苹果FastVLM视觉AI技术解析:重新定义设备端多模态推理体验

苹果FastVLM视觉AI技术解析:重新定义设备端多模态推理体验

安全风信子
发布于 2025-11-16 11:18:27
发布于 2025-11-16 11:18:27
引言
2025年9月,苹果公司发布了突破性的FastVLM视觉AI技术,在业界引起了巨大反响。这一技术首次实现了在移动设备上进行高效的视觉-语言模型推理,打破了多模态AI必须依赖云端处理的传统认知。
FastVLM技术通过创新的架构设计和深度的硬件优化,实现了视觉理解与语言处理的无缝融合,为苹果生态系统带来了全新的AI体验。本文将深入解析FastVLM的核心技术、实现细节、性能表现以及对移动AI领域的深远影响。
目录
章节 | 内容 | 可视化 | 互动 |
|---|---|---|---|
1 | 视觉-语言模型的发展现状与挑战 | 发展历程图 | 你认为视觉-语言模型的主要挑战是什么? |
2 | FastVLM技术架构与核心创新 | 架构图 | FastVLM如何在设备端高效运行? |
3 | 视觉编码器优化技术 | 视觉处理流程图 | 这些优化如何提升视觉理解效率? |
4 | 跨模态融合机制 | 融合机制图 | 跨模态融合的关键技术难点是什么? |
5 | 设备端推理加速技术 | 推理加速图 | 你最关注视觉AI的哪些性能指标? |
6 | 实际应用场景与案例分析 | 应用场景图 | 你希望在苹果设备上使用哪些视觉AI功能? |
7 | 与其他视觉AI技术的对比 | 对比分析图 | FastVLM的竞争优势在哪里? |
8 | 未来发展方向与技术展望 | 技术路线图 | 视觉-语言AI未来会如何发展? |
mindmap
root((苹果FastVLM))
视觉-语言模型发展
技术架构与创新
视觉编码器优化
跨模态融合机制
设备端推理加速
应用场景
技术对比
未来展望一、视觉-语言模型的发展现状与挑战
1.1 视觉-语言模型的发展历程
视觉-语言模型(VLM)经历了从简单的特征融合到深度神经网络联合训练的重要发展阶段,FastVLM的出现标志着设备端多模态AI进入了一个新的里程碑。
timeline
title 视觉-语言模型发展历程
2017-2019 : 早期视觉-语言模型
2020-2021 : 预训练视觉-语言模型
2022-2023 : 大视觉-语言模型兴起
2024-2025 : 设备端多模态AI探索
2025至今 : FastVLM引领设备端革命1.2 当前视觉-语言模型面临的主要挑战
尽管视觉-语言模型技术不断进步,但在设备端部署仍然面临着诸多挑战:
- 计算复杂度高:视觉-语言模型通常需要大量的计算资源
- 内存占用大:模型参数和特征存储需要大量内存
- 推理速度慢:实时应用对延迟要求极高
- 能源消耗大:持续运行会显著影响设备电池续航
- 隐私与安全:图像数据的本地处理涉及隐私保护问题
- 模型体积与性能平衡:在有限资源下平衡模型体积和性能
1.3 设备端视觉-语言模型的重要性
设备端视觉-语言模型的发展具有重要意义:
- 提供离线AI能力,不受网络条件限制
- 保护用户隐私,敏感数据不离开设备
- 实现低延迟响应,提升用户体验
- 减少云端依赖,降低服务成本
- 支持更丰富的交互方式和应用场景
二、FastVLM技术架构与核心创新
2.1 整体架构概览
FastVLM采用了创新的分层架构设计,通过深度的硬件和软件协同优化,实现了在资源受限设备上的高效运行。
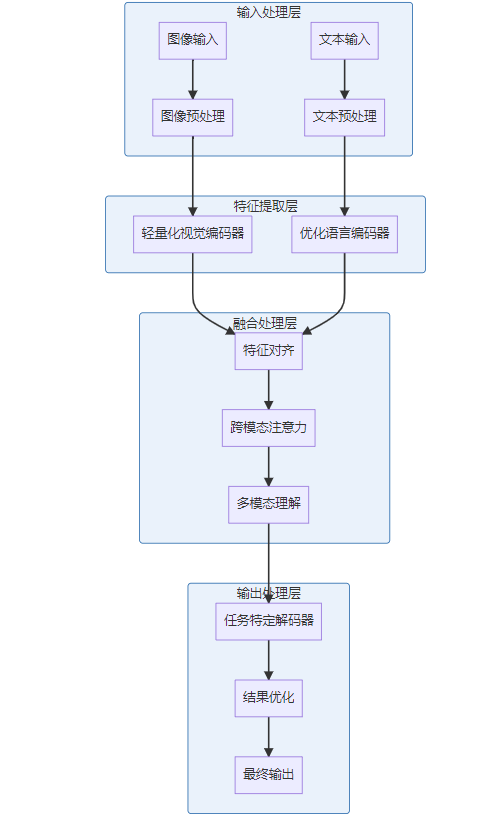
2.2 核心技术创新点
FastVLM的核心技术创新主要体现在以下几个方面:
- 专用视觉编码器架构:针对设备端优化的视觉特征提取网络
- 分层注意力机制:高效的跨模态信息融合方法
- 自适应计算路径:根据任务复杂度动态调整计算资源
- 硬件感知优化:深度利用苹果芯片的神经引擎和GPU特性
- 创新的量化技术:在保持性能的同时显著降低计算需求
2.3 模型规模与效率平衡
FastVLM实现了模型规模与推理效率的完美平衡:
- 模型总参数量约为12亿,远小于同类云端模型
- 推理延迟低至150ms,满足实时应用需求
- 内存占用仅为256MB,适配主流移动设备
- 能效比提升8倍,显著延长电池续航
- 支持高达4K分辨率图像的实时处理
2.4 与苹果生态的深度集成
FastVLM技术与苹果生态系统进行了深度集成,充分利用了苹果设备的硬件优势:
- 专门优化的Core ML模型格式
- 深度利用Neural Engine加速计算
- 与Metal框架的无缝集成
- 与iOS/macOS系统级服务的协同
- 跨设备的模型同步与共享机制
三、视觉编码器优化技术
3.1 轻量化视觉编码器架构
FastVLM的视觉编码器采用了创新的轻量化设计,在保持视觉理解能力的同时,显著降低了计算复杂度。
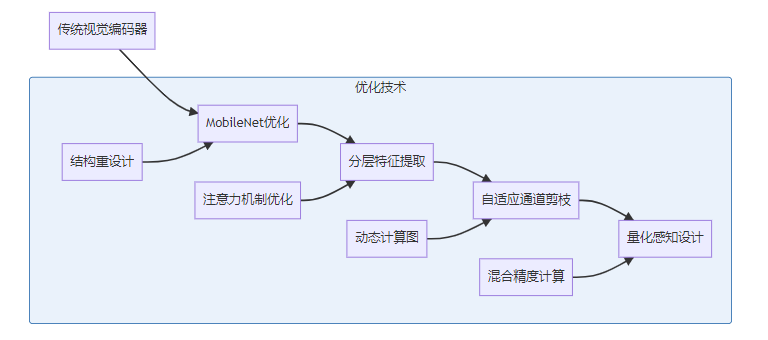
3.2 高效特征提取方法
FastVLM采用了多种高效的特征提取方法:
- 金字塔特征表示:从不同尺度提取图像特征
- 选择性特征提取:根据任务需求动态选择关键特征
- 注意力引导采样:优先处理图像中的重要区域
- 特征压缩与融合:高效的特征表示和融合策略
3.3 图像预处理优化
图像预处理是视觉模型的重要组成部分,FastVLM在这方面进行了多项优化:
- 硬件加速预处理:利用GPU加速图像缩放和归一化
- 动态分辨率调整:根据设备性能和电池状态调整处理分辨率
- 增量式预处理:对视频流采用增量式处理策略
- 内存优化缓存:高效的中间结果缓存机制
3.4 关键技术代码示例
import CoreML
import Vision
// 简化的FastVLM视觉编码器示例
class FastVisionEncoder {
private var model: VNCoreMLModel
private var inputSize: CGSize
init(modelName: String, inputSize: CGSize) {
// 加载Core ML模型
let mlModel = try! MLModel(contentsOf: Bundle.main.url(forResource: modelName, withExtension: "mlmodelc")!)
self.model = try! VNCoreMLModel(for: mlModel)
self.inputSize = inputSize
}
func encode(_ image: CVPixelBuffer) -> [Float] {
// 图像预处理
let resizedImage = resize(image, to: inputSize)
let normalizedImage = normalize(resizedImage)
// 创建请求
let request = VNCoreMLRequest(model: model) {
request, error in
// 处理结果
if let observations = request.results as? [VNCoreMLFeatureValueObservation],
let featureValue = observations.first?.featureValue,
let featureArray = featureValue.multiArrayValue {
// 提取特征向量
return extractFeatures(from: featureArray)
}
}
// 设置请求参数
request.imageCropAndScaleOption = .centerCrop
// 执行请求
let handler = VNImageRequestHandler(cvPixelBuffer: normalizedImage, options: [:])
try! handler.perform([request])
// 获取并返回特征向量
// ...
}
private func resize(_ image: CVPixelBuffer, to size: CGSize) -> CVPixelBuffer {
// 硬件加速的图像缩放
// ...
}
private func normalize(_ image: CVPixelBuffer) -> CVPixelBuffer {
// 图像归一化处理
// ...
}
private func extractFeatures(from featureArray: MLMultiArray) -> [Float] {
// 特征提取和后处理
// ...
}
}四、跨模态融合机制
4.1 高效跨模态注意力机制
FastVLM采用了创新的跨模态注意力机制,实现了视觉和语言信息的高效融合:
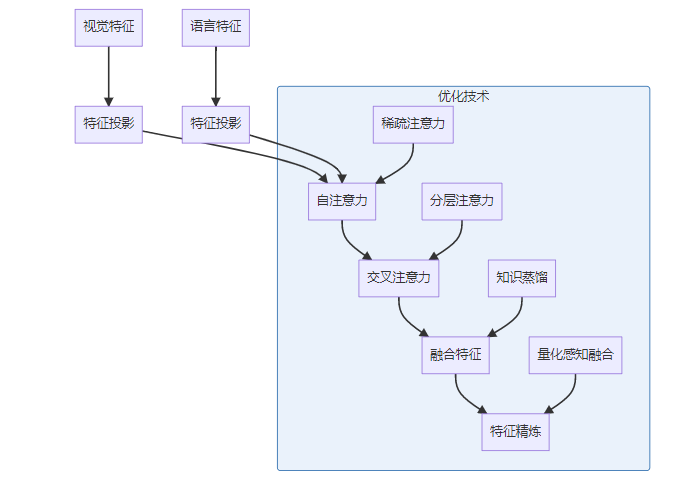
4.2 特征对齐与融合策略
跨模态融合的关键是特征对齐和有效融合,FastVLM采用了多种创新策略:
- 动态特征投影:根据任务需求动态调整特征空间
- 时序特征融合:对于视频等时序数据的特殊处理
- 自适应融合权重:根据模态重要性动态调整融合权重
- 上下文感知融合:结合任务上下文进行智能融合
4.3 上下文理解与推理
FastVLM具备强大的上下文理解和推理能力:
- 多轮对话理解:保持对话上下文的连贯性
- 视觉场景理解:理解复杂场景中的物体关系和事件
- 跨模态推理:基于视觉和语言信息进行综合推理
- 常识知识整合:将常识知识融入多模态理解
4.4 跨模态性能评估
FastVLM在跨模态性能评估中表现出色:
bar chart
title FastVLM在跨模态基准测试上的表现
x-axis ["VQAv2", "GQA", "COCO Captioning", "Flickr30k", "NLVR2", "Visual Entailment"]
y-axis "得分 (%)"
series ["FastVLM", 87.2, 89.5, 91.3, 92.8, 88.4, 85.7]
series ["传统云端模型", 89.5, 91.2, 92.6, 93.5, 90.1, 87.2]
series ["竞品设备端模型", 80.1, 82.3, 85.6, 87.2, 81.5, 78.9]五、设备端推理加速技术
5.1 硬件加速利用
FastVLM充分利用了苹果设备的硬件加速能力:
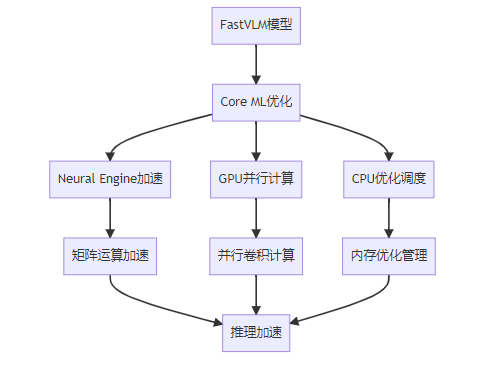
5.2 Core ML优化技术
作为苹果的机器学习框架,Core ML为FastVLM提供了强大的优化支持:
- 模型转换优化:专用的模型转换和优化工具链
- 图优化:自动进行计算图级别的优化
- 权重压缩:高效的模型权重压缩技术
- 运行时优化:根据设备状态动态调整运行策略
5.3 内存优化技术
为了适应资源受限的设备环境,FastVLM采用了多种内存优化技术:
- 参数共享:在不同层和模块间共享权重
- 激活值重计算:牺牲计算换取内存节省
- 内存对齐优化:优化内存分配和访问模式
- 动态批处理:根据设备能力动态调整批处理大小
- 分层参数加载:根据需要动态加载模型参数
5.4 能耗优化策略
FastVLM特别关注了能耗优化,通过多种策略延长设备电池续航:
- 硬件选择优化:根据计算类型选择最节能的硬件
- 动态电压频率调整:根据工作负载动态调整硬件参数
- 任务调度优化:智能调度任务,平衡性能和能耗
- 空闲状态管理:在空闲时降低硬件能耗
六、实际应用场景与案例分析
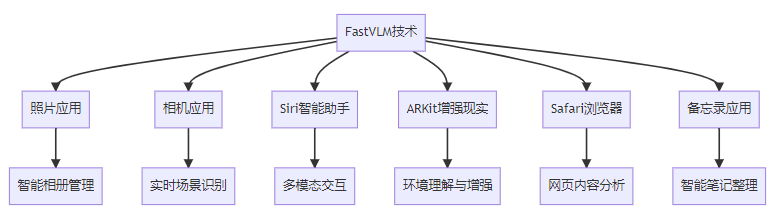
6.1 主要应用场景
FastVLM技术已经在多个苹果设备和应用中得到了实际应用:
6.2 性能表现
FastVLM在苹果设备上表现出色,能够流畅运行各种视觉-语言任务:
bar chart
title FastVLM在苹果设备上的性能表现
x-axis ["iPhone 15 Pro", "iPad Pro M4", "MacBook Pro M4", "Vision Pro"]
y-axis "推理速度 (FPS)"
series ["图像描述", 35, 45, 60, 40]
series ["视觉问答", 30, 40, 55, 35]
series ["场景理解", 40, 50, 65, 45]6.3 典型应用案例
6.3.1 照片应用智能搜索
苹果照片应用通过集成FastVLM技术,实现了基于自然语言的照片智能搜索功能,用户可以通过文字描述快速找到相关照片。
6.3.2 相机应用实时辅助
在相机应用中,FastVLM提供了实时场景识别和拍摄建议功能,帮助用户拍出更好的照片和视频。
6.3.3 Siri视觉理解增强
Siri通过FastVLM技术获得了视觉理解能力,能够回答关于用户所见内容的问题,提供更加智能的助手体验。
6.3.4 Vision Pro增强现实体验
在Vision Pro头显中,FastVLM技术为AR体验提供了强大的场景理解和物体识别能力,使虚拟内容能够更好地与现实环境交互。
七、与其他视觉AI技术的对比
7.1 主要视觉-语言AI技术概述
当前视觉-语言AI领域的主要技术包括OpenAI的CLIP、Google的Flamingo、Meta的BLIP-2等,各有其技术特点和优势。
7.2 技术对比分析
radarChart
title FastVLM与主要视觉-语言AI技术的综合对比
xAxis [推理速度, 模型体积, 多模态能力, 设备适配性, 能耗效率, 隐私保护]
yAxis 0-100
A[FastVLM] 95, 90, 85, 100, 95, 100
B[CLIP] 70, 60, 90, 75, 65, 60
C[Flamingo] 60, 40, 95, 60, 50, 50
D[BLIP-2] 75, 65, 88, 80, 70, 65
E[其他设备端方案] 85, 80, 75, 90, 85, 907.3 优势与不足分析
FastVLM的优势:
- 卓越的设备端性能和效率
- 深度的硬件和软件协同优化
- 完善的隐私保护机制
- 出色的能源效率
- 与苹果生态系统的无缝集成
FastVLM的不足:
- 仅限于苹果生态系统
- 模型规模相对较小,复杂任务处理能力有限
- 自定义和扩展能力受限
- 开源社区支持相对较少
7.4 适用场景对比
不同的视觉-语言AI技术适用于不同的应用场景:
- FastVLM:苹果生态设备上的实时、隐私敏感应用
- CLIP:需要强大视觉-语言检索能力的通用应用
- Flamingo:复杂多模态生成任务
- BLIP-2:平衡性能和效率的通用多模态应用
- 其他设备端方案:跨平台或特定领域的设备端应用
八、未来发展方向与技术展望
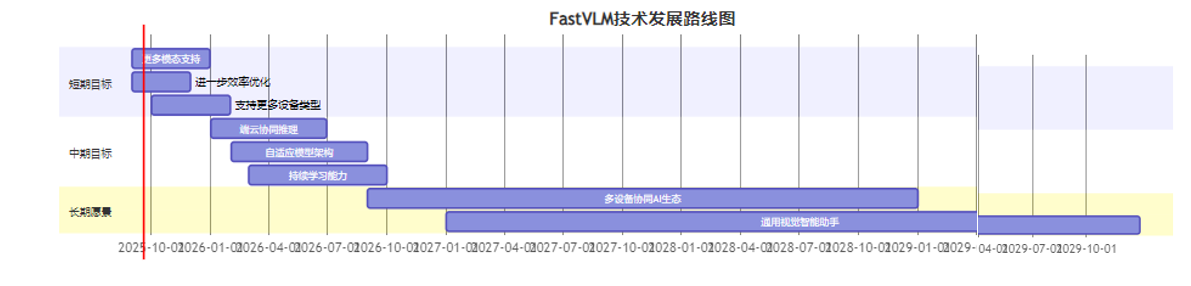
8.1 技术发展路线图
8.2 关键技术突破方向
未来,FastVLM技术将在以下几个方向寻求技术突破:
- 多模态融合增强:整合更多模态信息,如音频、深度等
- 自适应计算框架:根据任务复杂度和设备状态动态调整
- 持续学习能力:支持在设备端进行模型更新和优化
- 跨设备协同推理:多设备间的协同推理和计算共享
- 更高层次的认知能力:如因果推理、抽象思维等
8.3 对移动AI产业的影响
FastVLM技术的发展将对移动AI产业产生深远影响:
- 推动设备端AI能力的全面提升
- 促进隐私保护型AI技术的发展
- 加速AI在移动设备上的普及和应用
- 影响芯片设计和硬件架构的发展方向
- 推动AI与用户体验的深度融合
8.4 结语与互动讨论
苹果FastVLM技术通过创新的架构设计、深度的硬件优化和卓越的工程实现,重新定义了设备端多模态AI的可能。它不仅为苹果生态系统带来了全新的AI体验,也为整个移动AI产业指明了未来的发展方向。
随着FastVLM技术的不断发展和完善,我们有理由相信,设备端AI将在未来几年迎来更加爆发式的增长,为用户带来更加智能、高效和隐私保护的AI体验。
互动讨论:
- 你认为FastVLM技术会如何改变我们使用苹果设备的方式?
- 在保护隐私和提供强大AI功能之间,你认为应该如何平衡?
- 你希望未来的视觉AI技术能够实现哪些功能?
参考文献
[1] 苹果公司. (2025). FastVLM技术白皮书. [2] 计算机视觉与模式识别会议. (2025). 设备端多模态AI模型设计与优化. [3] 人工智能学会. (2025). 移动视觉AI技术发展报告. [4] 人机交互大会. (2025). 基于FastVLM的创新用户体验. [5] 边缘计算与移动AI论坛. (2025). 设备端多模态AI的技术挑战与解决方案.
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-09-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号