【数据处理包Pandas】DataFrame的创建

【数据处理包Pandas】DataFrame的创建

Francek Chen
发布于 2025-01-22 20:56:31
发布于 2025-01-22 20:56:31
一、DataFrame简介
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共用同一个索引)是基于。
DataFrame函数原型:pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
- data:数据,可以是多种形式,如ndarray、Series、DataFrame、字典等。
- index:行索引,用于指定行的标签,默认为整数索引。
- columns:列索引,用于指定列的标签,默认为整数索引。
- dtype:数据类型,用于指定DataFrame中的数据类型,默认为None。
- copy:是否复制数据,默认为False。
DataFrame的属性:
函数 | 返回值 |
|---|---|
values | 元素 |
index | 索引 |
columns | 列名 |
dtypes | 类型 |
size | 元素个数 |
ndim | 维度数 |
shape | 数据形状(行列数目) |
导入 NumPy 库和 Pandas 库:
import numpy as np
import pandas as pd二、基于一维数据创建
DataFrame对象看成一维对象的有序序列,序列中的对象元素又分成按列排列和按行排列两种情况。
(一)按列排列
按列排列,需要基于字典构建:字典的键对应列名,字典的值可以是一列表、一维Numpy数组、Series 对象,或者字典都行。此时,只要一列存在行索引,则该行索引被共享(例如 english 的索引);如果各列都没有行索引,则用整数作为隐含索引。
1、字典的值分别是一个Series对象、一维列表、一维Numpy数组的情形
#***case1-① ② ③:字典的值分别是一个Series对象、一维列表、一维Numpy数组的情形
english = pd.Series([93,97],index=['s01','s02'])
pd.DataFrame({'英语':english,'语文':[86,88],'数学':np.array([97,95])})
2、字典的值是字典的情形
#***case1-④:字典的值是字典的情形
pd.DataFrame({'数学':{'s01':97,'s02':95},'英语':{'s01':93,'s02':97},'语文':{'s01':86,'s02':88}})对比:看看下面语句的执行结果:
pd.DataFrame({'s01':{'语文':86,'数学':97,'英语':93},'s02':{'数学':95,'语文':88,'英语':97}})
小结:只要外层是字典,则外层字典的键一定是作为DataFrame对象的列标签。内层如果是字典或 Series 对象(也可以看成是字典),则内层字典的键将作为作为DataFrame对象的行标签。
(二)按行排列
按行排列,需要基于列表构建:列表中的元素可以是一维 Series 对象、一维列表、一维 Numpy 数组或字典都行。
1、把行看成Series对象的情形
#***case2-①:这是把行看成Series对象的情形
s1 = pd.Series({'语文':86,'数学':97,'英语':93})
s2 = pd.Series({'数学':95,'语文':88,'英语':97})
pd.DataFrame([s1,s2],index=['s01','s02'])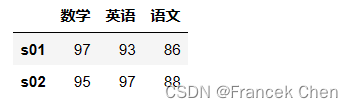
2、把行看成列表的情形
#***case2-②:这是把行看成列表的情形
pd.DataFrame([[97,93,86],[95,97,88]],index=['s01','s02'],columns=['数学','英语','语文'])3、把行看成一维Numpy数组的情形
#***case2-③:这是把行看成一维Numpy数组的情形
pd.DataFrame([np.array([97,93,86]),np.array([95,97,88])],index=['s01','s02'],columns=['数学','英语','语文'])4、把行看成字典的情形
#***case2-④:这是把行看成字典的情形
pd.DataFrame([{'语文':86,'数学':97,'英语':93},{'数学':95,'语文':88,'英语':97}],index=['s01','s02'])三、基于二维数据创建
1、基于二维列表创建
##***case3-①:基于二维列表创建
pd.DataFrame([[97,93,86],[95,97,88]],index=['s01','s02'],columns=['数学','英语','语文'])
2、基于二维数组创建
#***case3-②:基于二维数组创建
scores = np.array([[97,93,86],
[95,97,88]])
pd.DataFrame(scores,index=['s01','s02'],columns=['数学','英语','语文'])3、基于字典创建
#***case3-③:基于字典创建,列名看作字典的键
pd.DataFrame({'数学':[97,95],'英语':[93,97],'语文':[86,88]},index=['s01','s02'])四、基于已有的文件创建
#case4--基于已有的文件创建
pd.read_excel('team.xlsx')
注意:使用index和columns属性查看DataFrame的行、列名。字符串在 Pandas 中被处理成object类型的对象。
df = pd.DataFrame([[97,93,86],[95,97,88]],index=['s01','s02'],columns=['数学','英语','语文'])
print(df.index)
print(df.columns)
ser = pd.Series({'a':[1,2,3],'b':['1','2','3']})
ser
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号