大模型之DeepSeek-OCR2快速入门实战教程


01、DeepSeekOCR与传统OCR区别
传统的 OCR 技术,虽然能够识别字符,却往往无法理解图像中的语义关系。它知道一串文字写着什么,却不理解它在页面中的意义——是标题、表格项、还是公式的一部分。这正是传统 OCR 的“瓶颈”所在。
随着人工智能的发展,之前OCR仅仅识别文字远远不够,机器还需要理解整个文档的结构与语义。 于是,新的 OCR 模型开始出现,代表模型包括微软的 LayoutLM、百度的 PaddleOCR 2.0,以及多模态结构化识别模型 Donut、DocFormer、TextMonkey 等。这些模型不仅能识别文字,还能输出 Markdown、HTML 或 JSON 结构,理解表格、公式、图形之间的关系。也就是说,此时OCR模型就由原先的“看字”升级成了“看文档全貌”。
DeepSeek-OCR2 就是一个革命性的文档理解系统,它不再像传统 OCR 工具那样机械地从左到右、从上到下扫描文档,而是像人类一样根据内容的语义逻辑来"阅读"。
DeepSeek OCR 将高分辨率文档压缩为精益视觉标记,然后用 3B 参数的Moe专家混合模型解码,实现跨 100+ 语言的近无损文本、布局和图表理解。
关注公众号【阳光宅猿】回复【AIGC】领取最新AI人工智能学习资料,包含RAG、Agent、深度学习、模型微调等多种最新技术文档等你来选!!
关注公众号【阳光宅猿】回复【加群】进入大模型技术交流群一起学习成长!!!
02、DeepSeekOCR识别原理简述
DeepSeek OCR 是一款两阶段的基于Transformer的文档人工智能,将页面图像压缩成紧凑的视觉标记,然后用高容量的专家混合语言模型解码。
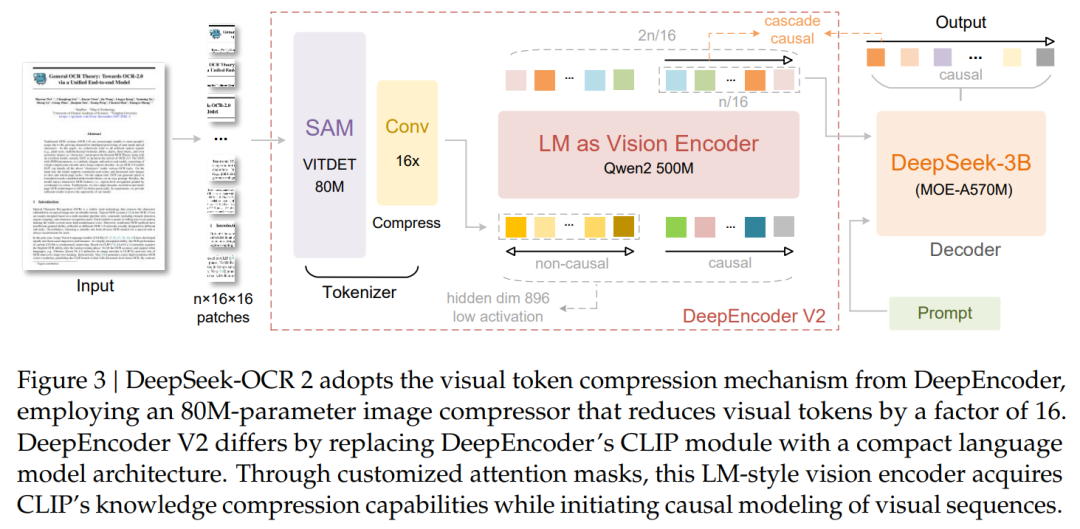
DeepSeek团队发布《DeepSeek-OCR 2: Visual Causal Flow》论文,并开源DeepSeek-OCR 2模型,采用创新的DeepEncoder V2方法,让AI能够根据图像的含义动态重排图像的各个部分,更接近人类的视觉编码逻辑。

- 项目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
- 论文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
- 模型地址:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
DeepSeek OCR 基于 3000 万真实 PDF 页面及合成图表、公式和图表训练,保留布局结构、表格、化学(SMILES 字符串)和几何任务。其 CLIP 的传统保持了多模态能力——采用上下文光学压缩引擎即使经过激烈压缩,字幕和对象的结构基础依然完整。
具体来说,该研究的核心创新在于将原本基于 CLIP 的编码器替换为轻量级语言模型(Qwen2-500M),并引入了具有因果注意力机制的「因果流查询」。
这种设计打破了传统模型必须按从左到右、从上到下的栅格顺序处理图像的限制,赋予了编码器根据图像语义动态重排视觉 Token 的能力。通过这种两级级联的 1D 因果推理结构(编码器重排与译码器解析),模型能够更精准地还原复杂文档(如带表格、公式和多栏布局)的自然阅读逻辑。
这就像是为机器装上了「人类的阅读逻辑」,让 AI 不再只是生搬硬套地扫描图像。对比之下,传统的 AI 就像一个死板的复印机,不管页面内容多复杂,都只能从左上角到右下角按行扫描。
在维持极高数据压缩效率的同时,DeepSeek-OCR 2 在多项基准测试和生产指标上均取得了显著突破。模型仅需 256 到 1120 个视觉 Token 即可覆盖复杂的文档页面,这在同类模型中处于极低水平,显著降低了下游 LLM 的计算开销。
继承自 V1 的优良基因,也是 DeepSeek 能够实现超快推理的基础。
物理机制:通过卷积 Tokenizer 将原始图像的视觉 Token 数量直接物理压缩 16 倍。
硬核数据:一张1024X1024 的高分图像,最终仅需 256 个 Token 即可表达。
用户价值:对于开发者来说,这意味着极低的显存占用和极高的吞吐量。
在 OmniDocBench v1.5 评测中,其综合得分达到 91.09%,较前代提升了 3.73%,特别是在阅读顺序识别方面表现出了更强的逻辑性。
03、主流VLM与OCR模型
目前VLM模型有很多,除了主流的多模态在线大模型外,还有如Qwen-VL、InternVL、Gemma等 开源的视觉模型。
在多模态 RAG 技术体系中,在线 VLM 模型是目前能力最全面的语义理解引擎。这类模型往往由顶尖大厂训练并托管在云端,参数规模达到数百亿甚至上千亿,具备强大的多模态感知与推理能力。典型代表包括 OpenAI 的 GPT-5(原生支持文本、图像、音频等模态,提供完善的 API 与生态)、Google 的 Gemini 2.5(强调长上下文、多语言和与搜索/Workspace 的无缝集成)、以及 Anthropic 的 Claude 4.5(在多步推理与代理式任务中表现突出,并已在多云环境提供企业级接入)。
这类在线模型 的优势在于即开即用、功能齐全、语义理解能力极强,但与此同时也存在调用成本高、隐私合规受限的现实问题。因此,在线VLM更适合作为复杂问题的“上层大脑”,在需要深度语义理解、跨模态推理和企 业级可靠性的场景下发挥核心价值。
OCR模型是RAG系统的“第一道神经通路”。它承担着从视觉信息中提取语 义结构的关键任务,是整个RAG链路的起点。如果说LLM是“大脑”,那么OCR模型就是“视觉皮层”——它决定了大脑能看到什么,能理解到什么程度?
DeepSeek OCR模型已经能够实现:
1、语义级解析:不仅识别文字,还能理解其上下文逻辑(如表头对应数据、公式与变量的关联);
2、结构级还原:能够自动将PDF文档转化为结构化的Markdown或HTML格式,保留段落层次、标 题、列表等格式信息;
3、视觉语义融合:能看懂图像与文字的关系,比如“图1展示了实验流程”、“左图为原始图像、右图为 结果对比”;
4、内容理解能力:不仅能提取表格数据,还能识别图表趋势、理解图像含义、甚至生成解释性描述。
DeepSeek-OCR 不仅继承了传统OCR的文本识别能力,更在“文档理解”层面进行了全方位升级。它是目前开源社区中少数具备端到端文档解析、语义理解与结构化生成能力的轻 量级多模态模型,参数量仅约 3.6B。
04、DeepSeek-OCR本地部署与环境搭建
可从Hugging Face或魔搭社区(ModelScope)获取。以 ModelScope 为例:
pip install modelscope
mkdir ./deepseek-ocr
modelscope download --model deepseek-ai/DeepSeek-OCR-2 --local_dir ./deepseek
ocr-2运行环境
基础运行环境建议:
OS:Ubuntu 20.04+/22.04
Python:3.10–3.12(推荐 3.10/3.11)(一定不要是3.13.9 不然vllm装不上)
CUDA:11.8 或 12.1/12.2(与显卡驱动匹配即可)
PyTorch:与 CUDA 匹配的预编译版本
GPU:≥7 GB(大图/多页 PDF 建议 16–24 GB)检查NVIDIA驱动:
nvidia-smi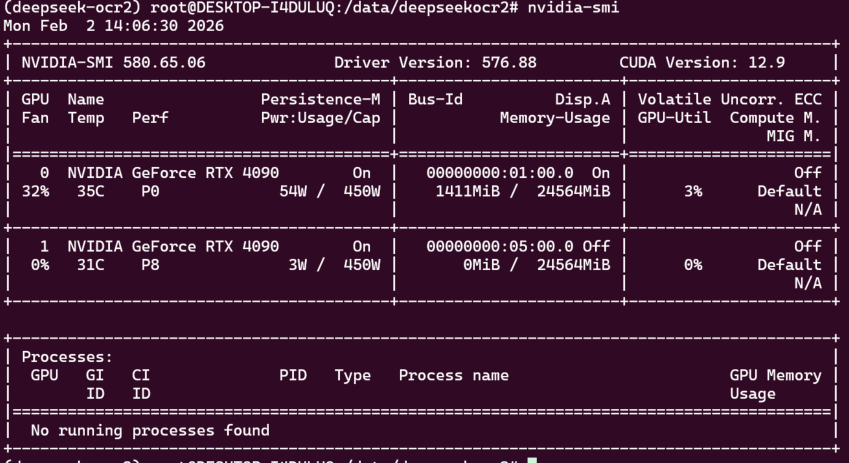
查看本地CUDA版本
nvcc --version
根据本地版本选择PyTorch安装命令
image.png
克隆代码仓库:
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git
cd DeepSeek-OCR-2创建 Conda 环境:
conda create -n deepseek-ocr2 python=3.12.9 -y
conda activate deepseek-ocr2安装依赖:
# 安装 PyTorch
pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu118
# 安装 vLLM(需要下载对应的 cu118 版本)
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
# 安装其他依赖
pip install -r requirements.txt
# 安装 Flash Attention 加速(不装可能会报错)
pip install flash-attn==2.7.3 --no-build-isolation需要完整模型和VLLM文件的可以后台私我获取。
04、DeepSeek-OCR调用
采用transformers库进行推理,不重点介绍,把代码直接放出来:
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name,
_attn_implementation='flash_attention_2', trust_remote_code=True,
use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
prompt = "<image>\n请详细描述图片内容"
image_file = '/root/autodl-tmp/image_input/测试图片.png'
output_path = '/root/autodl-tmp/image_output'
res=model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path =output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results =True, test_compress = True)DeepSeek-OCR模型的VLLM调用流程
除了使用 transformers 库进行直接推理外,DeepSeek-OCR 模型还支持基于 vLLM 的高性能调用流程。
vLLM 是目前主流的高吞吐推理引擎之一,能够显著提升多模态大模型的推理速度与显存利用率,尤其在处理长文档或多页 PDF 时优势明显。
通过 vLLM 调用,DeepSeek-OCR 可以在流式 (streaming)模式下快速生成 Markdown、图文描述或结构化输出,实现低延迟、高并发的推理体验。
官方项目中提供了部分可以直接用于进行vLLM任务推理的脚本如下:
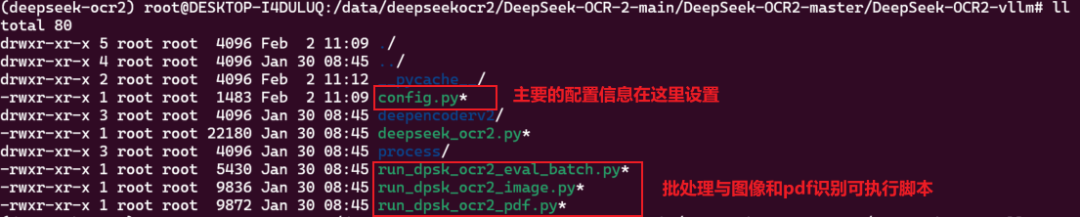
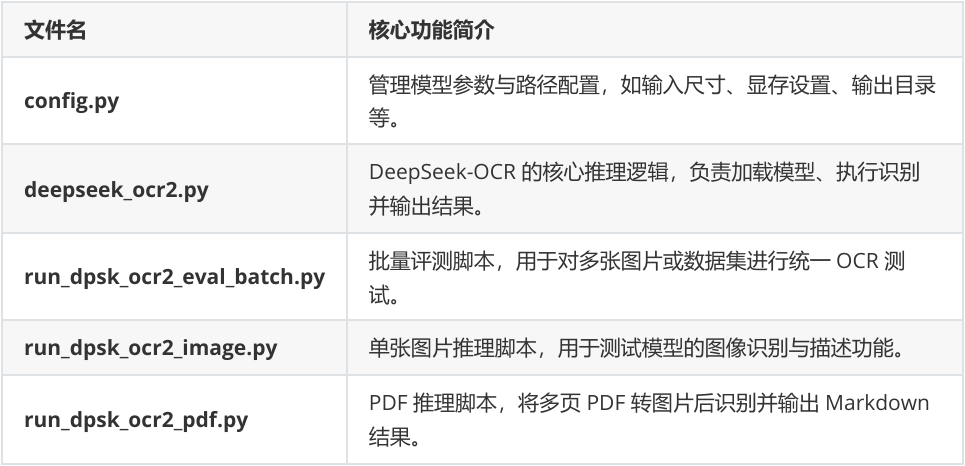
我们首先将需要识别的图片和需要模型输出的内容在配置文件config.py中设置,在config.py中设置模型路径、输入输出目录及提示词(如 \n<|grounding|>Describe this image in detail.)。同时可根据显卡显存调整 BASE_SIZE 与 IMAGE_SIZE 参数,以保证推理顺利运行。内容如下:
这里注意提示词不要随意修改,就保持默认,不然识别不出来,亲测!
执行
python run_dpsk_ocr2_pdf.py04、提示词与效果展示
1. 通用文档识别模板
对于常规文档的OCR识别,使用以下模板:
PROMPT = '<image>\n<|grounding|>Convert the document to markdown.'这个模板能够将文档内容转换为结构化的Markdown格式,保留标题、段落、列表等排版信息。在实际应用中,该模板能够准确识别数学练习册、新闻简报等复杂文档结构。
2. 自由OCR识别模板
当您只需要简单的文本提取时,可以使用:
<image>\nFree OCR.3. 图表解析模板
针对文档中的图表和图像内容:
<image>\nParse the figure.4. 详细图像描述模板
需要获取图像的全面描述时:
<image>\nDescribe this image in detail.5. 目标定位与识别模板
在图像中定位特定元素:
<image>\nLocate <|ref|>xxxx<|/ref|> in the image.6. 表格提取模板
专门针对表格内容的识别:
<image>\nExtract the table data in markdown format.7. 数学公式识别模板
处理数学文档和公式:
<image>\nRecognize mathematical formulas in the document.8. 多语言混合识别模板
处理包含多种语言的文档:
<image>\nOCR with multilingual support.9. 结构化输出模板
要求特定格式的输出:
<image>\n<|grounding|>Convert to structured JSON.10.批量处理模板
适用于批量OCR任务:
<image>\nProcess all text with layout preservation.11.自定义精度模板
根据需求调整识别精度:
<image>\nHigh-precision OCR for legal documents.DeepSeek-OCR实际应用效果

OCR文档识别效果
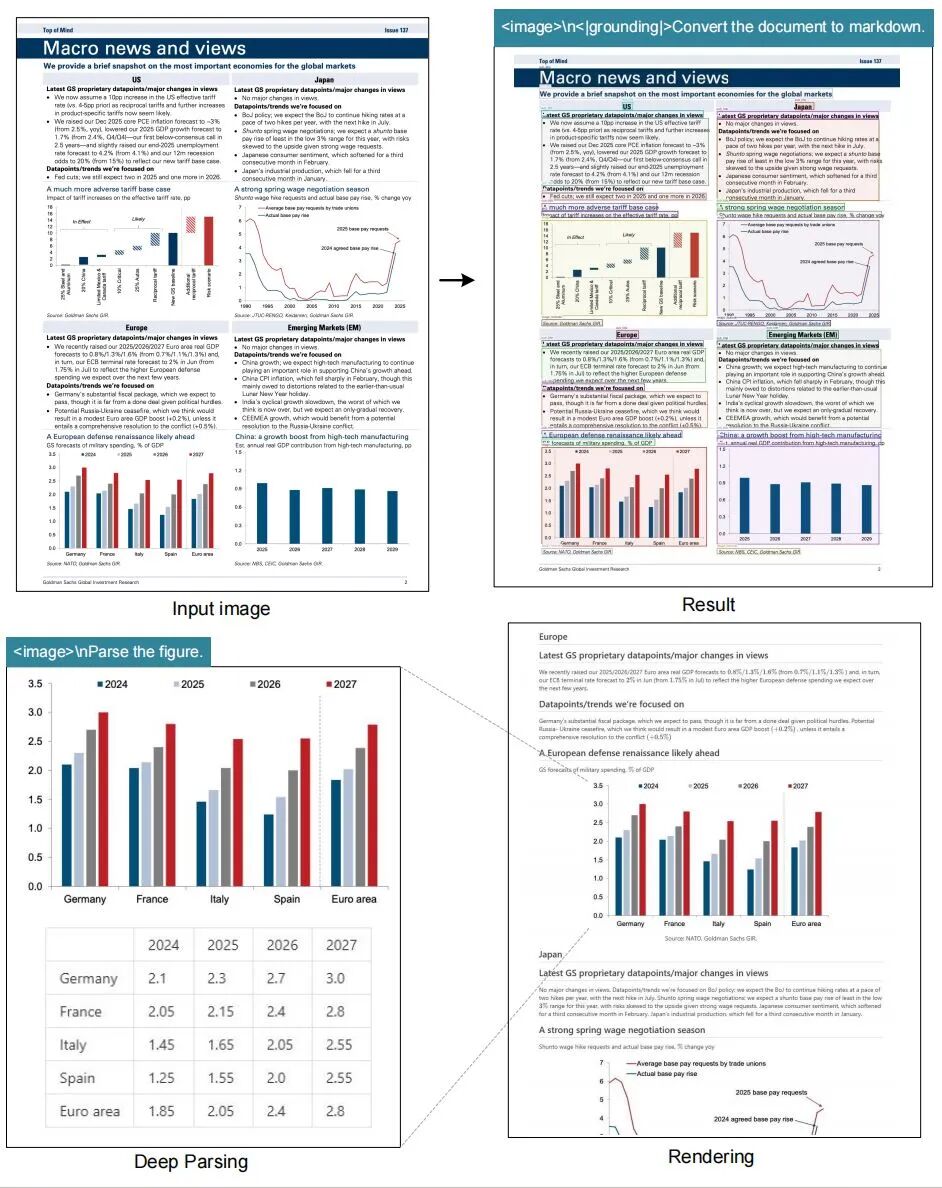
图表解析示例

多任务处理能力

复杂场景处理
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号