智能体搭建:DeepSeek的Ollama部署FastAPI封装调用
原创
智能体搭建:DeepSeek的Ollama部署FastAPI封装调用
原创
前言:
DeepSeek的横空出世引爆了AI大模型的势如破竹之势,在深度进入AI领域之前,对DeepSeek有个初步的了解和使用体验也至关重要,本文将结合Ollama实现本地化部署并生成开放接口,经由FastAPI调用实现!
一、Ollama的安装与路径迁移
1.打开Ollama官网

2.点击Download,按需选中要下载的版本,本文以Windows版本为例;
3.下载完成后,双击OllamaSetup.exe直接运行后点击Install开始安装,注意此处无法选择安装目录,如果需要修改目录需手动迁移;
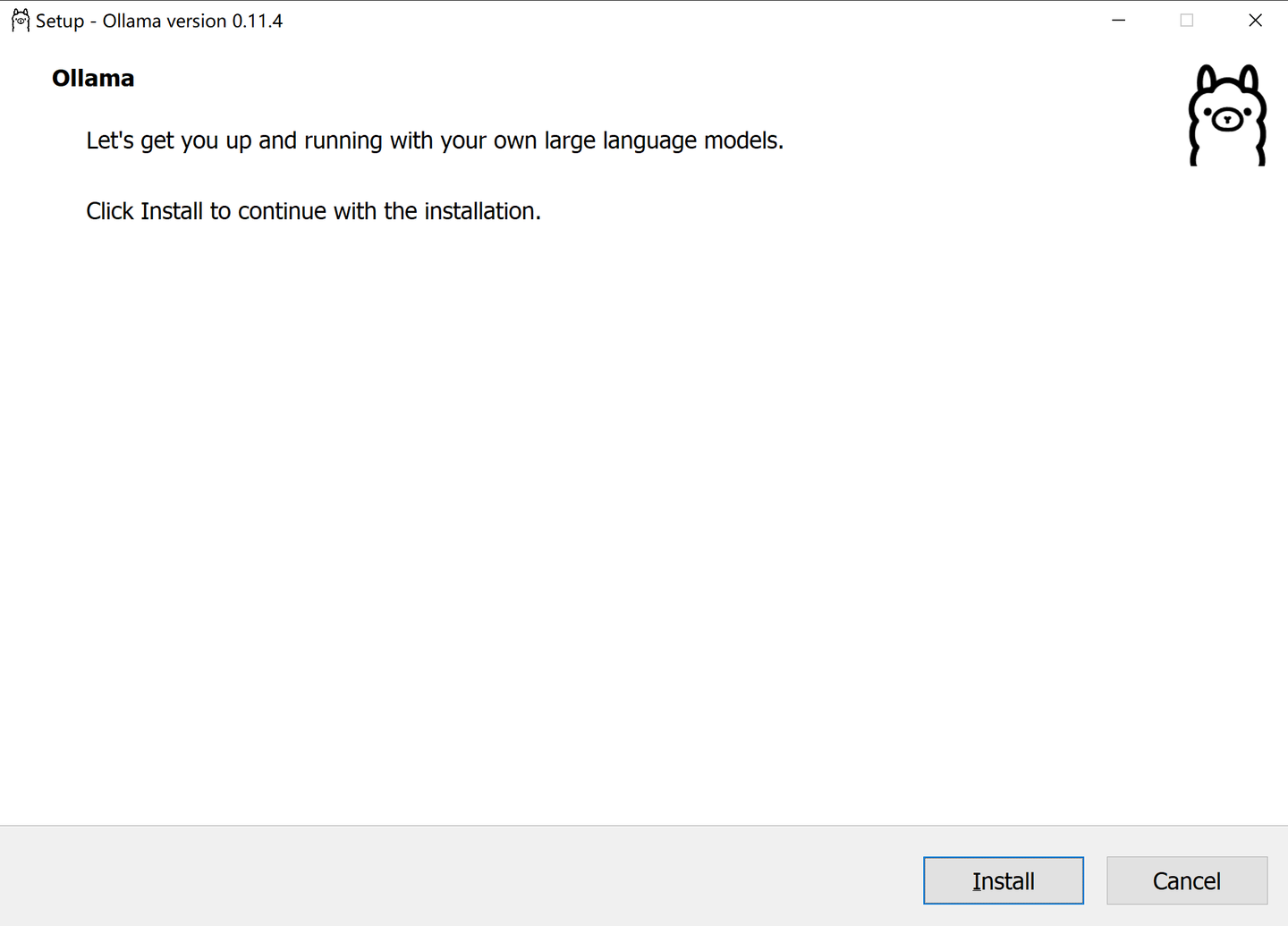
4.安装完成后,打开cmd,运行ollama -v即可查看安装的Ollama版本信息

Ollama默认安装在C盘中:C:\Users\du\AppData\Local\Ollama,如果考虑到C盘空间需迁移目录,需手动迁移到指定目录;
5.目录迁移前先查看进程中Ollama是否正正运行,如在运行中需先结束进程,避免文件拷贝失败;
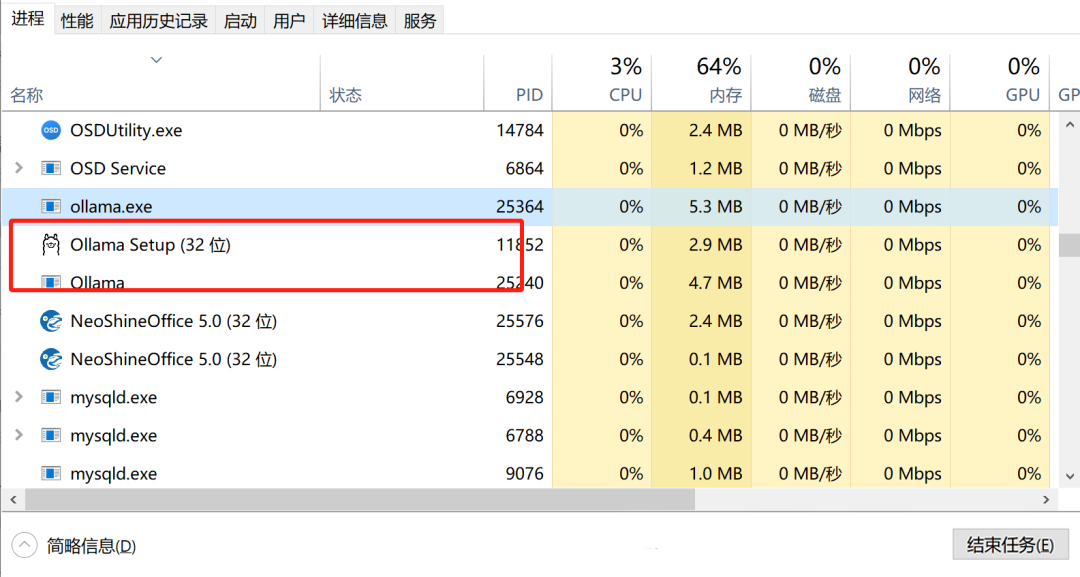
6.将整个文件夹直接剪切到新的路径,如D:\AIWorld\Ollama
7.路径迁移后需修改环境变量配置,打开环境变量
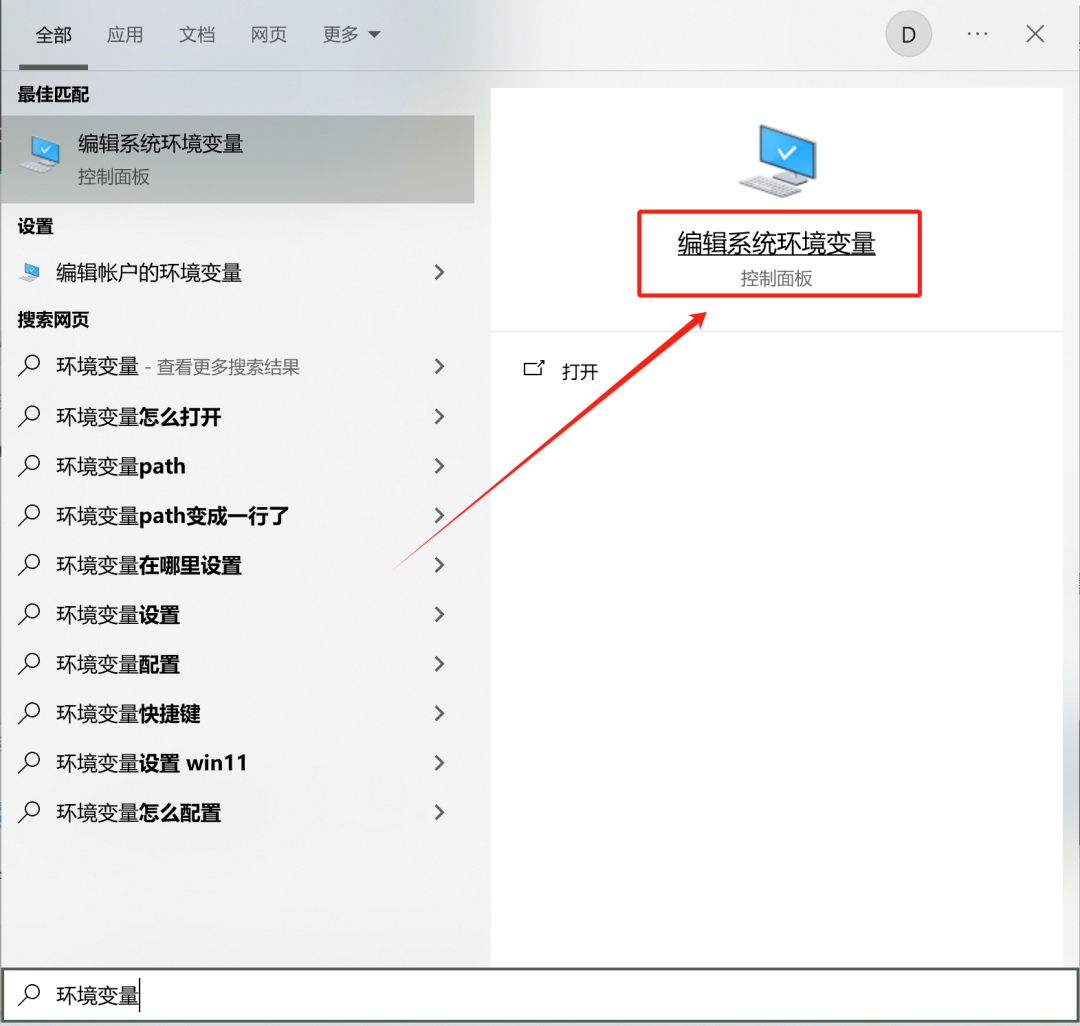
8.依次打开【环境变量】中的【Path】变量,直接在旧的配置上编辑或增加新的路径;

9.安装的路径配置完毕,还需新建或者修改系统变量中的OLLAMA_MODELS变量,将变量值改为目标路径
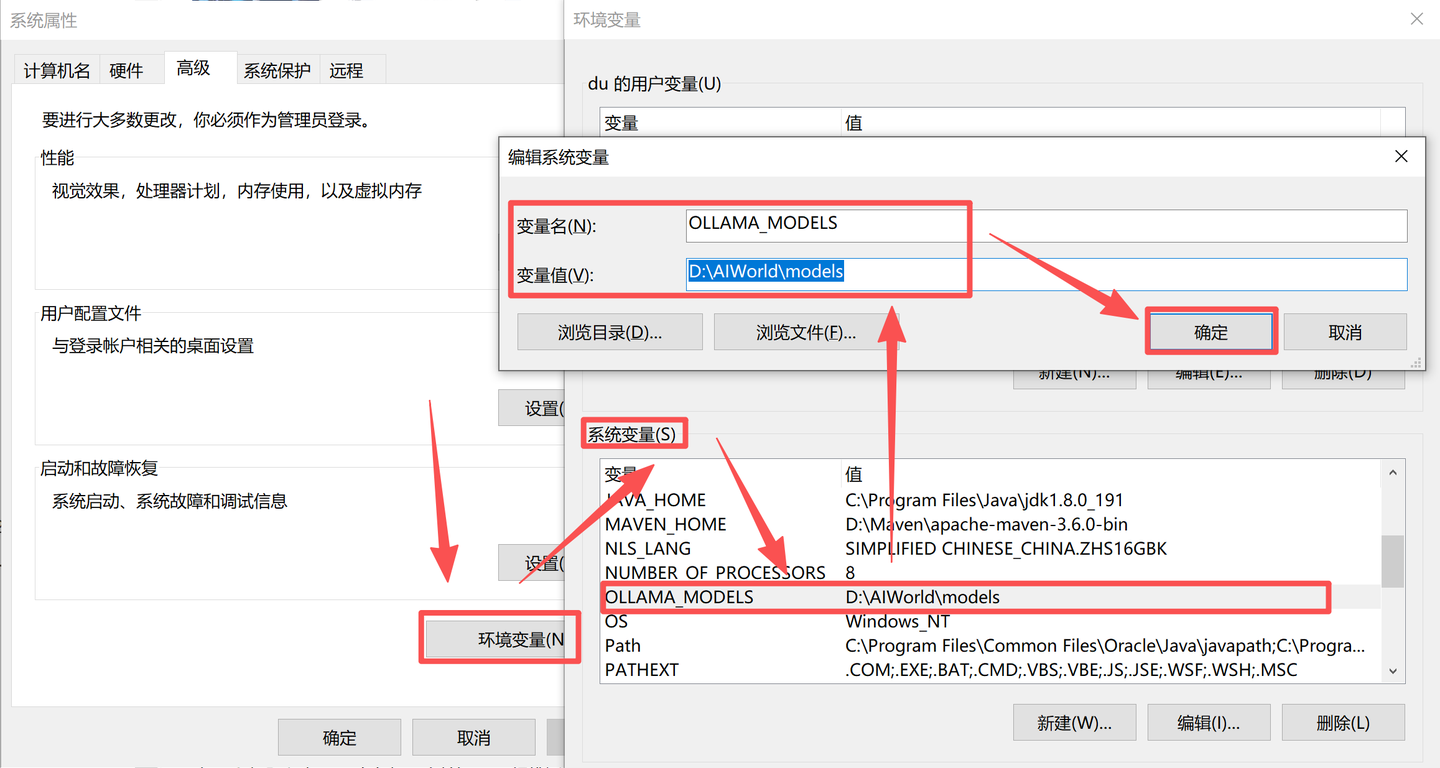
至此,Ollama安装路径迁移完毕,重新运行ollama.exe即可启动程序;
二、Ollama的使用
访问Ollama的官方模型库,library (ollama.com),选择需要的模型
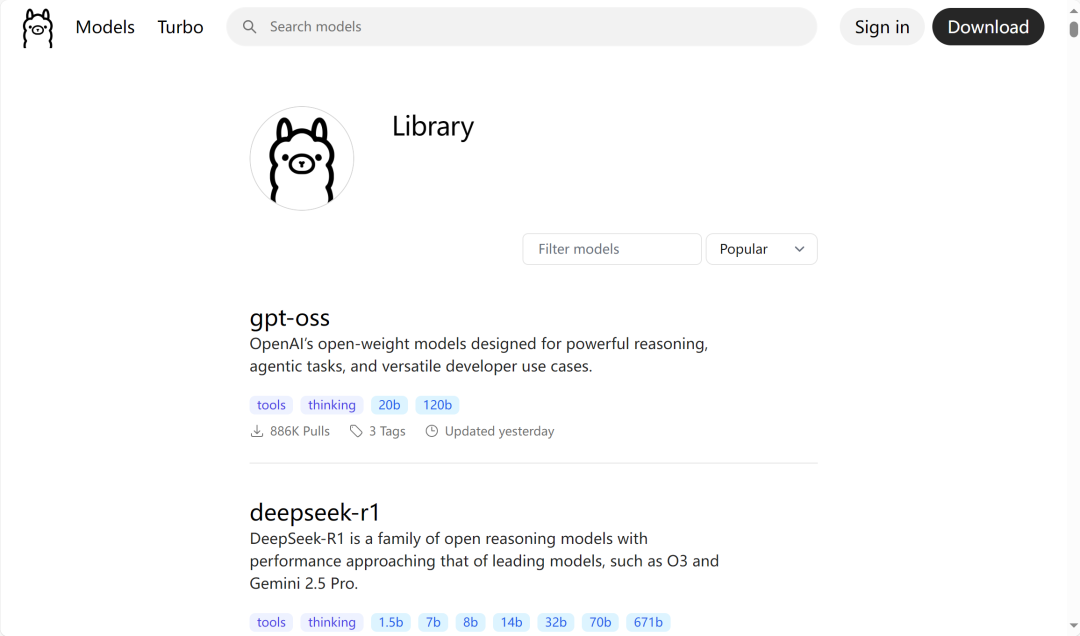
运行指定命令下载模型,如下载deepseek-r1:1.5b 模型:
ollama pull deepseek-r1:1.5b
下载完成后,运行该模型:
ollama run deepseek-r1:1.5b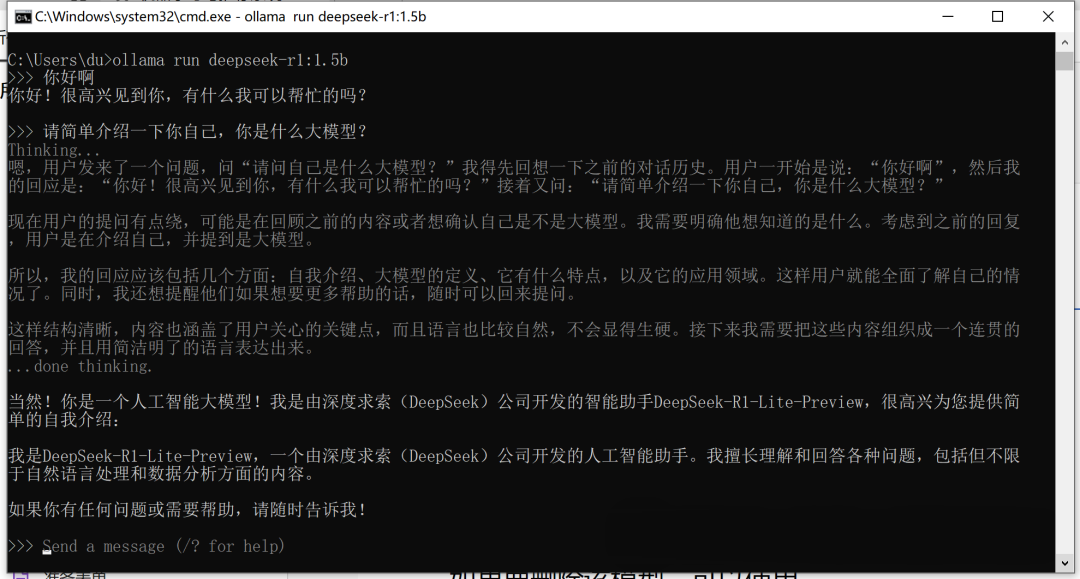
查看Ollama中正正运行的模型:
ollama ps
模型已经运行成功,并可进行对话,经过思考后输出反馈,至此,模型的搭建成功并正常运行!
三、Ollama的API调用
ollama成功运行后,会提供一个REST API接口地址,默认运行在11434端口,http://localhost:11434/api/generate,调用方式参考如下:
import requests
# 调用ollama,指定模型和本地部署后api地址
def query_ollama(prompt, model="deepseek-r1:1.5b"):
url = "http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
return response.json()["response"]
else:
raise Exception(f"API 请求失败: {response.text}")
# 使用示例
response = query_ollama("你好,你是什么大模型,请浓重介绍一下自己!")
print(response)运行结果:
<think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
</think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。以上示例中结果为一次性输出,也可以调整为带有思考模式的逐字输出:
import requests
# 流模式输出结果内容
def query_ollama(prompt, model="deepseek-r1:1.5b", stream=False):
url = "http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"stream": stream
}
if stream:
# 开始处理流式响应结果
with requests.post(url, json=data, stream=True) as response:
if response.status_code == 200:
# 逐行打印结果内容
for line in response.iter_lines(decode_unicode=True):
if line:
# Ollama流式返回每行是一个json字符串
try:
import json
obj = json.loads(line)
print(obj.get("response", ""), end="", flush=True)
except Exception as e:
print(f"解析流式响应出错: {e}")
else:
raise Exception(f"API 请求失败: {response.text}")
else:
response = requests.post(url, json=data)
if response.status_code == 200:
return response.json()["response"]
else:
raise Exception(f"API 请求失败: {response.text}")
# 使用示例
print("流式响应结果输出:")
query_ollama("你好,你是什么大模型,请隆重介绍一下自己", stream=True)当本地的模型部署完毕后,可以使用FastAPI进行封装后提供给外部调用,主要注意接口地址和端口,以下配置路径没有特别限制,可自定义调整:
http://127.0.0.1:8000/api/aichatfrom fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import requests
app = FastAPI()
# 定义请求模型
class ChatRequest(BaseModel):
prompt: str
model: str = "deepseek-r1:1.5b"
# 允许跨域请求(根据需要配置)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
#此处画重点,外部访问的接口地址
@app.post("/api/aichat")
async def chat(request: ChatRequest):
ollama_url = "http://localhost:11434/api/generate"
data = {
"model": request.model, #接口调用要传入的模型参数
"prompt": request.prompt, #接口调用要传入的指令
"stream": False
}
response = requests.post(ollama_url, json=data)
if response.status_code == 200:
return {"response": response.json()["response"]}
else:
return {"error": "Failed to get response from Ollama"}, 500
if __name__ == "__main__":
import uvicorn
#外部调用时访问的端口
uvicorn.run(app, host="0.0.0.0", port=8000)运行以上代码后,出现以下提示,表示接口成功运行:
INFO: Started server process [10588]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) 可以使用接口测试工具Postman测试接口是否可以正常调用,输出的结果包含了思考部分和最终结果,可以实现推理到结果的过程:
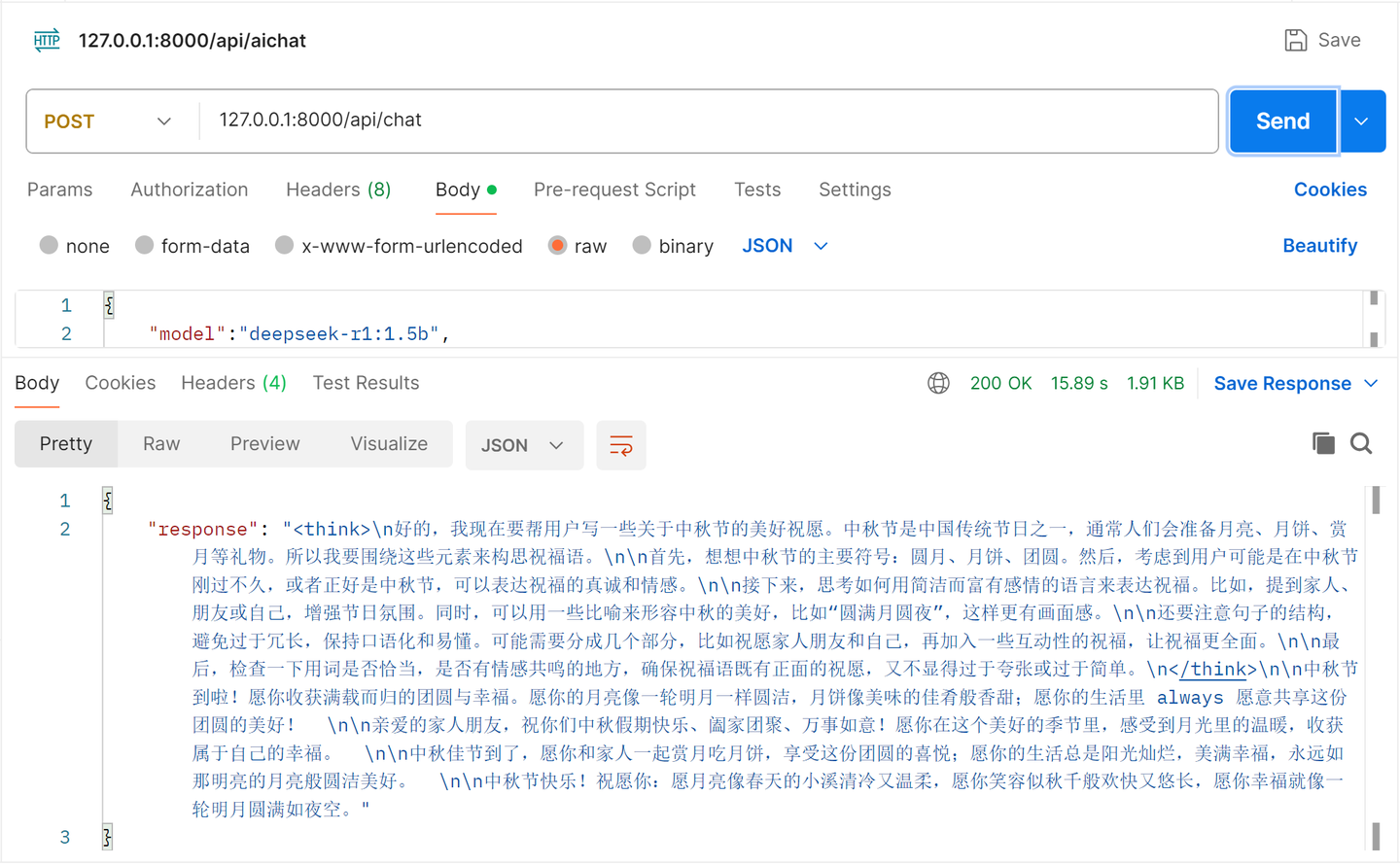
如果不清楚Postman的使用,也可以通过Python测试:
import requests
response = requests.post(
"http://localhost:8000/api/aichat",
json={"model":"deepseek-r1:1.5b","prompt": "你好,请介绍一下你自己"}
)
print(response.json())也会得到同样的输出结果:
{'response': '<think>\n\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。关于我以及我的能力,请参考官方文档或使用相关AI服务工具获取详细信息。'}原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
