一文讲清楚DPU和SmartNIC(智能网卡)

一文讲清楚DPU和SmartNIC(智能网卡)

现在市场端,关于DPU和DPU卡、智能网卡的描述时常有些混乱,霞姐摘录了比较权威的四家观点,和大家分享一下它们关于DPU、智能网卡是怎么看的。相信大家看完后,就知道怎么分辨了。
1.行业龙头Nvidia的观点—凯文·迪尔林 2021年
(凯文·迪尔林是 NVIDIA 的网络高级副总裁)
从DPU的角度来看
https://blogs.nvidia.com/blog/whats-a-dpu-data-processing-unit/
DPU是一种新型可编程处理器(SOC),是结合了三种关键元件的SoC:
(1)行业标准、高性能、软件可编程的多核CPU,通常基于广泛使用的 Arm 架构,与其他 SoC 组件紧密耦合。
(2)一种高性能网络接口,能够以线速或网络其余部分的速度解析、处理数据并高效传输到GPU 和 CPU
(3)一组丰富的灵活且可编程的加速引擎,可卸载和提高AI 和机器学习、零信任安全、电信和存储等应用程序的性能

DPU 可用作独立的嵌入式处理器。但它更经常集成到SmartNIC(智能网卡)中。

有些厂家声称它们的设备是DPU设备,但凯文认为不算,理由是:
(1)有些设备使用专有处理器,这些处理器无法从广泛的 Arm CPU 生态系统丰富的开发和应用程序基础设施中受益。
(2)有些设备即只关注嵌入式 CPU 来执行数据路径处理。这种方案和使用X86的CPU进行数据包处理来比,没有竞争力,扩展性也不好。
并且凯文认为DPU的网络路径的加速引擎至少要提供下面10项功能,而市面上有些设备的功能太单薄了,只包含其中的一小部分。
(1)Data packet parsing, matching and manipulation to implement an open virtual switch (OVS)
数据包解析、匹配和操纵,以实现开放式虚拟交换机(OVS)
(2)RDMA data transport acceleration for Zero Touch RoCE
零接触 RoCE 的 RDMA 数据传输加速
(3)GPUDirect accelerators to bypass the CPU and feed networked data directly to GPUs (both from storage and from other GPUs)
GPUDirect 加速器绕过 CPU 并将网络数据直接提供给 GPU(从存储和其他 GPU )
(4)TCP acceleration including RSS, LRO, checksum, etc.
TCP 加速包括 RSS、LRO、校验和等。
(5)Network virtualization for VXLAN and Geneve overlays and VTEP offload
用于VXLAN 和 Geneve 叠加以及 VTEP 卸载的网络虚拟化
(6)Traffic shaping “packet pacing” accelerator to enable multimedia streaming, content distribution networks and the new 4K/8K Video over IP (RiverMax for ST 2110)
流量整形“数据包步调”加速器,支持多媒体流、内容分发网络和新的 4K/8K IP 视频(适用于 ST 2110 的 RiverMax)
(7)Precision timing accelerators for telco cloud RAN such as 5T for 5G capabilities
用于电信云 RAN 的精密定时加速器,例如用于 5G 功能的 5T
(8)Crypto acceleration for IPSEC and TLS performed inline, so all other accelerations are still operational
IPSEC 和 TLS 的加密加速以内联方式执行,因此所有其他加速仍可运行
(9)Virtualization support for SR-IOV, VirtIO and para-virtualization
对 SR-IOV、VirtIO 和半虚拟化的虚拟化支持
(10)Secure Isolation: root of trust, secure boot, secure firmware upgrades, and authenticated containers and application lifecycle management
安全隔离:信任根、安全启动、安全固件升级以及经过身份验证的容器和应用程序生命周期管理。
从智能网卡的角度来看:https://blogs.nvidia.com/blog/what-is-a-smartnic/
SmartNIC 或智能网络接口卡是一种可编程加速器,从服务器CPU 中卸载了管理现代分布式应用程序所需的不断扩大的工作。
在网卡之上集成了各种互联的、通常可配置的硅块单元,这些单元将智能置于SmartNIC 中。这些硅块就像一个专家委员会,在数据流经数据中心时决定如何处理和路由数据包。
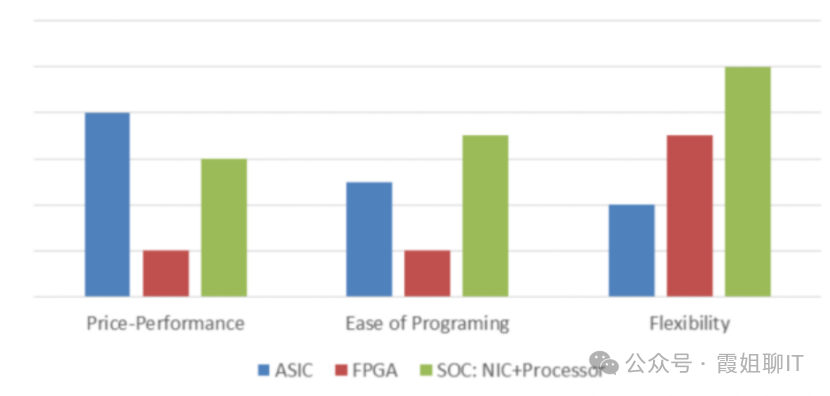
这些硅块有些是硬件加速器,而有些则可由用户编程,因此SmartNIC兼具性价比、性能、灵活性。
SmartNIC有三种派别:
1.FPGA派别。但FPGA 难以编程、价格昂贵,并且无法提供与集成加速器相同的性能
2.专用ASIC派别。这类方案通常提供最佳性价比和一定的灵活性。代表产品:NVIDIA ConnectX。
3.SoC派别:将专用硬件加速器与可编程处理器混合在一起。这些SmartNIC 往往具有最高的性能和最大的灵活性,因此它们的成本更高。比如BlueField DPU可编程智能网卡。

2.servethehome的观点—Patrick Kennedy 2021年
(servethehome是一个在服务器、存储和网络领域具有一定影响力的行业资源平台)
https://www.servethehome.com/dpu-vs-smartnic-sth-nic-continuum-framework-for-discussing-nic-types/
DPU有一些关键特征:
(1)高速网络连接(这一代通常有多个 100Gbps-200Gbps 接口)
(2)具有特定加速器和可编程逻辑的高速数据包处理(P4/P4-like)
(3)CPU core complex(通常基于这一代的 Arm 或 MIPS)
(4)内存控制器(通常是 DDR4,但我们也看到 HBM 和 DDR5 支持)
(5)加速器(通常用于加密或存储卸载)
(6)PCIe Gen4 通道(作为root或endpoint运行)
(7)安全和管理功能(比如有一个硬件信任根)
(8)运行自己的、独立于主机系统的、操作系统(通常是 Linux,但也有可能是VMware Project Monterey ESXi on Arm等)

DPU vs SmartNIC
这篇文章将NIC分成下面几类

(1)Foundational NIC 基础NIC
基础NIC 旨在实现低成本网络端口,因此它放弃了许多会增加成本和复杂性的高端卸载功能,但有一些非常基本的卸载功能,例如 IPv4/IPv6 和 TCP/UDP 校验和卸载。

(2)Offload NIC 卸载NIC
在100Gbps 甚至更快的数据速率下,让网卡在硬件中独立于CPU 处理网络功能变得至关重要。
Offload NIC的目标是尽可能地将 CPU 从网络处理中解放出来,以便有更多的 CPU 资源可用于运行应用程序。
Offload NIC有一些有限的可编程性,但程度不如SmartNIC。

(3)SmartNIC 智能网卡
SmartNIC 的关键创新是增加了一个更灵活的可编程管道,这也是 DPU 所采用的。
鉴于市场上的混淆,以及“SmartNIC”术语在行业采用“DPU”术语之前就已经使用的事实,存在很多混淆。但DPU 和传统的 SmartNIC的概念模型不一样。
因此,这篇文章将 SmartNIC 定义为具有可编程管道的 NIC,以进一步增强主机 CPU 的卸载能力。
换句话说,尽管许多SmartNIC 可能运行 Linux 并拥有自己的 CPU 内核,但 SmartNIC 的功能是减轻主机 CPU 作为整个服务器一部分的负担。
在该角色中,SmartNIC 与 DPU 不同,因为 DPU 似乎更专注于成为独立的基础设施终端节点。

(4)DPU卡
对DPU来说,卸载和可编程性无疑是关键功能。
和智能网卡的最大的区别在于,供应商本着 AWS Nitro 平台的精神设计 DPU,使其成为基础设施终端节点。
这些基础设施端点可以直接将存储连接到网络(例如,使用Fungible 产品),
这些端点可能是网络的安全入口(例如,使用Pensando DSC 产品/Marvell Octeon 产品),
或者它们可能更像是通用端点,用于安全地向整个基础设施提供计算、网络和存储。

(5)Exotic 奇异网卡
Exotic NIC 是具有巨大灵活性的解决方案。
这种灵活性是通过使用大型 FPGA 来实现的。借助 FPGA,组织可以创建自己的自定义管道,以实现低延迟网络,甚至将 AI 推理等应用程序作为解决方案的一部分,而无需使用主机 CPU。
不过,一般来说,SmartNIC/DPU 和 Exotic NIC 之间存在重大差异。
这种灵活性和可编程性意味着那些部署 Exotic NIC 的组织将拥有专门通过为 FPGA 编程新逻辑从NIC 中提取价值的团队。
灵活性伴随着责任,这就是为什么需要将这些解决方案归类到传统的 SmartNIC 和 DPU 类别之外。
在许多领域,被归类为奇特的解决方案可以产生令人印象深刻的结果,但也带有额外的设计和维护考虑因素,使它们对高端应用具有吸引力。

3.《专⽤数据处理器(DPU)白皮书》的观点 2021年
编写单位:中科院计算所、中科驭数、计算机体系结构国家重点实验室、CCF集成电路设计专业组。
DPU:
DPU(Data Processing Unit)是以数据为中心构造的专用处理器,采用软件定义技术路线支撑基础设施层资源虚拟化,支持存储、安全、服务质量管理等基础设施层服务。
DPU要解决的核心问题是基础设施的“降本增效”,即将“CPU处理效率低下、GPU处理不了”的负载卸载到专用DPU,提升整个计算系统的效率、降低整体系统的总体拥有成本(TCO)。
DPU最直接的作用是作为CPU的卸载引擎,接管网络虚拟化、硬件资源池化等基础设施层服务,释放CPU的算力到上层应用。
DPU还可以成为新的数据网关,将安全隐私提升到一个新的高度。
DPU也可以成为存储的入口,将分布式的存储和远程访问本地化。
DPU将成为算法加速的沙盒,成为最灵活的加速器载体。
智能网卡:
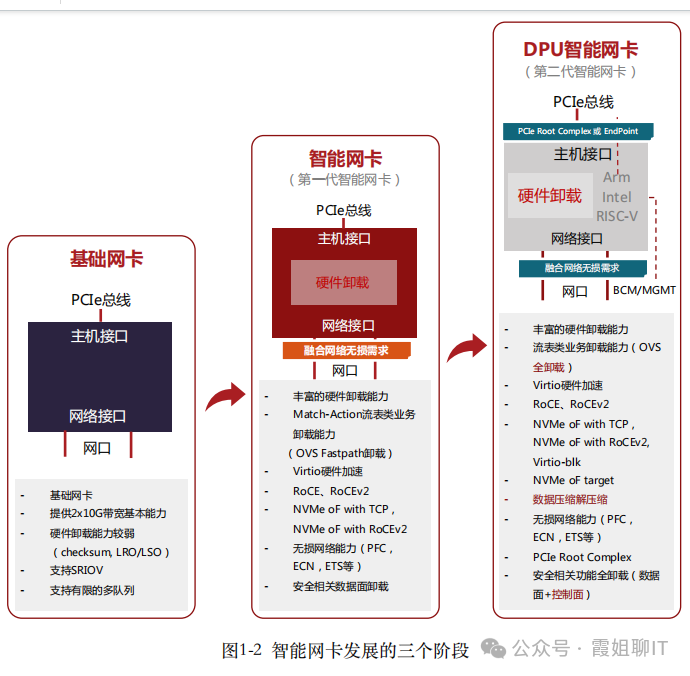
智能网卡发展经历了三个阶段:
第一阶段:基础功能网卡(即普通网卡)
提供2x10G或2x25G带宽吞吐,具有较少的硬件卸载能力,主要是Checksum,LRO/LSO等,支持SR-IOV,以及有限的多队列能力。
第二阶段:硬件卸载⽹卡
是第一代智能网卡,具有丰富的硬件卸载能力,比较典型的有OVS Fastpath硬件卸载,基于RoCEv1和RoCEv2的RDMA网络硬件卸载,融合网络中无损网络能力(PFC,ECN,ETS等)的硬件卸载,存储领域NVMe-oF的硬件卸载,以及安全传输的数据面卸载等。这个时期的智能网卡以数据平面的卸载为主。
第三阶段:DPU智能⽹卡
在第一代智能网卡基础上加入CPU,可以用来卸载控制平面的任务和一些灵活复杂的数据平面任务。
4.《云计算通用可编程DPU 发展白皮书(2023 年)》的观点
编写单位:中移(苏州)软件技术有限公司、中国信息通信研究院云计算与大数据研究所、深圳云豹智能有限公司
DPU:
DPU 作为软件定义芯片的典型代表,完美诠释了“软件定义、硬件加速”的理念,是集数
据中心基础架构于芯片的通用处理器。
DPU 通用处理单元用来处理控制平面业务,专用处理单元保证了数据平面的处理性能,从而达到了性能与通用性的平衡。
DPU 专用处理单元用来解决数据中心通用基础设施虚拟化的性能瓶颈,通用处理单元则保证 DPU 的通用性,使得 DPU 能够广泛适用于各家云厂商的基础设施,实现了数据中心虚拟化软件框架向 DPU的平滑迁移。
DPU 在新型数据中心的架构中,主要聚焦解决当前数据中心应用中消耗 CPU、GPU 算
力资源的网络、存储、安全以及和应用相关的,诸如AI、数据库等性能要求敏感的数据处理 任务。
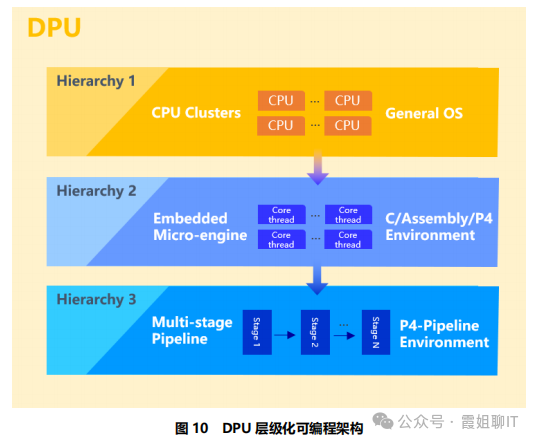
为了达到这个目标,DPU 必须具备:层级化可编程性、低延时网络、统一管控以及适应持续发展的加速卸载的关键特性。
层级化可编程性指的是:
(1)层级1 – 通用可编程:高灵活性,性能需求相对不高
主要面对通用可编程处理需求,以及数据慢速路径的处理需求,极大的灵活性,满足灵活多变的场景需求。
(2)层级2 – 嵌入引擎可编程:均衡的灵活性/性能
嵌入引擎可编程介于通用可编程和下一个层级的领域可编程之间,主要针对DPU具备的各种嵌入式微引擎(例如,RISC-V core+增强的网络处理指令集的微引擎是实现层级2可编程能力的可行方案之一)。
嵌入引擎可编程兼顾灵活性和数据处理性能,基于C、汇编、P4 或其他编程语言,针对动态的业务加速和卸载需求,达到最佳的平衡点。
(3)层级3 – 领域可编程:极致性能、低灵活性
针对特定领域的可编程性,可以获得最佳的性能。
在领域可编程中,一种可行的方案是基于可编程的Pipeline 架构,应用层采用基于 P4-Pipeline 的编程接口。例如在对快速路径中报文转发与处理的应用,领域可编程能力可以发挥巨大作用。
智能网卡:
(1)传统网卡
又称网络适配器,已经初步具备了一些简单的硬件卸载能力,如 CRC 校验、TSO/UFO、LSO/LRO、VLAN 等,支持 SR-IOV 和流量管理 QoS。
(2)SmartNIC
智能网卡 SmartNIC 除了具备传统基础网卡的网络传输功能外,还提供丰富的硬件卸载加速能力,能够提升云计算网络的转发速率,释放主机 CPU 计算资源。
智能网卡SmartNIC 上没有通用处理器 CPU,需要主机 CPU 进行控制面管理。
智能网卡 SmartNIC 主要卸载加速对象是数据平面,如虚拟交换机 OVS/vRouter 等数据面 Fastpath 卸载、RDMA 网络卸载、NVMe-oF 存储卸载以及 IPsec/TLS 数据面安全卸载等。
(3)DPU
相比智能网卡 SmartNIC,DPU 在硬件架构上增加了通用处理单元 CPU 和丰富的硬件
加速单元。从而便于实现对网络、存储、安全和管控等通用基础设施的加速和卸载。
DPU的产品形态主要有NP/MP+CPU,FPGA+CPU和ASIC+CPU。
基于NP/MP+CPU和 FPGA+CPU 硬件架构的 DPU是发展初期大部分DPU厂商的选择。但是随着网络带宽的快速增长,这两种架构的DPU 在性能上将难以满足,功耗控制方面也会存在很大的挑战。而基于 ASIC+CPU 的硬件架构结合了 ASIC 和 CPU 的优势,兼顾了专用加速器的优异性能和通用处理器的可编程灵活性,成了 DPU 产品的发展趋势。
腾讯云开发者
