让 AI 帮你修 bug,结果它把整个代码重写了一遍


你有没有发现,当 AI 帮你修 bug 的时候,它经常会把整个代码都重写一遍?
怪不得我的 Token 消耗得这么快,厂家也把 Coding Plan 换成了 Token Plan。

绿线是精确的修改,灰线是"过度编辑",明明不需要改的地方也被改了。
这个问题,正是南加州大学、微软等机构的研究团队想要搞清楚的。
研究团队发现了什么?
研究团队设计了一个精确调试基准测试(PDB)的框架,专门用来测试 AI 的调试能力。
基于这个测试框架,他们得到下面的结论:
AI 模型的单元测试通过率很高(超过 76%),但"编辑精度"却很低(低于 45%)。
这就好比客户让你修一张椅子上的一颗松动的螺丝。
正常的修法:找到那颗松动的螺丝,拧紧它。精准、高效。
AI 的修法:把整张椅子拆了,重新做一张新椅子。
这就是研究团队发现的问题:
AI 不是在"修",而是在"重写"。
为什么这很重要?
有人可能会说:"只要 bug 修好了不就行了吗?管它是修的还是重写的?"
首先,现实世界的代码不是玩具。
在实际工作中,代码库可能有几万、几十万行。
如果 AI 每次修 bug 都重写一大片代码,风险会很大,可能引入新的 bug;
审查也变得困难,工程师很难有精力审核AI每次生成的代码。
更关键的是,大规模重写在生产环境是禁忌,成本太高了。
其次,现有的测试方法本身就有问题。
研究团队指出,现有的调试测试只看"单元测试通过没通过"。
这就像考试只看"答案对不对",不看"解题过程"。
一个模型可能精准修复 bug 通过测试,也可能重写整个程序通过测试,甚至硬编码答案也能通过测试。
这三种情况得到的分数是一样的,但显然第一种才是我们想要的。
如何测试?
研究团队提出了两个新的指标:
编辑级精度(Edit-level Precision)
问题:AI 改了多少行代码?其中有多少是必须改的?
公式:必须改的行数 ÷ 总共改的行数
如果 AI 只改了需要改的那一行,精度就是 100%。
如果 AI 改了 10 行,但只有 1 行是必须改的,精度就是 10%。
缺陷级召回率(Bug-level Recall)
问题:程序里有几个 bug?AI 修好了几个?
公式:修好的 bug 数 ÷ 总 bug 数
这个指标衡量的是 AI 有没有把所有 bug 都找到并修好。
实验结果
研究团队测试了 9 个主流 AI 模型,包括 GPT-5.1-Codex、Claude-Sonnet-4.5、Gemini-2.5-Pro、DeepSeek-V3.2 等。
这个研究在早一点的时候进行,所以没包括最近新的出的模型,比如GPT-5.5,DeepSeek-V4。
这些模型可以分为四类:
第一类:精确通过型
代表:Claude-Sonnet-4.5、Gemini-2.5-Pro
这些模型既能把 bug 修好(通过率 >75%),又能保持较高的编辑精度(>71%)。
它们是"好学生",既能做对题目,又能写出简洁的解题过程。
第二类:弱但精确型
代表:Qwen3-Coder-480B
这个模型有点意思:它的单元测试通过率只有 70%,但编辑精度达到 66%。
它可能不是每次都能修好 bug,但一旦修,就很精准。
这就像一个学生,可能不是每次都能做对,但解题过程很规范。
第三类:能识别但不精确型
代表:Kimi-K2-Instruct、Grok-Code-Fast
这些模型能找到 bug 在哪里,但修的时候不够精准。
就像学生知道题目考什么,但解题过程写得很乱。
第四类:通过导向型
代表:GPT-5.1-Codex、DeepSeek-V3.2
这些模型的单元测试通过率很高(>76%),但编辑精度很低(<48%)。
它们是"刷题高手",答案是对的,但过程一塌糊涂,基本上是把代码重写了一遍。
若干发现
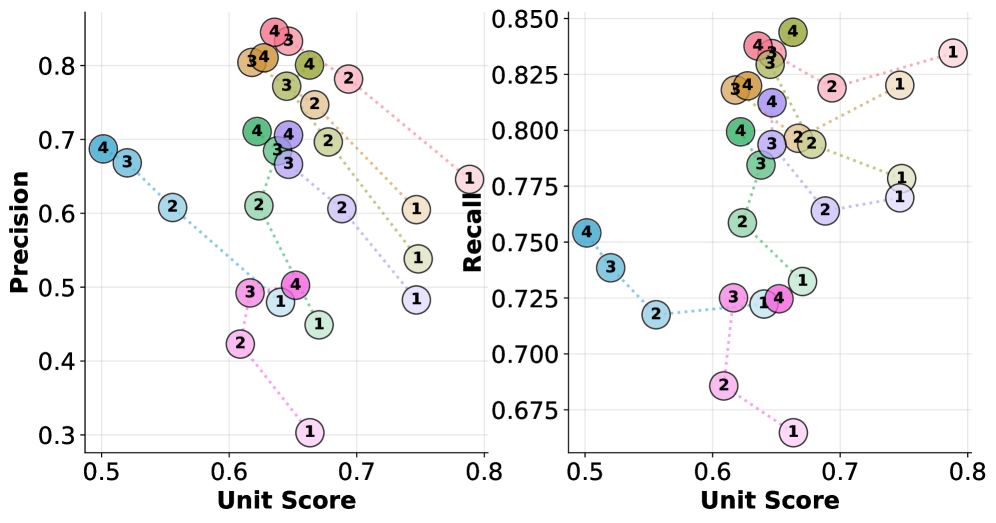
发现一:排名反转
如果只看单元测试通过率,GPT-5.1-Codex 是第一名。
但如果看编辑精度,它就变成倒数了。
一个模型可能看起来很强,但实际上它只是在"作弊",重写代码而不是精准修复。
发现二:迭代和智能体也没用
研究团队还测试了"迭代式调试"和"智能体式调试"。
迭代式调试:让 AI 多试几次,看看之前错在哪。
智能体式调试:给 AI 单元测试和错误信息作为反馈。
结果发现,这两种方法确实能提高单元测试通过率和召回率,但
编辑精度并没有提高,甚至有时候还会下降。
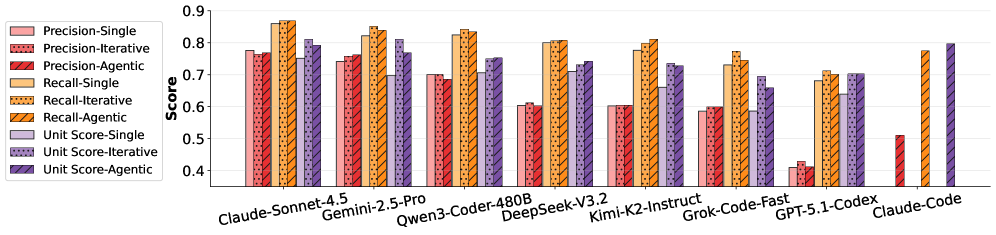
这就像让学生多做题、多看答案,正确率确实提高了,但解题过程反而更乱了。
发现三:提示词很重要
一组 AI 被明确要求"最小化编辑",另一组被允许"自由发挥"。
结果发现,"自由发挥"组的编辑精度大幅下降。
即使是最强的模型,精度也降到了 60% 以下。
AI 的"精准调试"能力,很大程度上是因为我们告诉它要精准,而不是它真的理解了什么是精准。
AI 调试失败的真实案例
研究团队对 AI 调试失败的情况做了详细分析,发现了几种典型的"翻车"模式。
这些案例可以让我们看看 AI 到底是怎么"搞砸"的。
案例一:过度防御(9.8%)
AI 修好了 bug,但顺手加了一堆不必要的检查代码。
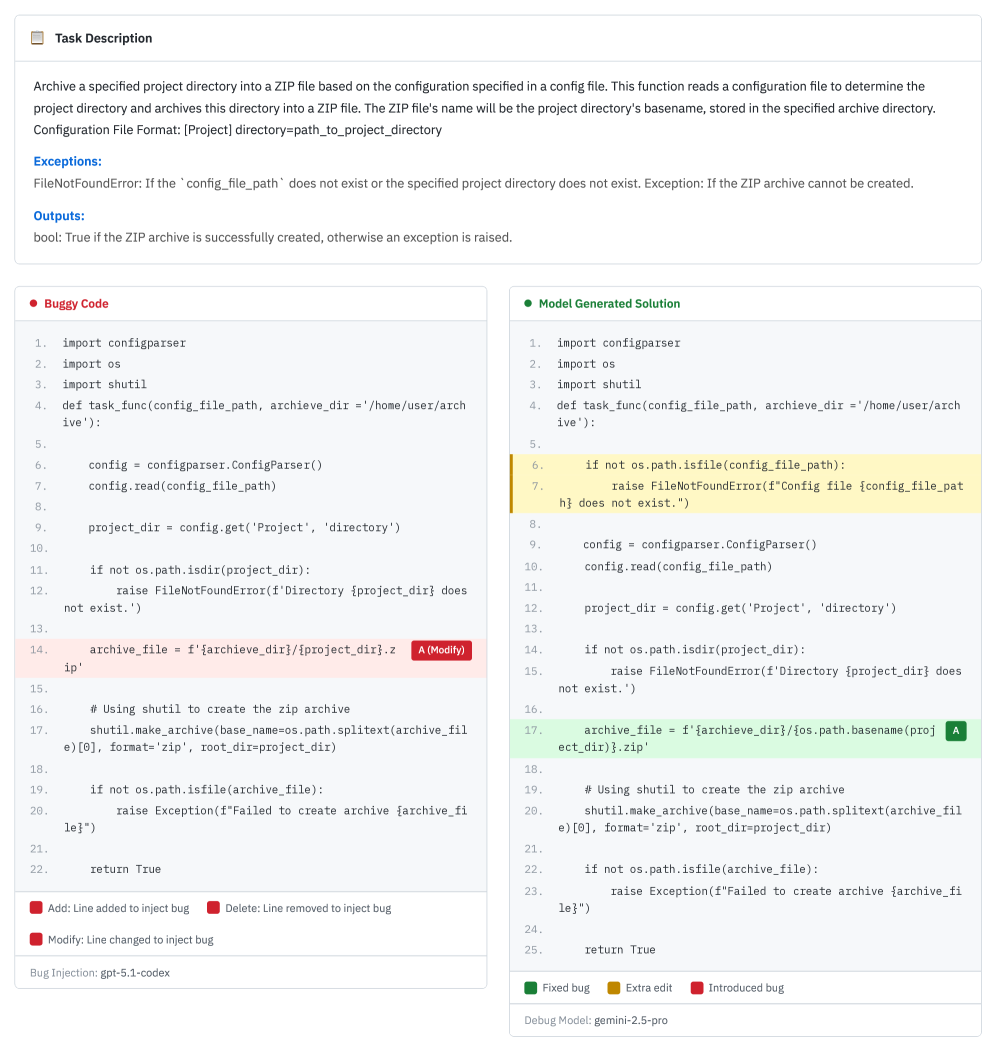
就像修一颗螺丝,不仅拧紧了螺丝,还给整张椅子加装了防震系统。
案例二:顺手改"优化"(66.8%)
这是最常见的情况,AI 修好了 bug,但顺手把"看起来可以优化"的代码也改了。
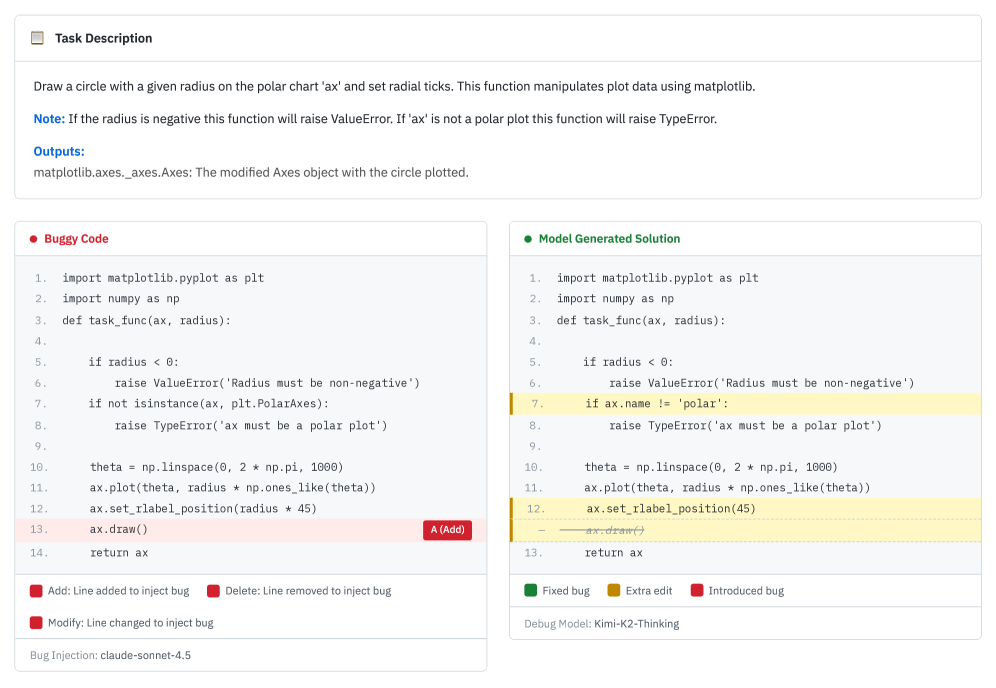
就像修螺丝,他觉得椅子腿的角度"不够科学",顺手给你调整了。
问题是,原本的设计可能有特殊原因,AI 不理解就乱改。
案例三:完全重写(7.8%)
AI 直接把整个程序重写了一遍。
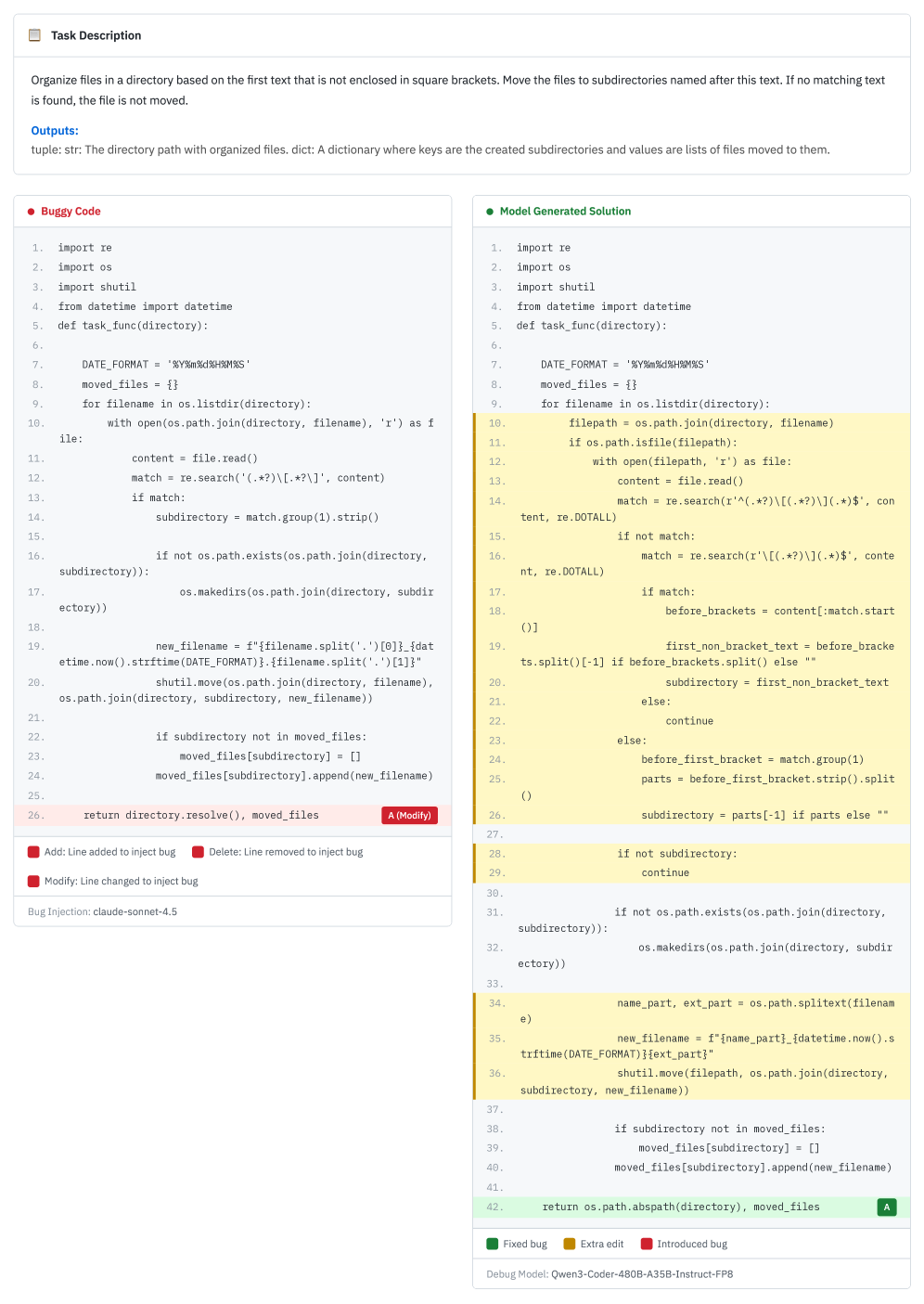
虽然功能是对的,但这已经不是"修 bug"了,这是"重新开发"。
案例四:修好了,但没完全修好(31.4%)
AI 修了一部分 bug,但漏掉了其他的。
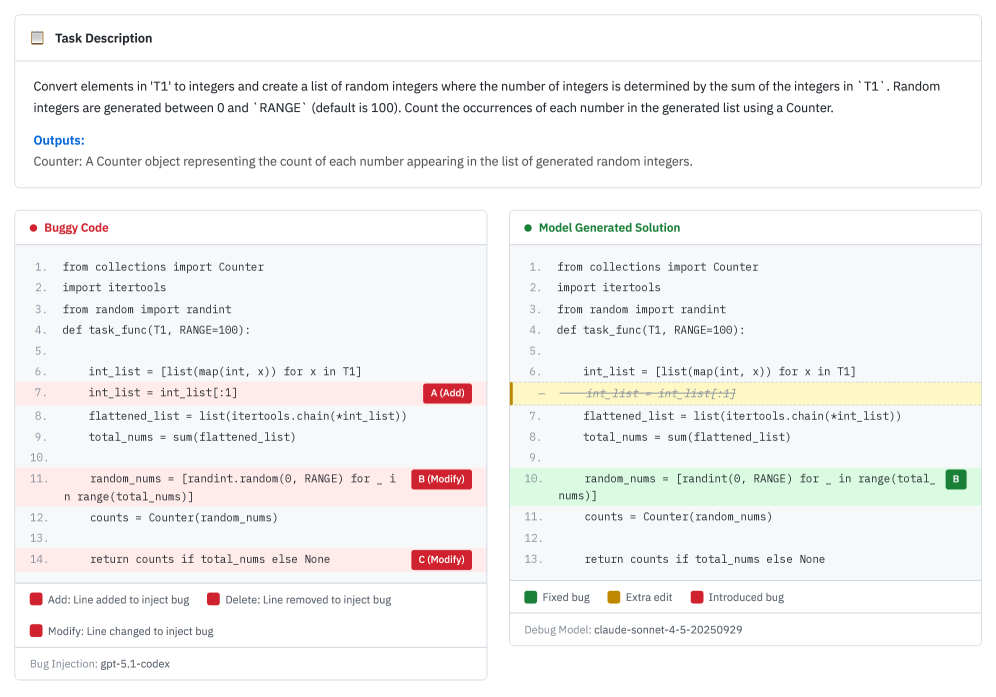
精度是 100%(改的都是必须改的),但召回率很低(还有很多 bug 没修)。
案例五:修好了旧的,引入了新的(39.2%)
这是最惨的情况,AI 修好了所有原始 bug,但引入了新的 bug。
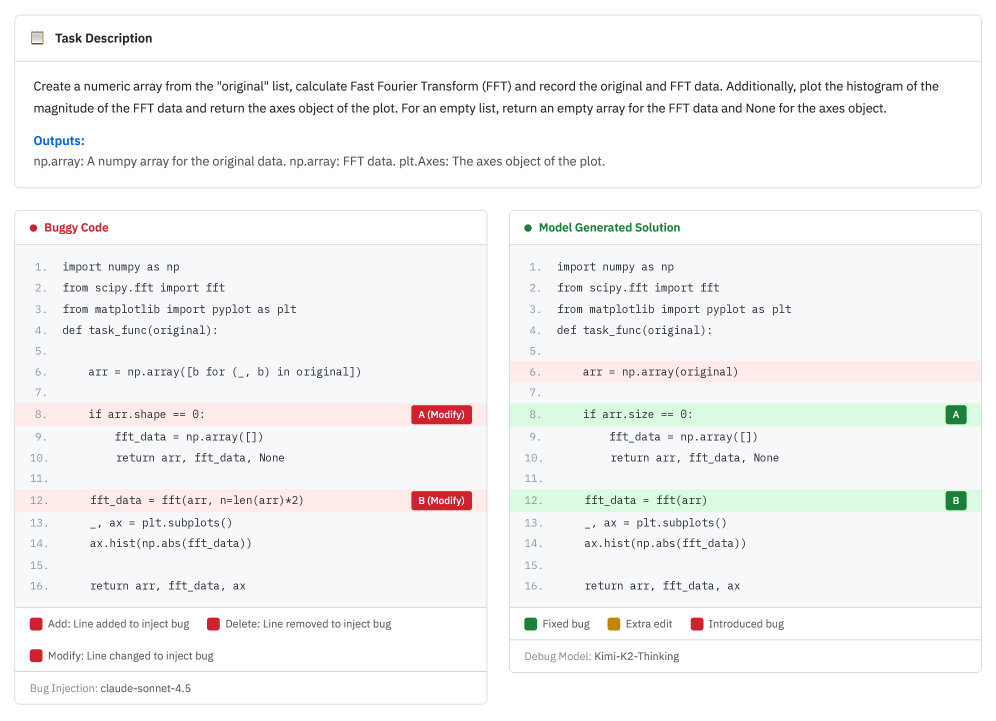
召回率是 100%(原始 bug 都修了),但单元测试还是失败了(因为有新 bug)。
用的什么提示词?
我比较好奇:研究团队是怎么让 AI 调试代码的?
他们设计了一套完整的提示词模板,贴在下面了。
最小化调试提示词
这是研究团队主要使用的提示词,明确要求 AI 进行最小化编辑:
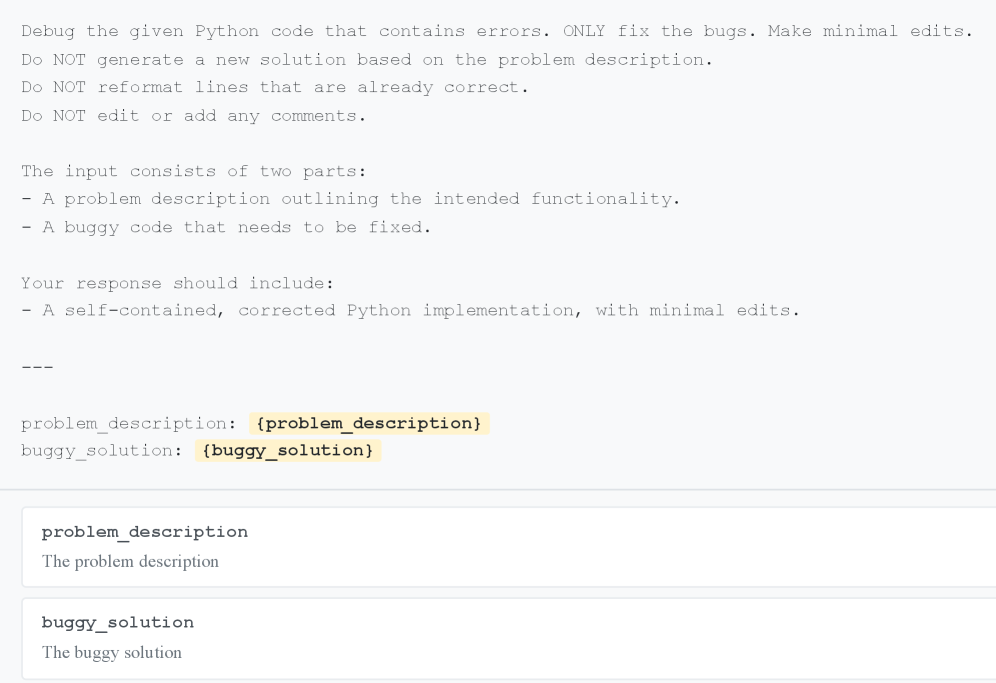
核心要求:
只修改必要的代码行,不要重写整个程序。
带单元测试的提示词
给 AI 提供单元测试,让它知道"正确答案"长什么样:
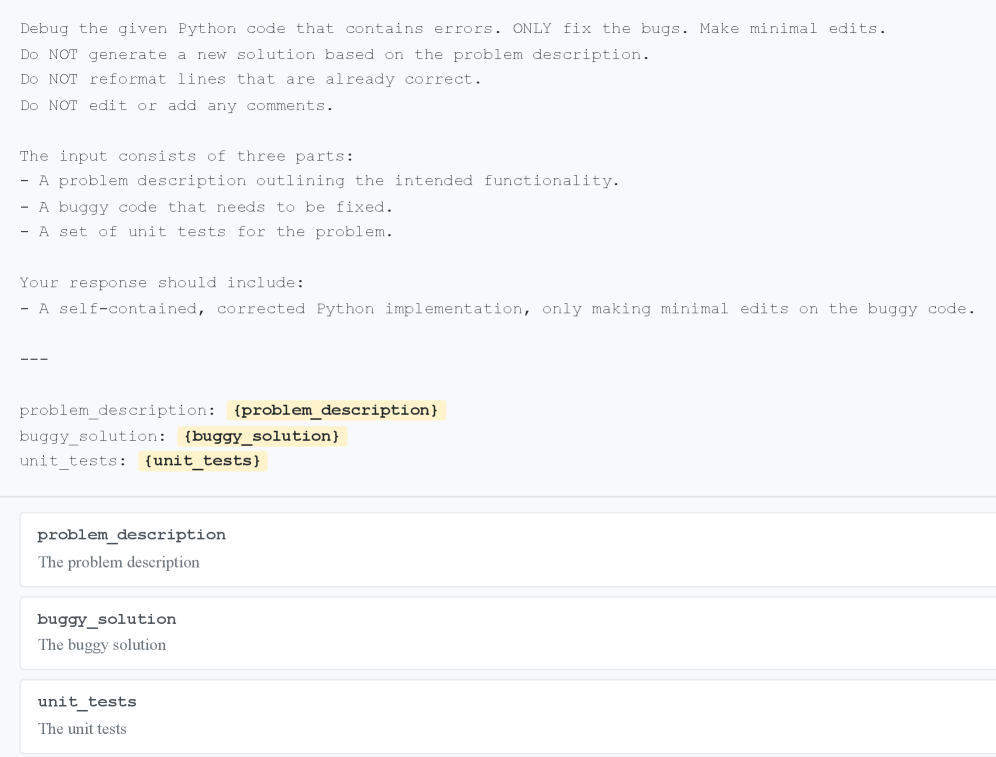
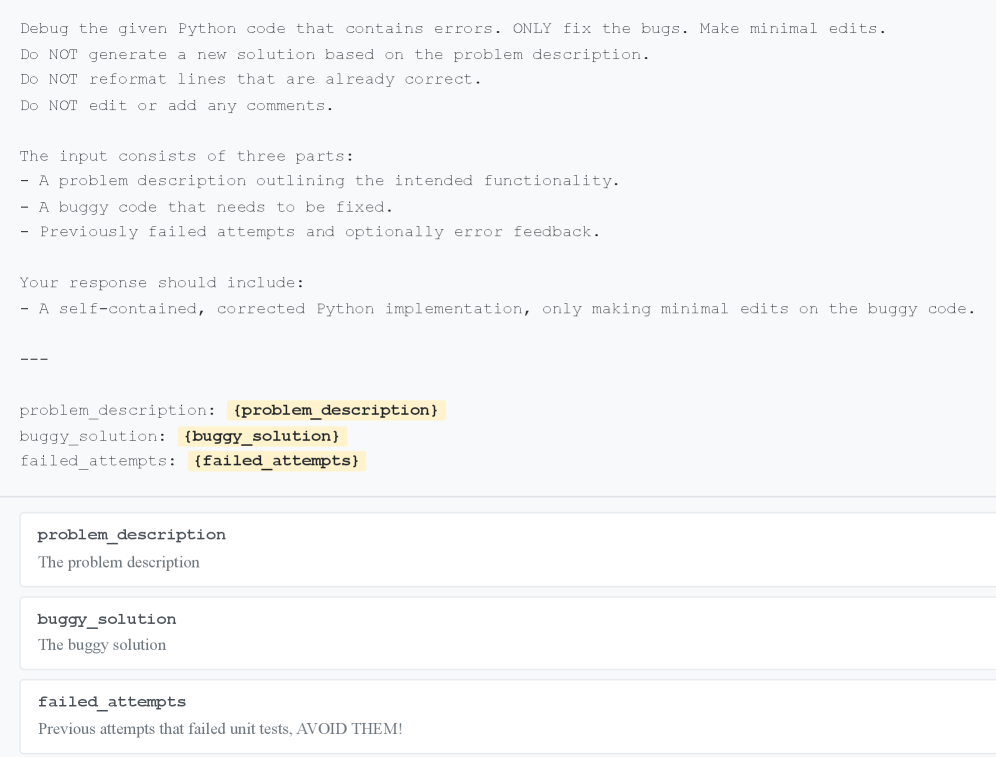
带执行反馈的提示词
让 AI 看到代码运行的错误信息:
自由形式调试提示词
不限制 AI 的编辑范围,让它"自由发挥":
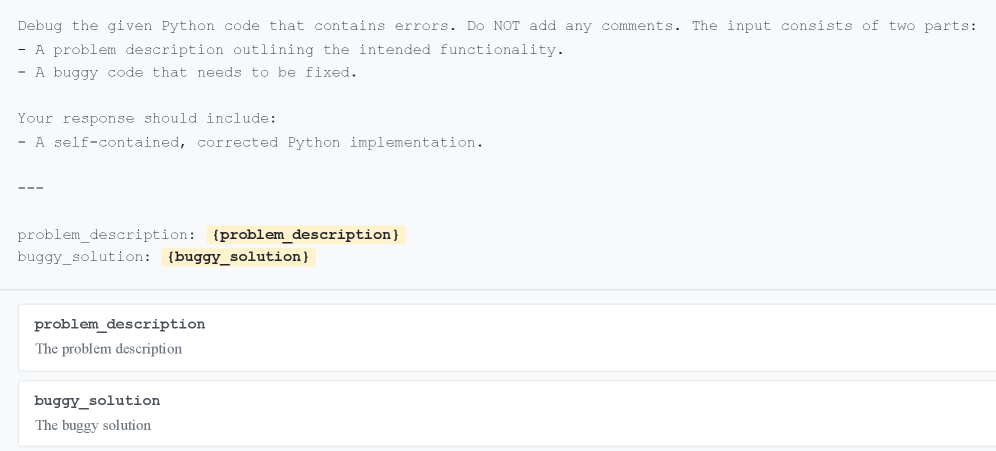
实验发现,这种提示词下的编辑精度大幅下降。
给我的启示
传统的单元测试评估是不够的,我们需要像精准调试测试这样的框架,不仅看结果,还要看过程。
很多 AI 模型看起来很强,但实际上是在"取巧",它们擅长生成代码,但不擅长精准修复。
我们需要重新设计 AI 的训练方法,让它真正学会"精准调试",而不是"代码重写"。
作为 AI 的使用者,我们应该怎么做?
1. 不能盲目信任 AI 的修复
AI 修好的代码,一定要仔细审查。
不要以为"测试通过了"就万事大吉。
2. 明确告诉 AI 你的要求
在提示词中明确要求"最小化修改"、"只修改必要的部分",可以提高 AI 的编辑精度。
3. 理解 AI 的局限性
AI 擅长生成,但不擅长精准修改。
对于重要的代码修改,可能还是需要人工介入。
总结
AI 模型在调试时倾向于重写代码,而不是精准修复;
单元测试通过率高不代表调试能力强;
迭代和智能体方法并不能提高编辑精度;
我们需要新的评估方法来衡量 AI 的调试能力。
也许各大模型厂家下一步可以朝这个方向改进。
下次当你让 AI 帮你修 bug 的时候,记得多看一眼它改了什么,可能它又在偷偷重写你的代码了!
你有没有类似的遭遇,欢迎评论区留言。
论文:https://arxiv.org/abs/2604.17338
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号