源码级解读:YOLO26的新架构与创新设计
原创

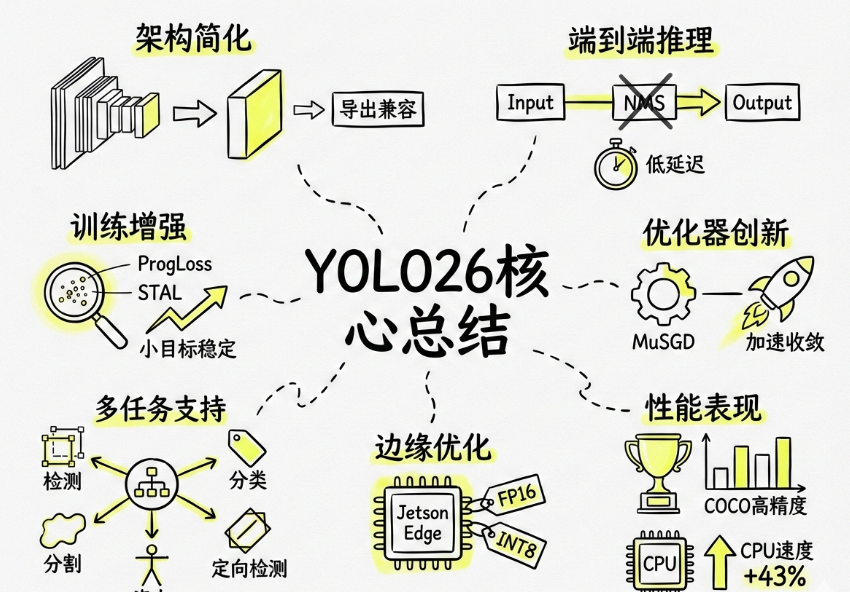
YOLO26核心总结
- 架构简化:移除分布焦点损失(DFL),简化边界框回归,提升导出兼容性。
- 端到端推理:采用无NMS设计,直接输出检测结果,降低延迟与部署复杂度。
- 训练增强:引入渐进损失平衡(ProgLoss)与小目标感知标签分配(STAL),提升小目标检测稳定性。
- 优化器创新:使用MuSGD优化器,结合SGD与Muon优势,加速模型收敛。
- 多任务支持:统一框架支持检测、实例分割、姿态估计、定向检测与分类。
- 边缘优化:支持FP16/INT8量化,在Jetson等设备上实现低延迟实时推理。
- 性能表现:在COCO等基准上达到高精度,CPU推理速度较前代提升最高43%。

应用场景:适用于无人机、机器人、智能制造等资源受限的边缘设备实时视觉任务。
博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
1.YOLO26原理介绍

论文:https://arxiv.org/pdf/2509.25164
摘要:本研究对Ultralytics YOLO26进行了全面分析,重点阐述了其关键架构改进及其在实时边缘目标检测中的性能基准测试。YOLO26于2025年9月发布,是YOLO系列最新、最先进的成员,专为在边缘及低功耗设备上实现高效、精确且易于部署的目标而构建。本文依次详述了YOLO26的架构创新,包括:移除了分布焦点损失(DFL);采用端到端的无NMS推理;集成了渐进损失(ProgLoss)与小目标感知标签分配(STAL);以及引入了用于稳定收敛的MuSGD优化器。除架构外,本研究将YOLO26定位为多任务框架,支持目标检测、实例分割、姿态/关键点估计、定向检测及分类。我们在NVIDIA Jetson Nano与Orin等边缘设备上呈现了YOLO26的性能基准测试,并将其结果与YOLOv8、YOLOv11、YOLOv12、YOLOv13及基于Transformer的检测器进行比较。本文进一步探讨了其实时部署路径、灵活的导出选项(ONNX、TensorRT、CoreML、TFLite)以及INT8/FP16量化技术。文章重点展示了YOLO26在机器人、制造业及物联网等领域的实际应用案例,以证明其跨行业适应性。最后,讨论了关于部署效率及更广泛影响的见解,并展望了YOLO26及YOLO系列的未来发展方向。
关键词:YOLO26;边缘人工智能;多任务目标检测;无NMS推理;小目标识别;YOLO(You Only Look Once);目标检测;MuSGD优化器

Detection (COCO)
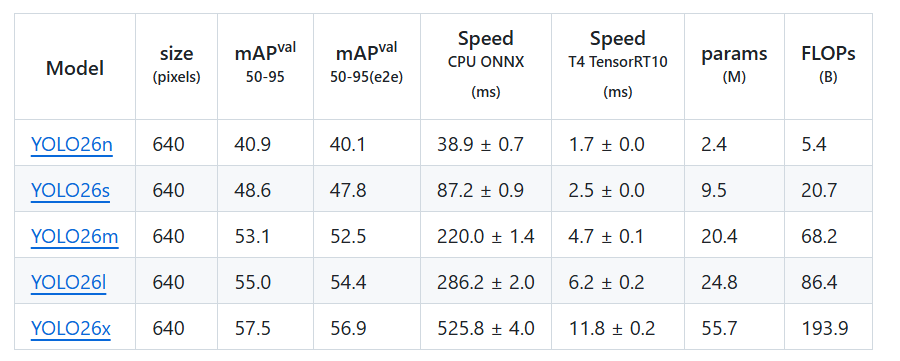
结构框图如下:
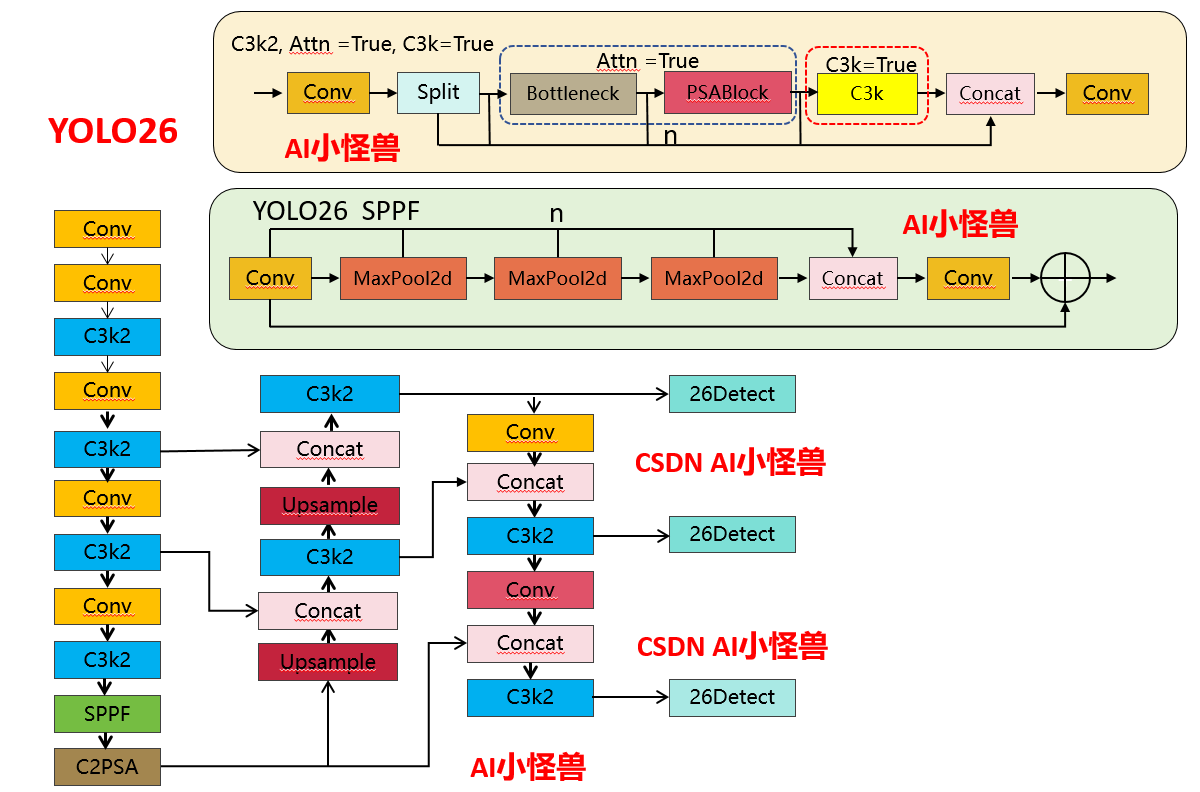
1.1 YOLO11 vs YOLO26结构差异性
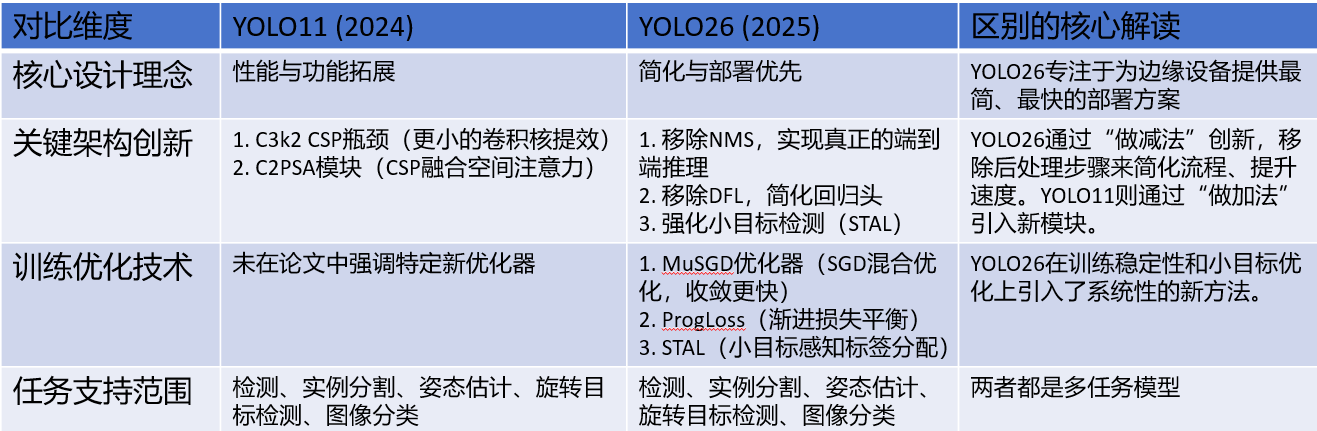
1.1.1 SPPF 核心差异对比
1)池化次数灵活性:YOLO11 的 3 次池化是硬编码的,要修改必须改源码;YOLO26 通过n参数可灵活调整(比如设为 2 次或 4 次),无需改核心逻辑。
2)Shortcut 设计:YOLO26 新增的残差连接能缓解深层网络的梯度消失问题,提升特征复用能力,而 YOLO11 无此设计。
3)激活函数控制:YOLO26 禁用 Conv1 的激活函数,让特征在池化前保持更 “原始” 的状态,是工程上对特征提取的优化。
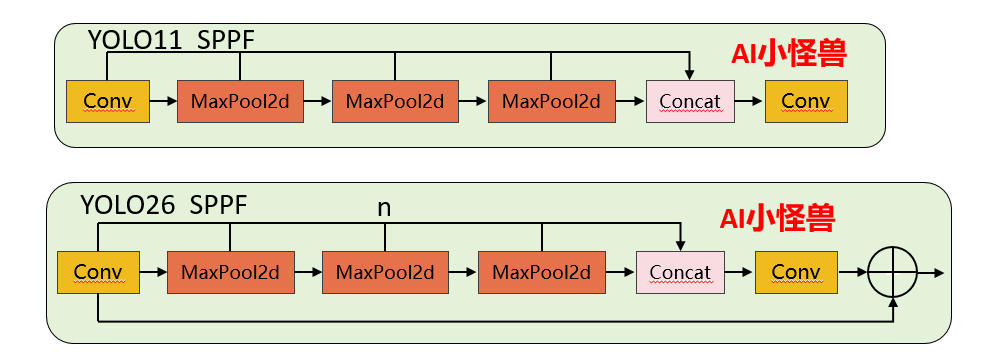
源码位置:ultralytics/nn/modules/block.py
YOLO26 SPPF
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1: int, c2: int, k: int = 5, n: int = 3, shortcut: bool = False):
"""Initialize the SPPF layer with given input/output channels and kernel size.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
k (int): Kernel size.
n (int): Number of pooling iterations.
shortcut (bool): Whether to use shortcut connection.
Notes:
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1, act=False)
self.cv2 = Conv(c_ * (n + 1), c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.n = n
self.add = shortcut and c1 == c2
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply sequential pooling operations to input and return concatenated feature maps."""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(getattr(self, "n", 3)))
y = self.cv2(torch.cat(y, 1))
return y + x if getattr(self, "add", False) else y
YOLO11 SPPF
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))
1.1.2 C3k2 核心差异对比
1)注意力机制的新增:YOLO26 的 C3k2 首次引入PSABlock(金字塔注意力模块),通过attn参数控制是否启用,这是两者最核心的功能差异 —— 启用后模块会先通过 Bottleneck 提取基础特征,再通过 PSABlock 增强关键区域的特征权重,提升小目标 / 复杂场景的检测效果。
2)分支逻辑的扩展:YOLO11 的分支仅受c3k控制,而 YOLO26 的分支逻辑优先级为attn > c3k,即只要attn=True,会优先启用注意力模块,忽略c3k的配置。
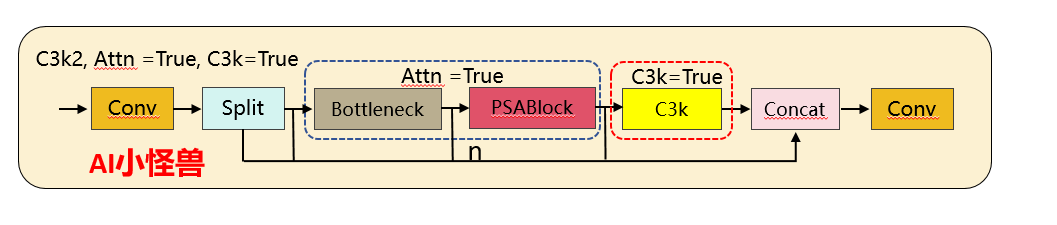
重复模块m (n次迭代):
┌─────────────────────────────────────────────────────────┐
│ │
│ 如果 attn=True: │
│ Sequential( │
│ Bottleneck(self.c, self.c), │ ←─ 先特征提取
│ PSABlock(self.c, attn_ratio=0.5, num_heads=...) │ ←─ 后注意力增强
│ ) │
│ │
│ 否则如果 c3k=True: │
│ C3k(self.c, self.c, 2) │ ←─ 同YOLOv11
│ │
│ 否则: │
│ Bottleneck(self.c, self.c) │ ←─ 同YOLOv11
│ │
└─────────────────────────────────────────────────────────┘
YOLO26 C3k2代码:
源码位置:ultralytics/nn/modules/block.py
YOLO26 C3k2代码:
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(
self,
c1: int,
c2: int,
n: int = 1,
c3k: bool = False,
e: float = 0.5,
attn: bool = False,
g: int = 1,
shortcut: bool = True,
):
"""Initialize C3k2 module.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of blocks.
c3k (bool): Whether to use C3k blocks.
e (float): Expansion ratio.
attn (bool): Whether to use attention blocks.
g (int): Groups for convolutions.
shortcut (bool): Whether to use shortcut connections.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
nn.Sequential(
Bottleneck(self.c, self.c, shortcut, g),
PSABlock(self.c, attn_ratio=0.5, num_heads=max(self.c // 64, 1)),
)
if attn
else C3k(self.c, self.c, 2, shortcut, g)
if c3k
else Bottleneck(self.c, self.c, shortcut, g)
for _ in range(n)
)
YOLO11 C3k2代码:
YOLO11 C3k2代码:
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
1.2 YOLO26核心创新点
YOLO26引入了多项关键架构创新,使其区别于前几代YOLO模型。这些增强不仅提高了训练稳定性和推理效率,还从根本上重塑了实时边缘设备的部署流程。本节将详细描述YOLO26的四项主要贡献:(i)移除分布焦点损失(DFL),(ii)引入端到端无NMS推理,(iii)新颖的损失函数策略,包括渐进损失平衡(ProgLoss)和小目标感知标签分配(STAL),以及(iv)开发用于稳定高效收敛的MuSGD优化器。我们将详细讨论每一项架构增强,并通过对比分析突显其相对于YOLOv8、YOLOv11、YOLOv12和YOLOv13等早期YOLO版本的优势。
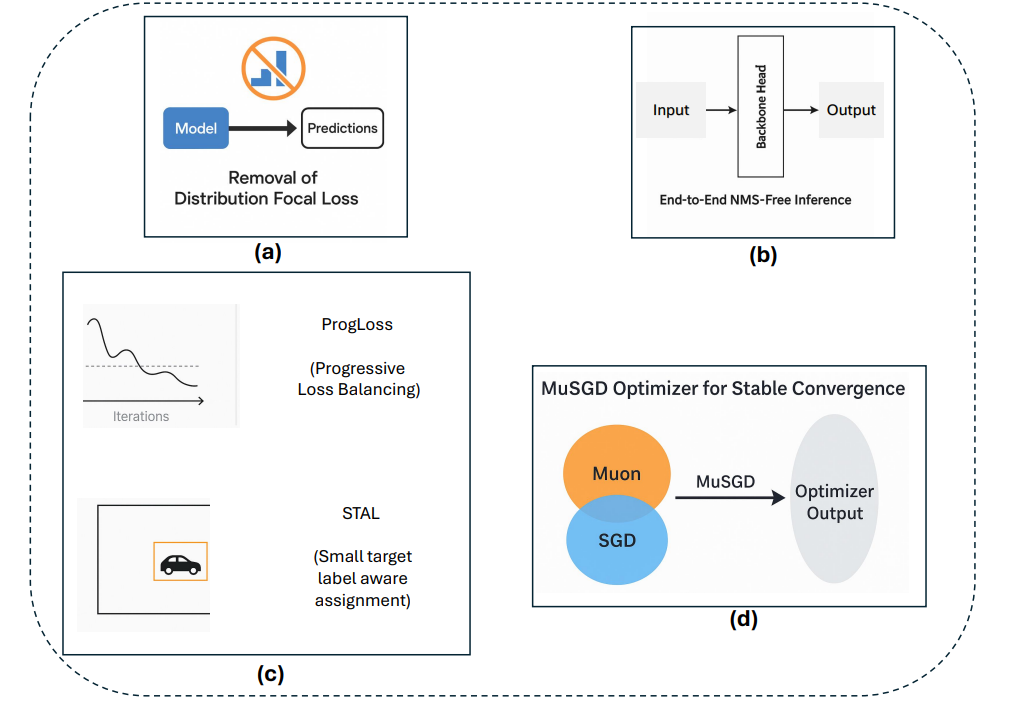
1.2.1 创新点1:移除分布焦点损失(DFL)
YOLO26最重要的架构简化之一是移除了分布焦点损失(DFL)模块(图3a),该模块曾存在于YOLOv8和YOLOv11等早期YOLO版本中。DFL最初旨在通过预测边界框坐标的概率分布来改进边界框回归,从而实现更精确的目标定位。虽然该策略在早期模型中展示了精度提升,但也带来了不小的计算开销和导出困难。在实践中,DFL在推理和模型导出期间需要专门处理,这使针对ONNX、CoreML、TensorRT或TFLite等硬件加速器的部署流程变得复杂。
源码位置:ultralytics/utils/loss.py
通过reg_max 设置为1,移除了分布焦点损失(DFL)
class BboxLoss(nn.Module):
"""Criterion class for computing training losses for bounding boxes."""
def __init__(self, reg_max: int = 16):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.dfl_loss = DFLoss(reg_max) if reg_max > 1 else None
1.2.2 创新点2:端到端无NMS推理
YOLO26从根本上重新设计了预测头,以直接产生非冗余的边界框预测,无需NMS。这种端到端设计不仅降低了推理复杂度,还消除了对手动调优阈值的依赖,从而简化了集成到生产系统的过程。对比基准测试表明,YOLO26实现了比YOLOv11和YOLOv12更快的推理速度,其中nano模型在CPU上的推理时间减少了高达43%。这使得YOLO26对于移动设备、无人机和嵌入式机器人平台特别有利,在这些平台上,毫秒级的延迟可能产生重大的操作影响。
源码位置:ultralytics/utils/nms.py
def non_max_suppression(
prediction,
conf_thres: float = 0.25,
iou_thres: float = 0.45,
classes=None,
agnostic: bool = False,
multi_label: bool = False,
labels=(),
max_det: int = 300,
nc: int = 0, # number of classes (optional)
max_time_img: float = 0.05,
max_nms: int = 30000,
max_wh: int = 7680,
rotated: bool = False,
end2end: bool = False,
return_idxs: bool = False,
):
"""Perform non-maximum suppression (NMS) on prediction results.
Applies NMS to filter overlapping bounding boxes based on confidence and IoU thresholds. Supports multiple detection
formats including standard boxes, rotated boxes, and masks.
Args:
prediction (torch.Tensor): Predictions with shape (batch_size, num_classes + 4 + num_masks, num_boxes)
containing boxes, classes, and optional masks.
conf_thres (float): Confidence threshold for filtering detections. Valid values are between 0.0 and 1.0.
iou_thres (float): IoU threshold for NMS filtering. Valid values are between 0.0 and 1.0.
classes (list[int], optional): List of class indices to consider. If None, all classes are considered.
agnostic (bool): Whether to perform class-agnostic NMS.
multi_label (bool): Whether each box can have multiple labels.
labels (list[list[Union[int, float, torch.Tensor]]]): A priori labels for each image.
max_det (int): Maximum number of detections to keep per image.
nc (int): Number of classes. Indices after this are considered masks.
max_time_img (float): Maximum time in seconds for processing one image.
max_nms (int): Maximum number of boxes for NMS.
max_wh (int): Maximum box width and height in pixels.
rotated (bool): Whether to handle Oriented Bounding Boxes (OBB).
end2end (bool): Whether the model is end-to-end and doesn't require NMS.
return_idxs (bool): Whether to return the indices of kept detections.
Returns:
output (list[torch.Tensor]): List of detections per image with shape (num_boxes, 6 + num_masks) containing (x1,
y1, x2, y2, confidence, class, mask1, mask2, ...).
keepi (list[torch.Tensor]): Indices of kept detections if return_idxs=True.
"""
1.2.3 创新点3:ProgLoss和STAL:增强训练稳定性和小目标检测
训练稳定性和小目标识别仍然是目标检测中持续存在的挑战。YOLO26通过整合两种新颖策略来解决这些问题:渐进损失平衡(ProgLoss)和小目标感知标签分配(STAL),如图(图3c)所示。
ProgLoss在训练期间动态调整不同损失分量的权重,确保模型不会过拟合于主导物体类别,同时防止在稀有或小类别上表现不佳。这种渐进式再平衡改善了泛化能力,并防止了训练后期的不稳定。另一方面,STAL明确优先为小目标分配标签,由于像素表示有限且易被遮挡,小目标尤其难以检测。ProgLoss和STAL共同为YOLO26在包含小目标或被遮挡目标的数据集(如COCO和无人机图像基准)上带来了显著的精度提升。
1.2.4 创新点4:用于稳定收敛的MuSGD优化器
YOLO26的最后一项创新是引入了MuSGD优化器(图3d),它结合了随机梯度下降(SGD)的优势与最近提出的Muon优化器(一种受大型语言模型训练中使用的优化策略启发而发展的技术)。MuSGD利用SGD的鲁棒性和泛化能力,同时融入了来自Muon的自适应特性,能够在不同数据集上实现更快的收敛和更稳定的优化。
源码位置:ultralytics/optim/muon.py
class MuSGD(optim.Optimizer):
"""Hybrid optimizer combining Muon and SGD updates for neural network training.
This optimizer implements a combination of Muon (a momentum-based optimizer with orthogonalization via Newton-Schulz
iterations) and standard SGD with momentum. It allows different parameter groups to use either the hybrid Muon+SGD
approach or pure SGD.
Args:
param_groups (list): List of parameter groups with their optimization settings.
muon (float, optional): Weight factor for Muon updates in hybrid mode. Default: 0.5.
sgd (float, optional): Weight factor for SGD updates in hybrid mode. Default: 0.5.
Attributes:
muon (float): Scaling factor applied to Muon learning rate.
sgd (float): Scaling factor applied to SGD learning rate in hybrid mode.
Examples:
>>> param_groups = [
... {
... "params": model.conv_params,
... "lr": 0.02,
... "use_muon": True,
... "momentum": 0.95,
... "nesterov": True,
... "weight_decay": 0.01,
... },
... {
... "params": model.other_params,
... "lr": 0.01,
... "use_muon": False,
... "momentum": 0.9,
... "nesterov": False,
... "weight_decay": 0,
... },
... ]
>>> optimizer = MuSGD(param_groups, muon=0.5, sgd=0.5)
>>> loss = model(data)
>>> loss.backward()
>>> optimizer.step()
Notes:
- Parameter groups with 'use_muon': True will receive both Muon and SGD updates.
- Parameter groups with 'use_muon': False will receive only SGD updates.
- The Muon update uses orthogonalization which works best for 2D+ parameter tensors.
"""
def __init__(
self,
params,
lr: float = 1e-3,
momentum: float = 0.0,
weight_decay: float = 0.0,
nesterov: bool = False,
use_muon: bool = False,
muon: float = 0.5,
sgd: float = 0.5,
):
"""Initialize MuSGD optimizer with hybrid Muon and SGD capabilities.
Args:
params: Iterable of parameters to optimize or dicts defining parameter groups.
lr (float): Learning rate.
momentum (float): Momentum factor for SGD.
weight_decay (float): Weight decay (L2 penalty).
nesterov (bool): Whether to use Nesterov momentum.
use_muon (bool): Whether to enable Muon updates.
muon (float): Scaling factor for Muon component.
sgd (float): Scaling factor for SGD component.
"""
defaults = dict(
lr=lr,
momentum=momentum,
weight_decay=weight_decay,
nesterov=nesterov,
use_muon=use_muon,
)
super().__init__(params, defaults)
self.muon = muon
self.sgd = sgd
@torch.no_grad()
def step(self, closure=None):
"""Perform a single optimization step.
Applies either hybrid Muon+SGD updates or pure SGD updates depending on the
'use_muon' flag in each parameter group. For Muon-enabled groups, parameters
receive both an orthogonalized Muon update and a standard SGD momentum update.
Args:
closure (Callable, optional): A closure that reevaluates the model
and returns the loss. Default: None.
Returns:
(torch.Tensor | None): The loss value if closure is provided, otherwise None.
Notes:
- Parameters with None gradients are assigned zero gradients for synchronization.
- Muon updates use Newton-Schulz orthogonalization and work best on 2D+ tensors.
- Weight decay is applied only to the SGD component in hybrid mode.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
# Muon
if group["use_muon"]:
# generate weight updates in distributed fashion
for p in group["params"]:
lr = group["lr"]
if p.grad is None:
continue
grad = p.grad
state = self.state[p]
if len(state) == 0:
state["momentum_buffer"] = torch.zeros_like(p)
state["momentum_buffer_SGD"] = torch.zeros_like(p)
update = muon_update(
grad, state["momentum_buffer"], beta=group["momentum"], nesterov=group["nesterov"]
)
p.add_(update.reshape(p.shape), alpha=-(lr * self.muon))
# SGD update
if group["weight_decay"] != 0:
grad = grad.add(p, alpha=group["weight_decay"])
state["momentum_buffer_SGD"].mul_(group["momentum"]).add_(grad)
sgd_update = (
grad.add(state["momentum_buffer_SGD"], alpha=group["momentum"])
if group["nesterov"]
else state["momentum_buffer_SGD"]
)
p.add_(sgd_update, alpha=-(lr * self.sgd))
else: # SGD
for p in group["params"]:
lr = group["lr"]
if p.grad is None:
continue
grad = p.grad
if group["weight_decay"] != 0:
grad = grad.add(p, alpha=group["weight_decay"])
state = self.state[p]
if len(state) == 0:
state["momentum_buffer"] = torch.zeros_like(p)
state["momentum_buffer"].mul_(group["momentum"]).add_(grad)
update = (
grad.add(state["momentum_buffer"], alpha=group["momentum"])
if group["nesterov"]
else state["momentum_buffer"]
)
p.add_(update, alpha=-lr)
return loss
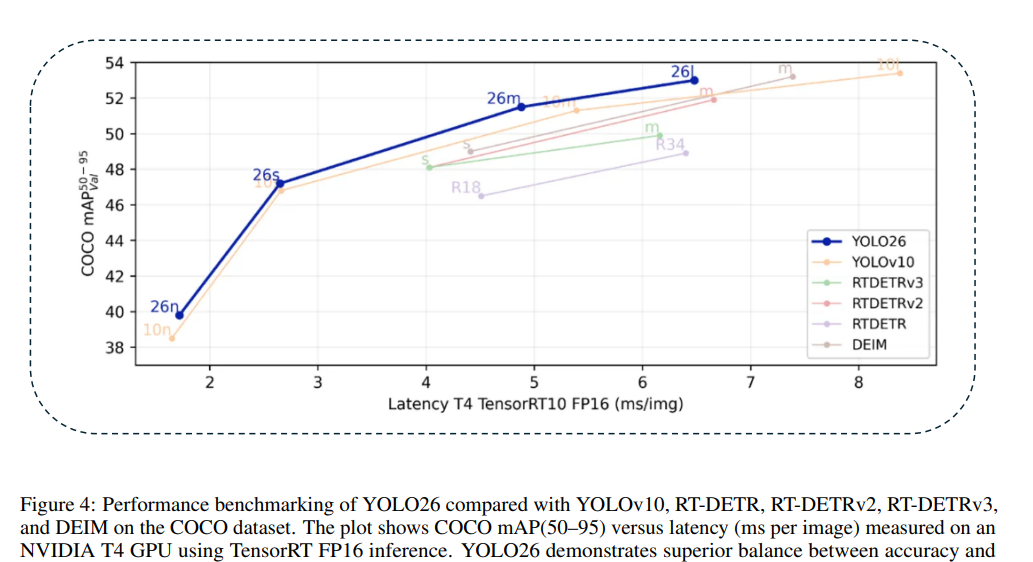
1.3 基准测试与对比分析
针对YOLO26,我们进行了一系列严格的基准测试,以评估其相对于YOLO前代模型和其他最先进架构的性能。图4展示了此评估的综合视图,在采用TensorRT FP16优化的NVIDIA T4 GPU上,绘制了COCO mAP(50–95)与每张图像延迟(毫秒)的关系。纳入YOLOv10、RT-DETR、RT-DETRv2、RT-DETRv3和DEIM等竞争架构,提供了近期实时检测进展的全面图景。从图中可见,YOLO26展示了一个独特的定位:它保持了与RT-DETRv3等基于Transformer模型相媲美的高精度水平,同时在推理速度方面显著优于它们。例如,YOLO26-m和YOLO26-l分别达到了高于51%和53%的竞争性mAP分数,但延迟大幅降低,这凸显了其无NMS架构和轻量化回归头带来的优势。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号