深度学习框架对比研究:TensorFlow与PyTorch的综合分析

深度学习框架对比研究:TensorFlow与PyTorch的综合分析

一点人工一点智能
发布于 2025-11-26 16:03:53
发布于 2025-11-26 16:03:53
编辑:陈萍萍的公主@一点人工一点智能
导读:深度学习作为人工智能的核心技术之一,已经在多个领域取得了突破性进展。TensorFlow和PyTorch作为当前最主流的深度学习框架,各自具有独特的设计理念和应用优势。本文基于一篇系统性的对比研究,从多个维度对这两个框架进行分析,旨在为研究者和工程师提供选型参考。

论文地址:https://arxiv.org/pdf/2508.04035

引言
深度学习框架的发展极大地推动了神经网络模型的开发与应用。TensorFlow由Google于2015年发布,以其强大的分布式计算能力和生产环境部署优势著称。PyTorch由Facebook于2016年推出,以其动态计算图和Python风格的编程接口迅速在研究社区中流行。两者虽然在功能上有所重叠,但在设计哲学、用户体验和生态系统方面存在显著差异。本研究从编程范式、性能表现、部署能力、社区支持等多个角度对这两个框架进行系统比较,旨在帮助用户根据具体需求做出合理选择。
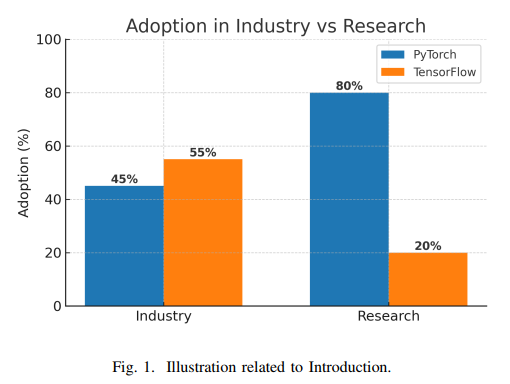
早期的深度学习框架如Theano、Caffe和Torch7等,虽然在当时具有一定影响力,但在易用性和扩展性方面存在局限。TensorFlow通过其静态计算图模型和强大的硬件支持,迅速成为工业界的主流选择。PyTorch则凭借其动态图和直观的编程风格,在研究领域取得了广泛认可。随着TensorFlow 2.0的发布,其默认启用动态图模式,进一步缩小了与PyTorch在用户体验上的差距。然而,两者在性能优化、部署工具和生态系统方面仍存在明显差异,这些差异直接影响用户的选择。

编程风格与开发体验
编程风格是TensorFlow和PyTorch最显著的区别之一。PyTorch采用“定义即运行”的动态图模式,允许用户在模型前向传播过程中使用Python的原生控制结构(如循环和条件语句)。这种设计使得调试过程更加直观,开发者可以直接使用Python的调试工具(如pdb)或打印语句跟踪代码执行过程。例如,在PyTorch中,一个简单的全连接网络可以通过继承nn.Module类并实现forward方法来实现,其代码风格与标准的Python类定义非常相似。
TensorFlow在早期版本中采用静态计算图模式,开发者需要先构建计算图,然后通过会话(Session)执行。这种方式虽然有利于性能优化和跨平台部署,但增加了代码的复杂度和调试难度。TensorFlow 2.0通过默认启用动态图模式(Eager Execution)和深度集成Keras API,显著改善了用户体验。用户现在可以像编写普通Python代码一样编写TensorFlow模型,同时仍可通过@tf.function装饰器将代码编译为静态图以提升性能。这种混合执行模式使得TensorFlow在保持灵活性的同时,兼顾了性能优化需求。
在训练循环的实现上,PyTorch通常需要用户显式编写前向传播、损失计算、反向传播和参数更新等步骤。这种设计虽然增加了代码量,但提供了更大的灵活性。例如,用户可以在每个批次训练过程中插入自定义逻辑(如梯度裁剪或动态学习率调整)。TensorFlow则通过Keras提供的model.compile和model.fit方法,将训练过程抽象为高级API,减少了样板代码,但在处理非常规训练流程时可能需要使用底层API(如tf.GradientTape)。
错误处理和调试体验也是影响开发效率的重要因素。PyTorch由于采用动态执行模式,错误信息通常直接指向源代码中的具体行数,便于快速定位问题。TensorFlow在静态图模式下的错误信息可能涉及计算图的内部表示,调试起来较为复杂。尽管TensorFlow 2.0在动态图模式下改善了这一问题,但在使用@tf.function时仍可能遇到难以理解的错误堆栈。总体而言,PyTorch在调试体验上更胜一筹,而TensorFlow通过KerasAPI在标准化任务上提供了更高的开发效率。

性能比较:训练与推理
性能是深度学习框架选择的关键因素之一,涉及训练速度、推理延迟、内存使用和扩展性等多个方面。研究表明,TensorFlow和PyTorch在性能上各有优劣,具体表现取决于任务类型、硬件配置和优化策略。
在训练吞吐量方面,早期TensorFlow凭借静态图的全局优化能力(如操作融合和并行化)在某些场景下具有优势。然而,随着PyTorch不断优化其计算内核并引入自动混合精度训练等功能,两者之间的性能差距逐渐缩小。Yapıcı等人的研究显示,在小规模图像数据集(如MNIST)上,TensorFlow的训练速度略高于PyTorch,这可能得益于其对小矩阵操作的开销优化。但在大规模图像数据上,PyTorch表现出更好的内存管理能力,训练速度反而更优。例如,在GPDS签名数据集上,PyTorch的每轮训练时间显著短于TensorFlow。
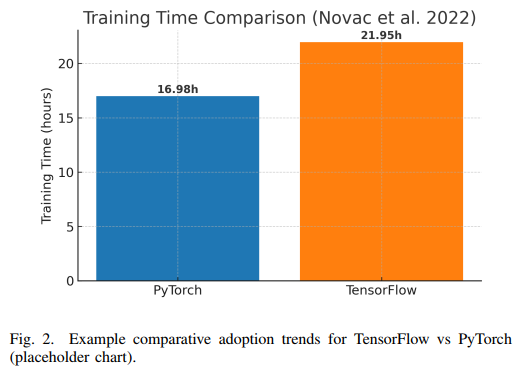
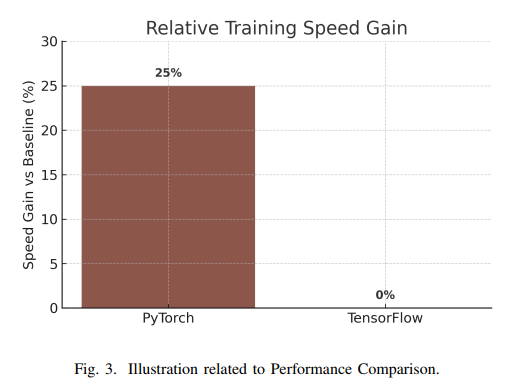
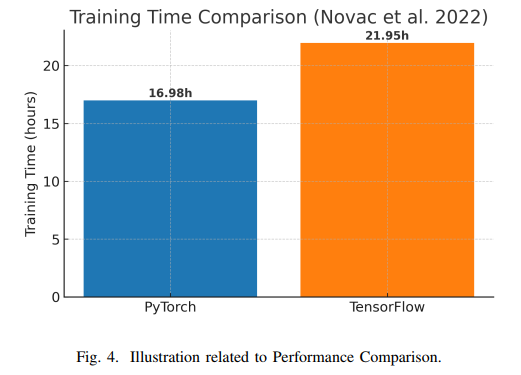
Novac等人通过对卷积神经网络的实验发现,PyTorch在总训练时间上比TensorFlow快约25.5%。具体而言,PyTorch完成训练需16.98小时,而TensorFlow需21.95小时。进一步分析表明,PyTorch的单步训练时间(0.0008693秒)比TensorFlow(0.0011189秒)快约28%。这些结果与社区反馈一致,表明PyTorch的后端实现(基于cuDNN和优化点操作)具有较高的效率。需要注意的是,TensorFlow在某些场景下可通过手动调优(如启用XLA编译或使用@tf.function)进一步提升性能,而PyTorch在大多数情况下无需额外配置即可达到良好性能。
推理性能对于生产环境尤为重要。Bedirovic等人比较了PyTorch、TensorFlow和JAX在图像分类任务上的推理延迟。对于28×28的小图像,PyTorch的平均推理时间为0.3032秒,TensorFlow(Keras)为0.8985秒,JAX为0.3620秒。PyTorch的显著优势可能源于其较低的单次推理开销。对于64×64的较大图像,JAX凭借编译器优化取得最快速度(1.2692秒),PyTorch次之(1.5961秒),TensorFlow最慢(2.0182秒)。这一结果表明,框架性能受输入规模和编译器优化程度的影响较大。
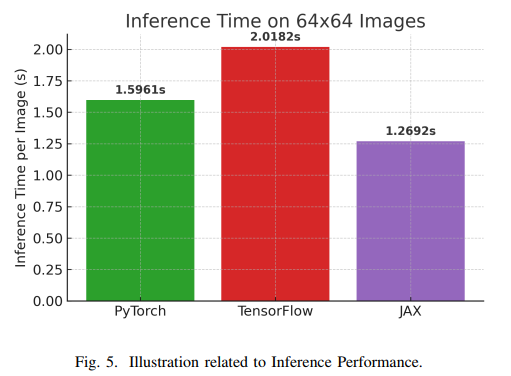
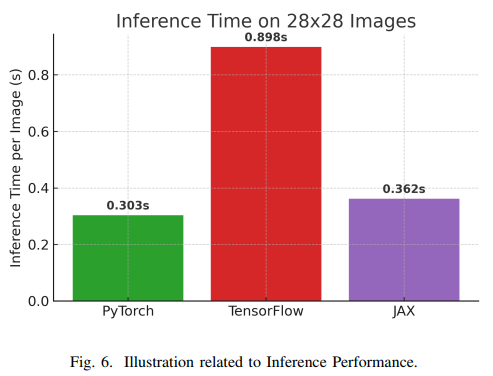
内存使用方面,PyTorch采用缓存内存分配器,减少了长时间训练中的内存碎片问题。TensorFlow则倾向于预先分配大量GPU内存以提高效率,但这可能在多进程共享GPU时引发问题。研究表明,PyTorch在处理大规模张量和可变张量大小时表现更优,这也是其在大规模数据上训练速度更快的原因之一。TensorFlow提供了细粒度内存控制选项(如tf.config.experimental.set_memory_growth),但内存碎片问题仍可能发生。
在扩展性方面,TensorFlow凭借其成熟的分布式策略(如MirroredStrategy和TPUStrategy)和多节点训练支持,在大规模计算场景中具有优势。PyTorch的分布式数据并行(DDP)近年来也取得了显著进展,能够在线性扩展多GPU训练。两者在多GPU训练效率上已接近持平,性能差异更多取决于具体实现细节而非框架本身。此外,TensorFlow对TPU的支持更为成熟,而PyTorch通过PyTorch/XLA项目也提供了TPU支持,但在某些高级功能上可能略逊一筹。
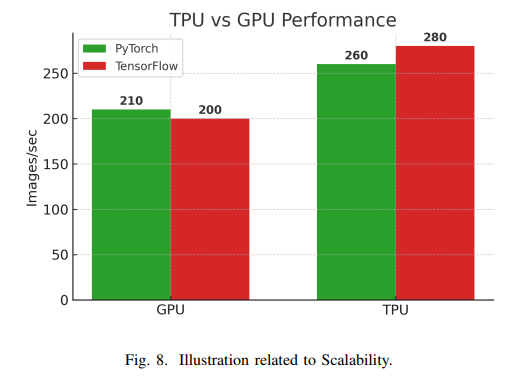
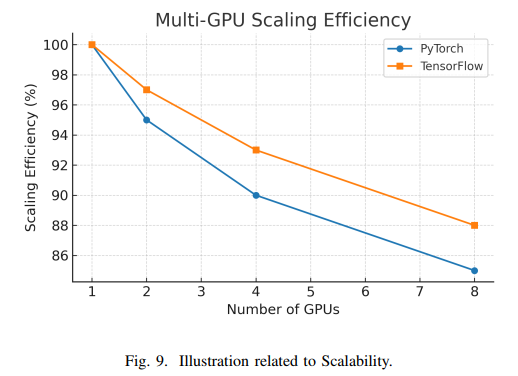

部署与模型部署灵活性
模型部署是深度学习项目从研究到生产的关键环节。TensorFlow和PyTorch在模型序列化、跨平台部署和服务化工具方面提供了不同的解决方案。
模型序列化方面,TensorFlow使用SavedModel格式保存计算图和权重,该格式与语言无关,可通过Python、C++、Java等语言加载。Keras模型还可保存为HDF5格式。PyTorch默认将模型权重保存为Python pickle文件,需依赖PyTorch和模型类定义进行加载。为支持跨平台部署,PyTorch提供了TorchScript,可通过跟踪或脚本方式将模型转换为中间表示,并在C++环境中独立运行。尽管TorchScript功能强大,但完全捕获PyTorch模型可能需要避免某些动态Python结构。


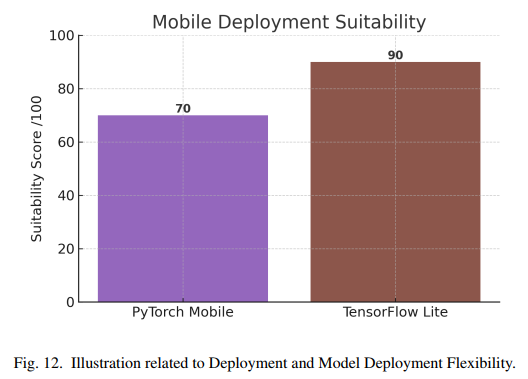
在移动端部署方面,TensorFlow Lite(TFLite)是专为移动和嵌入式设备设计的轻量级推理引擎,支持量化和硬件加速。TFLite Micro进一步扩展了在微控制器上的应用,可在内存仅几KB的设备上运行模型。PyTorch Mobile虽然也支持Android和iOS平台,但其运行时库较大,且优化程度不及TFLite。因此,TensorFlow在移动和嵌入式部署中更具优势。
浏览器和JavaScript部署是另一个重要场景。TensorFlow.js支持在浏览器中运行和训练模型,可通过WebGL或WebAssembly进行加速。PyTorch缺乏官方JavaScript运行时,需通过ONNX转换或重写模型实现浏览器部署。这使得TensorFlow在Web应用中更具便利性。
ONNX(Open Neural Network Exchange)作为跨框架模型交换标准,为PyTorch和TensorFlow提供了互操作性支持。PyTorch的ONNX导出功能覆盖了大多数常用层,可用于将模型部署到ONNX Runtime等推理引擎。TensorFlow虽支持ON导入,但其自身生态系统通常无需依赖ONNX。ONNX在跨框架模型迁移中发挥重要作用,例如将PyTorch训练的模型转换为TensorFlow格式进行部署。
服务化工具方面,TensorFlow Serving是专为生产环境设计的模型服务系统,支持版本管理、A/B测试和高性能推理。PyTorch的TorchServe由AWS和Facebook开发,提供类似功能,但在工业界的应用广度不及TensorFlow Serving。云平台对两者的支持较为均衡:Google Cloud优先集成TensorFlow,AWS和Azure则同时支持两者。总体而言,TensorFlow在部署工具链的成熟度和完整性上略胜一筹。
编译器优化是提升部署性能的重要手段。TensorFlow的XLA编译器可对计算图进行内核融合和目标架构优化,显著提升某些工作负载的性能。PyTorch通过TorchScript和PyTorch 2.0的TorchDynamo+NVFuser栈实现JIT编译优化。两者均支持通过XLA后端运行于TPU,体现了技术上的交叉融合。未来,随着编译器技术的进步,动态执行与静态编译的界限可能进一步模糊。
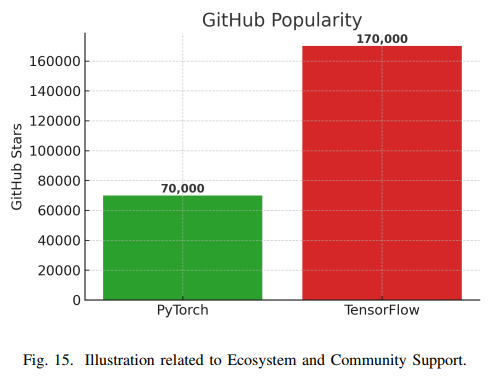

生态系统与社区支持
生态系统和社区支持是框架长期发展的重要保障。TensorFlow和PyTorch均拥有丰富的扩展库和活跃的社区,但在组织风格和重点领域上有所不同。

在扩展库方面,TensorFlow提供了一系列官方工具,如TFX用于端到端机器学习管道,TensorBoard用于可视化,TF Hub用于模型共享。这些工具与TensorFlow核心紧密集成,形成了完整的开发闭环。PyTorch则采用更加模块化的方式,通过torchvision、torchtext和torchaudio等官方库提供基础功能,并通过社区项目(如Hugging Face Transformers和PyTorch Lightning)扩展能力。这种设计使得PyTorch在研究和创新应用中更具灵活性。
计算机视觉领域,TorchVision为PyTorch提供了丰富的预训练模型和数据加载工具,TensorFlow则通过TF Image和TensorFlow Models仓库提供类似功能。自然语言处理方面,PyTorch凭借Hugging Face Transformers库占据主导地位,而TensorFlow则通过TensorFlow Text和官方发布的BERT等模型保持竞争力。强化学习、图神经网络和概率编程等领域,两者均有相应的扩展库支持,但PyTorch在研究社区中的受欢迎程度更高。
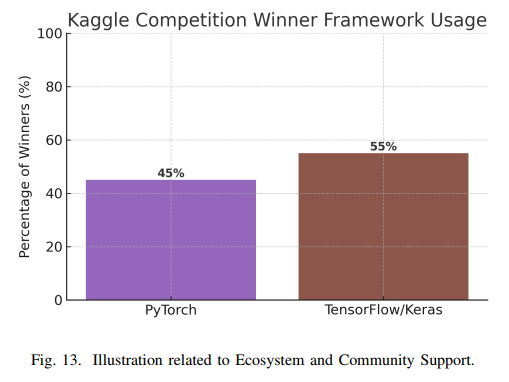
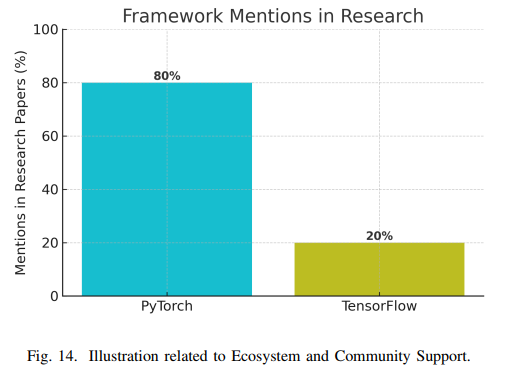
社区规模和活跃度方面,TensorFlow凭借Google的推广和早期优势,拥有庞大的用户基础。PyTorch则在2018-2020年间在研究社区实现爆发式增长。GitHub上的星标数显示,TensorFlow(超过170k)高于PyTorch(超过70k),但这反映了历史累积数据。Stack Overflow 2023年调查显示,8.41%的开发者使用TensorFlow,7.89%使用PyTorch,表明两者在工业界的应用规模相当。Kaggle调查则显示,PyTorch在研究场景中更受欢迎。
企业支持方面,TensorFlow早期在大型企业中广泛应用,特别是在具有完整ML管道需求的场景中。PyTorch随着其在研究中的成功,逐渐被Meta、AWS和Microsoft等公司采用。2022年,PyTorch加入Linux基金会,标志着其向更加开放和多元化的治理模式转变。云服务提供商对两者的支持较为均衡,Google Cloud对TensorFlow的TPU集成更为成熟,AWS和Azure则提供跨框架优化解决方案。
学习曲线是新手选择框架时考虑的重要因素。TensorFlow通过Keras提供高级抽象,降低了入门门槛。PyTorch则以其Python风格的语法和直观的设计,受到具有Python背景的开发者的青睐。两者均拥有丰富的学习资源,包括官方文档、在线课程和社区教程。总体而言,TensorFlow适合需要快速构建标准化应用的场景,而PyTorch更适合需要高度定制化的研究项目。

应用与案例研究
TensorFlow和PyTorch在不同领域的应用反映了其各自优势。计算机视觉中,Google的DeepLab和Inception等项目基于TensorFlow开发,而Meta的Detectron2和Vision Transformer参考实现则多采用PyTorch。工业界中,Tesla使用PyTorch开发自动驾驶视觉模型,Google Photos则使用TensorFlow进行图像标注。研究表明,两者在准确率上相当,但性能差异可能影响部署选择。
自然语言处理领域,PyTorch凭借Transformers库的优势占据主导地位。Google的BERT虽基于TensorFlow发布,但OpenAI的GPT系列和Hugging Face的Transformers库均优先支持PyTorch。微软等公司已将NLP研究迁移至PyTorch以利用其灵活性。TensorFlow仍在大型NLP系统(如Google翻译和语音识别)中广泛应用。
推荐系统方面,Meta的DLRM基于PyTorch开发,并针对生产环境进行了优化(如使用FBGEMM)。Google的推荐系统则基于TensorFlow构建,并与TFX集成。两者均能处理大规模嵌入表和高并发推理需求。
强化学习和机器人学中,Google DeepMind早期使用TensorFlow开发AlphaGo等项目,现已逐渐转向JAX。OpenAI的强化学习研究则基于PyTorch,其Spinning Up教程也采用PyTorch实现。机器人研究者常使用PyTorch进行原型开发,而生产系统则可能采用TensorFlow以确保稳定性。
科学研究中,PyTorch在物理、生物等领域的应用较为广泛,PyTorch Lightning等框架提供了结构化支持。TensorFlow则在AlphaFold和气候建模等项目中发挥重要作用,尤其擅长利用TPU进行大规模计算。案例研究表明,框架选择常受现有基础设施、团队熟悉度和部署要求的影响。

未来方向与开放挑战
深度学习框架的发展仍面临诸多挑战。统一易用性与性能是主要目标之一。PyTorch 2.0引入的torch.compile基于TorchDynamo和NVFuser技术,可在保持动态执行的同时实现JIT编译优化。TensorFlow则通过增强@tf.function和集成JAX的纯函数概念,提升静态图生成效率。两者可能最终收敛于混合执行模式,根据运行时需求选择性编译模型部分。
异构硬件支持是另一重要方向。XLA作为通用后端,为TensorFlow、JAX和PyTorch提供跨硬件优化能力。MLIR等中间表示技术有望进一步统一编译器基础设施,使框架成为高级前端,通过公共IR实现硬件特定优化。
分布式和联邦学习方面,TensorFlow的tf.distribute.Strategy和TensorFlow Federated提供了多设备和边缘设备训练支持。PyTorch通过DDP和PySyft等项目实现类似功能。简化分布式训练流程,使其接近单GPU工作流,仍是待解决的问题。
互操作性和标准化通过ONNX和Keras 3.0等多后端API得到推进。挑战在于在跨平台执行过程中保持性能和框架特定功能的访问能力。领域特定需求(如图神经网络、变长序列处理和稀疏张量优化)也在推动框架功能扩展。
框架设计哲学上,“最小核心”与“全功能集成”的争论仍在继续。PyTorch倾向于精简核心加外部扩展的模式,TensorFlow则提供官方集成工具链。未来可能出现平衡方案,即核心保持精简,通过官方互操作扩展提供高级功能。
长期维护和开源可持续性也是重要考虑因素。PyTorch加入Linux基金会后,由多组织共同管理,确保了发展稳定性。TensorFlow开发与Google对JAX的投资并行,需平衡创新与向后兼容性。支持遗留模型和保持用户信任是关键挑战。

结论
TensorFlow和PyTorch作为当前最主流的深度学习框架,各自具有鲜明的特点和优势。TensorFlow以其成熟的生产就绪生态系统、静态图优化能力和跨平台部署工具,在需要规模化、端到端管道和多样化部署目标的场景中表现卓越。PyTorch则凭借直观的Pythonic接口、动态计算图和灵活的研究导向设计,成为学术界的首选框架。
研究表明,两者在性能上互有胜负,选择应基于具体需求:TensorFlow适合移动/Web部署和生产环境,PyTorch适合动态性要求高的研究流程。随着编译器技术、多后端API和跨框架互操作性的发展,两者之间的技术差异可能进一步缩小,框架选择将更多取决于生态系统偏好而非技术限制。
最终,成功的深度学习项目不仅依赖于框架选择,还受团队 expertise、项目需求和发展战略的影响。理解两者的优势与局限,有助于在快速发展的深度学习领域做出明智的技术决策。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号