告别数据荒!YOLO与视觉语言模型融合,解锁遥感小样本学习新范式
原创
告别数据荒!YOLO与视觉语言模型融合,解锁遥感小样本学习新范式
原创
AI小怪兽
发布于 2025-12-03 09:32:32
发布于 2025-12-03 09:32:32
📄 论文核心摘要
该论文聚焦于解决遥感图像分析中标注数据稀缺的挑战,核心贡献在于探索并融合了传统的视觉模型与新兴的视觉-语言模型。以下是其关键要点:
- 研究方法:提出将目标检测模型(如YOLO)与视觉-语言模型(如LLaVA、ChatGPT、Gemini)相结合,以提升对遥感图像的理解能力,特别是在飞机检测和场景理解任务上 。
- 主要成果:实验表明,该方法在飞机检测与计数的准确率上取得了显著提升(平均绝对误差降低了48.46%),并且在图像质量退化的情况下也表现鲁棒。同时,对于图像的整体语义理解(使用CLIPScore衡量)也提升了6.17% 。
- 研究意义:这项工作为在小样本学习场景下进行更高效、更智能的遥感图像分析提供了新的思路和可行的技术路径 。

博主简介

深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。

论文:https://arxiv.org/pdf/2510.13993
摘要:遥感技术已成为城市规划、环境监测和灾害应对等领域的重要工具。尽管数据生成量显著增长,但传统视觉模型常受限于对大量领域特定标注数据的需求,且在复杂环境中理解上下文的能力有限。视觉语言模型通过整合视觉与文本数据提供了一种互补方法,然而由于其通用性特征,在遥感领域的应用仍待深入探索。本研究探讨将视觉模型与VLM相结合以增强遥感图像分析,重点关注飞机检测与场景理解。通过将YOLO与LLaVA、ChatGPT、Gemini等VLM集成,旨在实现更精准且具有上下文感知能力的图像解译。在标注与未标注遥感数据以及关键性的图像退化场景下进行性能评估,结果显示:在原始及退化场景中,飞机检测与计数的平均绝对误差较基线模型平均提升48.46%,尤其在挑战性条件下表现突出;同时遥感图像综合理解的CLIPScore指标提升6.17%。所提出的传统视觉模型与VLM融合方法,为推进遥感图像分析技术发展,特别是在小样本学习场景中实现更先进高效的分析开辟了新路径。
伪代码:
# ============================================
# 伪代码框架:遥感少样本学习 (视觉-语言模型融合)
# 核心思想:通过动态融合视觉与文本特征,增强模型在少量样本下的判别力
# 参考方法:DiffCLIP[citation:1], UMFT[citation:3], CPKP[citation:2] 等
# ============================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from vision_transformer import ViT # 假设的视觉编码器
from transformers import BertModel # 假设的文本编码器
class EfficientFewShotRemoteSensingModel(nn.Module):
"""
高效遥感少样本学习模型(主类)
流程:图像/文本编码 -> 多模态特征融合 -> 分类/检测
"""
def __init__(self, vision_backbone='ViT-B/16', text_backbone='BERT-base', feature_dim=512, num_classes=10):
super().__init__()
# 1. 初始化多模态编码器 (通常使用预训练权重并冻结部分参数)
self.visual_encoder = VisualEncoder(backbone=vision_backbone, output_dim=feature_dim)
self.text_encoder = TextEncoder(backbone=text_backbone, output_dim=feature_dim)
# 2. 动态多模态融合模块 (核心)
self.multimodal_fusion = DynamicMultimodalFusion(feature_dim)
# 3. 分类/检测头 (根据下游任务定制)
self.classifier = nn.Linear(feature_dim, num_classes)
# 4. (可选) 知识增强提示生成器 [参考 CPKP[citation:2]]
self.knowledge_prompt_generator = KnowledgePromptGenerator()
def forward(self, images, text_labels, support=False):
"""
Args:
images: 输入遥感图像 (B, C, H, W)
text_labels: 类别文本标签列表 (list of str) 或嵌入向量
support: 是否为支撑集(用于Few-Shot训练)
Returns:
logits: 分类logits或检测结果
fused_features: 融合后的多模态特征 (用于分析)
"""
# 1. 提取视觉特征
visual_features = self.visual_encoder(images) # (B, D_v)
# 2. 处理文本标签
if self.knowledge_prompt_generator:
# 知识增强提示生成 [citation:2]
enhanced_prompts = self.knowledge_prompt_generator(text_labels)
text_features = self.text_encoder(enhanced_prompts)
else:
# 基础提示模板,如 "a satellite image of a [LABEL]"
basic_prompts = [f"a satellite image of a {label}" for label in text_labels]
text_features = self.text_encoder(basic_prompts) # (K, D_t), K为类别数
# 3. 动态多模态特征融合 [参考 UMFT[citation:3]]
# 此模块计算视觉与文本特征间的亲和力,并选择性融合
fused_features = self.multimodal_fusion(visual_features, text_features)
# 4. 分类/预测
if support:
# 在支撑集上,可能使用基于度量的分类(如原型网络)
# 计算每个类别的原型 (对支撑集样本取平均)
pass
else:
# 查询集上,使用分类器或直接进行特征匹配
logits = self.classifier(fused_features)
return logits, fused_features
class DynamicMultimodalFusion(nn.Module):
"""
动态多模态融合模块
参考: UMFT中的亲和力引导融合(AGM)与跨模态相关(CCM)模块[citation:3]
"""
def __init__(self, feature_dim):
super().__init__()
# 亲和力矩阵计算层
self.affinity_net = nn.Sequential(
nn.Linear(feature_dim * 2, feature_dim),
nn.ReLU(),
nn.Linear(feature_dim, 1)
)
# 跨模态注意力
self.cross_attn = nn.MultiheadAttention(embed_dim=feature_dim, num_heads=8)
def forward(self, visual_feats, text_feats):
# visual_feats: (B, D), text_feats: (K, D)
B, D = visual_feats.shape
K, _ = text_feats.shape
# 1. 计算亲和力矩阵 (B, K)
affinity_matrix = []
for i in range(B):
for j in range(K):
pair = torch.cat([visual_feats[i], text_feats[j]])
affinity = self.affinity_net(pair)
affinity_matrix.append(affinity)
affinity_matrix = torch.stack(affinity_matrix).view(B, K)
# 2. 基于亲和力的特征加权与融合
# 将文本特征扩展到批次维度 (B, K, D)
text_feats_expanded = text_feats.unsqueeze(0).expand(B, -1, -1)
# 使用亲和力矩阵作为注意力权重
weights = F.softmax(affinity_matrix, dim=-1) # (B, K)
weighted_text = torch.bmm(weights.unsqueeze(1), text_feats_expanded) # (B, 1, D)
# 3. 跨模态注意力细化 [citation:3]
visual_feats_2d = visual_feats.unsqueeze(0) # (1, B, D)
text_feats_2d = text_feats.unsqueeze(1) # (K, 1, D)
# 简化处理:将视觉特征作为query,文本特征作为key/value
attn_output, _ = self.cross_attn(visual_feats_2d, text_feats_2d, text_feats_2d)
attn_output = attn_output.squeeze(0) # (B, D)
# 4. 残差连接融合
fused = visual_feats + 0.5 * weighted_text.squeeze(1) + 0.5 * attn_output
return fused
class KnowledgePromptGenerator(nn.Module):
"""
(可选) 知识增强提示生成器
参考: CPKP中的本体知识图谱检索与去冗余[citation:2]
"""
def __init__(self, knowledge_graph_path=None):
super().__init__()
# 这里简化为一个可学习的提示前缀库
# 实际实现可接入外部知识库[citation:2]
self.prompt_prefixes = nn.Parameter(torch.randn(10, 768)) # 可学习的前缀
self.relation_pruner = nn.Linear(768, 768) # 模拟关系类型剪枝
def forward(self, class_labels):
# class_labels: 原始类别名称列表
enhanced_prompts = []
for label in class_labels:
# 1. 知识检索 (此处为简化,实际可能查询知识图谱)
# 例如,对于"机场",可能关联"跑道、航站楼、飞机"等概念[citation:2]
retrieved_concepts = self.retrieve_from_knowledge_base(label)
# 2. 去冗余与特征提炼 (双层次去混淆[citation:2])
pruned_concepts = self.relation_pruner(retrieved_concepts)
# 3. 构建最终提示
prompt = f"A satellite image of {label}, which shows {pruned_concepts}"
enhanced_prompts.append(prompt)
return enhanced_prompts
# ============================================
# 训练与评估循环伪代码
# ============================================
def few_shot_episodic_training(model, optimizer, meta_train_loader, num_episodes, N_way, K_shot):
"""
小样本情景式训练循环 (Episode-based Training)
Args:
N_way: 每个Episode中的类别数
K_shot: 每个类别的支撑样本数
"""
model.train()
for episode in range(num_episodes):
# 1. 随机采样一个任务 (N个类别,每个类别K个支撑样本 + Q个查询样本)
support_images, support_labels, query_images, query_labels = meta_train_loader.sample_episode(N_way, K_shot)
# 2. 提取支撑集特征并计算原型 (用于基于度量的方法)
model(support_images, support_labels, support=True)
# 3. 在查询集上计算损失
logits, _ = model(query_images, query_labels, support=False)
loss = F.cross_entropy(logits, query_labels)
# 4. 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
def evaluate_few_shot(model, meta_test_loader, N_way, K_shot, num_tasks=600):
"""
小样本评估:在多个随机任务上平均准确率
"""
model.eval()
total_correct = 0
total_samples = 0
with torch.no_grad():
for task in range(num_tasks):
support_images, support_labels, query_images, query_labels = meta_test_loader.sample_episode(N_way, K_shot)
# ... (类似训练过程,但不反向传播)
# 计算本任务准确率并累加
accuracy = total_correct / total_samples
return accuracyI. 引言
遥感技术已成为多个领域不可或缺的工具,显著提升了城市规划、环境监测和灾害响应能力[1]–[3]。随着遥感技术的进步,生成的数据量持续呈指数级增长,为各种应用提供了宝贵的见解。数据的激增也推动了对更复杂分析工具的需求,以处理、解释并从遥感产生的复杂数据集中提取可操作的信息。高效分析和解读海量影像数据对于做出明智决策至关重要。随着遥感技术的不断进步,人工智能的融合将在释放其全部潜力方面发挥关键作用[4]。
传统的视觉模型,如YOLO [5],在目标检测和图像分类任务中已展现出卓越的性能。然而,这些模型通常需要大量领域特定的标注数据,这在遥感领域可能难以获取[6]。视觉语言模型[7]通过结合视觉和文本数据,为图像分析引入了新的维度,实现了视觉问答等任务[8]。这些模型为改进图像解译提供了一条充满前景的途径,特别是在标注数据稀缺的场景下。然而,由于其通用性特征,它们在遥感等专业领域的性能仍不确定[9]。
本文旨在通过探索视觉模型与VLM的协同组合来弥补现有差距,以增强遥感应用中的图像分析。该研究致力于利用两类模型的优势,以实现更精准、高效且具有上下文感知能力的图像解译。具体而言,本文将研究结合YOLO与LLaVA [10]、ChatGPT [11] 和 Gemini [12] 等VLM,在遥感应用的小样本学习背景下,执行包括视觉问答和图像描述在内的任务的有效性。特别地,本文作出了以下贡献:
- 对多种VLM在小样本学习场景下,于已标注和未标注的遥感数据上的性能进行定量和定性分析。
- 探索这些模型在图像质量退化条件下的表现,以模拟现实世界中的遥感挑战。
II. 相关工作
将YOLO等视觉模型与视觉语言模型相整合,为克服其各自局限、利用其互补优势以增强遥感应用中的图像分析,提供了一种前景广阔的途径。
视觉模型与VLM的结合使用可能带来若干关键优势,从而显著提升遥感图像分析的能力。其中一项可能的益处是准确性与可解释性的提升。视觉模型以其精确的目标检测能力而闻名,擅长识别和定位图像中的物体。这种能力对于交通监控中的车辆检测、城市规划中的建筑物识别以及森林管理中的树木计数等任务至关重要[13], [14]。然而,这些模型通常缺乏对检测到的对象进行上下文理解的能力。这正是VLM发挥作用的地方,它们提供了一层语义分析,能对检测对象之间的上下文和关系提供更深入的见解。通过将视觉模型与VLM集成,组合系统能够对遥感数据中的复杂场景提供更丰富、更全面的解读,从而提高分析的准确性和意义[15]。
视觉模型与VLM整合的另一个潜在优势是在图像退化条件下的性能增强。遥感经常需要应对具有挑战性的环境条件,如大气干扰、传感器噪声和变化的光照水平,这些都可能导致图像质量下降。视觉模型凭借其强大的特征检测能力,即使在不理想的图像中也能熟练识别关键要素。当这些能力与VLM的上下文推理能力相结合时,系统对噪声和图像伪影的适应能力就更强。即使视觉数据部分模糊或含有噪声,VLM也能推断出上下文和含义,从而在实际遥感应用中实现更可靠、更稳定的性能[16]。
此外,视觉模型与VLM的结合解决了遥感中经常遇到的数据稀缺挑战。获取用于训练视觉模型的大规模标注数据集可能很困难,特别是在标注数据有限的专门或研究较少的领域。然而,VLM即使在标注样本较少的情况下也能有效执行,这使其成为视觉模型的有价值的补充。通过将VLM与视觉模型结合使用,有可能开发出一种更高效的方法,最大限度地利用现有数据。这在数据稀缺是常见挑战的遥感领域尤其有益[17],有助于建立即使在标注数据集有限的情况下也能有效运行的鲁棒模型。
从方法论的角度看,现有关于视觉模型与VLM整合的工作可大致归纳为三种策略:(a) 直接向VLM提示原始图像,(b) 在VLM推理前使用检测或分割模型进行预处理(本研究采用的方法),以及 (c) 视觉和语言组件共同优化的联合多模态训练。策略(a)提供了简便性,但在场景杂乱时可能受到无关注意力干扰;策略(b)提供了强大的视觉基础,同时在语言阶段保持了灵活性;策略(c)实现了紧密的集成,但通常需要大规模、领域特定的数据集。
在VLM架构方面,先前的研究涵盖了基于CLIP的编码器、指令微调的多模态大语言模型(例如LLaVA)以及专有的基础模型(例如GPT-4o、Gemini)。基于CLIP的模型效率高且零样本迁移能力强,但可能缺乏丰富的推理能力。指令微调模型提高了任务适应性,但推理成本更高。专有模型通常提供最鲁棒的推理和退化图像处理性能,但由于其闭源特性和计算需求,可能面临部署限制。
应用领域包括细粒度目标检测、活动识别、土地覆盖分类和环境监测。以检测为重点的研究(例如,交通监控、基础设施测绘)通常青睐预处理方法,而场景级解读任务(例如,灾害响应、城市规划)则倾向于依赖直接提示或联合训练。我们的工作将预处理方法应用于两个不同的遥感场景——结构化计数(飞机检测)和非结构化解读(灾害影像)——展示了其在不同领域需求下的适应性。
若干研究,例如[18]–[21],已经探索了视觉模型与VLM的结合。他们探索了将Faster R-CNN、YOLO、ChatGPT和LLaVA等视觉模型与VLM相结合,以应对不同领域的挑战,包括钢铁表面缺陷检测、实时水污染监测和导航。其中两项研究[18], [20]将在下文详细说明。
A. 案例研究:用于智能导航的距离感知大视觉模型
Saeed等人[18]探索了通过将大视觉模型与先进计算机视觉技术相集成来增强自动驾驶车辆的导航能力,以提高空间感知和距离估计的精度。他们强调了精确距离测量在确保更安全、更高效驾驶方面的关键作用。该研究调查了立体视觉、单目深度估计和三角形相似性等方法,以估计车辆与驾驶环境中物体之间的距离。此外,该研究还结合了LLaVA自然语言处理模型,通过将目标检测数据与距离测量相结合来生成详细的场景描述,从而改善情境感知。这项工作与我们的研究密切相关,因为它同样侧重于将先进的计算机视觉技术与VLM集成,以增强场景理解和目标检测。尽管应用领域不同——分别是自动驾驶与遥感——但其提高视觉数据准确性和上下文解读能力的基本目标是一致的。
B. 案例研究:使用YOLO和LLaVA监测人类活动
Shijun Pan等人[20]的研究提供了一个成功整合视觉模型与VLM的显著案例。该研究将YOLOv8与LLaVA结合,用于监测日本冈山县旭川沿岸的人类活动。其目标是利用YOLO进行目标检测,LLaVA进行活动分析,实现从4K摄像机图像中自动识别人类活动。该研究成功证明了这种组合可以有效计数人员并识别诸如行走、奔跑和滑板等活动。通过自动化这些任务,该方法解决了人工调查的局限性,并提供了关于河道空间如何被利用的详细见解。然而,研究也指出了在较远距离和不同空间背景下检测活动方面存在挑战,这提示了需要进一步改进的领域。本案例研究凸显了将目标检测模型与VLM相结合以增强动态场景分析的潜力,这种能力可以扩展到各种遥感应用中。
III. 方法论
我们的方法结合了YOLOv8先进的目标检测能力与ChatGPT、LLaVA和Gemini等视觉语言模型的解读能力,创建了一个能够在复杂视觉数据集中识别并描述对象的系统。该项目核心基于空客飞机检测数据集[22],这是一个专门用于飞机检测任务的标注图像集合。空客飞机检测数据集包含103张高分辨率图像。除了主要的飞机数据集,另一组选定的灾害卫星图像数据集[23]也被用于定性研究。
工作流程始于数据准备阶段,在此阶段通过一系列修改来增强空客数据集,包括采用旋转、缩放和翻转等数据增强技术。这些调整旨在增加训练数据的多样性,从而提高模型的鲁棒性。同时,还准备了一组单独添加了高斯噪声的退化图像。
数据准备就绪后,YOLOv8——一个以其速度和准确性闻名的尖端目标检测模型——在该数据集上进行了微调。该模型学习精确检测和定位图像中的飞机,并为每个检测到的对象输出精确的边界框。随后,将YOLOv8的输出与VLM集成。
该方法还包含一个评估框架,该框架使用定量和定性指标,特别是通过针对原始数据和标注数据的视觉问答和图像描述任务,来评估集成模型的性能。平均绝对误差这一定量指标为目标检测准确性提供了详细分析。为确保模型在真实场景中的鲁棒性和适用性,还对其在退化条件下的表现进行了测试。此外,使用自然语言处理指标CLIPScore[24]来评估VLM生成的文本描述的质量和相关性。同时还对输出结果进行了人工评估。
IV. 实验实现
我们的实现将用于目标检测的YOLOv8s模型与VLM集成,以增强解读分析能力。我们对包含103张高分辨率遥感图像的空客飞机检测数据集进行了修改,创建了标准图像集和退化图像集。数据集示例如图1所示。退化过程通过添加高斯噪声来模拟具有挑战性的真实世界条件。生成一个均值为0、标准差为50的正态分布噪声数组,随后将其添加到原始图像中,从而产生一个噪声版本,其中像素值根据生成的噪声值随机增加或减少。


YOLOv8s是YOLOv8的一个较小变体,我们使用其预训练权重[25]在该数据集上进行了微调,微调参数设置为50个训练周期,批大小为16,图像尺寸为512x512像素。微调的目标是同时优化精确率和召回率,确保模型能够通过精确的边界框准确识别和定位数据集中的对象。为优化训练效率,采用了自动混合精度技术,并使用了初始值为0.01的余弦学习率调度策略。应用了数据增强技术,包括随机水平翻转、颜色调整、旋转、缩放和亮度调整,以增强模型的泛化能力。采用5折交叉验证方法以确保评估的鲁棒性并减轻过拟合。在整个训练过程中,通过评估验证集上的精确率和召回率来持续监控模型性能。这使得能够调整训练策略,例如优化损失函数或调整训练时长,以获得最佳结果。微调过程侧重于优化模型的超参数,以实现精确率和召回率之间的最佳平衡。
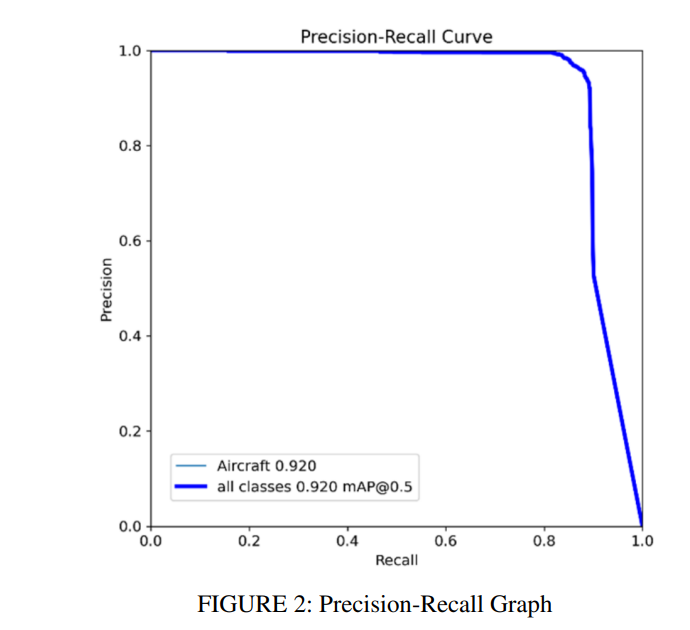
如图2所示的精确率-召回率曲线,最终模型在广泛的召回值范围内始终保持高精确率。这表明它能够准确检测飞机,同时最大限度地减少误检。曲线在接近最大召回率时的急剧下降凸显了模型能够检测几乎所有飞机实例的能力,仅在最高召回率水平时对精确率有轻微影响。均值平均精度MAP@0.5达到0.920,进一步证明了模型在提供准确检测和精确边界框方面的有效性,确保了在实际应用中的可靠性能。
微调完成后,将YOLOv8s与预训练的VLM(LLaVA、ChatGPT和Gemini)集成,以生成关于检测到对象的描述并回答相关问题。本研究具体采用了ChatGPT-4o [26]、LLaVA v1.5-13B-3GB [27]和Gemini 1.5 Flash [28]来执行这些任务。ChatGPT-4o将视觉编码器与GPT-4的大规模语言模型相结合。LLaVA v1.5基于具有130亿参数的大规模Transformer架构构建。它使用双编码器系统,一个编码器处理视觉数据,另一个处理语言处理。该模型的3GB版本针对效率进行了优化,使其能够实时处理大型数据集。Gemini 1.5 Flash利用专家混合方法创建了一个更专业化、更高效的系统。MoE架构将模型划分为更小的、独立的"专家"神经网络,每个网络都经过训练以处理特定的输入类型。
输入流程的示例包括标准和退化条件下的原始图像及标注图像。提示词示例如表1所示。评估既包括定量指标——用于目标计数的平均绝对误差,也包括定性评估——使用CLIPScore[24]以及对描述准确性和相关性的人工评估。该框架确保了在各种条件下进行严格测试,并强调了模型在真实世界的适用性。

评估包含三项关键任务:1)在飞机数据集上执行视觉问答,对标准及退化图像中的飞机进行计数;2)在灾害响应数据集上执行视觉问答;3)在标准飞机数据集上执行视觉描述生成。
V. 实验结果
本节展示了将YOLOv8与LLaVA、ChatGPT和Gemini集成后所得的定量和定性性能结果。
A. 定量结果
定量结果总结于表2,显示了每个VLM在原始图像、退化图像、带边界框的原始图像以及带边界框的退化图像上的目标计数准确度(以MAE表示)。原始和退化图像的结果代表了基线方法,我们将其与所提出的方法(即包含边界框的行)进行比较。尽管我们单独评估了YOLOv8s以了解其基线检测行为,但本工作未详细报告仅使用YOLO的结果,因为重点在于视觉语言模型如何通过上下文推理来补充检测输出。YOLO组件主要作为区域提议阶段,使VLM能够在候选感兴趣区域上运行,而非整个场景。还需注意的是,除了此计数任务外,其余评估任务无法由独立的YOLO模型执行,因为它们并非定量任务。
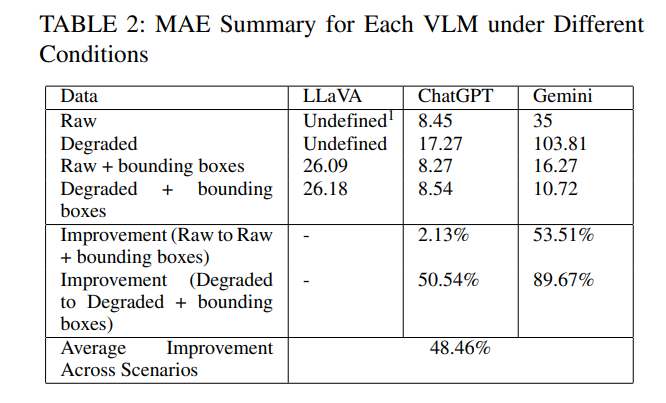
LLaVA在标准条件和退化条件下均无法生成响应(在表格中标记为"未定义"),但在包含边界框时能够响应。ChatGPT在原始和退化图像上均表现出中等性能,且在应用边界框后显示出明显改进,尤其在退化条件下。Gemini展示了最显著的改进,特别是在退化条件下。
总体而言,结果表明包含边界框通常能增强所有模型的性能,尤其是在涉及退化图像的挑战性场景中,平均改进幅度达48.46%。细节将在下一节进一步讨论。
B. 定性结果
我们同时进行了缩放CLIPScore和人工评估,结果表明基于原始图像的结果在定性上有所改善。
CLIPScore结果总结如表3所示。原始结果代表了基线方法,我们将其与所提出的方法(即包含边界框的行)进行比较。如前一节所述,CLIPScore可能无法可靠地衡量退化图像中的概念对齐,因为图像退化会扭曲关键特征,导致评估不准确——这种评估更多受视觉质量而非底层内容的影响,因此在这种情况下,原始图像比较更适合进行定性评估。结果表明,包含边界框通常能提升模型性能,表3中更高的CLIPScore值证明了这一点。边界框可能通过将模型的注意力引导至图像的相关区域来提供帮助,从而产生更准确且上下文更合适的描述。
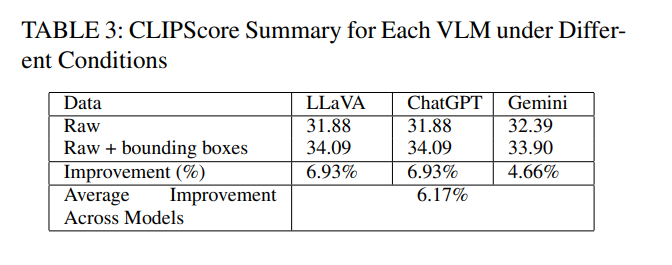
总体而言,CLIPScore结果表明,虽然所有模型在原始图像上表现中等,但添加边界框提高了描述准确性,特别是对于ChatGPT和LLaVA,模型平均改进幅度为6.17%。这些发现得到了与图3对应的表4和表5中人工评估结果的进一步证实,这些评估对生成描述的相关性和正确性提供了更多见解,确认了边界框集成的益处。这些示例的详细讨论将在下一节提供。
我们还对一个灾害卫星影像的次要数据集[23]进行了人工评估。该评估揭示了在不同背景下发掘额外见解的潜力,因为模型在添加边界框后能够推断出更好的答案。总体而言,数据集中的边界框有助于VLM估算飞机数量、提高定位准确性,并在图像描述中更有效地检测其他对象的存在。这将在下一节进行更详细的探讨。
C. 计算性能
为评估所提出流程的实际可行性,我们在评估设置下测量了其经验运行时间:使用NVIDIA A100 GPU进行YOLOv8s推理,并使用本地或基于API的查询进行VLM处理。YOLOv8s检测每张512×512图像平均耗时约12毫秒。每个检测到的边界框的VLM处理时间约为:使用LLaVA(本地)约300毫秒,使用Gemini 1.5 Flash(API)约0.9秒,使用ChatGPT-4o(API)约1.2秒。对于我们数据集中的典型场景,总处理时间范围从约1.0–1.5秒(YOLO + LLaVA)到约3–6秒(YOLO + 基于API的VLM)。这些时间表明该方法非常适用于批量或离线遥感分析,而实时部署将受益于边界框优先级排序或本地VLM托管等优化技术。
VI. 讨论
本节对前文呈现的结果进行严谨的性能讨论,并提供详细的解读和潜在的启示。
观察到的YOLO + VLM流程相较于单独使用VLM所获得的性能提升,似乎源于检测与多模态推理的互补性,而非单纯的检测精度。首先,YOLO生成的边界框可以将VLM的视觉焦点缩小到相关区域,抑制遥感图像中常见的背景干扰。其次,这种空间基础可以增强上下文理解,使VLM即使在输入图像质量下降时也能保持计数和场景解读的一致性。第三,这两个组件可能导致误差补偿行为:VLM可以通过识别空间模式或重复排列(例如,部分遮挡的飞机队列)来推断漏检,而YOLO的检测可以限制VLM因幻觉或误解而导致的过度计数。
我们在结果中观察到,YOLO偶尔会未能检测到部分遮挡或重叠的飞机,导致计数不足。而VLM,基于检测到的对象的边界框和更广泛的场景上下文,能够推断出缺失飞机的存在。另一方面,在一些杂乱的机场场景中,YOLO将地面车辆或结构误分类为飞机。VLM在对边界框裁剪区域进行推理时,排除了这些误检,使计数更接近真实值。
A. 目标检测
平均绝对误差通过计算预测目标计数与实际计数之间的平均绝对差来量化模型预测的准确性。在表2所示的结果背景下,MAE值揭示了不同VLM在不同条件下的性能存在显著差异。
如图4所示,这些发现强调了边界框在提高目标计数准确性方面的关键作用,尤其是在具有挑战性的视觉环境中。这些线的下降趋势表示MAE的降低。这种降低表明,当数据补充了边界框时,模型性能更好(即更准确)。Gemini的MAE显著降低以及LLaVA的明显改进说明了边界框在提供必要上下文线索方面的有效性,从而带来更准确可靠的模型性能。
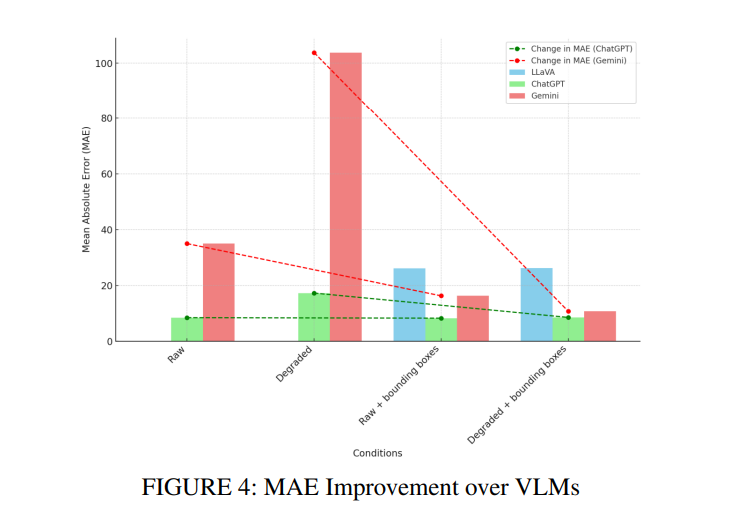
1) 原始与退化条件
在原始图像上,ChatGPT表现良好,MAE为8.45,表明准确性很高。当图像退化时,MAE增加到17.27。这一增加表明ChatGPT的准确性受到图像质量下降的影响,尽管它仍然保持了合理的性能。
对于原始图像,Gemini的MAE为35,表明在此场景下其准确性低于ChatGPT。当图像退化时,Gemini的MAE显著上升到103.81,表明性能大幅下降。这表明Gemini对图像质量退化更敏感,这极大地影响了其做出准确预测的能力。
LLaVA在原始或退化图像上均未返回可用的MAE,表明该模型在这些条件下难以生成响应。这种可用输出的缺乏表明LLaVA可能需要额外的上下文或增强(如边界框)才能在这些场景中有效运行。
2) 带边界框的原始图像
在原始图像添加边界框后,ChatGPT的MAE略微改善至8.27。这一改进虽然不大,但表明即使在最佳情况下(使用原始图像),模型在通过边界框获得额外上下文信息时也能进一步提高其准确性。
对于Gemini,在原始图像中引入边界框带来了显著改进,将MAE从35降低到16.27。这一降低表明Gemini从增加的上下文中获益匪浅,表明该模型可以利用边界框来持续增强其性能。
就LLaVA而言,在原始图像添加边界框后,MAE为26.09。虽然这是一个可用的结果,但与其他模型相比仍然较高,表明即使在原始图像的最佳条件下,LLaVA也可能未能充分利用边界框提供的额外上下文。
3) 带边界框的退化图像
当在退化图像中添加边界框时,ChatGPT的MAE从17.27略微降低至8.54。这表明边界框帮助模型显著恢复了准确性,几乎匹配了其在原始图像上的性能。ChatGPT展示了利用边界框克服退化图像挑战的强大能力。
Gemini在退化图像中添加边界框时显示出巨大的改进,其MAE从103.81降至10.72。这一大幅下降凸显了边界框提供的额外上下文对于Gemini至关重要,使其即使在处理低质量图像时也能 drastically 提高性能。
LLaVA在退化图像中使用边界框时,MAE为26.18,这是一个稳定但高于ChatGPT和Gemini的值。虽然边界框的添加帮助LLaVA在之前无法响应的情况下做出响应,但它在实现更低MAE值方面仍然面临挑战,表明可能需要更多的上下文或进一步调优以获得更好的性能。
表2中的定量结果强化了观察到的模型对YOLO检测依赖性的差异。LLaVA的MAE在添加YOLO边界框后仅略有变化(原始:8.45 → 8.27;退化:17.27 → 8.54),表明其严格遵循YOLO的输出,独立修正能力有限。ChatGPT-4o表现出中等程度的依赖,在原始图像上有适度改进(26.09 → 8.27),但在退化条件下有显著增益(35.00 → 16.27),表明其会偶尔利用场景上下文重新评估检测结果。Gemini 1.5 Flash表现出最高程度的独立性,通过在原始(35.00 → 16.27)和退化图像(103.81 → 10.72)上产生最大的改进,积极识别并纠正了YOLO的过度计数和计数不足。这些模式证实了不同VLM之间"信任水平"的差异直接影响了从集成YOLO生成边界框中获益的程度。
B. 图像描述
图5可视化了引入边界框时每个VLM的CLIPScore改进情况(如表3所示),为了解每个模型将其生成的文本描述与图像内容对齐的程度提供了见解。
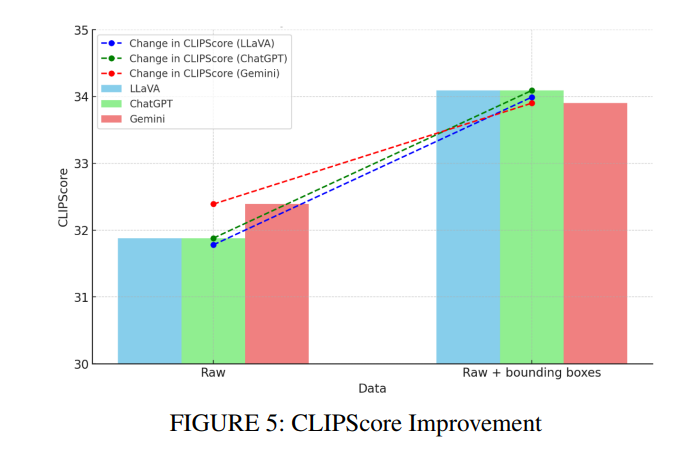
对于原始图像,LLaVA和ChatGPT的CLIPScore均为31.88,而Gemini以32.39的分数略微优于它们。这表明所有三个模型在生成与视觉内容对齐的描述方面表现相似,Gemini略有优势。这些分数表明模型在捕捉图像中的关键元素(例如在机场场景中识别飞机等重要物体)方面表现相似。分数的微小差异反映了每个模型处理和解释原始视觉数据方式的细微差别。
当引入边界框时,所有三个模型的CLIPScore都有明显改善。LLaVA和ChatGPT的分数都增加到34.09,上升了2.21。这一改进强调了边界框提供的额外上下文带来的优势,使这些模型能够生成更准确和上下文相关的描述。Gemini也显示出改进,其CLIPScore上升了1.51至33.90,表明它也同样受益于边界框提供的视觉线索,尽管程度略低于LLaVA和ChatGPT。
这些结果强调了上下文信息在提高VLM描述准确性方面的关键作用。所有模型在添加边界框后性能的一致提升表明,在获得额外上下文时,原始图像可以实现与视觉内容更好的对齐。分数的适度增加表明这些模型可能需要进行进一步的微调,但它们证明了融入视觉线索(如边界框)能有效增强其生成更准确和上下文更丰富的描述的能力。总体而言,这些结果虽然是边际性的,但仍然表明,虽然所有模型都能有效地描述图像,但它们捕捉额外细节和上下文的能力可以通过视觉线索(如边界框)的可用性得到潜在增强。
C. 上下文理解
如表4和表5所示,VLM在示例中提供的描述突出了不同程度的上下文理解能力。在原始图像描述中,ChatGPT脱颖而出,提供了更详细和结构化的解读,识别了诸如飞机排列、施工区域和整体机场活动等具体元素。当引入边界框时,所有模型都提高了其上下文感知能力,LLaVA认识到了用于分析的标注的目的,而ChatGPT则通过解读图像中不同区域的功能进一步增强了其描述。
1) 飞机相关数据集
为了展示具体例子,表6和表7中显示的由LLaVA生成的基于原始图像的描述提供了对图像的初步理解,突出了关键元素,如机场布局、多条跑道、滑行道和飞机停机位。它注意到飞机的存在,并表明该图像可能是一个繁忙机场的航空或卫星视图。然而,通过边界框提供的额外细节提供了更细致的理解。原始描述代表了基线方法,我们将其与所提出的方法(即包含边界框的行)进行比较。如图6和表6所述,边界框有助于识别具体的飞机数量——至少13架——它们位于图像中不同的距离,从而增强了观看者对机场规模和活动水平的认识。此外,如图6所示,包含飞机附近的卡车和支援车辆增加了进一步的上下文,表明在停机坪上正在进行的动态操作,例如起飞准备或着陆后程序。这些边界框有助于细化对场景的解读,提供了机场繁忙环境以及与航空运输操作相关的复杂活动的更清晰画面,这些已成功被模型识别,如表6所示。类似地,在表7的另一个例子中,与没有边界框的原始图像相比,模型也成功识别出场景中至少有14架飞机,一些位于前景,其他位于更远的背景中。这种更丰富的上下文允许对图像进行更精确和知情的分析,强调了详细视觉标注在理解复杂场景中的重要性。

对模型性能的定性评估超越了简单的检测,延伸到提供额外的上下文信息。例如,机场场景中卡车的存在可以使用边界框突出显示,增加了一层对场景环境的理解。这种能力在上下文很重要的场景中特别有益,例如区分机场的不同运营区域或了解特定区域的活动水平。在场景中标注和识别多个对象的能力增强了视觉语言模型的描述能力,允许进行更全面和信息丰富的描述。这种额外的上下文不仅提高了态势感知能力,还通过提供更完整的场景画面来辅助更好的决策过程。然而,需要注意的是,边界框提供的额外上下文理解仅在某些场景中带来改进,而不是在所有情况下一致地提高描述准确性。
2) 灾害相关数据集
对灾害卫星影像次要数据集的探索进一步巩固了组合方法可以增强态势感知并支持更好决策的观点。经过人工评估,将边界框与VLM集成大大提高了确定疏散路线状态的准确性,成功识别了原始图像(无边界框)未能检测到的畅通路径。由YOLO生成的边界框提供了关键物体(本例中为车辆)的精确定位。这种空间信息对于评估路线状况至关重要。虽然诸如YOLO之类的目标检测模型擅长识别和标记图像中的物体,但它们本身并不提供对场景或上下文的整体理解。另一方面,VLM旨在从视觉数据解释和生成自然语言描述,但有时可能缺乏空间推理的精确性或有效关联分散物体的能力。通过结合YOLO目标检测的优势和VLM的解释能力,分析变得更加稳健。边界框作为引导,帮助VLM更好地理解车辆与道路基础设施之间的空间关系。这种协同作用允许对疏散路线进行更准确的评估。
如图7和表8所示,边界框突出了主要道路上的车辆,特别是在桥梁的引桥上。这种视觉线索使VLM能够推断出存在潜在的拥堵,表明该路线可能部分受阻而非完全畅通。类似地,在下层道路上检测到单一车辆且周围没有任何拥堵,这使得VLM可以得出结论,这条次要路线仍然畅通无阻。这种组合方法弥合了纯目标检测和上下文理解之间的差距,从而产生更准确和可操作的评估,这对于有效指导救援工作至关重要。通过利用YOLO的精确定位和VLM的上下文推理,该分析提供了关于哪些疏散路线可行的更可靠判断,最终在紧急情况下支持更好的决策。


VII. 结论
本文的研究工作表明,将YOLOv8与视觉语言模型(即LLaVA、ChatGPT和Gemini)相集成,为飞机检测和场景解读提供了一个鲁棒的框架。这种组合方法展现了在提升图像分析的定性与定量性能两方面的潜力。
其所带来的提升是双重的。从定量角度看,它提升了目标计数相关性能,尤其是在图像退化条件下,在原始及退化场景中,所有模型的平均绝对误差平均改善了48.46%。从定性角度看,如各示例所示,边界框的使用在各种场景下为多个目标提供了更丰富的上下文洞察,并导致CLIPScore平均提升了约6.2%。这使得能够更准确、更全面地理解复杂的视觉数据,本文中显著的示例证明了这一点,这些模型有效地提供了关于飞机数量和位置的详细上下文信息,识别了数据集中的其他元素,并推断出灾害场景中的畅通路线。
所提出的视觉模型与VLM的集成极大地提升了检测准确性和描述质量。它构成了一个用于分析遥感图像的强大工具,特别是在数据稀缺环境下(零样本或少样本学习至关重要)。虽然本工作侧重于飞机检测和灾害响应,但该方法不依赖于特定任务,可以扩展到其他领域,包括土地覆盖分类和变化检测,且仅需极少的架构修改。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
