因果推断常用计量方法
原创
因果推断
概念&术语
因果推断(Causal Inference): 是关联分析的一种统计方法,在大型系统中,试图指定/干预 “因” 而观测影响/改变 “果”的过程。因果推断不仅关注事物之间的关联性,还会更进一步探究该关联是否具有从因到果的推断关系。因果推断在生物医学、社会科学有广泛应用。通过揭示变量之间的因果关系,理解数据的产生机制,探究出现象背后的深层原因;通过回答"Why",理解决策的背后原因。
“因果关系阶梯”(Ladder of Causation) 是由Judea Pearl和Dana Mackenzie在《The Book of Why 》中提出的一个概念,描述思考因果关系的三个层次,分别为:关联观测(Association)、干预(Intervention) 和 反事实推理(Counterfactuals)。
以下对本文涉及的相关术语进行说明:
1. 潜在结果(Potential Outcome):如果个体i 接受特定干预行为D_i (例如服药,本文仅讨论二元干预),则对应的结果Y_i 为Y_i(1) ,如果没有接受干预则对应的结果Y_i(0) ,这两种结果称为潜在结果。
2. 观测结果(Observed Outcome):现实中,无法同时观测到个体i 的两种潜在结果。个体i 接受干预后(D_i = 1 ),或者不接受干预后(D_i = 0 ) ,得到的真实结果称为观测结果。
3. 反事实结果(Counterfactual Outcome):与观测结果对应的,未观测到的潜在结果,对于个体i ,若观测结果Y_i = Y_i(1) ,则对应的反事实结果为Y_i(0) 。
4. 自变量:也称为解释变量(原因变量),可由研究者选择、控制,且能独立变化而影响其他变量变化的条件或因素。因变量:也称为被解释变量(结果变量),研究的目标变量,取值可被观测且随自变量的变化而变化。协变量:除自变量外,能够影响因变量的变量因素,但不被研究者控制。
5. 混淆变量(Confounder):既影响自变量又影响因变量的变量。潜在结果框架的核心: 通过尽可能消除混淆变量的影响,得到精准的干预效应。
6. 干预效应(Treatment Effect):干预问题的基础是量化干预效应,常用的计量指标包括:
(1). ITE:Individual Treatment Effect,个体干预效应,个体i 接受干预(D_i = 1 )的潜在结果Y_i(1) 和没有接受干预(D_i = 0 )的潜在结果Y_i(0) 的差异。
由于个体干预效应存在异质性且无法同时观测,因此常使用以下平均干预效应。
(2). ATT:Average Treatment Effect on the Treated,所有接受干预(D_i = 1 )的个体效应平均值,即干预组平均干预效应。
(3). ATU:Average Treatment Effect on the Untreated,所有未接受干预(D_i = 0 )个体的效应平均值,即控制组平均干预效应。
(4). ATE:Average Treatment Effect,总体的平均干预效应,包括所有接受和未接受干预的个体。
(5). CATE:Conditional Average Treatment Effect,在特定条件下,总体的平均干预效应。
辛普森悖论
“相关不等于因果”,因果关系必然导致相关关系,但相关关系不一定反映出因果关系。甚至某些情况下,用相关关系推导出的因果关系存在自身矛盾的问题,著名的辛普森悖论展示了两者的区别。
辛普森悖论(Simpson's paradox) 是英国统计学家E.H.辛普森于1951提出,在指定条件下的两组数据,分别讨论时会满足特定的结论,但合并考虑得到相反的结论。即两个变量X和Y在每个分组中的关系是正(负)相关的,但在汇总后关系会发生逆转,变为负(正)相关的。
假设研究某药物的治疗效果,分为30岁和40岁年龄组,每组都有服药和未服药的个体,观测数据如下[1]:
年龄 | 未服药(平均身体健康指数) | 服药(平均身体健康指数) | 健康状况差异(服药-未服药) |
|---|---|---|---|
30岁 | 80 (6) | 90 (2) | 10 |
40岁 | 60 (3) | 65 (5) | 5 |
所有 | 73.3 (9) | 72.1 (7) | -1.2 |
(1). 若不考虑年龄因素,则服药与健康指数存在负相关性,即服药的治疗效果是副作用(-1.2) 。
(2). 若考虑年龄影响,并假设不存在其他混淆因素,则服药与健康指数是正相关性,即服药的治疗效果是正向作用。定义两个变量年龄(Age)、是否服药(Treat),并整理数据如下:
Age | Treat | Health |
|---|---|---|
30 | 0 | 80 |
30 | 1 | 90 |
40 | 0 | 60 |
40 | 1 | 65 |
定义线性回归模型如下:
其中β_{0} 是截距,β_{1} 是Treat服药的相关系数,β_{2} 是Age年龄的相关系数,ϵ 是误差项。使用OLS最小二乘法计算,可得到如下结果:服药与健康指数是正相关的,年龄与健康指数是负相关的。
产生辛普森悖论的原因是,从相关关系跨向因果关系具有一个重要挑战: 混淆的存在。以上示例中,年龄作为混淆变量,同时影响健康指数和服药效果。因此直接对整体计量时,相关关系与因果关系是相悖的。使用相关关系刻画因果关系时,应该控制混淆变量(例如按年龄段分组),用来消除虚假的因果关系。
关系路径图&偏差
因果推断中关系路径图是DAG有向无环图,是研究因果关系的有效辅助工具,可以将复杂问题图形化。路径图由节点(顶点)和单项箭头组成,每个节点代表变量,实心节点表示可观测的变量,空心节点表示不可观测的变量。
基于路径图可表示变量之间的关联方式,常见的路径种类分为三类:
- 因果路径:也称为链状路径,A\rightarrow B\rightarrow C ,由“因”指向“果”的单向路径,箭头指向同一方向。因果路径的关系是稳定可回溯的。示例因果路径,锻炼与否 \rightarrow 生活规律 \rightarrow 健康。
- 混淆路径:也称为叉状路径,A\leftarrow B\rightarrow C,指观测变量中存在混淆变量,该变量同时影响因变量(解释变量)与自变量(被解释变量)。在混淆路径中, 学历\leftarrow 智商\rightarrow 收入,其中智商是混淆变量,该混淆变量在路径中造成学历与收入的相关性。
- 对撞路径:也称为反叉状路径,A\rightarrow B\leftarrow C,指具有对撞变量的路径,对撞变量是受两个变量共同影响的变量,对撞变量本身不会衍生相关性,但固定对撞变量会造成原始变量产生相关性。在对撞路径中,作息规律\rightarrow 是否患病\leftarrow 饮食健康,存在对撞变量是否患病。
因果推断的本质是找到所有变量间的因果路径,同时剔除非因果路径。在实际研究中,如果不能正确处理变量间的路径关系,会存在各种偏差。偏差主要归为以下三类[2]。
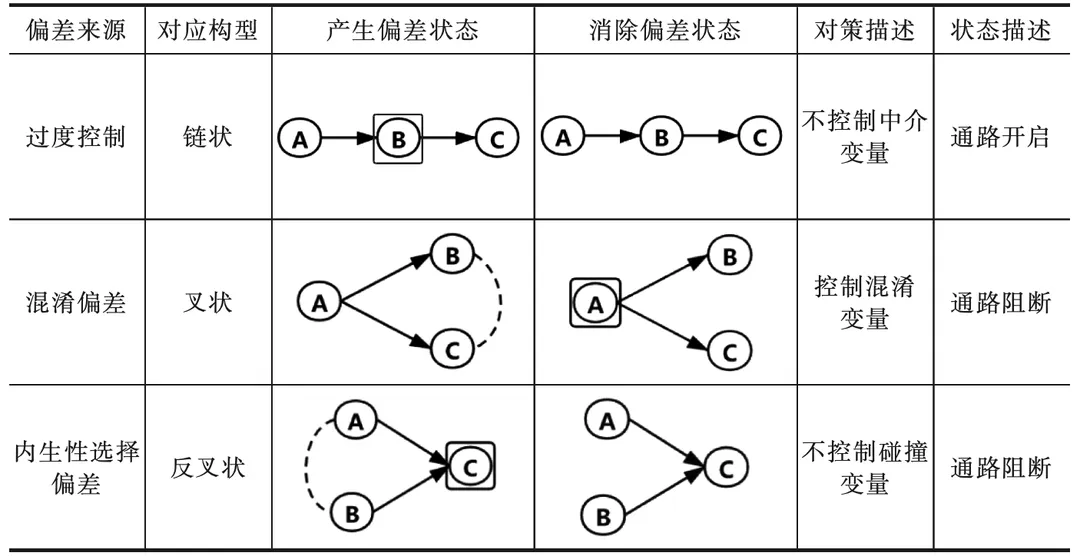
- 过度控制偏差(Overcontrol Bias):错误控制因果路径上的中介变量产生的偏差,该偏差会削弱变量间真实因果效应。锻炼与否 \rightarrow 生活规律\rightarrow 健康,若控制生活规律,则会低估锻炼对健康的影响,即低估自变量对因变量的影响。
- 混淆偏差(Confounding Bias):由混淆变量产生的偏差,在因果变量之间存在未截断的混淆路径,导致变量之间的相关性不仅包含因果关系,也包含混淆变量衍生的非因果相关关系。
- 内生选择偏差(Endogenous Selection Bias):也称为选择性偏差,由对撞变量产生的偏差,而对撞变量产生主要与样本选择和数据生成方式相关,导致两个不相关变量基于对撞变量衍生出新的相关路径。例如,对撞路径 作息规律\rightarrow 是否患病\leftarrow 饮食健康,仅选择患病群体作为研究样本。如果作息规则,则可能是饮食不健康导致患病;如果饮食健康,则可能是作息不规律导致患病。因此会错误衍生出作息规律与饮食健康存在负相关性。
框架模型
因果推断主要有两个框架模型流派:
- 潜在结果框架(Potential Outcome Framework):也称为Rubin因果模型(Rubin Causal Model,RCM),20世纪70年代,由统计学家Donald Rubin和经济学家Guido Imbens等人发展。其核心是估算不同干预策略下的潜在结果,以评估实际的干预效果。该框架将模糊的概念转变为具有明确语义和逻辑基础的数学对象,不依赖完整的因果图,只需明确关注变量对于输出结果是否有因果影响即可。 该框架强调随机化实验,通过随机化帮助消除干扰因素的影响。
- 结构因果模型(Structure Causal Model,SCM):20世纪90年代,Judea Pearl基于因果图提出,其核心是在一个已知的因果图中去做推断,依赖专家知识定义因果图。目前较为成熟的判断准则,如后门准则(Back Door)、前门准则(Front Door)等去除其中的混淆,通过Do-Calculus 干预实现因果估计[3]。
常用计量方法
随机对照试验
因果推断的一条黄金法则:随机对照试验(AB测试) 是确定因果关系最可靠的方法 [3]。
随机对照试验(Randomized Controlled Trial, RCT):是统计假设检验理论的实际应用,将研究对象随机分组,对不同分组实施不同的干预,以比较效果差异。基于数学的反证法评估变量影响,首先假设随机对照试验中自变量对因变量没有影响,然后寻找反例推翻该假设,进而证明变量之间存在因果关系。
步骤1:建立原假设H_0 (也称为零假设)。基于“自变量对因变量没有影响”进行建模,统计学上可表示为:对于唯一改变自变量取值而采集的A/B组样本,因变量在A/B组样本上的均值分布无差异,即F(\overline{Y}_A) = F(\overline{Y}_B) ,其中\overline{Y}_A 和\overline{Y}_B 分别代表结果指标在A/B组样本上的结果均值。
基于中心极限定理: 大量互相独立的随机变量的均值分布趋近于正态分布,而与随机变量的具体分布无关,即\overline{Y}=\frac{1}{n}(Y_1+Y_2+…+Y_n) 趋近于正态分布。因此在处理结果数据时,并不需要考虑样本数据的分布情况,仅需考虑均值的正态分布,即\overline{Y} \sim N(μ, \frac{σ^2}{n}) ,其中μ代表样本总体均值, σ^2 代表样本总体方差,n 代表样本数。结合H_0 原假设F(\overline{Y}_A) = F(\overline{Y}_B) ,则μ_A=μ_B=μ, σ_A=σ_B=σ ,可得到如下分布形式,样本的均值差也服从正态分布。
步骤2:寻找反例推倒原假设。基于小概率原理,一个事件如果发生概率很小,则它在一次试验中几乎不可能发生。因此只要在某次随机对照试验中找到已发生的小概率事件,则等价于找到反例。在统计学中,显著性水平\alpha 通常设定为0.05。p 值是衡量观察数据与假设之间的差异指标,p 值越小则说明样本数据与假设之间的差异越大,当p 值小于0.05则拒绝原假设H_0 ,并认为结果是统计显著。

通常使用样本均值和样本方差构建统计量,判断两组数据的绝对差异是否显著。常见的假设检验方法,参数检验: Z检验、T检验、F检验;非参数检验: 卡方检验、二项检验等。
其中μ 为总体均值,σ 为总体标准差,\overline{X} 为样本均值,n 为样本量,S 为样本标准差,S^2 为样本方差,N_{oi} 为观测频数,N_{ei} 为理论期望频数。
DeltaMethod是一种概率分布逼近方法,通过线性逼近估计随机变量函数的概率分布。常用于计算复杂随机变量的方差、标准差等统计量,从而简化概率推断的计算过程。单变量DeltaMethod: 假设随机变量X_n 满足渐进正态性 [4]:
\sqrt{n}[X_{n}-\theta] \xrightarrow{D} \mathcal{N}(0,\sigma^{2}) ,其中\theta 和\sigma^{2} 是有限值常数,并且\xrightarrow{D} 表示分布收敛,则
给定函数g 和常量\theta ,函数g 在\theta 处的一阶导g'(\theta) 存在且非零值。
多变量DeltaMethod: 假设多元随机变量\{X_1, X_2, ...X_p\} 满足渐进正态性,\vec{X} 由向量构成\vec{X}=(X_1, X_2, ...X_p)' ,给定函数g 和常数向量\vec{\theta}=(\theta_{1},\theta_{2},...\theta_{p} )' ,且函数g 在\vec{\theta} 处的梯度\nabla g(\vec{\theta}) 存在,\nabla g(\vec{\theta}) = \left( \frac{\partial g}{\partial X_1}(\theta_1), \frac{\partial g}{\partial X_2}(\theta_2), \ldots, \frac{\partial g}{\partial X_p}(\theta_p) \right) ,则可以得到,服从近似服从正态分布。
var(\sqrt{n}[g(\vec{X}) - g(\vec{\theta})])= \nabla g(\vec{\theta})^T \cdot\Sigma \nabla g(\vec{\theta}) ,其中\Sigma 为\vec{X} 的协方差矩阵:
可以得到: Var(g(\vec{X}))\approx \frac{1}{n} \nabla g(\vec{\theta})^T \cdot \Sigma \nabla g(\vec{\theta})
线性回归
回归分析: 一种寻找因变量和自变量之间函数关系的统计方法,目的在于解释变量之间是否相关、相关方向及强度。线性回归是最简单的回归分析形式,函数关系可由线性函数表示。其中,最小二乘法(ordinary least squares,OLS) 是最常用的线性回归模型的系数求解方法。
定义总体线性回归模型如下:
其中系数\beta=(\beta_1, \beta_2, ... \beta_k)' ,X 是包含k 个自变量(解释变量)的向量,即X=(X_1, X_2, ... X_k)' ,Y 是因变量(被解释变量)。基于假设E(\epsilon | X) = 0 ,回归模型基于条件期望函数(CEF) 可表示为: E(Y|X)=E(X'\beta) .
使用最小二乘法求解系数估计值\widehat{\beta} ,实际就是最小化实际值与模型预测值的残差平方和,残差可表示为\widehat{\epsilon}=Y-\widehat{Y} = Y-X'b ,即求解问题 \widehat{\beta} = \underset{b}{argmin }E(Y-X'b)^2 。最小化条件是对$b$的一阶导数为0,即求导后满足: E[X(Y-X'\widehat{\beta})] = E[X\widehat{\epsilon}]=0 。最小二乘的本质是求解系数\widehat{\beta} ,使得因变量X 与残差\epsilon 不相关 E(\epsilon|X)= 0 。
E[X(Y-X'\widehat{\beta})] = 0 , 可以推导出:\widehat{\beta} =\frac{E(XY)}{E(XX')} = \frac{E(X(X'\beta + \epsilon))}{E(XX')} = \beta + \frac{E(X\epsilon)}{E(XX')} = \beta ,由此可得: 通过最小二乘法得到线性相关系数\widehat{\beta} 等价于线性模型中的系数\beta ,可进行因果关系解释。
示例: 分析受教育程度(EDU)对收入(INC)的因果影响,其中EDU和INC均为可观测变量,智商(IQ)是另一个观测变量,其他无法观测但会实际影响INC的变量称为干扰项e ,用线性函数描述为:
通过线性回归因果推断,希望识别出EDU对INC的因果影响系数\beta_1 。为保证能正确的识别因果关系,干扰项e 不能包含混淆变量,要求e 与解释变量无关,即E(e| EDU, IQ) = 0 。
回归系数求解如下,假设自变量不相关Cov(EDU, IQ)=0 ,则 \beta_1=\frac{Cov(EDU, INC)}{Var(EDU)} .
匹配方法
匹配方法基本原理:对于接受干预的个体,在控制组中找到可观测特征相同且未被干预的个体,通过比较观测结果估计干预效应。匹配方法需满足以下假设条件1:
假设1: 条件独立假设,给定观测特征后,潜在结果独立于干预状态。其数学表达为: \{Y_i(1), Y_i(0)\}\perp D_i | X_i ,也意味着在给定观测特征后,平均潜在结果和干预状态无关:
若以上条件同时成立,则给定观测特征后,平均干预效应ATE与干预状态无关。该假设也称为非混淆假设,意味除了观测变量X 外,不存在其他变量会混淆选择变量和观测结果的因果关系。
假设2: 共同支撑域条件: 给定可观测特征X_i = x ,个体接受干预的概率大于0且小于1,即表示为0 < P(D_i | X_i = x) < 1 。该条件确保存在部分个体接受干预,同时存在部分个体没有接受干预。
基于以上两个条件,可通过干预组-控制组观测结果差异计算出观测特征x 的平均干预效应。
可以得到ATE(x) = ATT(x) = ATU(x) ,基于特征为x 的ATT(x) ,进一步加权平均计算出:
当干预组与控制组只包含少数一个非连续观测变量,可使用直接匹配法对可观测的特征值进行精准匹配。如果可观测特征维数增加或者包含连续变量,则存在“维数诅咒”无法使用直接匹配法。
倾向性得分匹配(Propensity Score Matching, PSM):由Rosenbaum 和 Rubin于1983年提出,通过函数关系将多维变量X 变换为一维的倾向得分ps(X) ,基于倾向得分进行匹配。倾向得分是可观测特征X_i=x 的个体接受干预的概率,即 ps(X_i = x) = P(D_i = 1| X_i=x) 。由于可证明条件独立假设\{Y_i(1), Y_i(0)\}\perp D_i | X_i 等价于\{Y_i(1), Y_i(0)\}\perp D_i | ps(X_i) ,意味着如果干预组和控制组倾向性得分相同,则它们的可观测特征分布相同,可得到E(X_i|D_i=1, ps(x_i)) = E(X_i|D_i=0, ps(x_i)) 。多维特征x 的干预效应ATT(x) 可简化为:
对所有ATT(x) 加权平均可得到: ATT= E_{ps(x)|Di=1}(ATT(x))=\sum\limits_{x} ATT(x)P(ps(X_i=x)|D_i=1) .
在实际中,倾向性得分匹配法是最普遍使用的匹配方法,具体操作步骤包括[1]:
- 倾向得分估计: (1).模型选择: 通常使用Probit模型或者Logit模型;(2).变量选择
- 匹配前均衡校验: 校验倾向得分相同时,干预组和控制组基于观测特征X 分布无差异,即E(X_i|D_i=1, ps(x_i)) = E(X_i|D_i=0, ps(x_i)) .
- 共同支撑域条件评估: 尽可能保证干预组和控制组的样本分布重合,样本数量接近。
- 匹配方法选择: 选择合适方法进行干预组和控制组观测结果匹配计算。常见匹配方法有: (1). 分块匹配: 将样本按照倾向得分均衡划分区间,分别计算并汇总各个区间的干预效应; (2). 近邻匹配: 针对干预组样本,从控制组中选择倾向得分最接近的n 个样本匹配; (3). 卡尺匹配: 在近邻匹配基础上,要求匹配的倾向得分差异在一定的“卡尺”容忍程度内; (4). 半径匹配: 相比于卡尺匹配,允许满足容忍程度内的所有样本匹配,不限制n 个样本量; (5). 核匹配: 基于核函数进行匹配加权,距离越近的干预样本和控制样本,则权重越高,反之越低。
- 匹配后均衡校验: 检验匹配后的干预组和控制组的特征是否均衡,常见校验方法有: 标准化偏差、T 值检验、F 值检验。
- 计算干预效应: 除分块匹配法,其他匹配方法计算ATT可使用如下公式:
ATT = \frac{1}{N^{干预组}}\sum_{i\in I^{干预组}\bigcap S_p}\{Yi-\sum_{j\in I^{控制组}\bigcap S_p}w_{ij}Yj\} 其中,{N^{干预组}} 为干预组的样本个数,I^{干预组} 是干预组集合,S_p 是共同支撑域集合,I^{干预组}\bigcap S_p 是有共同支撑域的干预组样本,Yi 是干预组的样本观测结果;I^{控制组} 是控制组集合,I^{控制组}\bigcap S_p 是有共同支撑域的控制组样本,Yj 是控制组的样本观测结果,w_{ij} 是匹配权重。
面板分析法
线性回归和匹配方法都是通过控制可观测变量来推断因果关系,但现实中,很多混淆变量是无法观测。面板数据基于独特的多维数据结构,允许进一步控制不随时间变化的无法观测变量。面板数据(Panel Data): 是包含多个样本个体,且每个个体具有一系列不同时间观测点的数据,即面板数据同时包含个体横截面和时间序列的数据: 个体维度(i = 1,2, ...., N )和时间维度(t=1,2,...,T )。
面板数据变量X 的方差可分解如下:
可计算推导出 s^2_o \approx s^2_B + s^2_w ,因此,面板数据变量的总方差可分解为个体间方差和个体内方差。基于分解后的个体间和个体内的方差,可以明确较大的差异来源。如果变化更多来自于个体内差异,则说明变量随着时间存在变化;若变化更多来自个体间差异,则说明变量不随时间变化。
示例: 分析教育EDU与收入INC的影响,除此之外,影响因素还包括性别GENDER、个人天赋TALENT和运气LUCK,模型表示如下[1]:
基于线性回归,则不可观测的变量TALENT和 LUCK 都会归为一个干扰变量e_{it} ,INC_{it} = \alpha + \beta EDU_{it} + \gamma GENDER_{i} + e_{it} 。但基于面板数据,允许将干扰项中不可观测且不随时间变化的因素\alpha_i 分离出来: INC_{it} = \alpha + \beta EDU_{it} + \gamma GENDER_{i} + \alpha_i+ u_{it} ,并满足干扰项与变量无关假设,即E(u_{it}|EDU_{it}, GENDER_{i})= 0 .
根据\alpha_i 的不同假设,可分为三种面板数据模型:
- 合并横截面模型: 假设\alpha_i 不存在;
- 随机效应模型: 假设\alpha_i 存在,但是与自变量不相关,即E(\alpha_i|EDU_{it}, GENDER_{i}) = 0 ;
- 固定效应模型: 假设\alpha_i 存在,且与自变量相关,即E(\alpha_i|EDU_{it}, GENDER_{i}) \neq 0 ,此时不能直接将\alpha_i 当做干扰变量,需要与其他自变量处理等同。
固定效应模型可表示为如下形式:
模型假设条件为:\alpha_i 与自变量相关,u_{it} 与自变量无关,即E(\alpha_i|X_{it}, Z_i) \neq 0 ,E(u_{it}|X_{it}, Z_i) = 0 。\alpha_i 代表每个个体都有独立的截距项。 固定效应模型的常用估计方法: 个体内差分估计法、最小二乘虚拟变量估计法、一阶差分估计法。
双重差分法
双重差分法(Difference-in-Differences, DID): 也称为“准实验”法,常用于评估政策变化或治疗效果的影响,基本思想是通过比较干预组和控制组在处理前后的变化来估计干预效应。
横截面单重差分法: 通过比较干预组和控制组在事件干预后的平均结果差异来估计干预效应,将是否干预定义为Treat 变量, 模型为 Y_{it} = \beta_0 + \beta_1Treat_i + e_{it} , 其中干预后After_t=1 , 则干预组和控制组的观察差异均值可表示为:
为证明\widehat{\beta}_1 是{\beta}_1 的无偏估计量,需保证E( e_{it}|Treat_i = 1) - E( e_{it}|Treat_i = 0))= 0 , 即E( e_{it}|Treat_i = 1) = E( e_{it}|Treat_i = 0))= E( e_{it}|Treat_i)) =0 , 保证除了受是否接受干预的区别外,干预组和控制组不存在其他差别。现实中,该假设条件很难成立,上述模型中缺少变量控制干预前后After_t 的时间变化因素。
为解决单重差分无法控制的误差来源,引入双重差分法,通过两次差分处理消除误差,定义模型为:
其中,i 代表个体,t 代表时间,Treat_i 是干预分组变量,如果个体i 属于干预组,则Treat_i=1 ;否则属于控制组Treat_i=0 。After_t 是时间分组变量,时间t 在干预事件发生后,则After_t=1 ;否则After_t=0 ,模型需满足E(e_{it}|Treat_i, After_t) = 0 。
双重差分法回归系数图示[1]:
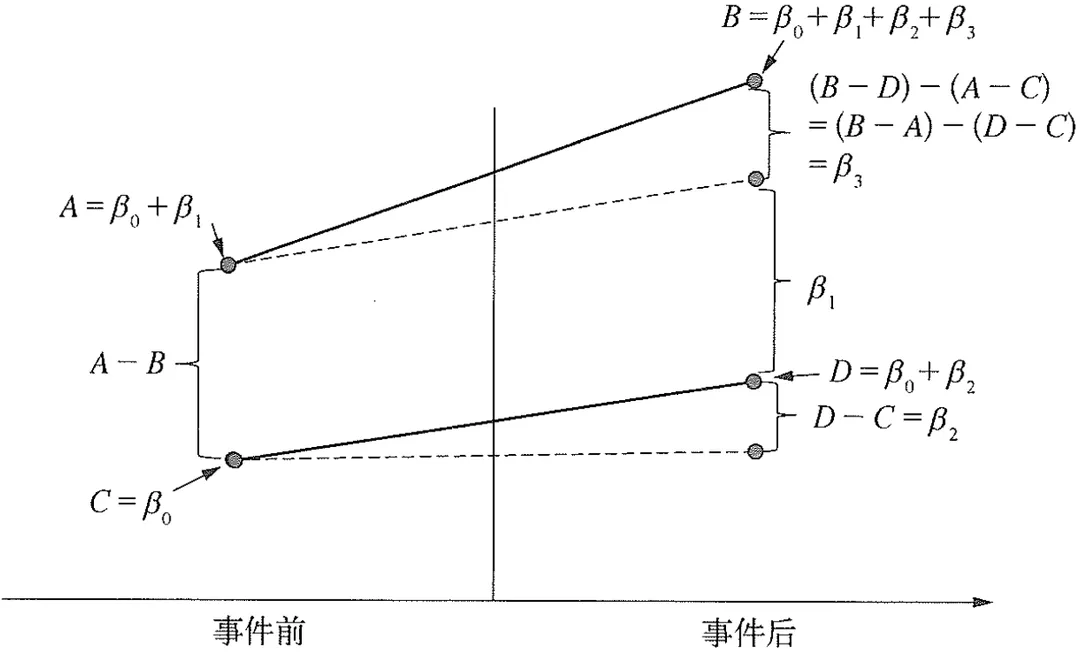
可得如下回归系数关系表:
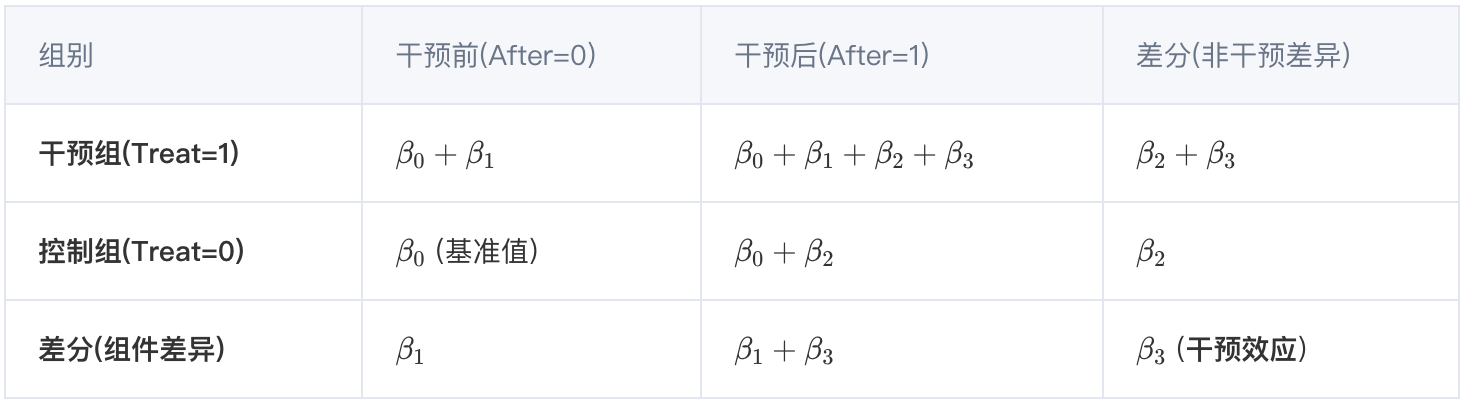
其中交乘项Treat_i \times After_t 的估计系数\beta_3 是双重差分估计量,可以从如下两个角度理解:
平行趋势假设: 使用双重差分法估计干预效应的关键假设,保证在没有干预事件发生的情况下,干预组和控制组的结果变量均值差异在不同时间内保持一致,即 E(Y_{it} | Treat_i=1,After_t=0) - E(Y_{it} | Treat_i=0, After_t=0) = \beta_1 成立。
工具变量法
在实际应用中,很多解释变量是不可观测且随时间变化的,通过不断添加控制变量“清理”干扰项并不可行,为解决该问题提出工具变量法。工具变量法通过增加工具变量,“清理”掉解释变量中与干扰项相关的部分,使用“清理”后的解释变量进行因果分析。
假设模型为: Y_i = \alpha + \beta_1D_i + e_i , 解释变量D_i 与干扰项e_i 相关,即Cov(D_i, e_i) \neq 0 , D_i 是内生变量。工具变量Z 需满足两个条件: (1). Z 与干扰项无关,Cov(Z_i, e_i) = 0 ; (2). Z 与原始解释变量D_i 强相关,Z 影响Y 只能通过路径Z \rightarrow D \rightarrow Y 实现,即。
- 工具变量估计: 间接最小二乘法(Indirect Least Squares, ILS)
假设内生变量$D$与工具变量$Z$的回归关系为: D_i = \gamma_0 + \gamma_1Z_i +u_i , 其中Cov(Z_i, u_i) = 0 ,回归系数\gamma_1=\frac{Cov(D_i, Z_i) }{Var(Z_i)} , 工具变量相关性Cov(D_i, Z_i) \neq 0 ,因此\gamma_1 \neq 0 . 可得结果方程为:
其中,\pi_1=\beta_1\gamma_1 ,可等价理解为: Z 对Y 作用(\pi_1 ) = Z 对D 作用(\gamma_1 ) \times D 对Y 作用(\beta_1 ), 基于因果路径图可表示为:
将\pi_1=\frac{Cov(Y_i, Z_i)}{Var(Z_i)} 和\gamma_1=\frac{Cov(D_i, Z_i)}{Var(Z_i)} 带入计算,可得到:
2. 工具变量估计: 两阶段最小二乘法(Two Stage Least Square, 2SLS)
第一阶段: 通过工具变量Z_i 将D_i 分解为两个不相关变量, D_i = \widehat{D}_i + v_i , 其中\widehat{D}_i = \gamma_0 + \gamma_1Z_i ,由于Z_i 与干扰项e_i 无关,因此 \widehat{D}_i 也与干扰项e_i 无关。
第二阶段: 使用\widehat{D}_i 估计D 对Y 的影响:
基于回归公式可得 \beta_1^{2SLS}=\beta_1^{ILS} :
附录
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
