GPT-4o原生图像生成上线!10秒完成“用嘴改图”

GPT-4o原生图像生成上线!10秒完成“用嘴改图”

用户11203141
发布于 2025-03-31 19:38:31
发布于 2025-03-31 19:38:31
就在谷歌刚发布号称“地表最强推理模型”的Gemini 2.5 Pro后不久。OpenAI深夜突袭,用一场30分钟的“轻量级发布会”扔出重磅炸弹——GPT-4o的原生图像生成功能正式上线。从自拍秒变动漫风,到生成相对论漫画,再到准确渲染复杂文本,GPT-4o的多模态能力让人眼前一亮。那么,OpenAI这波操作究竟能否在AI大战中扳回一局?让我们一探究竟。
深夜直播中,奥特曼亲自上阵,带领团队展示GPT-4o原生图像生成的功能。把一张三人自拍瞬间变成动漫风格,还在图片中玩梗加入了“feel the agi”文字。

相比以往依赖DALL-E 3的图像生成方式,GPT-4o的突破在于其原生多模态能力。作为一个统一的模型,它不再是单纯的语言或图像生成工具,而是能无缝处理文本、图像、音频等多种输入输出形式。

上图⬆️白板上的人物倒影都准确地对应了他们的动作
上图⬆️白板上的人物倒影都准确地对应了他们的动作
文本渲染
GPT-4o在文本渲染上的表现堪称惊艳。比如,给一段文字要求GPT-4o生成一张餐厅菜单。它不仅能够展现出精致的画面效果,还将每道菜的名称、价格及描述精准呈现,仿佛一张真实的菜单。

甚至在复杂场景中,如街头标牌上荒诞的“女巫扫帚停车禁区”提示、婚礼请柬生成,GPT-4o也能分毫不差地还原。


指令遵循
GPT-4o的图像生成遵循详细的指令,注重细节。当其他模型还难以处理5-8个对象时,GPT-4o可以处理多达10-20个不同的对象。
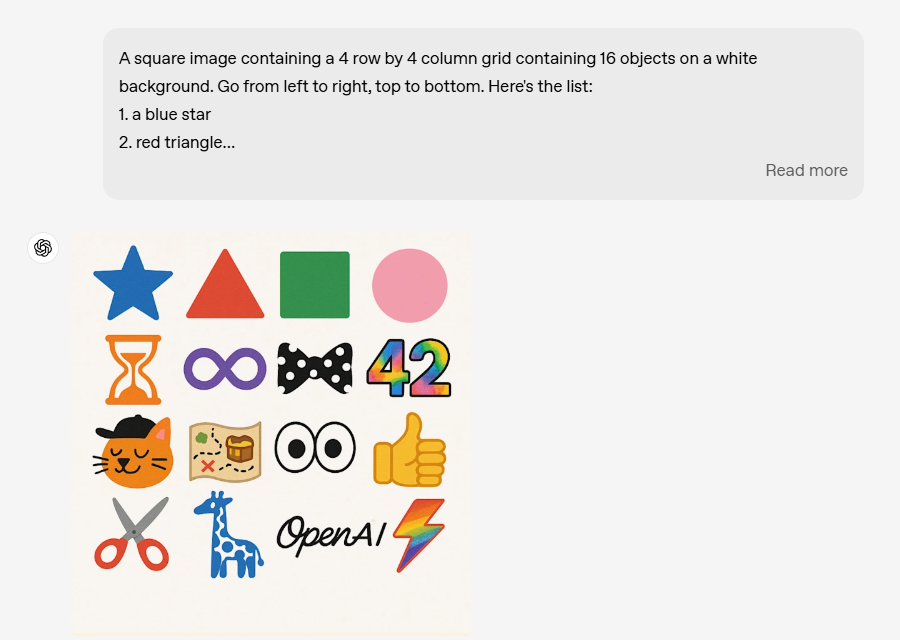

<左右滑动查看更多>
多轮对话生成
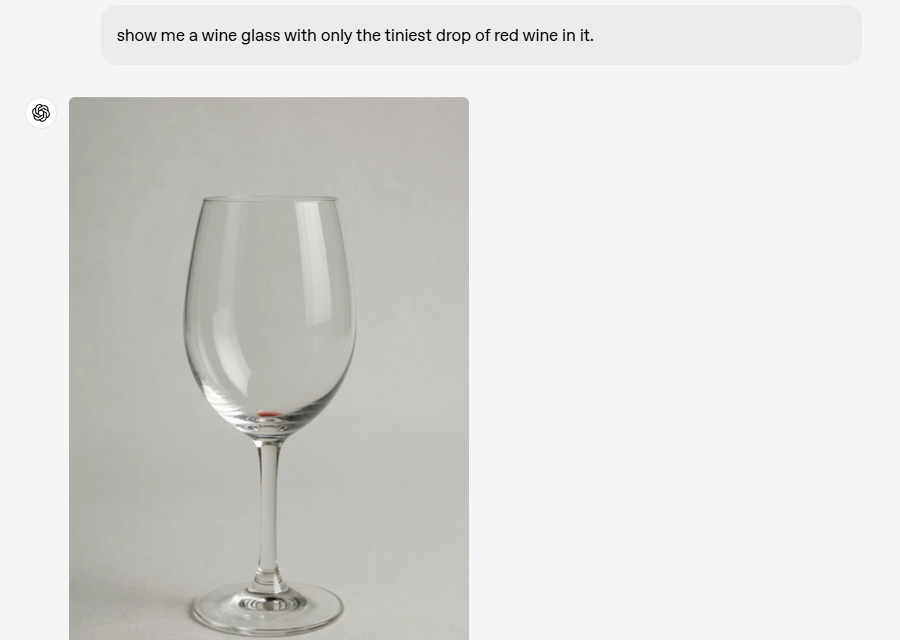
用户可以通过自然对话来优化图像,GPT-4o能够在聊天上下文中同时生成图像和文本,确保整个创作过程的一致性。例如,如果您正在设计一个视频游戏角色,在优化和调整过程中,该角色的外观将在多个迭代中始终保持连贯性。
情境学习
GPT-4o可以对用户上传的图像进行分析和学习,将其详细信息无缝整合到其上下文中,为图像生成提供信息。
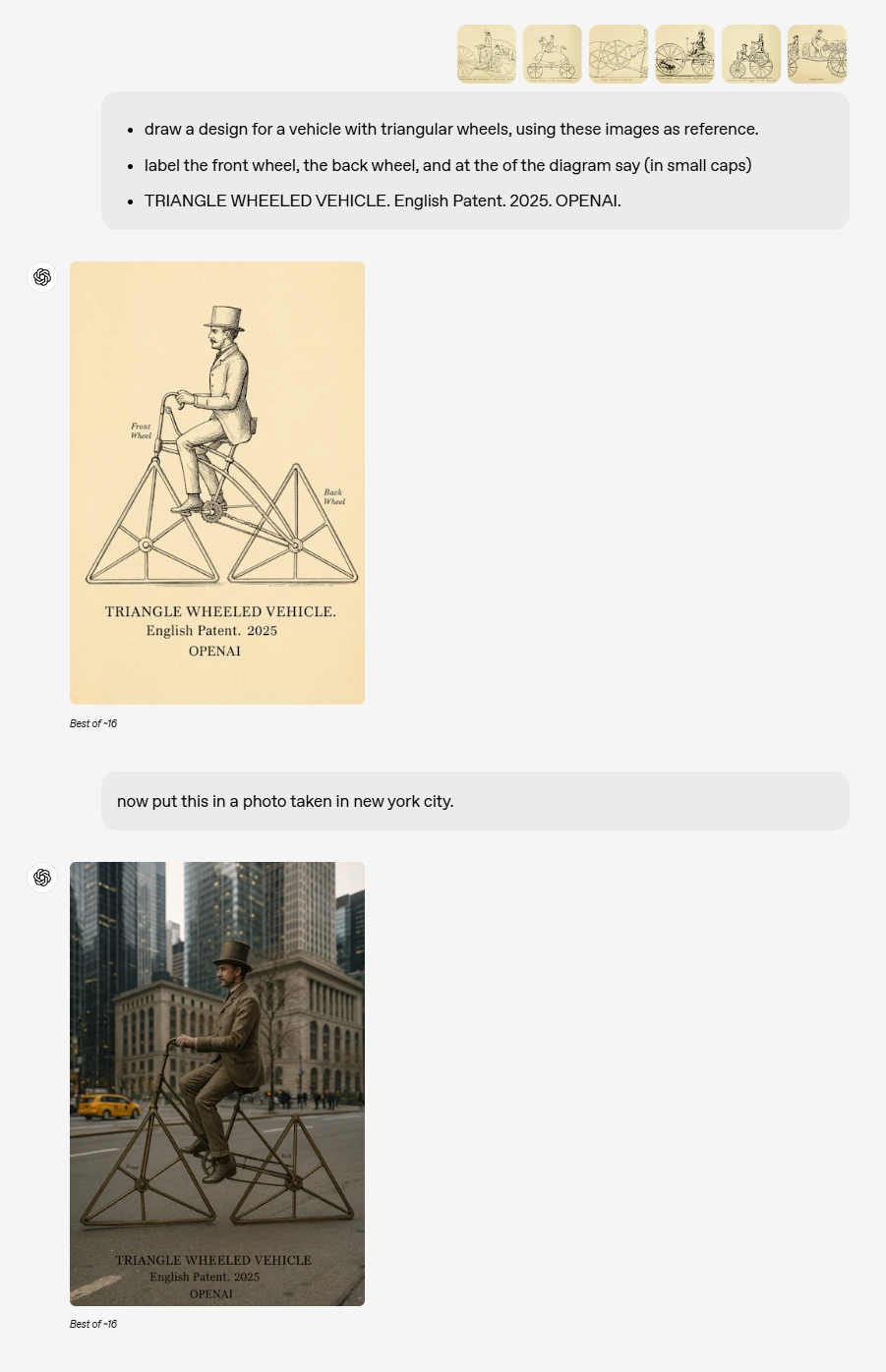
世界知识
原生图像生成技术的引入,使4o模型能够深度融合文本知识与图像,从而构建出更智能、更高效的模型,生成更贴近现实世界知识的图像。

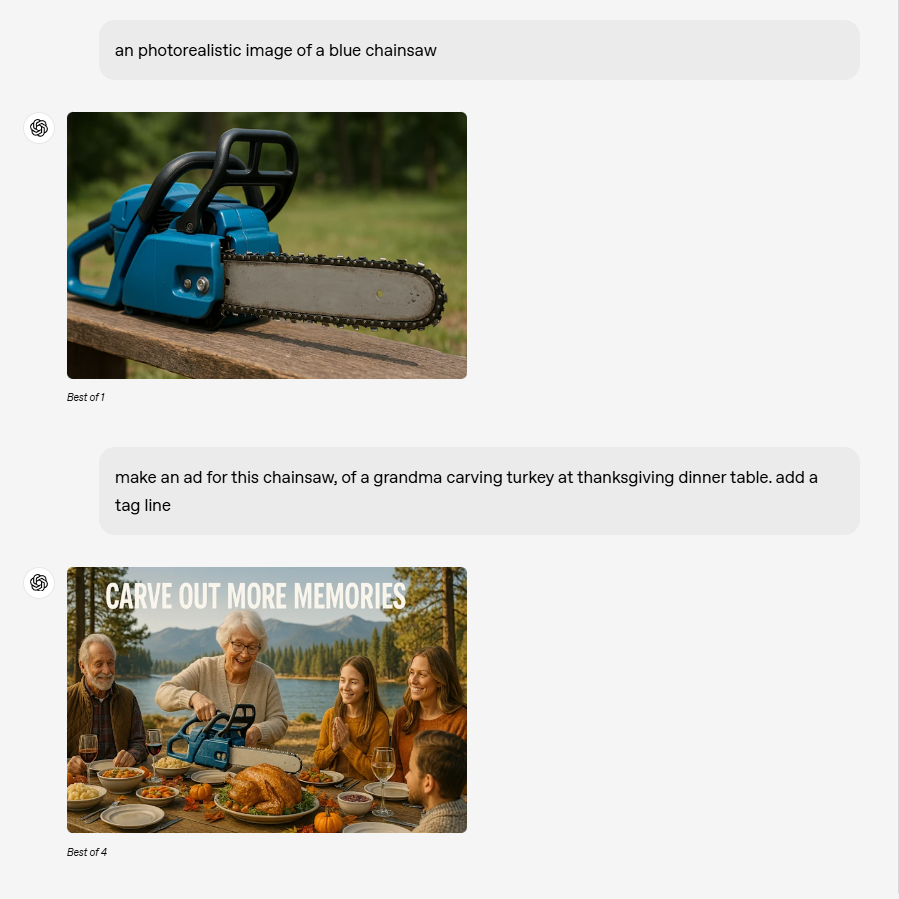
<左右滑动查看更多>
真实图像生成
通过对多种图像风格的深度训练,GPT-4o 能够生成高度逼真的图像。
马克思购物被偷拍
一张狗仔队风格的坦率照片,卡尔·马克思匆匆忙忙地穿过美国购物中心的停车场,在试图避免被拍照时,他带着惊讶的表情回头瞥了一眼。他手里拿着多个装满奢侈品的光鲜亮丽的购物袋。他的外套在风中飘扬,其中一个袋子正摆动着,仿佛他正在大步前进。汽车和发光的商场入口的模糊背景,以强调运动。相机的闪光眩光部分过度曝光了图像,给人一种混乱的小报感觉。

喝冰沙的小女孩
生成 2006 年夏季一个星期六多伦多农贸市场的逼真图像,这是一个美丽的六月下旬,人们正在购物和吃三明治。焦点应该是一个穿着牛仔工作服,啜饮草莓香蕉冰沙的年轻亚洲女孩——其余部分可能会变得模糊。这张照片应该让人想起 2006 年的数码相机拍摄的照片,并带有像打印照片一样的时间戳。

街边的猫
一只猫看着街道上的水坑,但它的倒影是老虎的倒影,而且这两个倒影都被水中的涟漪逼真地扭曲了。

小编实测
用嘴生图
Prompt:一位年轻的女生坐在地铁座位上,她的背影优雅且富有故事感。她穿着一件浅色风衣,长发随意地披散在肩膀上,手中拿着一本书或手机,沉浸在自己的世界里。地铁车厢内有温暖的灯光,窗外微微映出城市的光影,周围的乘客有的低头玩手机,有的闭目养神。

Prompt:制作一个视觉信息图表,描述地球上的碳循环是如何进行的

Prompt: 一只阿拉斯加嘴里咬着球在草地上奔跑的图片

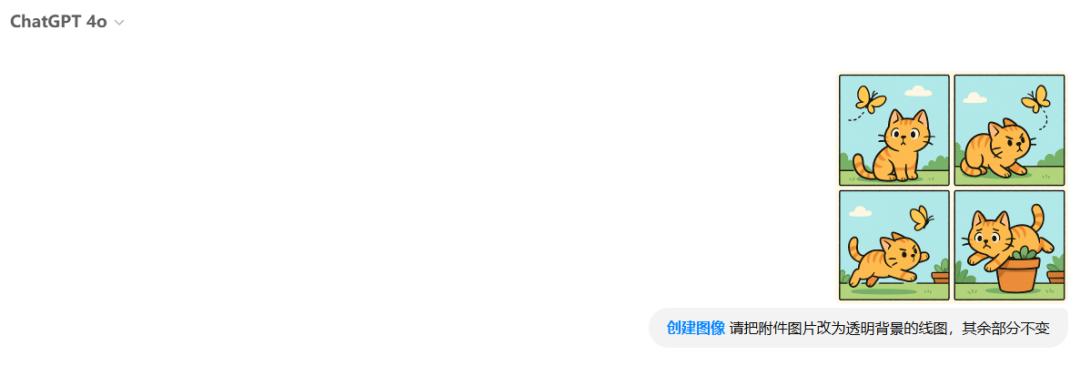
Prompt:绘制一个四格喜剧漫画:一只猫试图捉住一只飞来飞去的蝴蝶。第一格猫发现蝴蝶,第二格猫做准备起跳,第三格猫跳起来却扑空,第四格猫摔倒在花盆里满脸尴尬。使用简洁的线条、可爱的卡通风格和明亮的色彩。

用嘴改图
Prompt:请将第二张UI图片嵌入到第一张图片的手机中

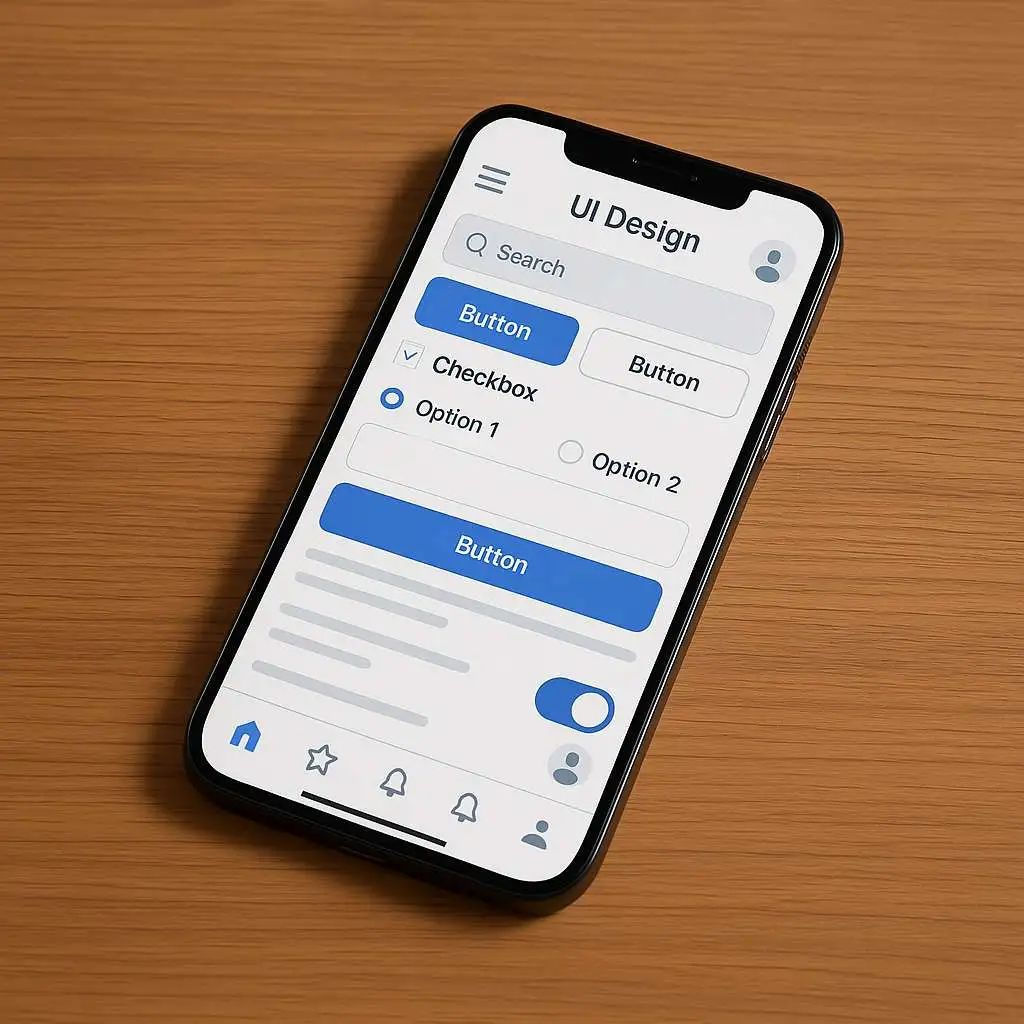
Prompt:请把附件图片改为透明背景的线图,其余部分不变

Prompt:请将附件图片转化为吉卜力风格,尺寸不变


不得不承认,GPT-4o此次推出的原生图像生成功能确实惊艳!更令人意外的是,免费用户也能第一时间体验这项功能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
