记住 ≠ 学习: AI 记住了你,但它从不反思——这才是 Agent 记忆的真正问题

记住 ≠ 学习: AI 记住了你,但它从不反思——这才是 Agent 记忆的真正问题

随机比特
发布于 2026-03-30 16:26:58
发布于 2026-03-30 16:26:58
你有没有遇到过这种情况:
花了好几轮对话训练一个 AI 助手,告诉它你喜欢用函数式编程、代码注释要用中文、别写过度工程化的东西。
然后下次打开,一切从零开始。
···
大部分开发者的第一反应是"接个记忆模块"。接了。加了 RAG,把对话历史塞进向量库,每次检索几条相关上下文。
感觉解决了。
但几周之后你会发现一个更深的问题:AI 记住了那些对话,但它好像从来没有从中"学到"什么。
它还是会犯你纠正过的同样的错误。它不会主动说"上次你说过更喜欢简洁的实现"。它只是在海量历史里搜了一下,找到了几条相似度最高的片段,然后继续回答你。
记住 ≠ 学习。这才是问题所在。
为什么 RAG 做不到"学习"
RAG 的底层逻辑是:存储原始文本 → 向量化 → 语义检索。
它很擅长找"上次讲过的类似信息"。但它不会自动整合信息,不会把"用户喜欢函数式"和"用户不喜欢类继承"合并成一个"关于用户编码风格的理解"。
两条原始记忆存在那,但没有人去"反思"它们,提炼出更高层次的认知。
人类的记忆不是这样工作的。
睡觉时,大脑会做一件事:把白天的零散经历整合成更稳定的知识。你不只是记住了"那天踩了一个空指针 bug",你还从中学到了"以后写 optional chain 要更小心"。
这个"整合理解"的过程,是大多数 Agent 记忆系统里缺失的那一块。
Hindsight 怎么解决这个问题
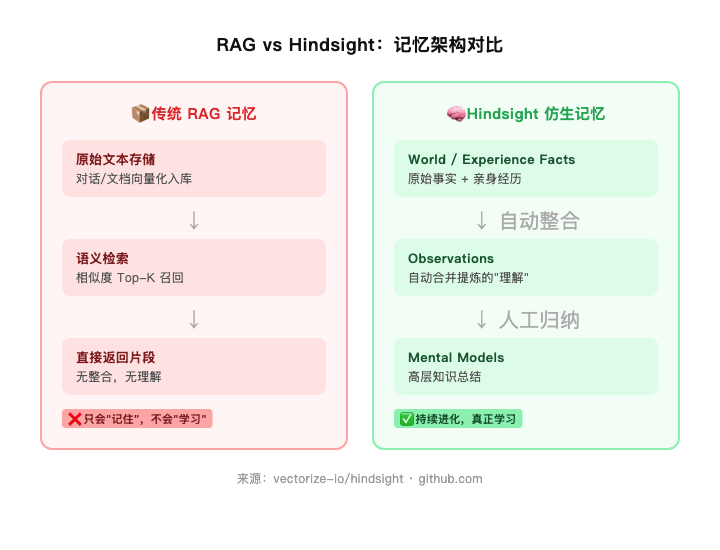
vectorize-io/hindsight 这个项目的核心设计思路就是模仿人类记忆的分层结构。
它把 Agent 的记忆分成四种类型:
类型 | 存什么 | 例子 |
|---|---|---|
World Fact | 客观事实 | "Alice 在 Google 工作" |
Experience Fact | Agent 自己的行动记录 | "我推荐过 Alice 用 Python" |
Observation | 自动整合多条事实得出的"理解" | "用户偏好函数式,最近从 React 切到了 Vue" |
Mental Model | 人工定义的高层知识 | "关于 Alice 的编码风格总结" |
关键在 Observation 这一层。
每次 Agent 接收到新信息(Retain),hindsight 会在后台自动分析:这条信息是否能和已有记忆合并?是否要更新已有的理解?
就像大脑在睡眠时做的事——把零散经历压缩成更稳定的认知。
01-memory-arch
三个操作,重新定义记忆
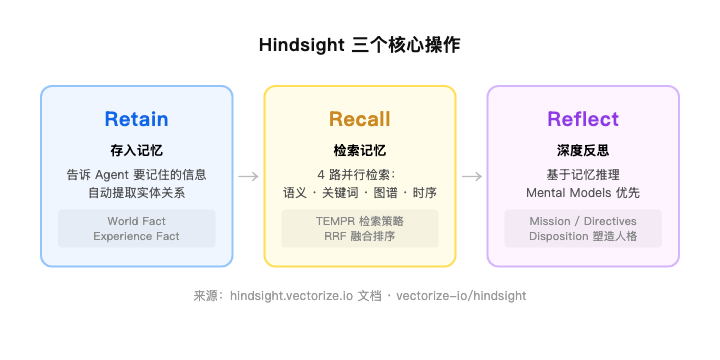
Hindsight 对外只暴露三个操作:
Retain — 告诉它要记住什么
client.retain(bank_id="my-agent", content="用户更喜欢简洁实现,不喜欢抽象层过多") Recall — 检索相关记忆
它同时跑 4 种检索策略:语义相似、BM25 关键词、知识图谱关联、时间范围。结果用倒数排名融合(RRF)合并后再 rerank。
比单纯向量检索更准,尤其在"上个月发生了什么""和 Alice 相关的所有信息"这类时序/关联查询上。
Reflect — 让 Agent 基于记忆进行深度推理
client.reflect(bank_id="my-agent", query="这个用户的编码风格是什么?") Reflect 不是简单检索,它会读 Mental Models → Observations → Raw Facts,从中生成"反思后的回答"。
你还可以给 memory bank 配置 Mission(身份)、Directives(不可违反的规则)、Disposition(思维风格偏好)——就像给 agent 的记忆赋予人格。
02-retain-recall-reflect
基准数据怎么说
在 LongMemEval 基准上,hindsight 拿到了目前报告的最高分。
这个基准测试的是 AI 在长期对话场景下的记忆表现:能不能记住跨越多次会话的信息、时序推理、间接关联等。
其他方案(RAG、知识图谱、简单摘要)在这个基准上的差距相当明显。Virginia Tech Sanghani AI 中心对结果做了独立复现验证,华盛顿邮报也进行了评估。
当然,benchmark 数据永远比真实场景乐观一些。但这至少说明方向是对的。
接进去有多难?
pip install hindsight-client 或者 Docker 起一个本地服务(内嵌 PostgreSQL,不依赖外部数据库):
docker run --rm -it --pull always -p 8888:8888 -p 9999:9999 \ -e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \ ghcr.io/vectorize-io/hindsight:latest 如果你用 LangChain、LlamaIndex 或者直接调 OpenAI/Anthropic SDK,只需要 2 行就能接入:把原来的 LLM client 换成 hindsight 的 wrapper,记忆的存储和检索会自动发生。
支持 OpenAI、Anthropic、Gemini、Groq、Ollama 等主流模型。
···
这不是说 RAG 没用。对于检索外部知识库这种场景,RAG 仍然是标准答案。
但如果你想让 Agent 在持续交互中真正进化——记住你的偏好、从错误中学习、在跨会话的上下文里保持一致——那光靠向量搜索是不够的。
你需要一个会"反思"的记忆系统。
Hindsight 试图解决这个问题。3251 颗星,MIT 协议,开源可自部署。值得试一下。
···
你现在做的 Agent 有没有加持久化记忆?用的什么方案?遇到过什么坑?评论区说说,这块还有很多值得聊的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号