使用DeepSeek V4 重构项目,只用了3块钱

使用DeepSeek V4 重构项目,只用了3块钱

灬沙师弟
发布于 2026-05-14 17:18:56
发布于 2026-05-14 17:18:56
当1000万上下文只花3块钱
在AI行业普遍还在为每百万token几美元的价格争吵时,DeepSeek V4系列直接用一张账单,把“大模型很贵”的固有认知砸得粉碎。
最近我使用deepseek v4重构我的物联网网关项目
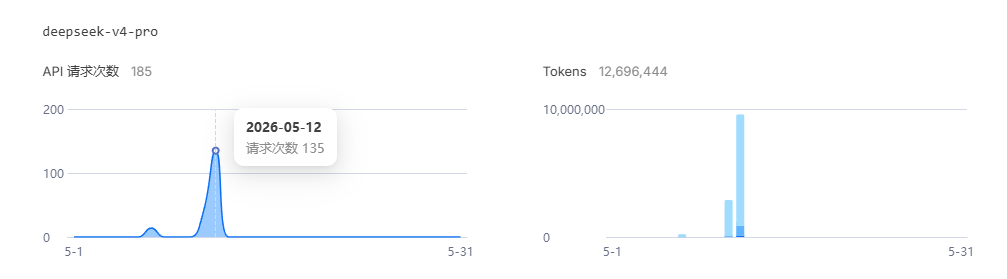
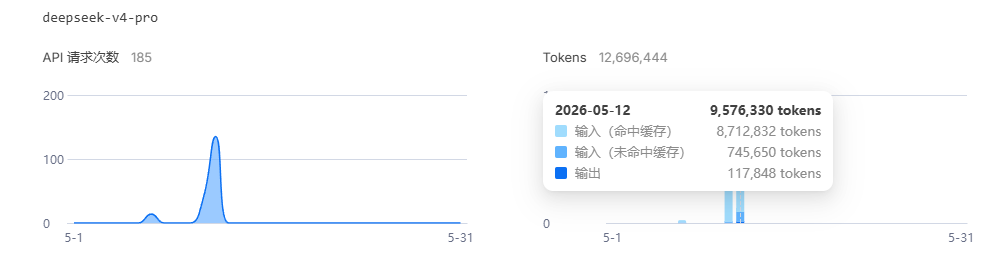
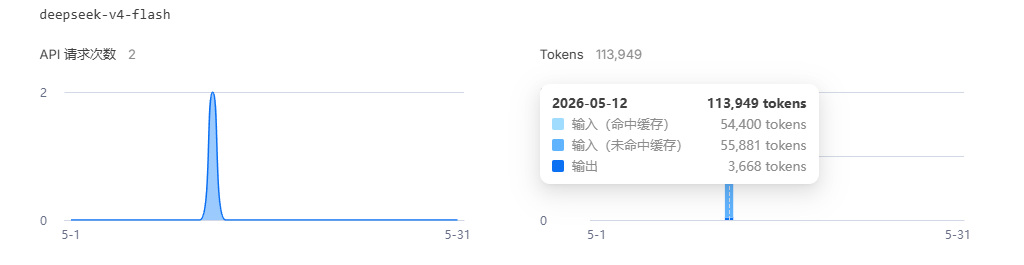
2026年5月12日,调用DeepSeek V4 Pro处理近1000万tokens的输入(其中870万来自缓存复用),加上11万多的输出token,最终花费仅3.16元;同期的V4-Flash处理11万多tokens,花费也仅0.06元。
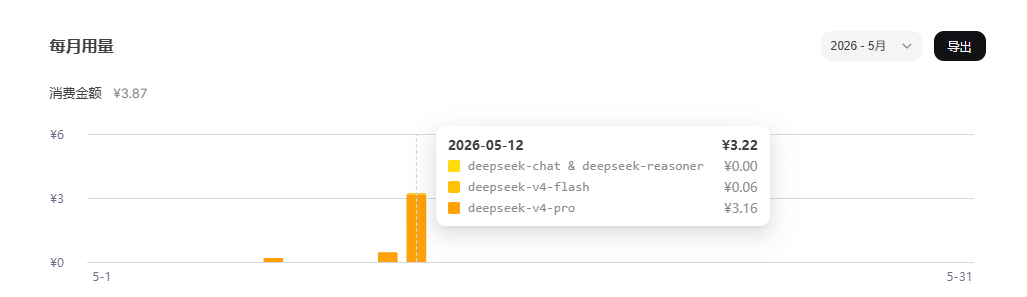
这不是实验室里的理想数据,而是真实业务场景下的账单——DeepSeek V4真正做到了“把百万级上下文的成本压到了白菜价”。
一、先算一笔明白账:
你的AI成本,被DeepSeek砍到了几分之一?
DeepSeek V4系列的价格优势,从来不是“打个八折”这种小打小闹,而是直接重构了成本结构。我们先把官方定价和你的账单数据结合起来,看看到底有多夸张:
模型版本 | 输入(缓存未命中) | 输入(缓存命中) | 输出 | 你的账单对应成本(百万tokens) |
|---|---|---|---|---|
DeepSeek-V4-Flash | 1元/百万tokens | 0.2元/百万tokens | 2元/百万tokens | 0.06元(11.4万tokens) |
DeepSeek-V4-Pro(限时特惠) | 3元/百万tokens | 0.1元/百万tokens(限时0.025元) | 6元/百万tokens | 3.16元(957万tokens) |
数据说明:V4-Pro的957万tokens里,871万来自缓存命中,仅74万多为未命中部分,按0.025元/百万的限时价计算,输入成本仅约0.02元;加上11.7万输出token的成本,最终合计3.16元,完美验证了定价的真实性。
横向对比行业竞品,差距更是触目惊心:
- 同样是旗舰级模型,GPT-4系列的输入价格约为DeepSeek V4 Pro的10倍以上,Claude 3 Opus更是达到了20倍;
- 轻量模型赛道,DeepSeek V4-Flash的价格仅为GPT-4o Mini的1/5,Gemini Flash的1/7;
- 而缓存命中的定价,直接让DeepSeek V4的成本比同类模型低出两个数量级——当别人为每百万token付几美元时,你只需要付几分钱。
这种价格差,带来的不是“省一点”,而是业务模式的根本改变:过去不敢想的“全量代码仓库分析”“百万字知识库实时对话”“7×24小时Agent持续运行”,现在都成了普通人也能负担的选项。
二、便宜不是靠“减配”,而是用技术重构成本逻辑
很多人会下意识觉得“便宜没好货”,但DeepSeek V4的低价,恰恰是建立在技术突破之上的,其中最核心的就是上下文缓存技术。
你账单里的871万缓存命中token,就是这项技术的最好证明:
- 它不是“重复请求不收费”,而是真正复用了计算结果:DeepSeek V4把用户的系统提示词、知识库上下文、对话历史等稳定前缀,缓存在分布式硬盘阵列中。当新请求的前缀和缓存匹配时,模型不需要重新计算这些token的注意力,直接复用结果。
- 成本差不是几倍,而是几十倍:缓存命中时,V4-Pro的输入价格低至0.025元/百万tokens,和未命中的3元/百万tokens相比,成本直接下降了**99%**。这意味着,只要你的业务存在重复的上下文(比如固定的系统提示词、反复调用的知识库),成本就能被压到可以忽略不计。
- 技术普惠不是口号,而是让长尾场景活起来:过去,AI成本决定了只有大厂能玩得起复杂Agent和长文本处理;现在,一个个人开发者、小团队,也能在DeepSeek V4上跑起百万级上下文的应用,而不用担心月底账单爆炸。
除了缓存技术,DeepSeek V4的模型架构优化也功不可没:V4-Pro采用的MoE架构,在保证推理性能的同时,大幅降低了单次请求的计算开销;V4-Flash则通过蒸馏和优化,实现了更低的延迟和更高的吞吐量,进一步摊薄了单位成本。
三、从“能用”到“敢用”:低价正在重塑AI的使用边界
DeepSeek V4的低价,正在从根本上改变开发者和企业使用AI的方式:
- 长文本处理不再是奢侈品:过去,处理100万字的文档,仅输入成本就要几十上百元;现在,用DeepSeek V4-Pro,即使不依赖缓存,成本也不到3元。这让论文分析、法律文档审查、小说续写等场景,真正实现了“按次计费,毫无压力”。
- Agent和自动化业务的成本被打穿:一个需要持续运行、不断调用知识库的AI Agent,过去每月成本可能要几百上千元;现在,依赖DeepSeek V4的缓存复用,成本可以降到几十元,甚至更低。
- 个人开发者的创业门槛被彻底拉低:不用再担心“用户多了就付不起API费”,也不用再为了控制成本而阉割功能。DeepSeek V4的价格,让开发者可以把全部精力放在产品本身,而不是和成本焦虑作斗争。
更重要的是,这种低价不是“赔本赚吆喝”的限时活动,而是DeepSeek基于自身技术栈和基础设施优化,给出的长期定价。当行业里还在为“降本增效”喊口号时,DeepSeek已经用实际账单,让所有人看到了大模型成本的真实底线。
四、价格战的终点,是普及AI的起点
DeepSeek V4的低价,从来不是简单的“价格战”,而是一场关于AI使用成本的“认知革命”。
它用一张3块钱的账单告诉所有人:大模型的成本,本就不该是天价;AI服务,不该只是大厂的专利。
未来,当更多开发者用上DeepSeek V4,当更多普通人能负担得起百万级上下文的AI服务,我们会发现,真正的AI普惠时代,不是靠补贴堆出来的,而是靠技术把成本打下来的。
而DeepSeek V4,正是这场革命里,最响亮的一枪。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号