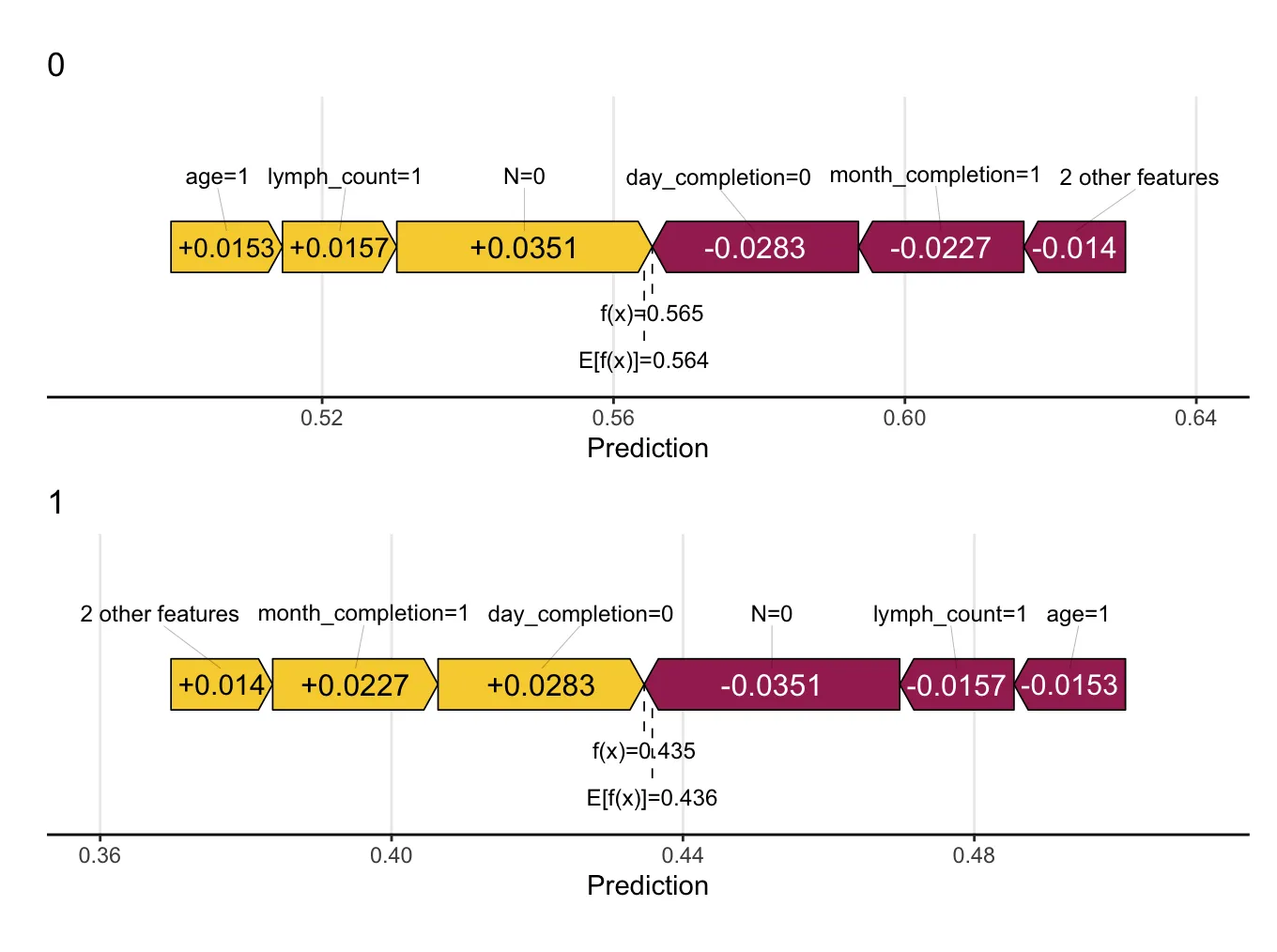
# 选择特定特征属性
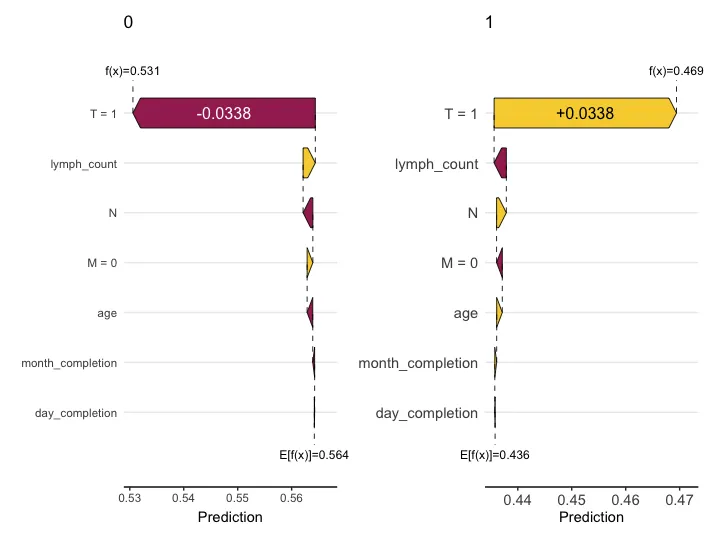
sv_waterfall(ps, ps$`1`$X$`T`=="1") +
theme(axis.text = element_text(size = 11))选择特定特征属性的样本,这里选择了在死亡组中T分期组别为1的样本进行可视化,可以看到这些样本在死亡组中可以增加0.0338的shap值,而在生存组中则正好相反。
参考资料:
- kernelshap github: https://github.com/ModelOriented/kernelshap
- shapviz github:https://github.com/ModelOriented/shapviz
- Explaining prediction models and individual predictions with feature contributions. Knowl Inf Syst (2014) 41:647–665
- A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems 30 (2017)
- 生信漫卷:https://mp.weixin.qq.com/s/pntRNrknoZv_Im-AN-ewYQ
- 医学和生信笔记:https://mp.weixin.qq.com/s/G6L7TdDvLJlYdrgGzVqh8g https://mp.weixin.qq.com/s/I05aXlUU4hnGCNObRtm0Wg https://mp.weixin.qq.com/s/c3OCbnmavd32JgMEDQ29Qw https://mp.weixin.qq.com/s/FWi3LkdofeG3kB2_VtK06A https://mp.weixin.qq.com/s/Kje4QknfqR2rVh7oYtaQag
注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多内容可关注公众号:生信方舟
- END -
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号