HDFS元信息管理的核心技术与实现
原创HDFS元信息管理的核心技术与实现
原创
HDFS简介
HDFS(Hadoop Distributed File System)是大数据领域中一种核心分布式文件系统,以高可靠性和高扩展性为特点,为海量数据存储提供了高效解决方案。具备高度容错性,通过分布式架构实现数据的高效存储与管理,HDFS采用分块存储与冗余副本策略,确保数据的高可用性与持久性,同时支持高吞吐量的数据访问,满足大数据量处理对性能与稳定性的需求,适用于大规模数据存储和处理场景,特别是读多写少的场景。
架构简介
HDFS是经典的Master和Slave架构,每一个HDFS集群包括两个NameNode(Active/Standby)和多个DataNode。
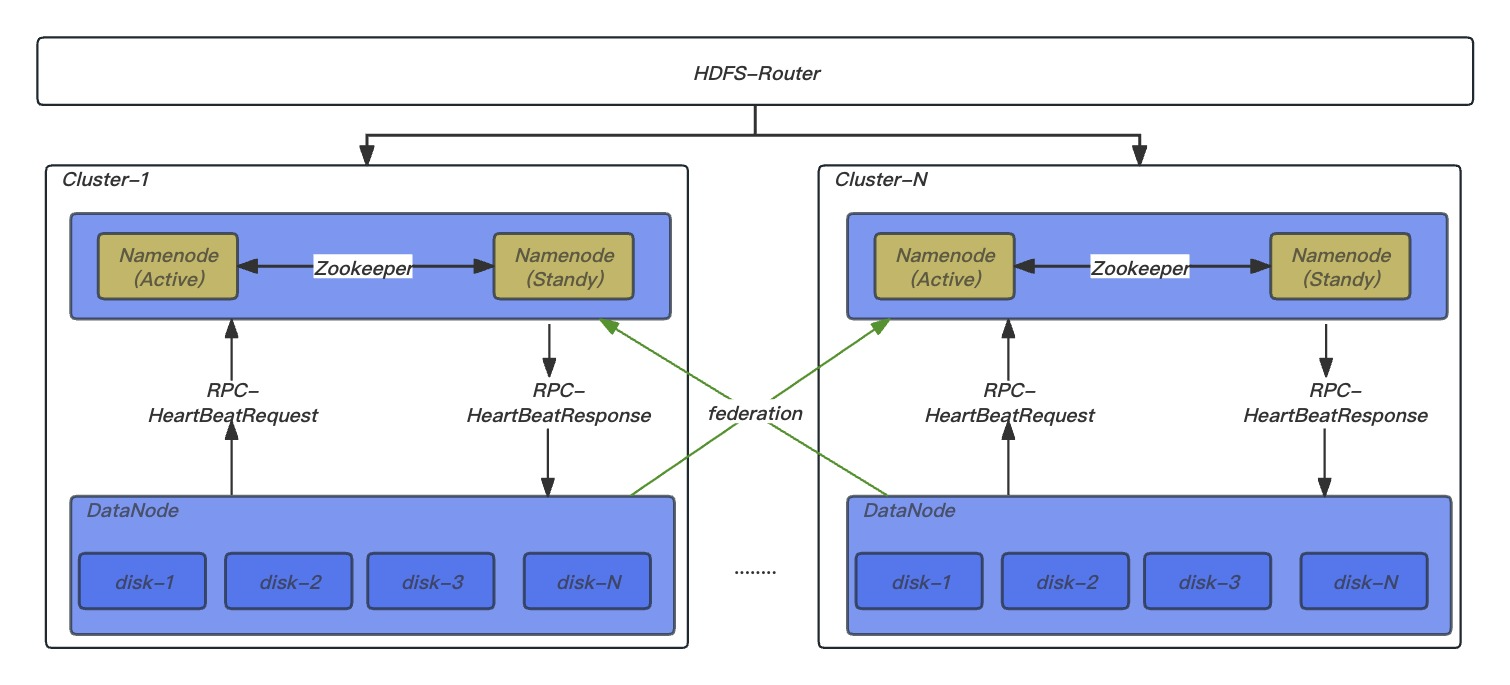
其中NameNode管理所有文件的元数据信息,并且负责与客户端交互。DataNode负责管理存储在该节点上的文件块。每一个上传到HDFS的文件都会被划分为一个或多个数据块,这些数据块根据HDFS集群的数据备份策略被分配到不同的DataNode上,位置信息交由NameNode统一管理。
名词解释
名称 | 描述 |
|---|---|
NameNode | 用于管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息,记录写入的每个数据块(Block)与其归属文件的对应关系。此信息以命名空间镜像(FSImage)和编辑日志(EditsLog)两种形式持久化在磁盘中。 |
DataNode | DataNode是Hadoop分布式文件系统(HDFS)中实际存储数据块的核心组件。DataNode会根据NameNode或Client的指令来存储或者提供数据块,并且定期地向NameNode汇报该DataNode存储的数据块信息。 |
Client | 通过Client来访问文件系统,然后由Client与NameNode和DataNode进行通信。Client对外作为文件系统的接口。 |
INode | 用于描述HDFS文件系统对象,元信息重要组成部分。INodeFile表示一个文件, INodeDirectory文件目录, INodeAttributes文件属性(group\owner\permission\accessTime\modifyTime\Acl\XAttr), INodeDirectoryWithQuota有配额限制的目录。INodeFileUnderConstruction处于构建状态的文件。 |
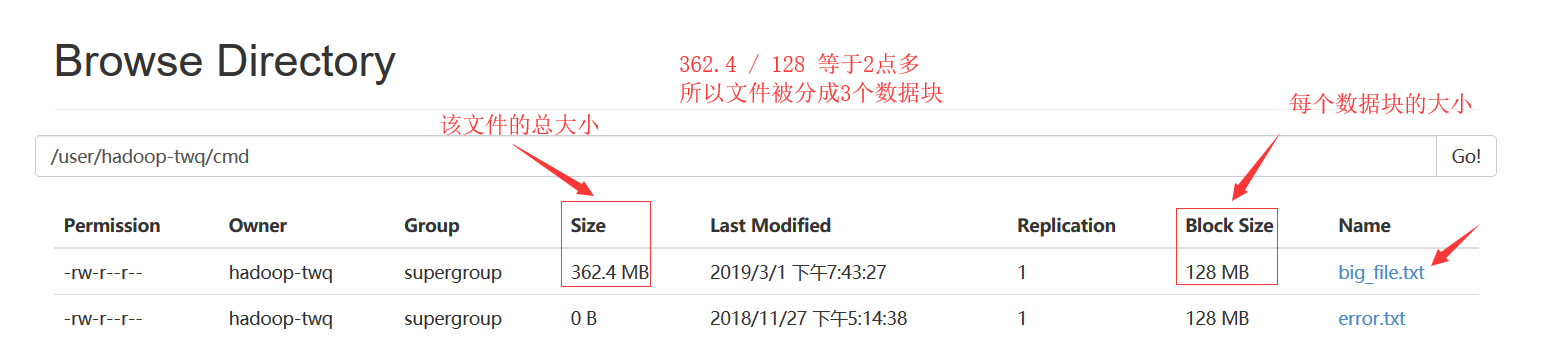
Blocks | HDFS将文件拆分成128 MB大小的数据块进行存储,这些Block可能存储在不同的节点上。HDFS可以存储更大的单个文件,甚至超过任何一个磁盘所能容纳的大小。一个Block默认存储3个副本,以Block为粒度将副本存储在多个节点上。此方式不仅提高了数据的安全性,而且对于分布式作业可以更好地利用本地的数据进行计算,减少网络传输。 |
Federation | HDFS为扩展单Namenode管理元信息容量限制而引入的联邦机制,一个集群有多个命名空间,即多个 Namenode,提供元信息管理水平扩展能力及隔离能力。 |
Router | 引入联邦机制后解决多Namenode管理问题,屏蔽 Federation 的实现细节;作为Namenode代理服务结合目录挂载表,将请求转发给正确的子集群,为用户提供了统一目录视图管理。 |

元信息管理
为加快元信息访问,服务运行时元信息存放在Namenode服务内存中,由两部分组成:
- 存在磁盘上的fsimage与editLog,Namenode启动时加载,生成文件与Block映射;
- Datanode服务启动后向Namenode汇报Block信息,并更新BlockMap完成Block与机器的映射更新,这部分是动态构建起来的;
简单说:Namenode管理文件切分成了几个数据块以及这些数据块分别存储在哪些datanode上;
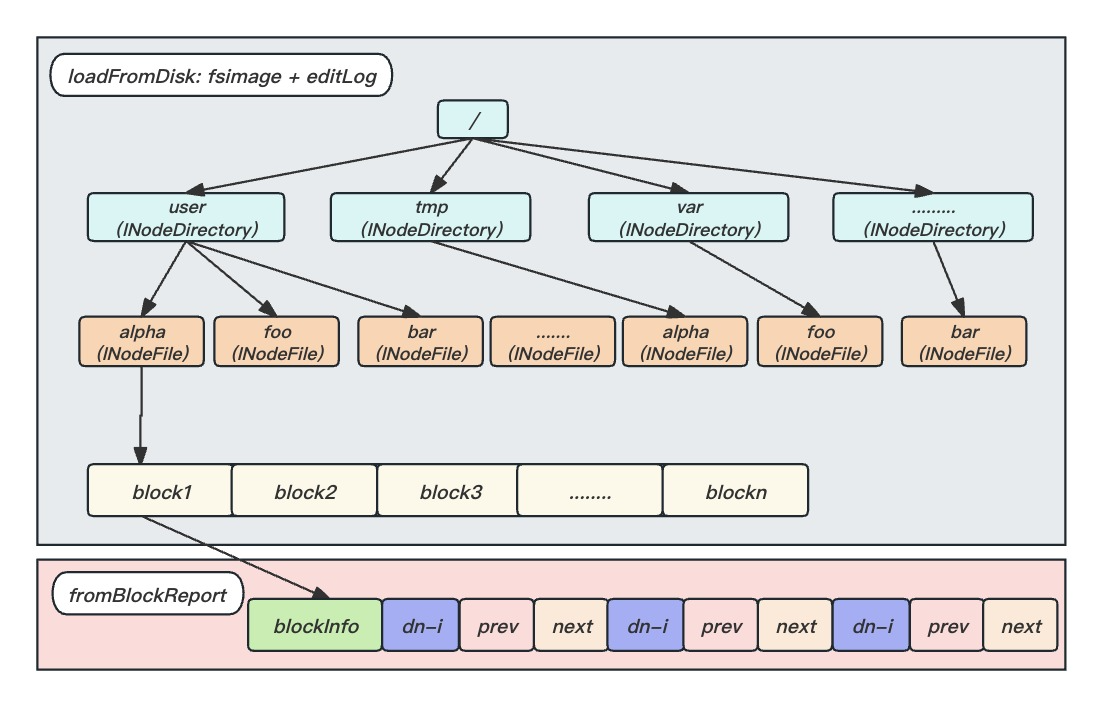

BlockInfo非常核心的属性triplets的数组,这个数组的长度是3*replication,replication表示数据块的备份数。这个数组中存储了该数据块所有的备份数据块对应的DataNode信息,我们现在假设备份数是3,那么这个数组的长度是 3 * 3,这个数组存储的数据如下:

tripletsi:Block所在的DataNode;tripletsi+1:该DataNode上前一个Block;tripletsi+2:该DataNode上后一个Block;其中i表示的是Block的第i个副本,i取值[0,replication)。
1.1 Namenode 端
1.1.1 FsImage & EditLog(Namenode )
FsImage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
Editlog是记录HDFS元信息各种更新操作,HDFS客户端执行所有的写操作都会被记录到editlog中。为了避免editlog不断增大,namenode(StandyBy)会周期性合并fsimage和edits成新的fsimage,这个周期可以自己设置(editlog到达一定大小或者定时)
Namenode启动加载文件元信息过程:
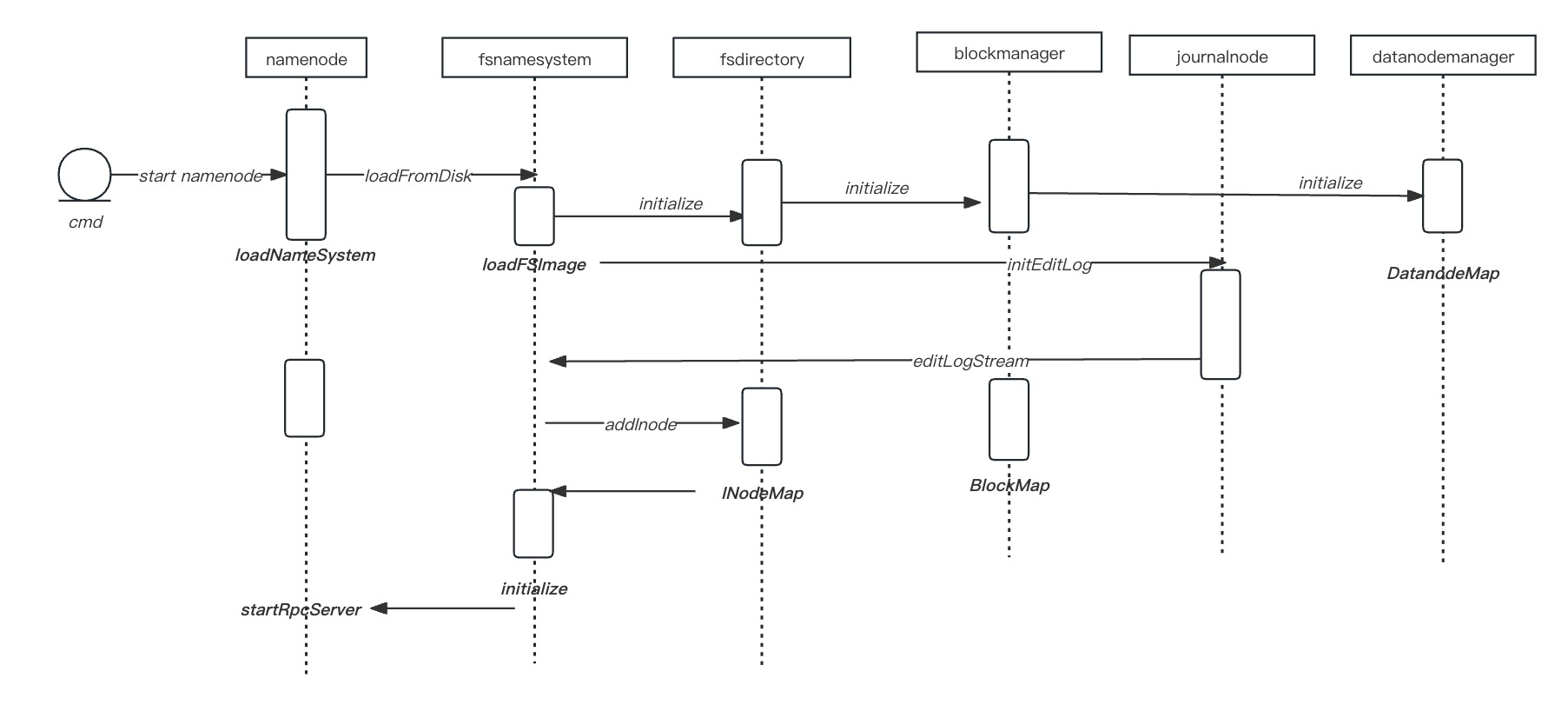
fsimage加载解析:
# fsimage-analysis
<?xml version="1.0"?>
<fsimage>
<NameSection>
<genstampV1>1000</genstampV1><genstampV2>1003</genstampV2><genstampV1Limit>0</genstampV1Limit><lastAllocatedBlockId>1073741827</lastAllocatedBlockId><txid>2632</txid>
</NameSection>
<INodeSection>
<lastInodeId>16406</lastInodeId>
<inode><id>16385</id><type>DIRECTORY</type><name></name><mtime>1555489279780</mtime><permission>hadoop:supergroup:rwxrwxrwx</permission><nsquota>9223372036854775807</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16386</id><type>DIRECTORY</type><name>testdba</name><mtime>1555504839494</mtime><permission>hadoop:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16388</id><type>DIRECTORY</type><name>test100</name><mtime>1555349720236</mtime><permission>hadoop:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16389</id><type>FILE</type><name>zookeeper-3.4.5-cdh5.4.11.tar.gz</name><replication>2</replication><mtime>1555349720231</mtime><atime>1555349720000</atime><perferredBlockSize>134217728</perferredBlockSize><permission>hadoop:supergroup:rw-r--r--</permission>
<blocks><block><id>1073741826</id><genstamp>1002</genstamp><numBytes>27595964</numBytes></block></blocks></inode>
<inode><id>16405</id><type>DIRECTORY</type><name>test300</name><mtime>1555504851619</mtime><permission>hadoop:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16406</id><type>DIRECTORY</type><name>test3000</name><mtime>1555504851619</mtime><permission>hadoop:supergroup:rwxr-xr-x</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection> <SnapshotSection><snapshotCounter>0</snapshotCounter></SnapshotSection>
<INodeDirectorySection>
<directory><parent>16385</parent><inode>16386</inode></directory> <directory><parent>16386</parent><inode>16388</inode><inode>16405</inode></directory> <directory><parent>16388</parent><inode>16389</inode></directory> <directory><parent>16405</parent><inode>16406</inode></directory>
</INodeDirectorySection>
<FileUnderConstructionSection></FileUnderConstructionSection>
<SnapshotDiffSection><diff><inodeid>16385</inodeid></diff></SnapshotDiffSection>
<SecretManagerSection><currentId>0</currentId><tokenSequenceNumber>0</tokenSequenceNumber></SecretManagerSection> <CacheManagerSection><nextDirectiveId>1</nextDirectiveId></CacheManagerSection>
</fsimage># fsimage-keyword
NS_INFO("NS_INFO"),
STRING_TABLE("STRING_TABLE"),
EXTENDED_ACL("EXTENDED_ACL"),
INODE("INODE"),
INODE_REFERENCE("INODE_REFERENCE"),
SNAPSHOT("SNAPSHOT"),
INODE_DIR("INODE_DIR"),
FILES_UNDERCONSTRUCTION("FILES_UNDERCONSTRUCTION"),
SNAPSHOT_DIFF("SNAPSHOT_DIFF"),
SECRET_MANAGER("SECRET_MANAGER"),
CACHE_MANAGER("CACHE_MANAGER");INodeMap:存储 INode 与 Block 映射
INodeMap 负责维护 INode(索引节点)到数据块(Block)之间的映射关系,采用LightWeightGSet结构存储,LightWeightGSet是一个占用较低内存的集合的实现,它使用一个数组array存储元素,使用链表来解决冲突,它没有实现重新哈希分区,所以,内部的array不会改变大小; INodeMap数组大小占JVM总内存 1%: 通过调用LightWeightGSet.computeCapacity(1, "INodeMap")确保了内存资源的合理分配,还有效避免了因过度分配或不足导致的性能瓶颈。
1.1.2 FSNamesystem (Namenode)
NameNode 实际记录信息、核心功能处理地方,其中与写操作重要相关的文件租约管理LeaseManager:
- HDFS特点支持Write-Once-Read-Many,对文件写操作的互斥同步靠Lease实现。Lease实际上是时间约束锁,其主要特点是排他性。客户端写文件时需要先申请一个Lease,一旦有客户端持有了某个文件的Lease,其它客户端就不可能再申请到该文件的Lease,这就保证了同一时刻对一个文件的写操作只能发生在一个客户端。
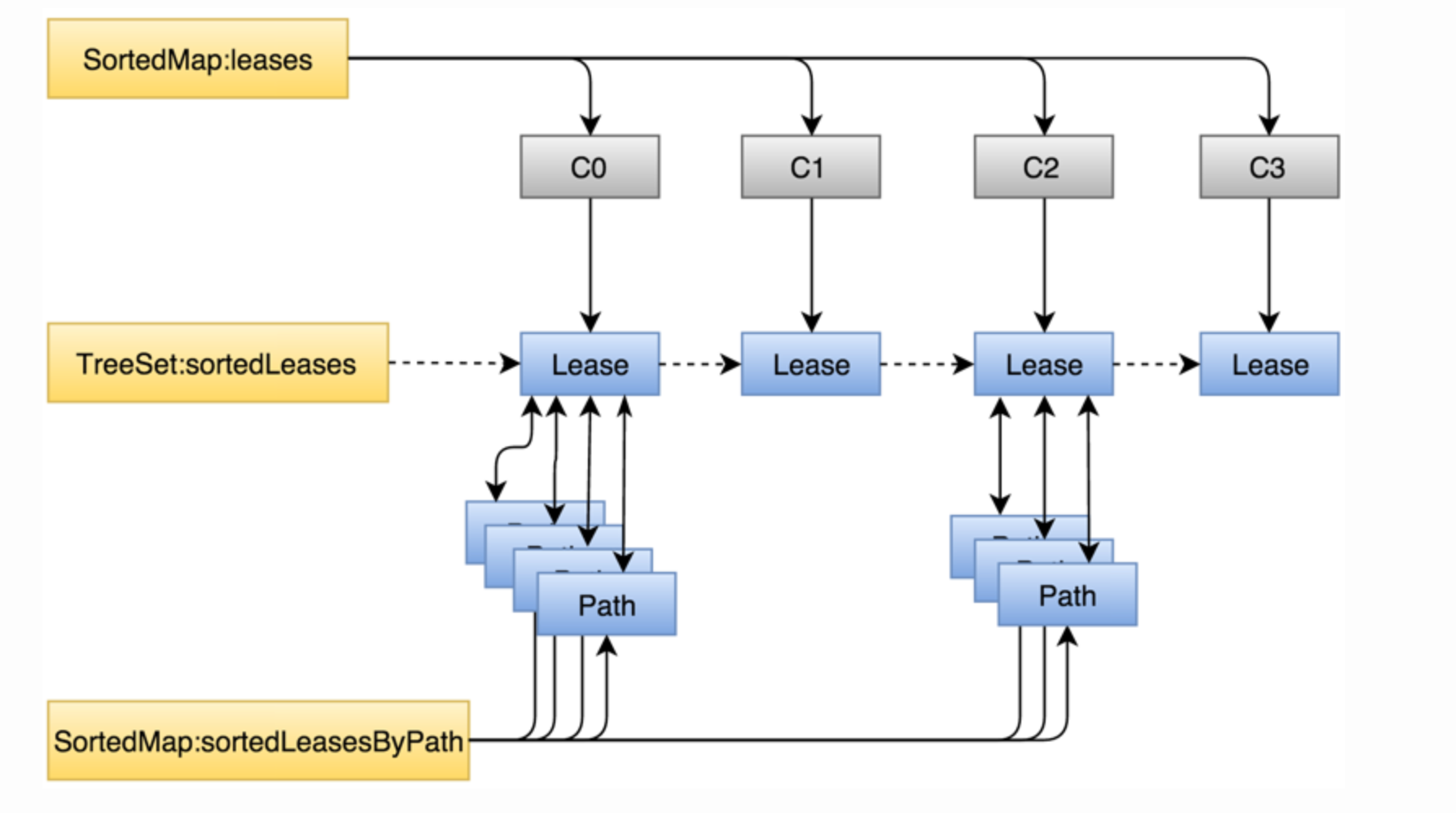
- 由于Lease本身的时间约束特性,当Lease发生超时后需要强制回收,内存中与该Lease相关的内容要被及时清除。超时检查及超时后的处理逻辑由LeaseManager.Monitor统一执行。LeaseManager中维护了两个与Lease相关的超时时间:软超时(softLimit)和硬超时(hardLimit),使用场景稍有不同。
正常情况下,客户端向集群写文件前需要向NameNode的LeaseManager申请Lease;写文件过程中定期更新Lease时间,以防Lease过期,周期与softLimit相关;写完数据后申请释放Lease。整个过程可能发生两类问题:
写文件过程中客户端没有及时更新Lease时间; 写完文件后没有成功释放Lease。
两个问题分别对应为softLimit和hardLimit。两种场景都会触发LeaseManager对Lease超时强制回收。如果客户端写文件过程中没有及时更新Lease超过softLimit时间后,另一客户端尝试对同一文件进行写操作时触发Lease软超时强制回收;如果客户端写文件完成但是没有成功释放Lease,则会由后台线程LeaseManager.Monitor检查是否硬超时后统一触发超时回收,保证后面其它客户端的写入能够正常申请到该文件的Lease。
1.1.3 BlockManager(Namenode)
BlockManager最重要的功能之一是维护Namenode内存中的数据块信息,通过对以下两部分内容进行修改实现的
■ 数据块与存储这个数据块的数据节点存储的对应关系, 这部分信息保存在数据块对应的BlockInfo对象的triplets[]数组中, Namenode内存中的所有BlockInfo对象则保存在BlockManager.blocksMap字段中。
■ 数据节点存储与这个数据节点存储上保存的所有数据块的对应关系, 这部分信息保存在DatanodeStorageInfo.blocks字段中, blockList是BlockInfo类型的, 利用BlockInfo.triplets[]字段的双向链表结构 ,DatanodeStorageInfo可以通过blockList字段保存这个数据块存储上所有数据块对应的BlockInfo对象。
■ DatanodeManager: BlockManager 负责接收管理来自 DataNode 的消息,具体的管理操作由 DatanodeManager 接管,他负责监控 DataNode 节点的状态变化以及消费 Block 信息变化指令。
■ DocommissionManager: 管理需要退役或检修的节点信息,在确保这些节点上的数据都被成功转移后,才将节点置为退役和检修状态,避免直接设置导致的数据丢失。
待处理不同状态Block:
/** Store blocks -> datanodedescriptor(s) map of corrupt replicas */
final CorruptReplicasMap corruptReplicas = new CorruptReplicasMap();
/** Blocks to be invalidated. */
private final InvalidateBlocks invalidateBlocks;
/**
* After a failover, over-replicated blocks may not be handled
* until all of the replicas have done a block report to the
* new active. This is to make sure that this NameNode has been
* notified of all block deletions that might have been pending
* when the failover happened.
*/
private final Set<Block> postponedMisreplicatedBlocks = Sets.newHashSet();
/**
* Maps a StorageID to the set of blocks that are "extra" for this
* DataNode. We'll eventually remove these extras.
*/
public final Map<String, LightWeightLinkedSet<Block>> excessReplicateMap =
new TreeMap<String, LightWeightLinkedSet<Block>>();
/**
* Store set of Blocks that need to be replicated 1 or more times.
* We also store pending replication-orders.
*/
public final UnderReplicatedBlocks neededReplications = new UnderReplicatedBlocks();
final PendingReplicationBlocks pendingReplications;由ReplicationMonitor周期默认3s执行block扫描, 如:
- 复制操作:从blockManager中的待复制数据块列表neededReplications中选出若干个数据块执行复制操作,为这些数据块的复制操作选出source源节点以及target目标节点,然后将其封装成BlockTargetPair对象添加到DatanodeDescriptor.replicateBlocks中,等待下次该DataNode心跳的时候将构造复制指令带到目标节点以执行副本的复制操作。
- 删除操作:从blockManager中的待删除数据块列表invalidateBlocks中选出若干个副本,然后构造删除指令,也即是将blockManager.invalidateBlocks中的待删除数据块添加到对应的DatanodeDescriptor.invalidateBlocks中,等待下次该DataNode心跳的时候将构造删除指令带到目标节点以执行副本的删除操作。
1.2 Datanode 端
1.2.1 BlockPoolMananger(Datanode )
Datanode 负责存储和管理数据Block,启动向Namenode注册后,将存储的Block信息汇报给Namenode;单台Datanode服务支持多磁盘挂载用于存储数据块(dfs.datanode.data.dir); 多个存储目录存储的数据块并不相同, 并且不同的存储目录可以是异构的, 这样的设计可以提高数据块IO的吞吐率;
datanode磁盘目录结构
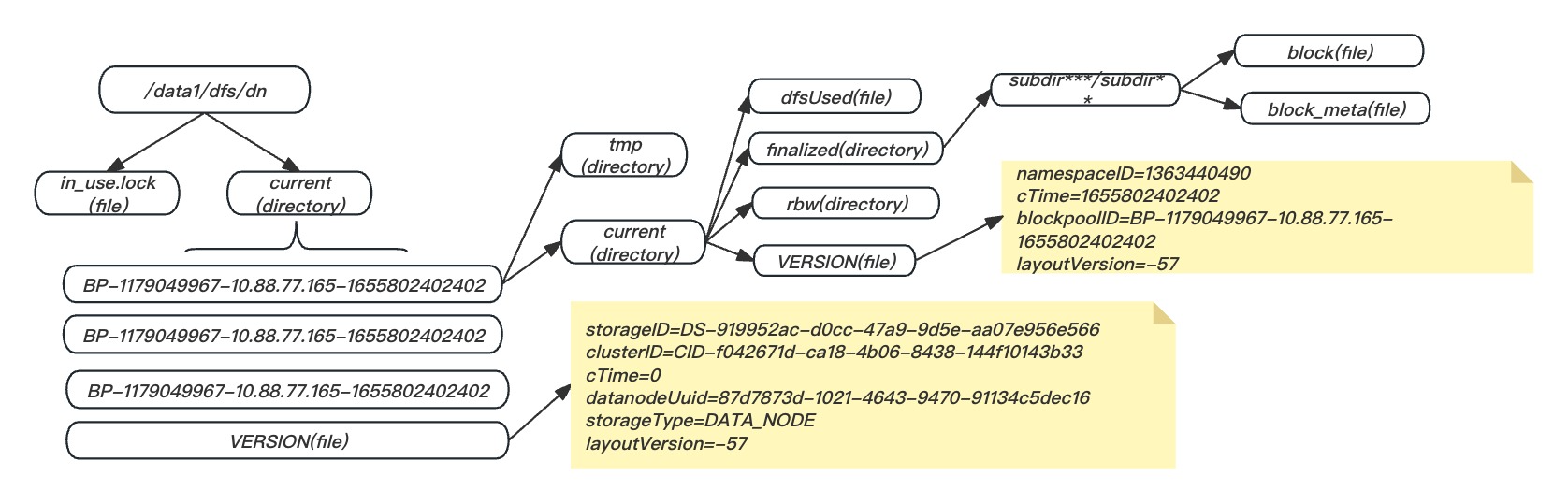
current目录包含finalized、 rbw以及lazyPersisit三个子目录。finalized目录保存了所有FINALIZED状态的副本, rbw目录保存了RBW(正在写) 、 RWR(等待恢复) 、 RUR(恢复中) 状态的副本, tmp目录保存了TEMPORARY状态的副本。
当集群数据量达到一定程度时, finalized目录下的数据块将会非常多。 为了便于组织管理, 数据块将按照数据块id进行散列, 拥有相同散列值的数据块将处于同一个子目录下,不同版本目录层级限制不同(2.7.x -- 256 * 256,2.8.x -- 32 * 32)
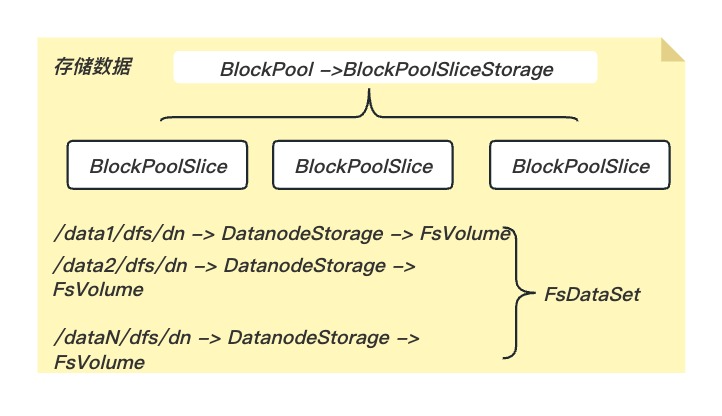
以Federation架构为例,一个Datanode节点会同时向多个Namenode节点注册并提供数据块存储服务,HDFS规定了一个目录能存放Block的数目,所以一个Storage上存在多个目录。管理工作划分:
■ BlockPoolSlice: 管理一个指定块池在一个指定存储目录下的所有数据块。 由于Datanode可以定义多个存储目录, 所以块池的数据块会分布在多个存储目录下。一个块池会拥有多个BlockPoolSlice对象, 这个块池对应的所有BlockPoolSlice对象共同管理块池的所有数据块。
■ FsVolumelmpl: 管理Datanode一个存储目录下的所有数据块。 由于一个存储目录可以存储多个块池的数据块, 所以FsVolumelmpl会持有这个存储目录中保存的所有块池的BlockPoolSlice对象。
■ FsVolumeList: Datanode可以定义多个存储目录, 每个存储目录下的数据块是使用一个FsVolumelmpl对象管理的, 所以Datanode定义了FsVolumeList类保存Datanode上所有的FsVolumelmpl对象, FsVolumeList对FsDatasetlmpl提供类似磁盘的服务。
datanode 启动过程
Datanode#runDatanodeDaemon() ⇒ BlockPoolManager.startAll();
⇒ BPOfferService#start() ⇒ BPServiceActor#start() => BPServiceActor#run() ⇒ connectToNNAndHandshake();
==> bpos.verifyAndSetNamespaceInfo(this, nsInfo); ==> DataNode.initBlockPool(this);
⇒ FsDatasetImpl#addBlockPool() ⇒ FsVolumeList#addBlockPool() ⇒FsVolumeImpl#addBlockPool()
==> new BlockPoolSlice(bpid, this, bpdir, c, new Timer());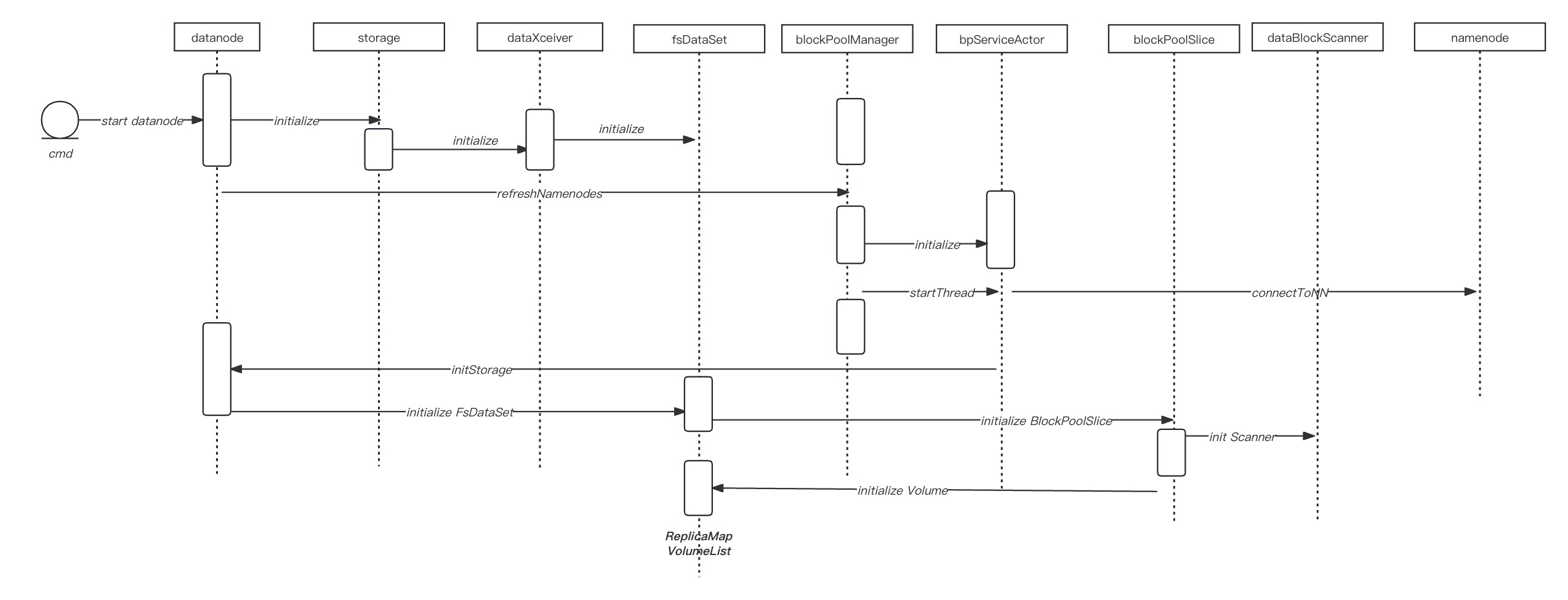
1.2.2 FsDataSet
与块相关的操作由Dataset相关的类处理,存储结构由大到小是卷(FSVolume)、目录(FSDir)和文件(Block和元数据等
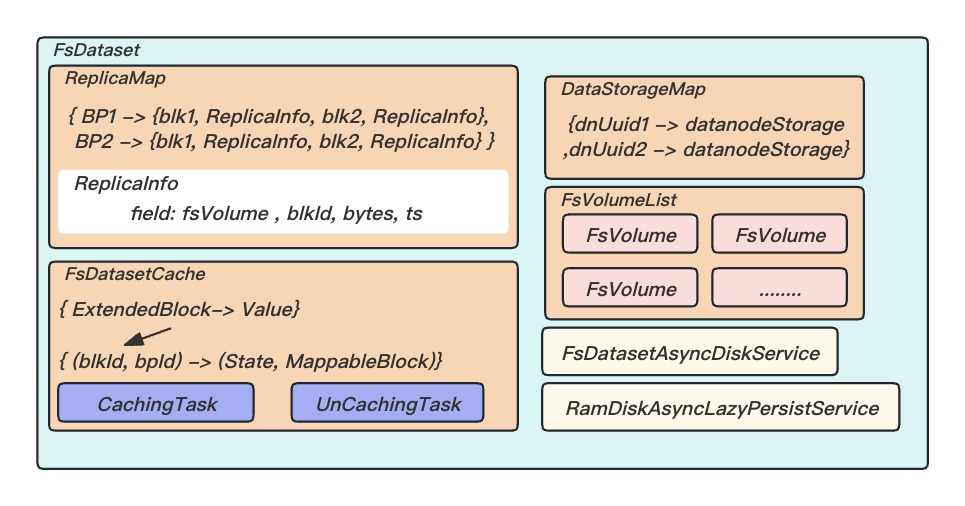
ReplicaMap
维护Datanode上所有数据块副本, 副本包含5种状态,Datanode会将不同状态的副本存储到磁盘的不同目录下, 也就是 Datanode上副本的状态是会被持久化的。
■ FINALIZED:Datanode上已经完成写操作的副本。 Datanode定义了FinalizedReplica类来保存FINALIZED状态副本的信息。
■ RBW(Replica Being Written):刚刚由HDFS客户端创建的副本或者进行追加写(append) 操作的副本, 副本的数据正在被写入, 部分数据对于客户端是可见的。 Datanode定义了ReplicaBeingWritten类来保存RBW状态副本的信息。
■ RUR(Relica Under Recovery):进行块恢复时的副本。 Datanode定义了ReplicaUnderRecovery类来保存RUR状态副本的信息。
■ RWR(ReplicaWaitingToBeRecovered):如果Datanode重启或者宕机, 所有RBW状态的副本在Datanode重启后都将被加载为RWR状态, RWR会等待块恢复操作。 Datanode定义了ReplicaWaitingToBeRecovered类来保存RWR状态副本的信息。
■ TEMPORARY:Datanode之间复制数据块, 或者进行集群数据块平衡操作(cluster balance) 时, 正在写入副本的状态就是TEMPORARY状态。 和RBW不同的是, TEMPORARY状态的副本对于客户端是不可见的, 同时Datanode重启时将会直接删除处于TEMPORARY状态的副本。 Datanode定义了ReplicaInPipeline类来保存TEMPORARY状态副本的信息。
FSVolumeList
FSVolumeList对所有的FSVolume对象进行管理,实际上就是对所有的存储路径进行管理。FSVolumeList主要为上层(DataNode进程)提供存储数据块选择一个的存储路径(分区),就是为该数据块创建一个对应的本地磁盘文件,同时也负载统计它的存储空间的状态信息和收集所有的数据块信息。其中一个FSVolume对应一个Storage,内部由FSDir对应一个目录;
2.数据读写
2.1文件删除过程
通过Hadoop客户端执行删除命令 rm -skipTrash 过程如下:
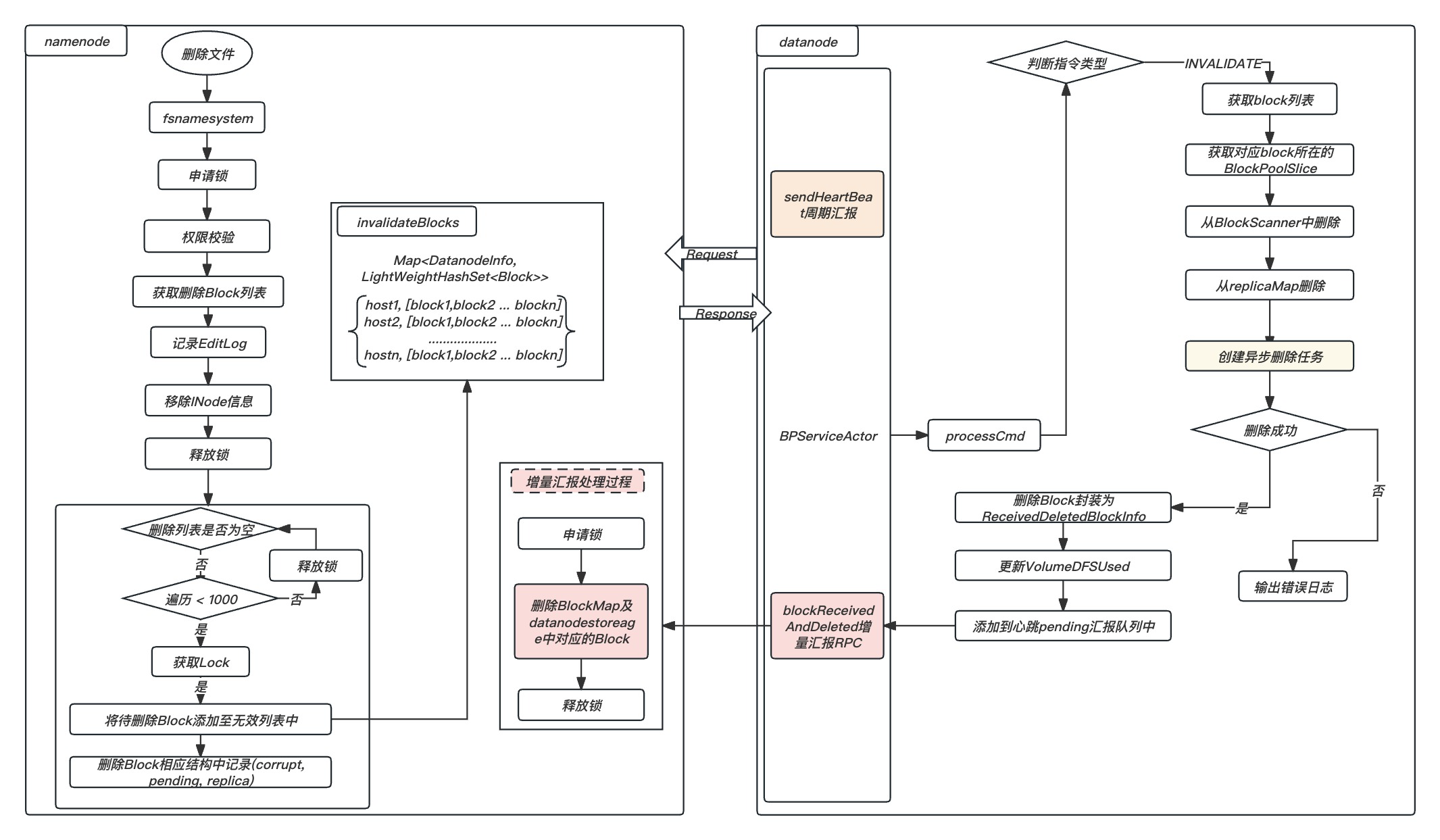
注意:避免短时间内删除大文件,降低NN-RPC处理性能及DN大量数据删除IO升高,对集群吞吐造成影响;
2.2 文件写入过程
通过DFSClient创建文件写入数据过程如下:
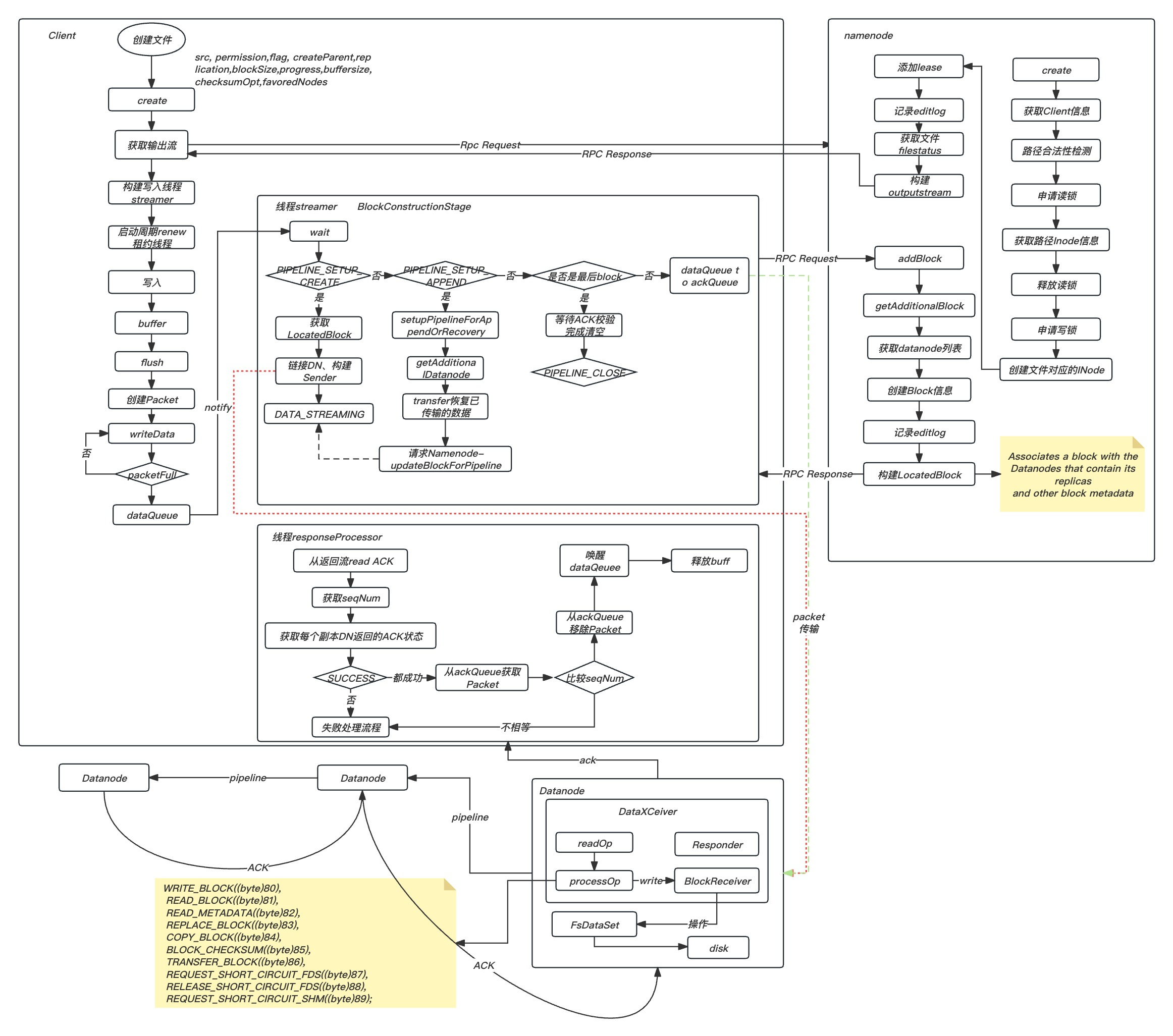
如果写满了一个数据块, 客户端会调用ClientProtocol.addBlock()方法向Namenode申请一个新的数据块。 这个请求到达Namenode后会由FSNamesystem.getAdditionalBlock()方法响应,getAdditionalBlock()方法首先会检查文件系统状态, 然后为新添加的数据块选择存放副本的Datanode, 最后构造Block对象并调用FSDirWriteFileOp.storeAllocatedBlock()方法将Block对象加入文件对应的INode对象中。
更新并持久化内存中.最后向client返回存储信息;当Datanode上写入了一个新的数据块副本或者完成了一次数据块副本复制操作后, 会通过DatanodeProtocol.blockReport()或DatanodeProtocol.blockReceivedAndDeleted()方法向Namenode汇报该Datanode上添加了一个新的数据块副本。
Datanode视角看pipeline写的流程:
每个datanode会创建一个线程DataXceiverServer,接收上游过来的TCP连接,对于每个新建的TCP连接,都会创建一个叫做DataXceiver的线程处理这个连接. 这个线程不断的从TCP连接中读op,然后调用processOp(op)处理这个op,这里以write block 这个op为例,由DataXceiver的writeBlock函数实现:
大体步骤如下:
new 一个BlockReceiver对象,随后用于接收上游(client或者datanode)的block数据; 根据传进来的DatanodeInfo数组,向数组的第一个元素代表的datanode建立TCP连接; 2.1. 调用Sender的writeBlock方法给下游datanode发送write block相关元信息,包括DatanodeInfo数组(刨去第一个元素),clientname,block的当前gs,minBytesRcvd,maxBytesRcvd(对于append,recovery操作有用)等; 2.2. 读取下游的回复,封装在BlockOpResponseProto对象中,可以通过内部成员firstBadLink知道建pipeline中第一个失败的datanode节点。接着将BlockOpResponseProto回复给上游 (datanode或者client) 2.3. 最后调用第一步new的BlockReceiver的receiveBlock方法用于接收一个完整的block. receiveBlock内部根据clientname发现是一个客户端在写block,创建一个PacketResponder线程用于处理下游datanode对packet的ack.PacketResponder后面分析。 2.4 不断的调用receivePacket()方法从上游(datanode或者client)接收一个个的packet,接收一个完整的packet的逻辑是由内部的PacketReceiver来处理的。对于一个接收到的packet,写入block file文件,同时checksum信息写meta文件,然后放入PacketResponder的ack queue队列,然后将packet写给下游的datanode。 2.5 最后调用PacketResponder的 close方法,这个方法会等到ack queue为空,即所有packet都已经从下游收到,并且已经给上游ack. 3.receiveBlock()结束后,关掉和上下游的连接.
清空ack queue的逻辑由专门处理下游ack包的PacketResponder线程处理,逻辑如下:
如果datanode是pipeline的中间node(通过PacketResponder的type属性来决定,LAST_IN_PIPELINE和HAS_DOWNSTREAM_IN_PIPELINE),从下游读一个PipelineAck并拿到seqno,然后从ack queue中get(不删除)第一个packet,拿出seqno,记作expected_seq_no,然后比较是否相等,如果不相等,说明写出错。 如果从ack queue中get的packet是block的最后一个packet,说明一个block接收完成.那么调用finalizeBlock方法。关闭block file和meta file文件,调用FsDatasetImpl的finalizeBlock(block)将block文件以及对应的meta文件移动到对应的block pool下的finalized目录下,然后生成一个FinalizedReplica对象,将bpid->FinalizedReplica的映射关系记录在内存中的volumnMap中,对象位于FsDatasetImpl下的ReplicaMap volumnMap(从ReplicaMap中定位一个ReplicaInfo,需要拿着bpid和block id去找)最后调用datanode的closeBlock()方法, ,最后调用DatanodeProtocolClientSideTranslatorPB bpNamenode的blockReceivedAndDeleted()将block信息汇报上给namenode,实现数据块更新. 给从下游接收的ack回复给上游。 将packet从ack queue的头部删除。
在HDFS中,数据块(block)的写操作依赖于两个关键线程的协同工作,这两个线程分别是 DataXceiver 和 PacketResponder,它们通过明确的职责分工和紧密的协作机制,以确保数据传输的高效性、可靠性和一致性。
DataXceiver 负责从上游节点接收数据流,并高效地写入本地存储介质。它不仅需要处理网络层的通信细节,还需确保数据包(packet)在本地节点的正确存储与完整性校验,从而为后续的数据持久化奠定基础。
PacketResponder 线程则专注于数据传输的可靠性保障。其主要职责是处理来自下游节点的确认消息(ACK),并对整个数据传输链路进行状态同步和一致性校验。通过对接收到的 ACK 消息进行解析和验证,PacketResponder 能够确保每个数据块在下游节点的写入操作已成功完成,并据此向上游节点发送相应的确认信号。这种基于 ACK 的反馈机制构确保了数据传输可靠性。
尚未收到下游节点确认响应且未向上游节点回复确认的数据包会被暂存于一个特殊的队列——ACK queue。该队列充当了数据传输过程中的缓冲区,用于管理数据包的状态流转和重传逻辑。ACK queue为系统的容错能力提供了重要支撑。
从架构设计层面来看,DataXceiver 和 PacketResponder 的协同工作不仅是分布式存储系统中数据流管理的核心,也是现代分布式系统设计理念的典范,为更广泛的分布式应用场景提供了重要的参考价值。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
