关联规则挖掘(二)


三、FP-增长算法
(一)算法的背景
Apriori算法存在以下两方面的不足:
(1)产生大量的候选项集
例如,当事务数据库有104个频繁1-项集时, Apriori算法就需要产生多达107个候选2-项集,即对存储空间要求会影响算法的执行效率。
(2)多次重复地扫描事务数据库
对每个
,为了计算候选k-项集的支持度,都需要扫描一次事务数据库,才能确定候选k-项集的支持度,其计算时间开销很大。
用 FP-增长 (Frequent-Pattern Growth,FP-Growth) 算法来发现频繁项集。算法只需扫描事务数据库两次,其计算过程主要由以下两步构成。
(1)构造FP-树
将事务数据库压缩到一棵频繁模式树 (Frequent-Pattern Tree,简记为FP-树) 之中,并让该树保留每个项的支持数和关联信息。
(2)生成频繁项集
由FP-树逐步生成关于项集的条件树,并根据条件树生成频繁项集。
(二)构造FP-树
FP-树是事务数据库的一种压缩表示方法。它通过逐个读入事务,并把每个事务映射为FP-树中的一条路径,且路径中的每个结点对应该事务中的一个项。不同的事务如果有若干个相同的项,则它们在FP-树中用重叠的路径表示,用结点旁的数字标明该项的重复次数,作为项的支持数。因此,路径相互重叠越多,使用FP-树结构表示事务数据库的压缩效果就越好。如果FP-树足够小且能够在内存中存储,则可以从这个内存的树结构中直接提取频繁项集,而不必再重复地扫描存放在硬盘上的事务数据库。
某超市经营
等5种商品,即超市的项集
,而表8-8是其交易数据库
。
下面借用这个事务数据库来介绍FP-树的构造方法,这里假设最小支持数
。
FP-树的构造主要由以下两步构成。
(1)生成事务数据库的头表
。
第一次扫描事务数据库
,确定每个项的支持数,将频繁项按照支持数递减排序,并删除非频繁项,得到
的频繁-1项集
。现有文献都将
称为事务数据库的头表 (Head table)。
对于表8-8的事务数据库
,其头表
,即
中的每个项都是频繁的。
(2)生成事务数据库的FP-树
第二次扫描数据集
,读出每个事务并构建根结点为null的FP-树。
开始时FP-树仅有一个结点null,然后依次读入
的第
个事务
。设
已删除了非频繁项,且已按照头表
递减排序为
,则生成一条路径
,并按以下方式之一,将其添加到FP-树中,直到所有事务处理完备。
① 如果FP-树与路径
没有共同的前缀路径 (prefix path),即它们没有从null开始,其余结点完全相同的一段子路径,则将
直接添加到FP-树的null结点上,形成一条新路径,且让
中的每个项对应一个结点,并用
表示。
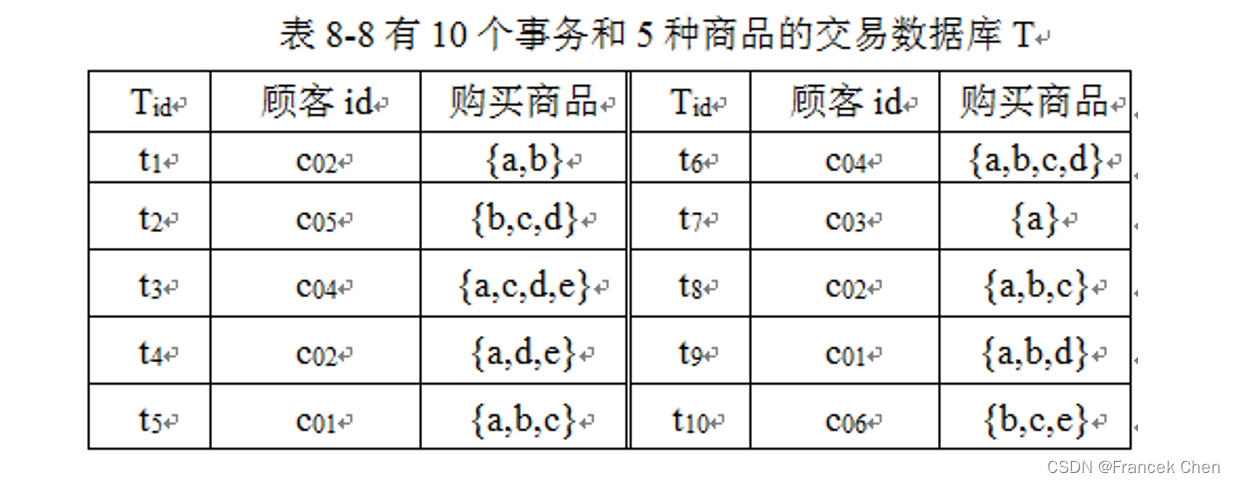
例 8-6 假设FP-树中已有两条路径 null-a-b 和 null-c-d-e (图8-4(1))。设有事务
,其对应的路径为
(事务和对应的路径采用同一个符号
)。因为FP-树与
没有共同的前缀路径,即从null开始没有相同的结点,因此,将t直接添加到FP-树中(图8-4(2))。
② 如果FP-树中存在从根结点开始与
完全相同的路径,即FP-树中存在从null到
直到的路径,则将FP-树中该路径上从
到的每个结点支持数增加1即可。
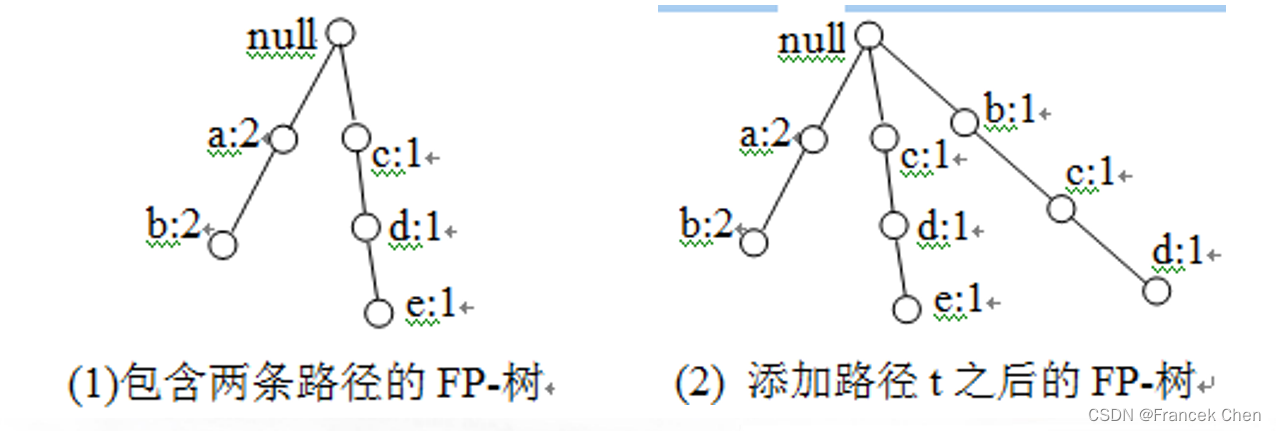
例 8-7 假设FP-树中已有两条路径 null-a-b-c 和 null-b-c-d (图8-5(1))。设有事务
,其路径为
,则因为FP-树从根节点 null 开始存在与 null-a-b 完全相同的路径,因此,将结点
的支持数分别增加1即可(图8-5(2))。
③ 如果FP-树与路径
有相同的前缀路径,即FP-树已有从null到
直到
的路径,则将FP-树的结点
到
的支持数增加1,并将
从
开始的子路径放在
之后生成新的路径。
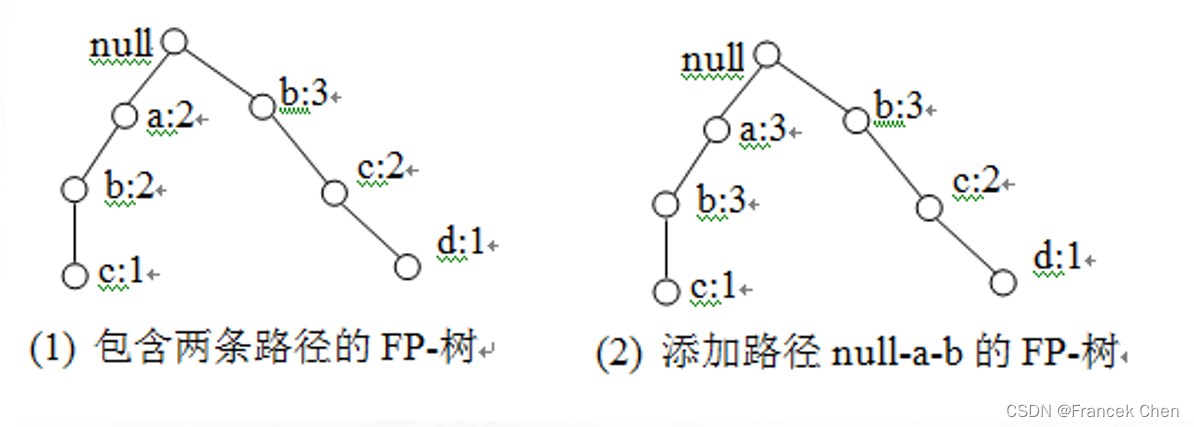
例 8-8 假设FP-树中已有两条路径 null-a-b 和 null-b-c-d (图8-6(1))。设有事务
,其对应的路径为
,则因为FP-树与
存在共同的前缀路径 null-b-c,因此,将结点
的支持数直接增加1,并在结点
后面增加结点
(图8-6(2))。
例 8-9 对表8-8所示的事务数据库
,假设最小支持数
,试构造它的FP-树。
在这里插入图片描述
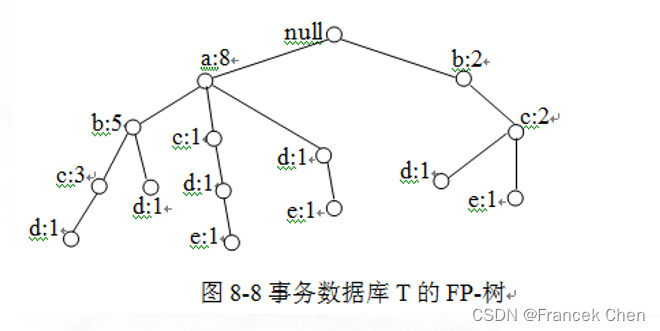
(三)生成频繁项集
由于每一个事务都被映射为FP-树中的一条路径,且结点代表项和项的支持数,因此通过直接考察包含特定结点 (例如e) 的路径,就可以发现以特定结点 (比如e) 结尾的频繁项集。
由FP-树生成频繁项集的算法以自底向上的方式搜索FP-树,并产生指定项集的条件树,再利用条件树生成频繁项集。
对于图8-8所示的FP-树,算法从头表
的最后,即支持数最小的项开始,依次选择一个项并构造该项的条件FP-树 (condition FP-tree),即首先生成以
结尾的前缀路径,更新其结点的支持数后获得
的条件FP-树,并由此生成频繁项集
。
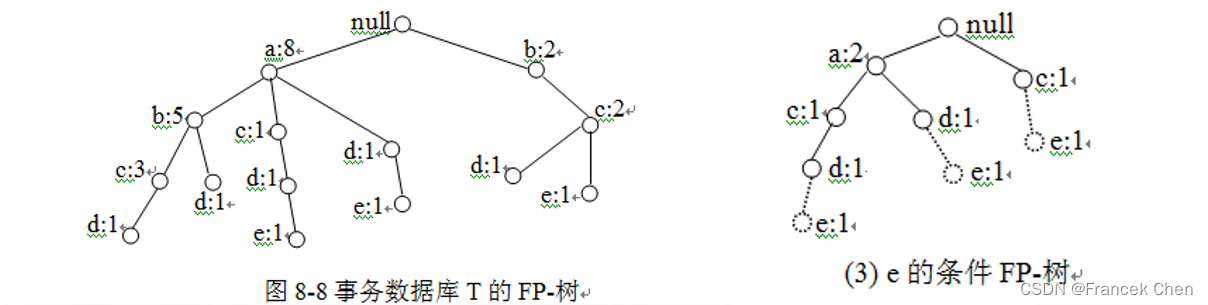
在
频繁的条件下,需要进一步发现以
和
结尾的频繁项集等子问题,直至获得以
结尾的所有频繁项集,即包括
的所有频繁项集。
观察头表
可知,包括
的项集共有
,
,
,
,
,
,
,
,
,
,
,
等。在
的条件FP-树产生过程中,算法会不断地删除非频繁项集保留频繁项集,而不是枚举地检验以上每个项集是否为频繁的,因而提高了搜索效率。从
的条件FP-树可得以
结尾的频繁项集
。
当包括
的所有频繁项集生成以后,接下来再按照头表
,并依次寻找包括
或
的所有频繁项集,即依次构造以
或
结尾的前缀路径和条件FP-树,并获得以它们结尾的所有频繁项集。
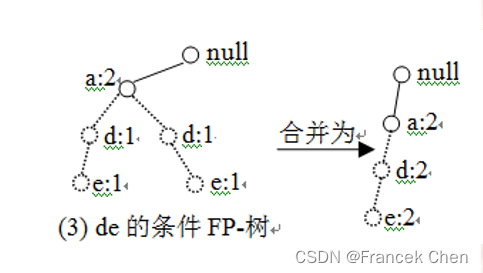
根据与前面类似的计算过程,最终可得事务数据库
的所有频繁项集 (表8-9)。

四、关联规则的评价
1、主观标准
以决策者的主观知识或领域专家的先验知识等建立的评价标准,称为主观兴趣度。关联规则 {黄油}
{面包} 有很高的支持度和置信度,但是它表示的联系连超市普通员工都觉得显而易见,因此不是有趣的。关联规则 {尿布}
{啤酒} 确实是有趣的,因为这种联系十分出人意料,并且可能为零售商提供新的交叉销售机会。
2、客观标准
以统计理论为依据建立的客观评价标准,称为客观兴趣度。客观兴趣度以数据本身推导出的统计量来确定规则是否是有趣的。支持度,置信度,提升度等都是客观兴趣度,也就是客观标准。
(一)支持度和置信度的不足
为了说明支持度和置信度在关联规则检测中存在的不足,可用基于2个项集
和
(也称二元变量
,
)的相依表来计算说明 (表8-10)。

表8-10中的记号
表示项集
没有在事务中出现,
为支持数,即
表示同时包含项集
和
的事务个数;
表示包含
但不包含
的事务个数;
表示包含
但不包含
的事务个数;
表示既不包含
也不包含
的事务个数;
表示
的支持数,
表示
的支持数,而
为事务数据库的事务总数。
例 8-10 一个误导的“强”关联规则。 若
,
,则
得出
是一个强关联规则的结论。
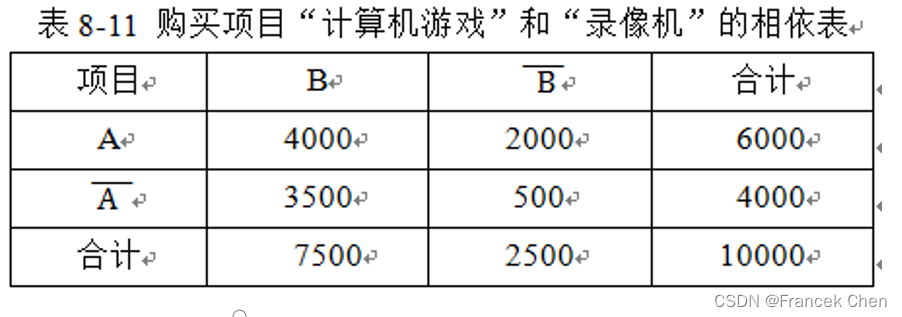
实际上,
这个强关联规则却是一个虚假的规则,如果商家使用这个规则将是一个错误,因为购买录像的概率是75%比66%高。
此外,计算机游戏和录像机是负相关的,因为买其中一种商品实际上降低了买另一种商品的可能性。如果不能完全理解这种现象,容易根据规则
做出不明智的商业决策。
(二)相关性分析
提升度 (Lift) 是一种简单的相关性度量。对于项集
和
,如果概
,则
和
是相互独立的,否则它们就存在某种依赖关系。
如果
的值大于1,表示二者存在正相关,而小于1表示二者存在负相关。若其值等于1,则表示二者没有任何相关性。
对于二元变量,提升度等价于被称为兴趣因子 (Interest factor) 的客观度量,其定义如下
例 8-11 对于表8-11所示的相依表,试计算其提升度或兴趣因子。
解:
;
;
关联规则
,也就是 {计算机游戏}
{录像机} 的提升度 Lift(A,B) 小于1,即前件
与后件
存在负相关关系,若推广 “计算机游戏” 不但不会提升 “录像机” 的购买人数,反而会减少。
项集之间的相关性也可以用相关系数来度量。对于二元变量
,
,相关系数
定义为
若相关系数
等于0,表示二者不相关,大于0表示正相关,小于0表示负相关。
例 8-12 对例8-10的表8-11所示的相依表,试计算相关因子。
解:相关系数
的分子等于
,故相关系数
小于0,故购买 “计算机游戏” 与购买 “录像机” 两个事件是负相关的。
此外,相关性还可以用余弦值来度量,即
相关性度量可以提高关联规则的可用性,但仍然存在局限性,还需要研究,并引入其它客观度量。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号