Crawl4AI - 开源的LLM友好型网络爬虫和抓取工具

Crawl4AI - 开源的LLM友好型网络爬虫和抓取工具

1、前言
在人工智能领域,数据是驱动模型创新的核心燃料。而网络爬虫作为获取海量数据的关键工具,正成为连接互联网资源与AI应用的桥梁。Crawl4AI正是一款专为AI时代设计的开源爬虫框架,它以高效、智能、灵活的特性,重新定义了数据采集的范式。
2、简介
Crawl4AI是GitHub上排名第一的热门存储库,由一个活跃的社区积极维护。它为大语言模型(LLMs)、人工智能代理和数据管道提供了专为人工智能优化的超快速网络爬虫。Crawl4AI开源、灵活,专为实现实时性能而打造,赋予开发人员无与伦比的速度、精度和部署便捷性。
功能特性:
1、Markdown生成
- 整洁Markdown:能生成格式准确、结构清晰的Markdown文档。例如,将网页内容转化为层次分明、格式规范的Markdown文本。
- 适配Markdown:基于启发式过滤,去除干扰和无关部分,使生成的Markdown更适合AI处理。比如,在处理新闻网页时,过滤掉广告、版权声明等无关内容。
- 引用和参考:把页面链接转换为带清晰引用的编号参考列表。当抓取一篇学术文章网页时,能将文中引用的参考文献链接整理成有序列表。
- 自定义策略:用户可根据特定需求创建自己的Markdown生成策略。如果用户只需要网页中特定格式的标题和段落生成Markdown,就可自定义策略实现。
- BM25算法:利用BM25算法过滤,提取核心信息,去除无关内容。在处理长篇网页时,能精准提取关键内容。
2、结构化数据提取
- LLM驱动提取:支持所有开源和专有大语言模型进行结构化数据提取。比如使用GPT系列模型或开源的LLaMA模型提取网页中的商品信息。
- 分块策略:实施基于主题、正则表达式、句子级别的分块,用于针对性内容处理。处理一篇电商产品介绍网页,可按产品特性、用户评价等主题分块。
- 余弦相似度:依据用户查询找到相关内容块,进行语义提取。当用户想从网页提取特定主题内容时,通过余弦相似度算法匹配相关内容。
- 基于CSS提取:运用XPath和CSS选择器,快速基于模式提取数据。比如从电商网页中通过CSS选择器提取商品价格、名称等信息。
- 模式定义:可定义自定义模式,从重复模式中提取结构化JSON数据。在处理表格数据时,定义模式提取每行数据为JSON格式。
3、浏览器集成
- 托管浏览器:可使用用户自己的浏览器,完全掌控,避免被识别为机器人。比如使用本地安装的Chrome浏览器进行网页抓取。
- 远程浏览器控制:连接Chrome开发者工具协议,进行远程大规模数据提取。在服务器端通过该协议控制远程浏览器抓取数据。
- 浏览器配置文件:创建和管理持久化配置文件,保存认证状态、Cookie和设置。方便下次抓取同一网站时,无需重新登录。
- 会话管理:保留浏览器状态,用于多步骤抓取。比如在登录网页后,保持登录状态进行后续页面操作。
- 代理支持:无缝连接带认证的代理,实现安全访问。在需要突破网络限制或隐藏IP时,使用代理服务器。
- 完全浏览器控制:可修改头部、Cookie、用户代理等,定制抓取设置。模拟不同浏览器类型和版本进行抓取。
- 多浏览器支持:与Chromium、Firefox和WebKit兼容。根据需求选择不同内核浏览器进行抓取。
- 动态视口调整:自动调整浏览器视口以匹配页面内容,确保完整渲染和捕捉所有元素。在抓取移动端适配网页时,自动调整视口。
4、抓取与爬取
- 媒体支持:能提取图像、音频、视频以及响应式图像格式如srcset和picture。抓取网页时,获取网页中的图片、视频等媒体资源。
- 动态抓取:执行JavaScript,等待异步或同步操作,提取动态内容。抓取单页应用(SPA)时,确保页面内容加载完成后再提取。
- 截图:在抓取过程中捕获页面截图,用于调试或分析。检查抓取的页面是否正确,分析页面布局。
- 原始数据抓取:可直接处理原始HTML(raw:)或本地文件(file://)。处理本地保存的网页文件或直接输入原始HTML代码进行抓取。
- 全面链接提取:提取内部、外部链接以及嵌入的iframe内容。抓取网页时,获取网页中所有链接和iframe中的内容。
- 可定制钩子:在每个步骤定义钩子,定制抓取行为。在抓取前修改请求头,或在抓取后处理数据。
- 缓存:缓存数据,提高速度并避免重复获取。多次抓取同一网页时,直接从缓存读取数据。元数据提取:从网页检索结构化元数据。获取网页的标题、描述、关键词等元数据。
- IFrame内容提取:无缝提取嵌入的iframe内容。在抓取包含iframe的网页时,获取iframe内的信息。
- 懒加载处理:等待图像完全加载,确保不因懒加载错过内容。抓取包含大量图片的网页时,保证图片都被加载和提取。
- 全页扫描:模拟滚动,加载并捕捉所有动态内容,适用于无限滚动页面。抓取社交媒体页面时,确保加载所有动态内容。
5、部署
- Docker化设置:带有FastAPI服务器的优化Docker镜像,便于部署。通过Docker快速搭建运行环境。
- 安全认证:内置JWT令牌认证,保障API安全。在调用API时,通过JWT令牌验证身份。
- API网关:一键部署,通过安全令牌认证实现基于API的工作流程。快速部署API,并保障安全访问。
- 可扩展架构:专为大规模生产设计,优化服务器性能。适用于处理大量数据抓取任务的场景。
- 云部署:为主要云平台提供就绪的部署配置。可在AWS、阿里云等云平台快速部署。
6、其他特性
- 隐身模式:模仿真实用户,避免被机器人检测。在抓取反爬虫机制严格的网站时,降低被封禁风险。
- 基于标签的内容提取:根据自定义标签、标题或元数据优化抓取。比如只抓取特定标签内的内容。
- 链接分析:提取并分析所有链接,进行详细数据探索。分析网页链接结构,了解网站内容关联。
- 错误处理:强大的错误管理,确保无缝执行。在网络中断、页面结构变化等情况下,能妥善处理错误。
- CORS与静态服务:支持基于文件系统的缓存和跨源请求。处理跨域请求问题,提高数据访问效率。
- 清晰文档:简化和更新的指南,帮助用户入门和掌握高级用法。为新手和有经验的用户提供详细指导。
- 社区认可:认可贡献者和拉取请求,保持透明度。鼓励社区成员参与项目开发。
官方网址:
https://crawl4ai.com/
3、快速上手
1、安装Crawl4AI
pip install -U crawl4ai如果遇到任何与浏览器相关的问题,你可以手动安装它们:
python -m playwright install --with-deps chromium2、使用Python运行简单的Web爬虫
import asyncio
from crawl4ai import *
async def main():
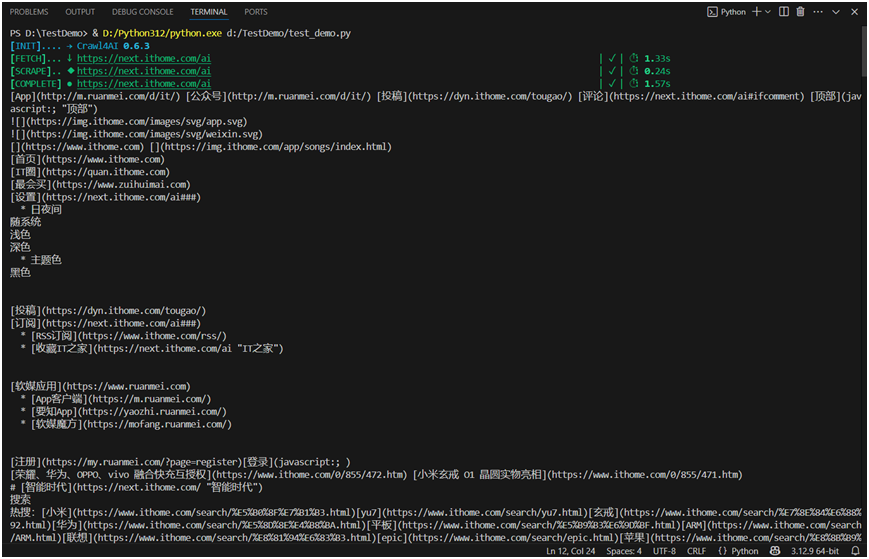
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://next.xxx.com/xxx",
)
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())运行结果
3、使用BFSDeepCrawlStrategy实现基本深度爬取
Crawl4AI最强大的功能之一是它能够执行可配置的深度抓取,可以探索单个页面以外的网站。通过对爬取深度、域边界和内容过滤的微调控制,Crawl4AI为你提供了精确提取所需的内容。
BFSDeepCrawlStrategy(max_depth=2, include_external=False)指示Crawl4AI:- 抓取起始页面(深度 0)加上2个级别 - 保持在同一域内(不要点击外部链接)- 每个结果都包含元数据,如抓取深度 - 所有抓取完成后,结果以列表形式返回。
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig
from crawl4ai.deep_crawling import BFSDeepCrawlStrategy
from crawl4ai.content_scraping_strategy import LXMLWebScrapingStrategy
asyncdef main():
# Configure a 2-level deep crawl
config = CrawlerRunConfig(
deep_crawl_strategy=BFSDeepCrawlStrategy(
max_depth=2,
include_external=False
),
scraping_strategy=LXMLWebScrapingStrategy(),
verbose=True
)
asyncwith AsyncWebCrawler() as crawler:
results = await crawler.arun("https://docs.crawl4ai.com/", config=config)
print(f"Crawled {len(results)} pages in total")
# Access individual results
for result in results[:3]: # Show first 3 results
print(f"URL: {result.url}")
print(f"Depth: {result.metadata.get('depth', 0)}")
if __name__ == "__main__":
asyncio.run(main())运行结果

4、使用命令行运行
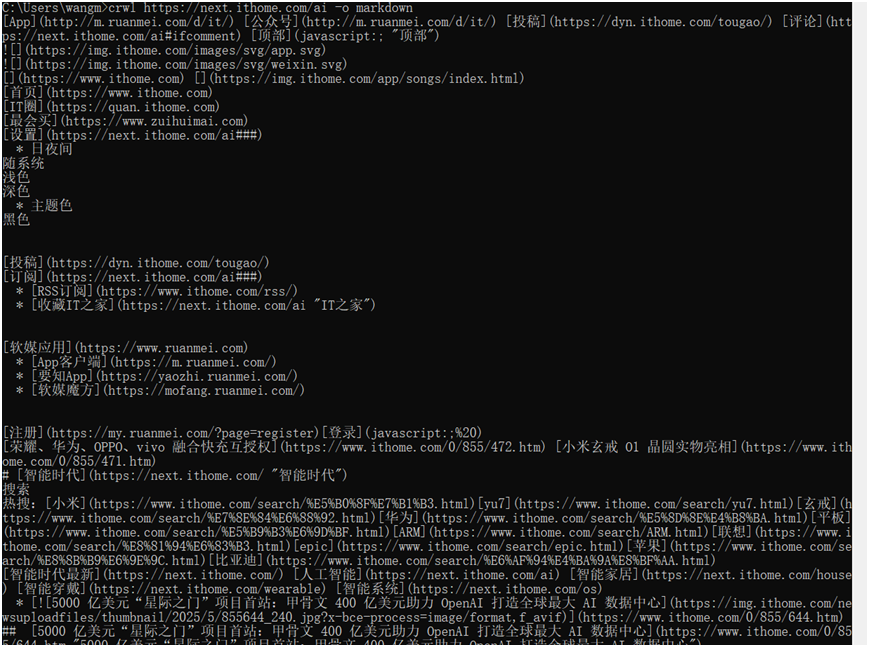
# 以Markdown格式输出的基础爬取
crwl https://next.xxx.com/xxx -o markdown运行结果
本文分享自 AllTests软件测试 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
腾讯云开发者
