Lightmatter的光互连


IEDM 2024会议上,Nvidia的关于下一代AI处理器的报告放了这么一张图,提到了3D stack DRAM,GPU tiers和硅光互连。
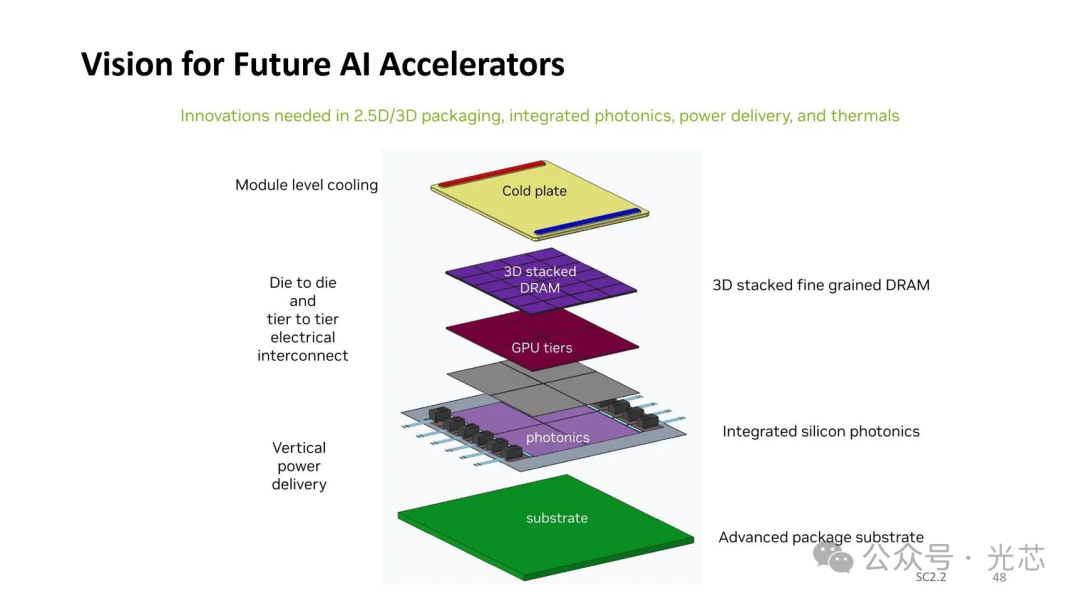
由于这个图的光互连部分长得实在跟Lightmatter的Passage很像,而且Lightmatter最新一笔融资也有Nvidia的参与,所以有外网的报道直接就把两者关联起来了。
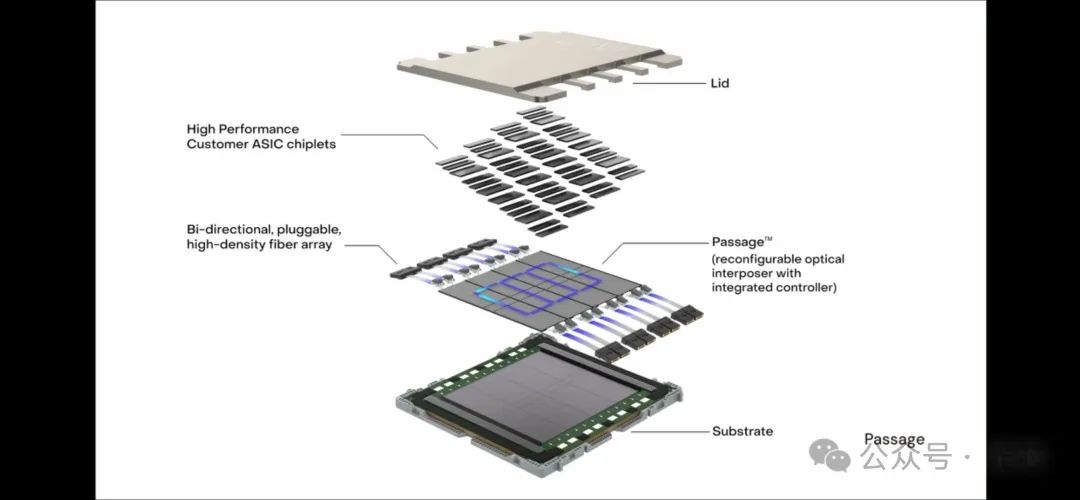

最近刚好也看到了一个Lightmatter的访谈视频(视频来源: https://www.youtube.com/watch?v=wBqfzj6CEzI),虽然还是没得到太多有用的信息,不过还是简单分享一些视频截图,看看各位列文虎克有没有新发现。
底下这个是Lightmatter讲了又讲的那个8寸48个reticle互连的大晶圆,宣称把跨reticle的光波导拼接、2.5D或3D封装、微环DWDM、片上OCS和光FPGA集了个大成。其中这里边最关键的我感觉就还是跨reticle的波导互连技术了。





从他放大的图片来看,他看起来像是4个reticle中间有一个密集图案的区域,其他部分还是做了划片槽,波导应该是不直接导通的。这个图就跟他们专利上的图片是一致的。
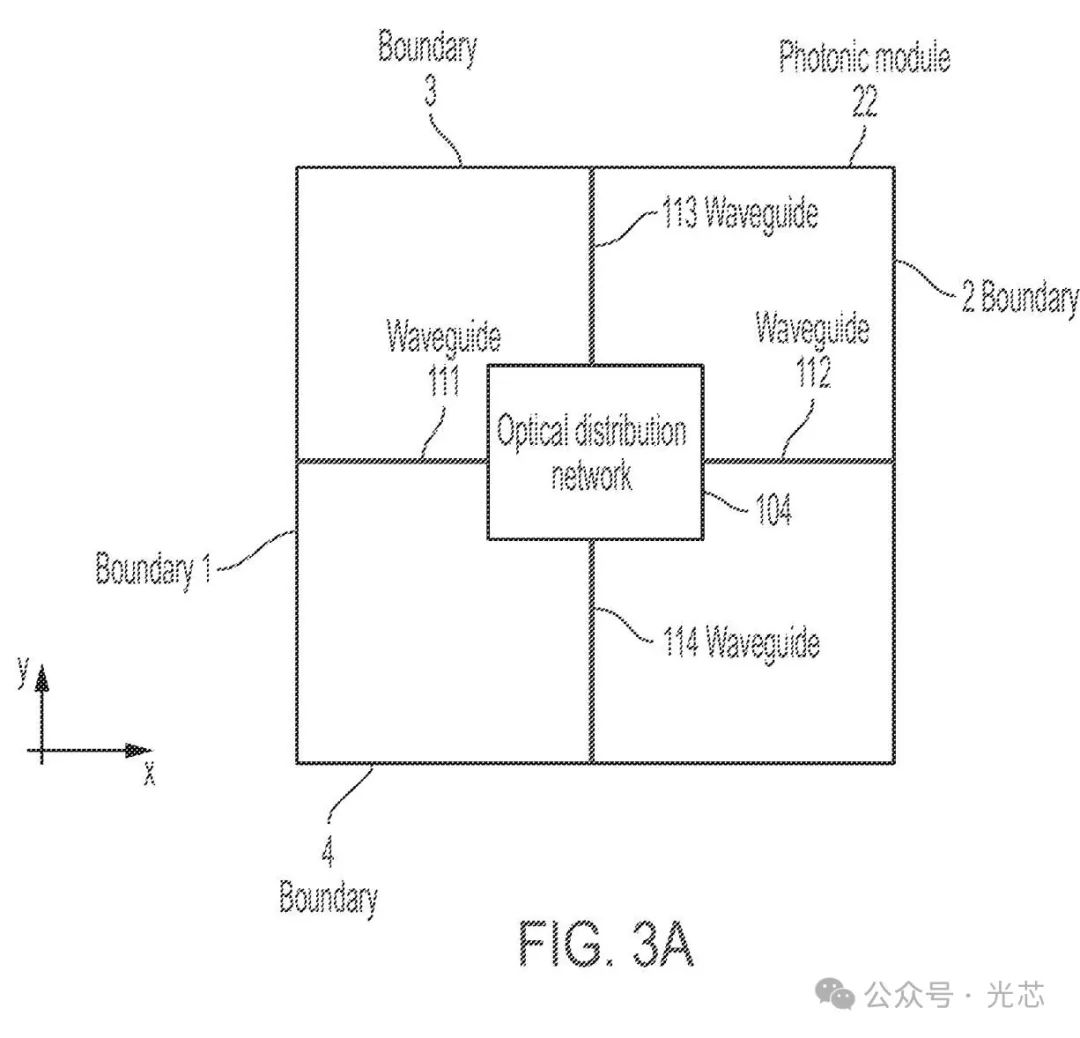
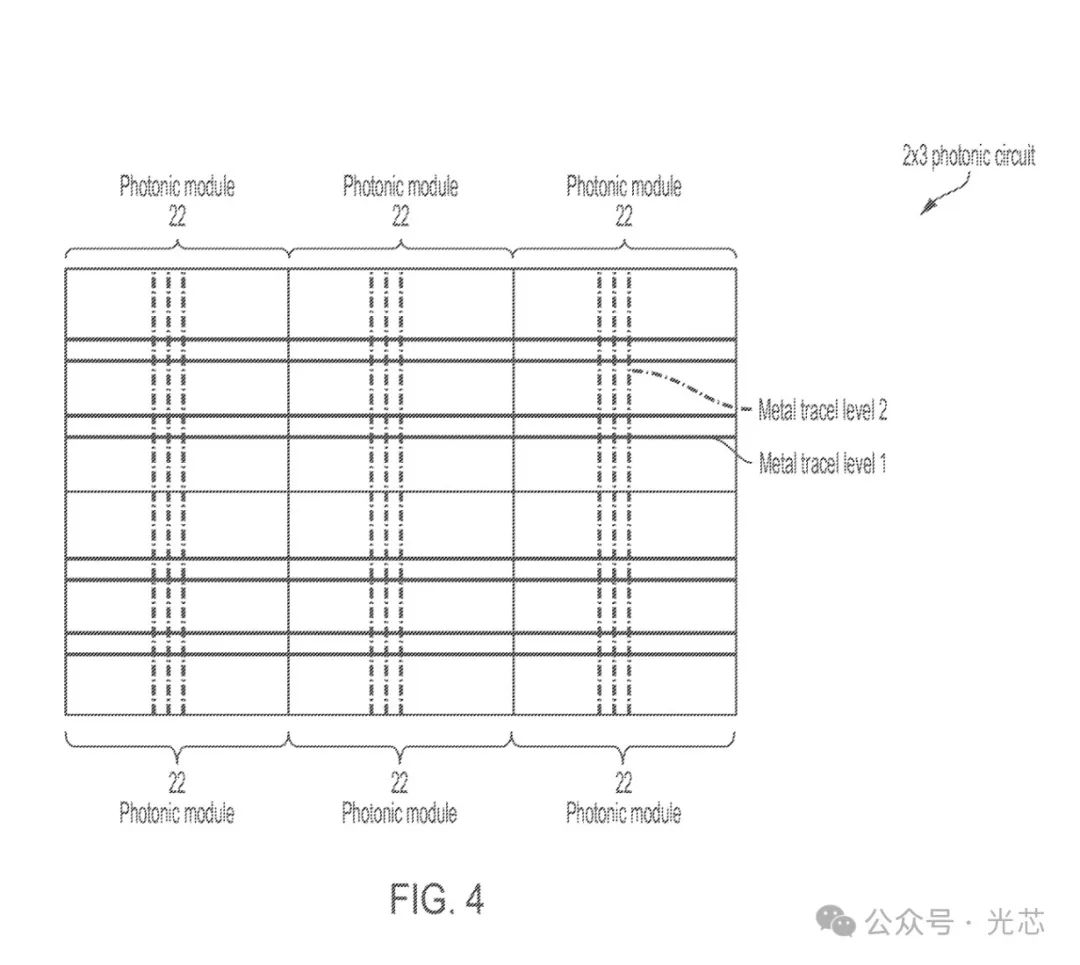
每4个reticle是一个基础单元,底下的Waveguide层和上边的Optical distribution network层用了两套mask加工。ODN层就有点像OCS,WG和ODN层的互连之间也配置了光开关。ODN的作用大概就是他底下的这张图了。

在他们的报告里边,说是可以按需划片,2×2的也可以,2×3的也可以,这我其实就不太理解了。他们的专利里边有一个实施例是说跨reticle之间还可以走电互连。那可能是用了背面TSV之类的技术实现的?如果还是走光互连的形式的话,那可能是端面做微透镜或者是用PWB等增材制造片外耦合器的方式?
下边就是他们的第二代正在开发的产品了,前段时间SC24上,他们是说25年下半年就要量产了。第二代的话就不用那么大的晶圆级互连了。这个访谈里边他们提到他们的这个Passage模块能够达到100Tbps的速率,总共是出8×32共256根光纤,每个光纤传16个波长(应该是dwdm微环调制器),算下来单通道的速率可能是25Gbps左右了。



底下是访谈中他们提到当前GPU以及存储元件的组装,都是集成在一个硅基板之上。在传统电连接设计中,这些计算单元的互连受到芯片的电学布线边界的限制,当耗尽了所有放置高速信号传输线路的空间时,电学传输速率就出现了瓶颈。所以Lightmatter做的就是用一种新的硅基板来取代原来的硅基板,让这些芯片能够利用光来传输数据。这样一来就设法找到了一种将下一代技术悄然融入现有生态系统的方法。





大概在视频里边提炼出来的信息也就这么点,Lightmatter想做的事情是清楚的,但具体实现那肯定还需要各种先进工艺来堆料了。像昨天写的台积电那个低损耗垂直耦合Coupe、EPIC工艺、高带宽/高均匀性MRM、多层波导互连等,感觉都是Lightmatter的集大成方案的可行性证明。
最后再放Nvidia在另外一个报告的两张有意思的图,NV的论文对这两张图没做解释。但是看上去满眼都是Lightmatter、Celestial AI和Ayar Labs的影子,也标出了TSMC interposer。上边很多内容都是想象能力范围内猜的,猜错了请谅解,看看有没有更专业的老师出来解读分析一下。
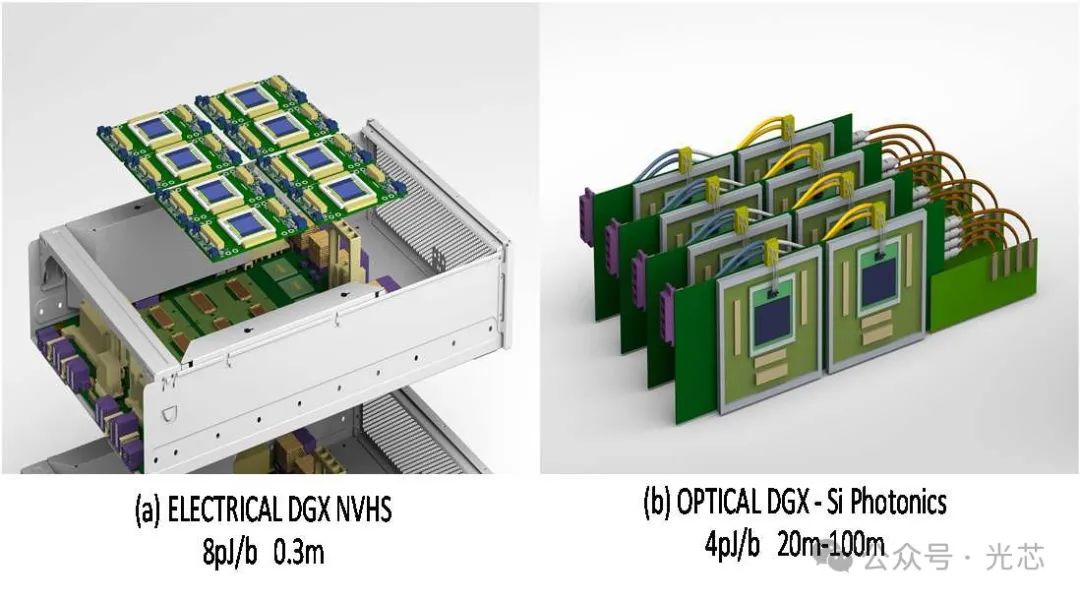
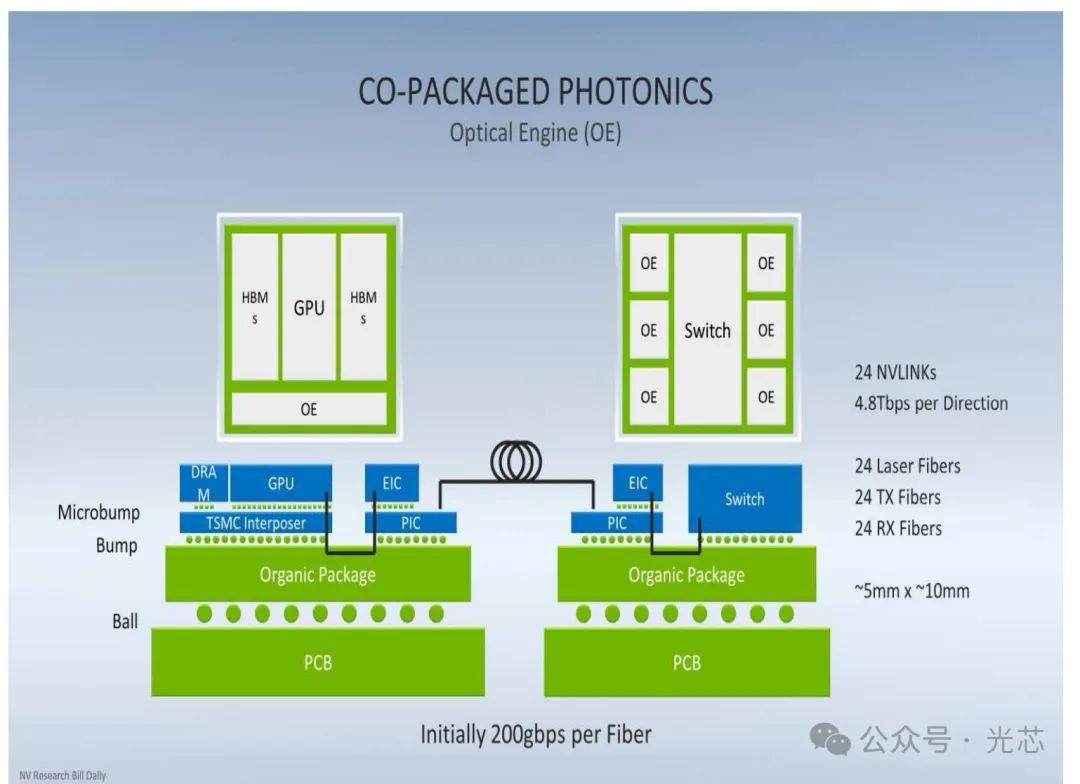
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号