免疫组库基础分析13:TCR\BCR序列相似性网络分析_NAIR包介绍(2)

免疫组库基础分析13:TCR\BCR序列相似性网络分析_NAIR包介绍(2)

三兔测序学社
发布于 2026-04-17 16:49:44
发布于 2026-04-17 16:49:44
Node-Level Network Properties
免疫组库网络分析中的节点级属性
1. 什么是节点级网络属性?
节点级属性是指网络图中每个单独节点所具有的特性。根据计算范围的不同,它们分为两类:
- 局部属性: 其值仅取决于网络中节点的子集。
- 示例:网络度,即直接连接到该节点的边的数量。
- 全局属性: 其值取决于网络中所有节点。
- 示例:权威分数,利用整个图的邻接矩阵(A)计算得出,具体为 A^TA 的主特征向量。
2. 计算方法
在 NAIR 包中,计算这些属性主要有两种方式:
- 构建时计算: 在调用
buildRepSeqNetwork()或其别名buildNet()时,设置参数node_stats = TRUE。 - 分步计算: 使用
addNodeStats()函数对已构建的网络对象进行单独计算。
# build network with computation of node-level network properties
net <- buildNet(toy_data, "CloneSeq",
node_stats = TRUE
)
net <- buildNet(toy_data, "CloneSeq")
net <- addNodeStats(net) 3.结果说明names(net$node_data)
#> [1] "CloneSeq" "CloneFrequency"
#> [3] "CloneCount" "SampleID"
#> [5] "degree" "transitivity"
#> [7] "eigen_centrality" "centrality_by_eigen"
#> [9] "betweenness" "centrality_by_betweenness"
#> [11] "authority_score" "coreness"
#> [13] "page_rank"指标名称 | 中文名称 | 核心逻辑 | 通俗理解 |
|---|---|---|---|
degree | 度 | 直接邻居的数量 | “人脉广” (认识多少人) |
betweenness | 中介中心性 | 位于最短路径上的频率 | “桥梁/把关人” (信息必经之路) |
closeness | 接近中心性 | 到所有其他节点的距离 | “传播快” (消息传得最快) |
eigen_centrality | 特征向量中心性 | 连接对象的重要性 | “圈子好” (认识的大佬多) |
authority_score | 权威分数 | 被重要节点引用的次数 | “学术大牛” (被很多人引用) |
page_rank | PageRank | 带随机跳转的概率权重 | “综合影响力” (谷歌排名逻辑) |
coreness | 核心度 | 所在网络的层级深度 | “核心骨干” (处于心脏地带) |
transitivity | 聚集系数 | 邻居之间是否也相连 | “小圈子紧密度” (我的朋友也互为朋友) |
4.其他:选择节点级属性
stats_to_include 参数配合 chooseNodeStats() 或 exclusiveNodeStats() 函数,允许用户灵活定制节点属性的计算范围,既能基于默认集增删属性,也能仅指定计算特定属性,从而优化计算效率。
# Modifying the default set of node-level properties
net <- buildNet(toy_data, "CloneSeq", node_stats = TRUE,
stats_to_include = chooseNodeStats
(closeness = TRUE,
page_rank = FALSE ))
# Include only the node-level properties specified below
net <- buildNet(toy_data, "CloneSeq",
node_stats = TRUE,
stats_to_include =
exclusiveNodeStats(degree = TRUE,
transitivity = TRUE
))聚类分析
1.主要运行代码
net <- buildRepSeqNetwork(toy_data, "CloneSeq", cluster_stats = TRUE)或者两步完成:net <- buildNet(toy_data, "CloneSeq")
net <- addClusterStats(net)2.结果说明
names(net$cluster_data)
#> [1] "cluster_id" "node_count"
#> [3] "eigen_centrality_eigenvalue" "eigen_centrality_index"
#> [5] "closeness_centrality_index" "degree_centrality_index"
#> [7] "edge_density" "global_transitivity"
#> [9] "assortativity" "diameter_length"
#> [11] "max_degree" "mean_degree"
#> [13] "mean_seq_length" "seq_w_max_degree"指标英文名 | 中文名称 | 详细定义与解释 |
|---|---|---|
node_count | 节点数量 | 该簇中包含的节点(如克隆、细胞)总数。 |
mean_seq_length | 平均序列长度 | 该簇内所有受体序列长度的平均值。 |
mean_degree | 平均度 | 该簇内节点的平均连接数(网络度)。 |
max_degree | 最大度 | 该簇内所有节点中最大的连接数。 |
seq_w_max_degree | 最大度序列 | 该簇内拥有最大连接数(Max Degree)的那个受体序列。 |
diameter_length | 直径长度 | 该簇内最长的测地距离(即最短路径中的最长距离)。 |
assortativity | 同配系数 | 基于节点度数的同配系数(计算时仅基于簇内节点)。 |
global_transitivity | 全局传递性 | 该簇图的传递性(即聚集系数),估计相邻顶点相互连接的概率。 |
edge_density | 边密度 | 该簇中实际边数占最大可能边数的比例(分数形式)。 |
agg_count | 聚合计数 | 该簇内所有节点计数的总和(基于 count_col 列,若提供)。 |
max_count | 最大计数 | 该簇内所有节点中的最大计数值(基于 count_col 列,若提供)。 |
seq_w_max_count | 最大计数序列 | 该簇内拥有最大计数值的那个受体序列。 |
degree_centrality_index | 度中心性指数 | 基于簇内图度数的簇级中心性指数。 |
closeness_centrality_index | 接近中心性指数 | 基于接近度(即到簇内其他节点的距离)的簇级中心性指数。 |
eigen_centrality_index | 特征向量中心性指数 | 基于特征向量中心性分数(邻接矩阵主特征向量的值)的簇级指数。 |
eigen_centrality_eigenvalue | 特征向量中心性特征值 | 对应该簇邻接矩阵主特征向量的特征值。 |
3.用途说明
- 如果你在寻找“谁是主角”(例如寻找与疾病相关的抗原受体簇),请优先看 agg_count。
- 如果你在研究“如何进化”(例如研究B细胞亲和力成熟过程),请结合 node_count 和 diameter_length 看簇的大小和跨度,并用 eigen_centrality_index 寻找进化树的根节
- 与count相关的属性计算,只有在用户通过 count_col 参数指定了包含丰度信息(如克隆计数或UMI计数)的列时,系统才会计算基于丰度的聚类网络属性(如 agg_count 和 max_count)。
4. 聚类算法 (Clustering Algorithm)
默认使用 cluster_fast_greedy(快速贪心算法),但也支持多种其他算法,可通过 cluster_fun 参数指定:
"fast_greedy"(默认);"leiden", "louvain" (常用);"infomap",
"label_prop";"edge_betweenness", "walktrap" 等
5. 高级用法:多重聚类与标签
- 多重聚类
- 可以使用不同的算法(如 Fast Greedy 和 Louvain)对同一网络进行多次聚类。
- 通过
cluster_id_name参数为每次聚类的结果指定不同的变量名(如cluster_greedy,cluster_louvain),以便区分。 - 限制:目前不支持保留多次聚类的簇属性(Cluster Properties),
addClusterStats()会覆盖现有的属性。
- 标记簇 (Labeling Clusters)
- 使用
labelClusters()函数可以在网络图上直接标注簇 ID。 - 默认仅标注节点数最多的前 20 个簇以保证可读性,但可以通过
top_n_clusters和criterion(如按agg_count排序)参数自定义。
- 使用
6.代码说明
# 第一阶段:构建网络并进行 Fast Greedy 聚类
net <- buildNet(toy_data, "CloneSeq",
print_plots = FALSE, # 不立即打印图表(为了效率,最后统一打印)
cluster_stats = TRUE, # 关键参数:在构建网络时直接计算簇的统计属性
cluster_fun = "fast_greedy", # 默认fast_greedy聚类算法,其实可以不写这个代码
cluster_id_name = "cluster_greedy", # 将此次聚类的ID保存为 "cluster_greedy"
color_nodes_by = "cluster_greedy", # 节点颜色依据 "cluster_greedy" 变量
color_scheme = "Viridis", # 使用 Viridis 配色方案
size_nodes_by = 1.5, # 节点大小固定为 1.5
plot_title = NULL) # 不设置标题
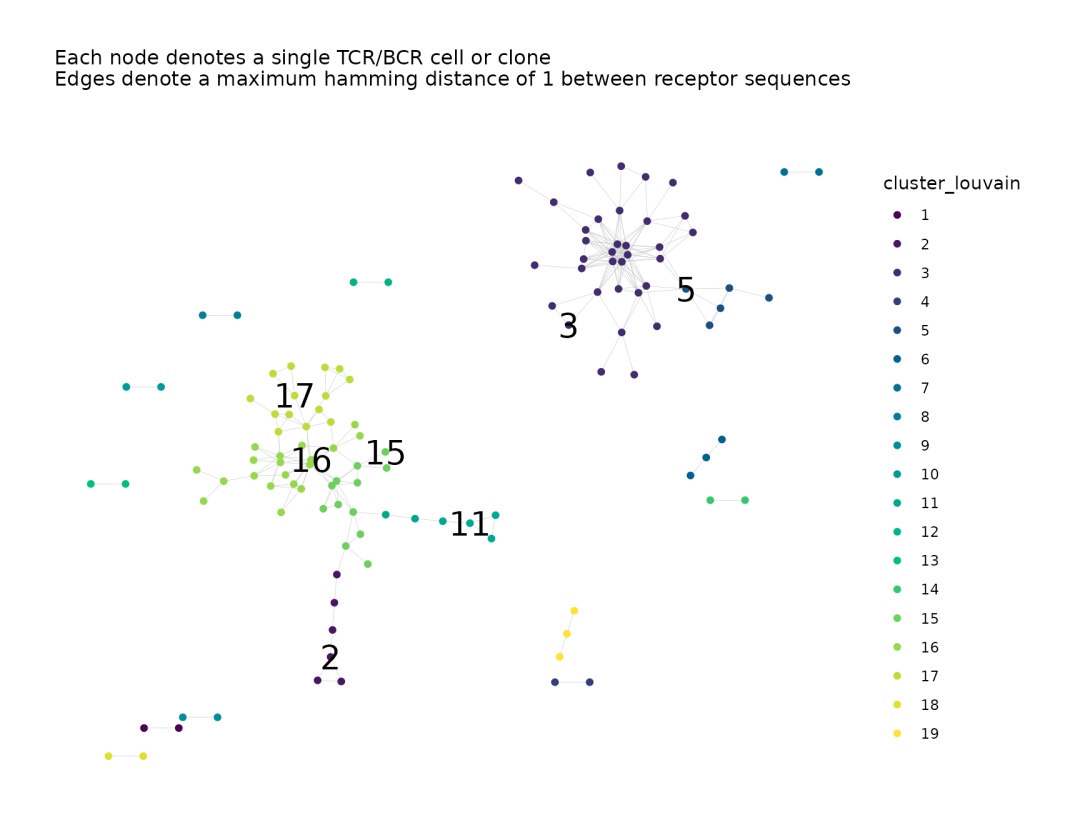
# 第二阶段:在现有网络上运行 Louvain 算法
net <- addClusterMembership(net, # 输入上一步生成的网络对象
cluster_fun = "louvain", # 指定使用 Louvain 聚类算法
cluster_id_name = "cluster_louvain") # 将此次聚类的ID保存为 "cluster_louvain" )
# 为 Louvain 聚类结果生成新的图表
net <- addPlots(net,
color_nodes_by = "cluster_louvain", # 节点颜色依据 "cluster_louvain" 变量
color_scheme = "Viridis", # 使用相同的配色方案以便对比
size_nodes_by = 1.5, # 节点大小固定
print_plots = FALSE )
# 第三阶段:为 Fast Greedy 的图表添加标签
net <- labelClusters(net, plots = "cluster_greedy", # 指定要标注的图表名称
cluster_id_col = "cluster_greedy", # 指定对应的簇 ID 变量
top_n_clusters = 7, # 仅标注最大的 7 个簇(避免图表混乱)
size = 7 # 标签字体大小为 7 )
# 第三阶段:为 Louvain 的图表添加标签
net <- labelClusters(net, plots = "cluster_louvain", # 指定要标注的图表名称
cluster_id_col = "cluster_louvain", # 指定对应的簇 ID 变量
top_n_clusters = 7, # 仅标注最大的 7 个簇
size = 7) # 标签字体大小为 7
# 显示 Fast Greedy 算法生成的图表
net$plots$cluster_greedy
# 显示 Louvain 算法生成的图表
net$plots$cluster_louvain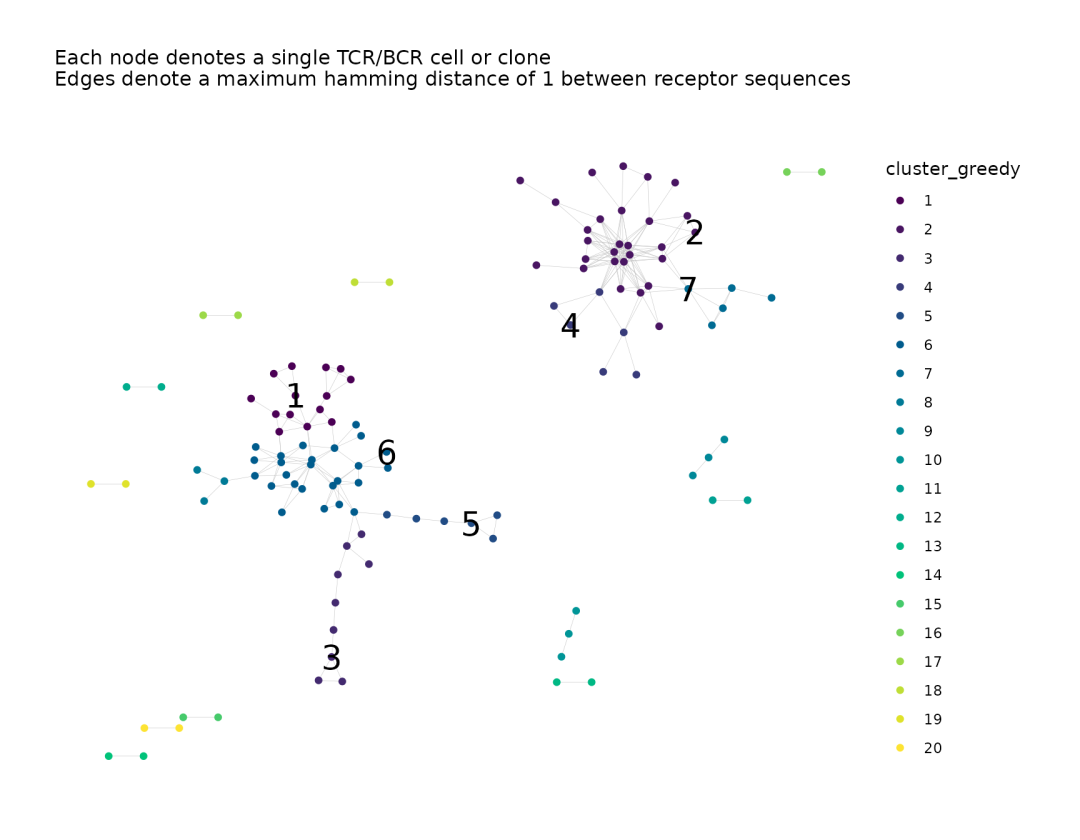
NAIR 补充函数参数详解表
函数名称 (Function) | 核心参数 (Parameters) | 中文解释与说明 |
|---|---|---|
Simulate Data | sample_size, prefix_length | 模拟数据:用于生成示例数据。sample_size 指定样本数量,prefix_length 指定序列前缀长度。 |
addPlots | color_nodes_by, color_scheme | 添加图表:color_nodes_by 指定节点着色依据的变量;color_scheme 指定配色方案(如 Viridis)。 |
addNodeStats | stats_to_include | 添加节点统计:指定要计算的节点属性。通常设为 "all" 以计算所有指标(如度、中心性等)。 |
addClusterStats | cluster_fun, cluster_id_name | 添加簇统计:cluster_fun 指定聚类算法(如 "walktrap");cluster_id_name 指定保存簇ID的列名。 |
addClusterMembership | cluster_fun, cluster_id_name | 添加簇成员:与上类似,但仅计算成员归属,不计算簇属性,用于对比不同算法。 |
addClusterLabels | cluster_id_col, top_n_clusters | 添加簇标签:cluster_id_col 指定要标注的簇ID列;top_n_clusters 指定仅标注最大的 N 个簇。 |
labelNodes | label_col, size | 标注节点:label_col 指定作为标签显示的列(如序列名);size 控制标签字体大小。 |
saveNetwork | output_dir, output_type | 保存网络:output_dir 指定输出目录;output_type 指定保存格式(如 individual)。 |
saveNetworkPlots | outfile | 保存网络图表:outfile 指定输出的 PDF 文件路径。 |
loadDataFromFileList | input_type, read.args | 从文件列表加载数据:input_type 指定文件格式(csv, rds 等);read.args 传递给读取函数的额外参数。 |
combineSamples | min_seq_length, sample_ids | 合并样本:除加载数据外,可指定 min_seq_length 过滤序列长度,或指定 sample_ids 添加样本ID。 |
filterInputData | min_seq_length, drop_matches | 过滤输入数据:min_seq_length 过滤掉长度不足的序列;drop_matches 过滤掉包含特定字符的序列。 |
aggregateIdenticalClones | clone_col, grouping_cols | 聚合同一克隆:clone_col 指定序列列;grouping_cols 指定分组变量(如按时间点或受试者分组聚合)。 |
getNeighborhood | target_seq, dist_cutoff | 获取邻域:target_seq 指定目标序列;用于提取与该序列相似(距离在阈值内)的其他序列。 |
generateNetworkObjects | dist_type, dist_cutoff | 生成网络对象:底层函数,用于仅生成网络对象而不进行绘图或复杂计算。 |
generateNetworkGraph | adjacency_matrix | 生成网络图:将邻接矩阵转换为 igraph 对象。 |
generateAdjacencyMatrix | dist_type, dist_cutoff | 生成邻接矩阵:根据序列列表计算距离并生成邻接矩阵。 |
免疫组库分析合集
【生信分析】免疫组库基础分析2-V/D/J基因使用频率可视化图
【生信分析】免疫组库基础分析3-基于V/D/J使用频率的聚类分析
【生信分析】免疫组库基础分析4-VJ/VDJ组合使用频率计算及可视化
【生信分析】免疫组库基础分析6-克隆子的分布分析(优势克隆与罕见克隆)
【生信分析】免疫组库基础分析10-CDR3 氨基酸理化性质分析
免疫组库分析11:Alakazam包【基因使用、多样性及氨基酸理化性质分析】使用说明
免疫组库分析12:TCR、BCR序列相似性网络分析-NAIR包介绍(1)
如果你觉得这篇博文对你有帮助,请点赞、收藏、转发!支持我们持续输出优质内容!
关注“三兔测序学社”,获取更多测序分析实用教程与前沿解读。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号