建议收藏:从硬件到安全,最全的 Linux 服务器巡检指南

建议收藏:从硬件到安全,最全的 Linux 服务器巡检指南

释然IT杂谈
发布于 2026-03-25 13:16:31
发布于 2026-03-25 13:16:31

前言
运维圈有句老话,服务器不是坏了才需要关注,而是要在它"想坏"之前就发现问题。
道理谁都懂。但真正落地执行的团队,说实话,真的不多。
我见过太多券商IT部门的运维状态是这样的:监控大屏常年绿色,日志没人看,巡检表是季度末应付合规审查才填的。然后某一天,砰——出事了,所有人开始追责,证监会的监管函也跟着来了。
今天这篇,我想从一个真实事故讲起,把服务器定期巡检这件事从头梳理一遍。不是为了写个标准文档,而是真的希望有人能从中避开同样的坑。
一、一个让人看了心里发凉的案例
事故背景
先说说场景。券商的IT系统有个特殊性——它不是普通的业务系统,而是直接跟客户的钱挂钩。交易委托、订单撮合、持仓结算,每一个环节出问题,后果都不是"用户体验差"那么简单,是真实的资金损失,是监管处罚,严重的是吊销业务资质。
所以券商的运维压力,跟电商、普通互联网公司不在一个量级上。
事故还原
2024年6月,某中型券商(营业部覆盖华东地区,管理资产规模约800亿),在A股半年结算日遭遇了一次系统性崩溃。
这家券商的核心交易系统跑在自建机房,服务器约80台,但运维团队只有5个人,长期处于救火状态。巡检这件事,嗯……怎么说,制度是有的,执行嘛,基本靠自觉,实际上没人认真做。
那天出事的时间节点,卡得非常不巧:
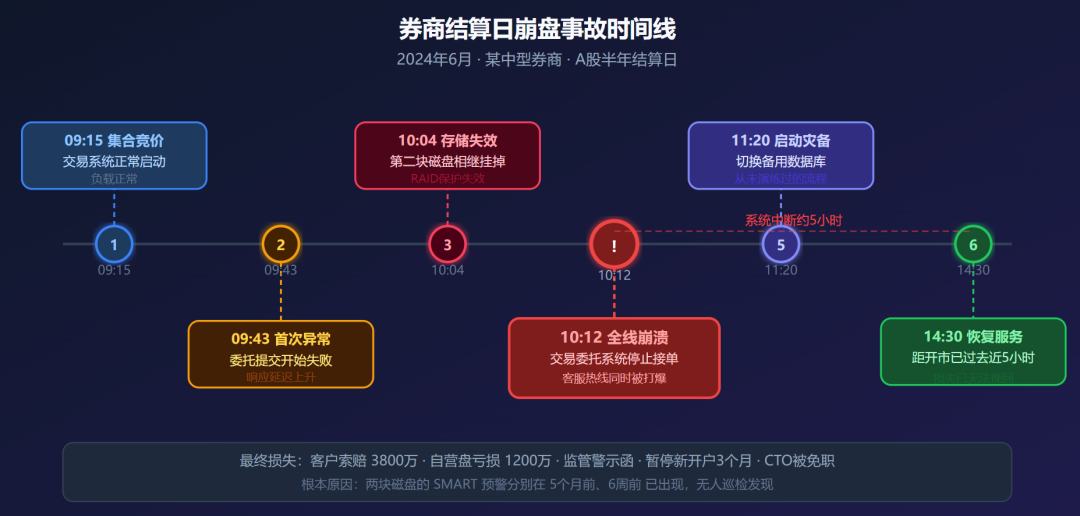
近5小时。覆盖了整个上午交易时段加午盘开市。
损失有多惨?直接算得出来的:客户因系统故障无法交易导致的索赔金额超过3800万元,券商自营盘因无法及时对冲损失约1200万元。间接的更麻烦——证监会出具监管警示函,责令整改,暂停新开户业务3个月,消息一出,公司股价当天跌了4.7%。
CTO被免职,运维负责人降级处分,整个IT部门被要求在30天内完成全面整改并向监管报告。
事后调查,才是最让人难受的部分
调查结论出来,所有人都沉默了:
- 第1块磁盘:5个月前已出现SMART预警,
Reallocated_Sector_Ct数值持续攀升,系统日志里有明确记录 - 第2块磁盘:6周前已出现坏道累积告警,
Current_Pending_Sector指标超出安全阈值
两块盘,一前一后,悄悄坏着。谁都没看。
RAID阵列最多只能容忍规定数量的磁盘失效。两块同时挂掉,数据库直接崩。
也就是说,这家券商有两次机会可以在事故发生前把问题消灭掉。第一次是5个月前,第二次是6周前。两次,全错过了。

如果每周做一次巡检,哪怕就是最基础的SMART检查,5个月前发现第一块盘的异常,换掉,那个半年结算日什么事都不会发生。3800万的赔偿不会有,监管函不会有,CTO也不用走人。
我常跟人讲一个账:每周投入2小时做巡检,换来的是对千万级损失的主动防御。对券商来说,这不是可选项,这是《证券公司信息系统安全运营管理指引》里白纸黑字写着的合规要求,也是保住业务资质的基本生命线。
二、服务器巡检要看哪些东西
坦白讲,巡检这件事看起来复杂,其实拆开来就是五个维度:硬件、系统、RAID、应用、安全。下面一个一个说。
2.1 硬件巡检
硬盘健康检查——这是最最重要的一项
硬盘是服务器里最容易静默失效的部件,它坏起来不会给你发通知,就那么悄悄坏着,等你发现可能已经迟了。
券商的行情数据库、交易委托数据库、结算数据库,全压在这些盘上。盘一坏,轻则交易中断,重则数据不一致,账务对不上——后一种情况更麻烦,因为涉及客户资产,监管介入是必然的。
SMART技术就是专门为了提前发现这类问题设计的,把它用起来:
smartctl -a /dev/sda
输出的内容很多,但你重点盯这几个指标就够了:
SMART编号 | 指标名称 | 含义 |
|---|---|---|
5 | Reallocated_Sector_Ct | 重新分配的扇区数 |
187 | Reported_Uncorrect | 无法修正的错误数 |
188 | Command_Timeout | 命令超时次数 |
197 | Current_Pending_Sector | 等待重新映射的扇区 |
198 | Offline_Uncorrectable | 离线无法修正的扇区 |
194 | Temperature_Celsius | 硬盘温度 |
说实话,这张表第一次看可能会懵,但你只要记住一个原则:197和198,只要不是0,就应该认真对待,大于5就该换盘了。别觉得"还能跑就先跑着",那家券商的运维大概也是这么想的。
告警阈值参考:
指标 | 正常 | 预警 | 严重 | 处理建议 |
|---|---|---|---|---|
重新分配扇区 | 0 | 1-100 | >100 | 严重时立即更换 |
无法修正错误 | 0 | 1-10 | >10 | 立即更换 |
命令超时 | 0 | 1-5 | >5 | 立即更换 |
待重映射扇区 | 0 | >0 | >5 | 出现就应更换 |
硬盘温度 | <45℃ | 45-55℃ | >55℃ | 检查散热 |
内存——这个很多人忽略
内存出问题的概率比硬盘低,但一旦出现,影响往往很诡异——系统莫名崩溃、数据计算出错。
对券商系统来说,"计算出错"四个字格外敏感。行情数据计算偏差、持仓盈亏数字不对、保证金计算错误……任何一个都可能引发客户投诉乃至法律纠纷。
# 查内存错误日志
dmesg | grep -i "memory\|ecc"
cat /var/log/messages | grep -i "memory error"
# Dell服务器
racadm hwinventory
# HP服务器
hpasmcli -s "show dimm"
判断原则:可纠正错误(CE)每天低于10次正常,超过100次需要换;不可纠正错误(UCE)出现一次,立刻换,别犹豫。
CPU温度与风扇、电源
这几项放在一起说,逻辑类似——都是"状态监控型"检查,平时没有大的异动基本没问题,但出现异常信号就要当天处理,不能拖。
# CPU温度
sensors
# 风扇转速
ipmitool sensor list | grep -i fan
# 电源状态
ipmitool sensor list | grep -i power
尤其是双电源环境,一路电源坏了另一路还在跑,很多运维就觉得"没事还能用"。但冗余已经失效,任何波动都可能直接宕机。券商交易时段的宕机,每一分钟都是真实的损失。
2.2 系统巡检
磁盘空间——最容易被忽视的日常炸弹
df -h
# 找大文件
du -sh /* | sort -rh | head -10
# 找超过100MB的日志文件
find /var/log -type f -size +100M
告警阈值:
分区 | 正常 | 预警 | 严重 |
|---|---|---|---|
根分区(/) | <70% | 70-85% | >85% |
/var | <80% | 80-90% | >90% |
/tmp | <80% | 80-90% | >90% |
数据分区 | <80% | 80-90% | >90% |
空间满了导致服务崩溃这种事说出来都是笑话,但在券商系统里真实发生过——交易流水日志把分区写满,新的委托记录写不进去,整个委托链路断掉。结算的时候发现当日部分交易记录缺失,那个对账噩梦不是一两句话能说清楚的。
需要注意:券商有交易数据留存的合规要求,清理日志前务必确认保留策略,监管要求留存的数据绝对不能删。
# 清理30天前的非核心日志
find /var/log -name "*.log.*" -mtime +30 -delete
# 清理包缓存
yum clean all # CentOS/RHEL
apt-get clean # Ubuntu/Debian
内存使用率、系统负载、网络连接
# 内存
free -h
ps aux --sort=-rss | head -11
# 负载
uptime
iostat -x 1
# 网络连接数
netstat -an | wc -l
netstat -an | grep TIME_WAIT | wc -l
负载阈值以8核CPU为例:
负载类型 | 正常 | 预警 | 严重 |
|---|---|---|---|
1分钟 Load | <8 | 8-12 | >12 |
5分钟 Load | <8 | 8-12 | >12 |
IO等待(wa) | <10% | 10-30% | >30% |
Swap使用率超过50%是个高危信号——性能下降会非常明显,不是"有点慢",是那种让人抓狂的慢。行情高波动时段,服务器本来负载就高,Swap异常再叠上去,委托延迟会直接被客户感知到,投诉随之而来。
系统日志——要养成每周看一遍的习惯
tail -100 /var/log/messages | grep -i error
dmesg | grep -i "error\|fail"
tail -100 /var/log/secure | grep -i fail
journalctl -p err -b
重点盯error、fail、critical。券商系统还要额外关注SSH登录失败记录——金融系统是网络攻击的重点目标,失败次数短时间内暴增,要立刻当安全事件对待。
2.3 RAID阵列巡检
这一块我想多说几句,因为前面那个券商事故的根源就在这里,而且这个坑很多人踩了还不知道。
不同RAID卡命令不一样:
# Dell PERC
/opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -aALL
# HP SmartArray
hpacucli ctrl all show config
# 软RAID(mdadm)
cat /proc/mdstat
mdadm --detail /dev/md0
状态解读:
状态 | 含义 | 处理建议 |
|---|---|---|
Optimal | 正常 | 无需操作 |
Degraded | 降级,有盘失效 | 尽快换盘,不是"找时间换" |
Failed | 阵列失效 | 紧急恢复 |
Rebuilding | 重建中 | 等完成,绝对不能关机 |
我见过有人RAID降级了觉得"还能跑",就拖着。在券商系统上,这种侥幸心理的代价是几千万的赔偿和监管处罚——前面那个案例已经说得很清楚了。换盘这件事没有"找时间",只有"今天"。
2.4 应用服务巡检
核心服务状态
券商系统的应用层比普通业务系统复杂,除了基础服务状态,还要关注交易链路上每个节点的健康状态。
systemctl status nginx
systemctl status mysql
systemctl status redis
# 端口监听
netstat -tlnp | grep :80
ss -tlnp | grep :3306
# 服务错误日志
tail -100 /var/log/nginx/error.log
tail -100 /var/log/mysql/error.log
数据库
MySQL这边主要看连接数、慢查询和死锁。死锁问题在券商系统里要格外重视——高并发交易场景下,多个委托同时操作同一账户持仓时容易产生死锁,直接导致委托失败:
mysql -e "show processlist;" | wc -l
mysql -e "show global status like 'Slow_queries';"
mysql -e "show engine innodb status\G" | grep -A 20 "LATEST DETECTED DEADLOCK"
# 主从复制(行情库、委托库均需检查)
mysql -e "show slave status\G" | grep -i "running"
主从复制延迟在这里是个严肃的风险点——延迟过大意味着灾备数据不同步。一旦主库崩溃切灾备,这段延迟时间内的委托记录可能丢失,账务对不上,后果比单纯的系统中断还要棘手。
Redis主要看内存和持久化:
redis-cli info memory | grep used_memory_human
redis-cli info clients | grep connected_clients
redis-cli info persistence | grep rdb_last_save_time
交易接口健康检查
# 核心接口响应时间(超过200ms需关注)
curl -o /dev/null -s -w "Time: %{time_total}s\n" https://your-trading-api.com/health
# 5xx错误统计(券商系统零容忍)
tail -10000 /var/log/nginx/access.log | awk '{print $9}' | grep "^5" | wc -l
# 慢请求统计(>1秒即需关注,交易系统对延迟极敏感)
tail -10000 /var/log/nginx/access.log | awk '{if($NF>1)print $0}' | wc -l
2.5 安全巡检
安全这块在券商绝对不能跳过。有些中小券商的运维会觉得"我们规模不大,黑产盯不上我们"——这个判断完全错误。券商系统直连客户资金账户,是网络攻击的高价值目标,规模越小防御越薄弱,反而更容易成为突破口。
登录审计是基本动作:
last | head -20
lastb | head -20
grep "Failed password" /var/log/secure | tail -20
w
who
要高度关注的信号:非交易时段的登录(尤其是凌晨)、境外IP、短时间大量登录失败。对券商系统来说,这三个信号任何一个单独出现都值得立刻调查,不能等到下次巡检再说。
账户和进程检查:
cat /etc/passwd
find /home -type d -mtime -7
cat /etc/sudoers
# 排查挖矿程序(券商服务器算力资源是挖矿黑产的目标)
ps aux | grep -E "xmrig|cryptonight|minerd"
# 排查可疑外联(防止数据外传)
netstat -antp | grep ESTABLISHED | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -rn | head -10
文件完整性检查:
stat /etc/passwd /etc/shadow /etc/sudoers
find /etc -type f -mtime -1
# Web应用Webshell检测(网上交易系统必查)
find /var/www -name "*.php" -type f | xargs grep -l "eval(" | head -20三、自动化脚本——把重复的事情交给机器做
手动巡检不是不行,但人会疲惫、会遗漏,把能自动化的部分脚本化是正确方向。下面这个脚本可以直接用:
#!/bin/bash
# 服务器健康巡检脚本 v2.0
# 适用场景:券商生产环境
HOSTNAME=$(hostname)
DATE=$(date +"%Y-%m-%d %H:%M:%S")
REPORT_FILE="/tmp/server_check_$(date +%Y%m%d).txt"
ALERT_THRESHOLD_CPU=80
ALERT_THRESHOLD_MEM=85
ALERT_THRESHOLD_DISK=85
cat > $REPORT_FILE << EOF
======================================
服务器健康巡检报告
服务器: $HOSTNAME
时间: $DATE
======================================
EOF
# 1. 系统基本信息
echo"【1. 系统基本信息】" >> $REPORT_FILE
echo"操作系统: $(cat /etc/redhat-release 2>/dev/null || head -1 /etc/lsb-release 2>/dev/null)" >> $REPORT_FILE
echo"内核版本: $(uname -r)" >> $REPORT_FILE
echo"运行时间: $(uptime | awk -F'up ' '{print $2}' | awk -F',' '{print $1}')" >> $REPORT_FILE
echo"" >> $REPORT_FILE
# 2. CPU检查
echo"【2. CPU使用情况】" >> $REPORT_FILE
CPU_USAGE=$(top -bn1 | grep "Cpu(s)" | sed "s/.*, *\([0-9.]*\)%* id.*/\1/" | awk '{print 100 - $1}')
echo"CPU使用率: ${CPU_USAGE}%" >> $REPORT_FILE
if [ $(echo"$CPU_USAGE > $ALERT_THRESHOLD_CPU" | bc) -eq 1 ]; then
echo"⚠️ 警告:CPU使用率超过 ${ALERT_THRESHOLD_CPU}%" >> $REPORT_FILE
fi
top -bn1 | head -15 >> $REPORT_FILE
echo"" >> $REPORT_FILE
# 3. 内存检查
echo"【3. 内存使用情况】" >> $REPORT_FILE
free -h >> $REPORT_FILE
MEM_USAGE=$(free | grep Mem | awk '{print int($3/$2 * 100)}')
echo"内存使用率: ${MEM_USAGE}%" >> $REPORT_FILE
if [ $MEM_USAGE -gt $ALERT_THRESHOLD_MEM ]; then
echo"⚠️ 警告:内存使用率超过 ${ALERT_THRESHOLD_MEM}%" >> $REPORT_FILE
fi
echo"" >> $REPORT_FILE
# 4. 磁盘检查
echo"【4. 磁盘使用情况】" >> $REPORT_FILE
df -h >> $REPORT_FILE
df -h | awk '{print $5}' | grep -v "Use%" | sed 's/%//g' | whileread usage; do
if [ "$usage" -gt "$ALERT_THRESHOLD_DISK" ] 2>/dev/null; then
echo"⚠️ 警告:存在分区使用率超过 ${ALERT_THRESHOLD_DISK}%" >> $REPORT_FILE
fi
done
echo"" >> $REPORT_FILE
# 5. 系统负载
echo"【5. 系统负载】" >> $REPORT_FILE
uptime >> $REPORT_FILE
CPU_CORES=$(nproc)
LOAD_5MIN=$(uptime | awk -F'load average:''{print $2}' | awk -F',''{print $2}' | xargs)
echo"CPU核心数: $CPU_CORES | 5分钟平均负载: $LOAD_5MIN" >> $REPORT_FILE
echo"" >> $REPORT_FILE
# 6. 硬盘SMART检查
echo"【6. 硬盘健康状态】" >> $REPORT_FILE
ifcommand -v smartctl &> /dev/null; then
for disk in $(lsblk -d -n -o name | grep -E "^sd|^nvme"); do
echo"--- /dev/$disk ---" >> $REPORT_FILE
smartctl -H /dev/$disk >> $REPORT_FILE 2>&1
smartctl -A /dev/$disk | grep -E "Reallocated_Sector|Reported_Uncorrect|Current_Pending|Temperature" >> $REPORT_FILE 2>&1
echo"" >> $REPORT_FILE
done
else
echo"smartctl 未安装,建议执行:yum install smartmontools" >> $REPORT_FILE
fi
echo"" >> $REPORT_FILE
# 7. 网络连接
echo"【7. 网络连接】" >> $REPORT_FILE
echo"总连接数: $(netstat -an | wc -l)" >> $REPORT_FILE
echo"ESTABLISHED连接: $(netstat -an | grep ESTABLISHED | wc -l)" >> $REPORT_FILE
echo"TIME_WAIT连接: $(netstat -an | grep TIME_WAIT | wc -l)" >> $REPORT_FILE
echo"" >> $REPORT_FILE
# 8. 核心服务状态
echo"【8. 核心服务状态】" >> $REPORT_FILE
SERVICES=("nginx""httpd""mysql""mysqld""redis""docker")
for service in"${SERVICES[@]}"; do
if systemctl list-units --full --all | grep -Fq "$service.service"; then
STATUS=$(systemctl is-active $service)
if [ "$STATUS" == "active" ]; then
echo"✓ $service: 运行中" >> $REPORT_FILE
else
echo"✗ $service: 已停止 ⚠️" >> $REPORT_FILE
fi
fi
done
echo"" >> $REPORT_FILE
# 9. 登录记录
echo"【9. 最近登录记录(10条)】" >> $REPORT_FILE
last | head -10 >> $REPORT_FILE
echo"" >> $REPORT_FILE
echo"【10. 失败登录记录(10条)】" >> $REPORT_FILE
lastb 2>/dev/null | head -10 >> $REPORT_FILE || echo"无失败登录记录" >> $REPORT_FILE
echo"" >> $REPORT_FILE
# 10. 系统错误日志
echo"【11. 系统错误日志(20条)】" >> $REPORT_FILE
tail -20 /var/log/messages 2>/dev/null | grep -i error >> $REPORT_FILE || echo"无错误日志" >> $REPORT_FILE
echo"" >> $REPORT_FILE
echo"======================================" >> $REPORT_FILE
echo"巡检完成: $(date)" >> $REPORT_FILE
echo"报告位置: $REPORT_FILE" >> $REPORT_FILE
echo"======================================" >> $REPORT_FILE
cat $REPORT_FILE
# 按需启用:发送至运维负责人与合规部门
# mail -s "[$HOSTNAME] 服务器巡检报告" ops@your-broker.com < $REPORT_FILE
定时任务配置,券商有个特殊考虑——巡检要在开市前完成,发现问题才有处置时间:
crontab -e
# 每天早上8点执行(开市前1.5小时,留足处置窗口)
0 8 * * 1-5 /opt/scripts/server_check.sh
# 每周六执行完整巡检(含SMART,利用休市时间)
0 9 * * 6 /opt/scripts/server_check_full.sh四、巡检报告要这么写
每次巡检完,必须留存结构化记录。对券商来说这份记录不只是运维存档,监管现场检查时《信息系统运维管理》专项是必查项,巡检记录的完整性直接影响检查评级。
服务器:trade-db-master-01(交易委托数据库主机)
日期:2026-02-14
巡检人:张三
耗时:20分钟
巡检类型:日常巡检(开市前)
硬件状态
[✓]CPU温度正常(62℃)
[✓] 内存无ECC错误
[⚠] 硬盘sda:Reallocated_Sector_Ct = 8,已超预警阈值
→ 已提交换盘工单 IT-20260214-001,预计2月18日到货
→ 到货后在周六休市维护窗口(2月22日 00:00-04:00)更换
[✓] 风扇转速正常
[✓] 双电源工作正常
系统状态
[✓] 磁盘:根分区68%,/data分区72%
[✓] 内存使用率:74%
[✓] 5分钟平均负载:3.8(8核,正常范围)
[✓] 网络连接数:3100(正常)
RAID状态
[✓]RAID10阵列:Optimal,8块盘全部Online
[✓] 上次重建完成时间:2026-01-15 03:22
应用服务
[✓] 交易委托服务运行正常
[✓]MySQL连接数:210,无死锁,无慢查询告警
[✓] 主从复制正常,当前延迟:0.3秒
[✓]Redis内存:3.1GB / 16GB,RDB持久化正常
安全检查
[✓] 无非交易时段登录记录
[✓] 无境外IP访问
[✓] 无可疑进程,无异常外联
问题与跟进
1. 硬盘sda预警(工单IT-20260214-001)
- 状态:已审批,等待硬件到货
- 预计完成:2026-02-22 04:00前
- 负责人:李四
2. /data分区72%,增速较上周加快(上周68%)
- 计划本周五收市后清理90天前的历史行情数据归档
- 清理前确认合规留存要求,保留监管要求的完整交易记录
- 负责人:张三,预计完成:2026-02-21 18:00
下次巡检:2026-02-17(下周一开市前)
巡检人签字:张三
审核人签字:李四(运维负责人)
合规备案编号:OPS-PATROL-20260214-001五、踩坑记录——这些错误券商运维真的犯过
坑1:只盯行情系统监控,忽略底层硬件状态
券商的监控体系往往建设得很完善——行情延迟、委托成功率、撮合吞吐量,这些业务层指标盯得死死的。但底层硬件的SMART数据?很多团队压根没接入监控体系。
大屏永远绿色,但存储层的盘已经悄悄累积坏道五个月了。那家中型券商出事之前,业务监控全部正常,直到IO飙升那一刻,所有指标同时变红。
怎么避: 监控体系必须下探到硬件层,SMART关键指标要纳入告警规则。业务层监控是结果,硬件层监控是原因,两层都不能少。
坑2:巡检记录流于形式,应付合规了事
这个问题在券商行业尤其普遍,因为有监管检查压力,所以巡检制度一定有,巡检记录一定有——但内容全是"正常""无异常""已检查"这类描述,没有任何具体数值。
某券商被证监会现场检查,调取过去半年的运维巡检记录,发现全部是模板化的"正常",检查人员直接判定"巡检制度形同虚设",整改要求随之而来。
怎么避: 巡检记录必须记具体数字:CPU使用率多少、内存占用多少、SMART各项指标数值是多少。数字才能反映趋势,描述性文字什么也说明不了。
坑3:发现了问题,卡在审批流程里没人跟进
这个坑最让人憋屈,因为运维本身已经尽职了。
某华东券商的运维在巡检中发现一块磁盘的 Current_Pending_Sector 数值异常,按流程提交了换盘申请。但申请进了采购流程之后,没人跟进审批进度,运维以为"提了就完了"。三周后,那块盘彻底失效,恰好撞上了一个交易高峰日。
事后复盘,申请单在采购部门那边因为预算审批卡了两周,根本没人知道这是紧急需求。
怎么避: 硬件故障工单必须有明确的紧急程度标记,运维负责人要每日跟进未完成工单的处理进度。SMART预警类的换盘申请应该走绿色通道,不能和普通采购混在一起排队。
坑4:RAID降级后,觉得"还在跑就先跑着"
这个是最危险的侥幸心理,前面案例里已经验证过代价了。
RAID降级之后,系统确实还能运行,业务指标也不会立刻异常,这给人一种"没什么大不了"的错觉。但冗余已经失效,这个状态下继续运行,相当于在没有安全带的情况下高速行驶——不出事是运气,出事是必然。
换盘这件事的优先级应该只有一个字:今天。不是本周,不是下次维护窗口,是今天。如果确实无法当天完成,要向管理层明确报告风险,留下书面记录,不能默默拖着。
坑5:灾备切换流程没有定期演练
这条不是直接的巡检问题,但和那个券商事故密切相关——系统崩溃之后,他们启动灾备切换花了超过1小时,原因是切换流程从来没有演练过,当场翻文档、当场踩坑。
一个没有被验证过的灾备方案,等于没有灾备。
怎么避: 灾备切换演练应该纳入季度运维计划,每次演练要记录RTO(恢复时间目标)和RPO(恢复点目标)的实际达成情况,发现问题持续优化。巡检的时候顺手验证灾备链路的连通性,是一个好习惯。
坑6:在交易时段做高IO的巡检操作
这个错误听起来低级,但确实有人犯过。
某券商运维在上午10点——交易高峰时段——执行了全盘SMART扫描,扫描产生的IO压力直接把数据库的响应时间推高了3倍,客户委托延迟从正常的50毫秒飙到180毫秒,客服热线随即承压。
怎么避: 巡检操作的时间窗口选择很重要。轻量级检查(查看状态、读取日志)可以在开市前完成;重IO操作(SMART全盘扫描、日志归档清理)要放在收市后或休市期间。券商有明确的交易时段,这个窗口期的运维操作要格外谨慎。
写在最后
回头看那个券商的事故,最让我觉得可惜的不是损失了多少钱,而是这件事本来完全可以避免。
5个月前,第一块盘的SMART报警出现了。如果有人在那个周的巡检里看到这个数字,提了换盘申请,跟进到换盘完成,后面的一切都不会发生。3800万的赔偿不会有,监管警示函不会有,CTO也不用走人。
整个链条上,差的就是那2小时的巡检,和一个闭环处理的习惯。
我见过不少券商IT团队,技术能力不弱,架构也做得很认真,但就是在这种"日常例行"的事情上掉链子。不是不知道该做,而是没有把"应该做"变成"每周必须做完并留存记录"。
知道和做到,中间隔着一套机制,一个习惯,还有管理层对这件事的真实重视程度——不是嘴上说说,而是真的给资源、给时间、给审批绿色通道。
希望看到这里的人,今天就把定时任务配上去,把巡检模板打印出来贴在工位上。
不用等下周,不用等下个季度。今天。
- EOF -
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号