Python 能干的 Agent,Go 一样行

Python 能干的 Agent,Go 一样行

王中阳AI编程
发布于 2026-05-19 12:02:54
发布于 2026-05-19 12:02:54
AI Agent 爆发已经两年了,各种框架和应用百花齐放。但如果你留意技术社区的讨论,会发现一个尴尬的现实:一提到 Agent 开发,默认就是 Python。LangChain、LlamaIndex、AutoGen……清一色 Python 生态,Go 开发者仿佛被排除在了这场技术浪潮之外。
有人甚至开始质疑:Go 是不是不适合做 AI?
我不这么认为。恰恰相反,Go 的高性能、强类型、出色的并发模型,正是 Agent 落地生产环境的天然优势。Python 写 Demo 很快,但到了企业级高并发场景,部署稳定性、类型安全、并发处理这些短板就会暴露。Go 缺的不是能力,而是一个成熟的 Agent 编排框架。
所以当我们看到字节跳动开源了 Eino(基于 CloudWeGo 的 AI 应用框架)之后,决定做一件事:用 Go + Eino 从 0 到 1 搭建一个完整的、可商用的 AI Agent 平台,用事实说话——Python 能干的 Agent,Go 一样行。
这篇文章,就是我们整个搭建过程的架构复盘。
二、项目概览:面试吧——AI 模拟面试平台
面试吧是一个智能 AI 模拟面试平台。用户上传简历(PDF),AI 面试官根据简历内容进行多轮专业提问,并在面试结束后生成详细的评估报告。
- 在线体验地址:http://mianshiba.dayu.club/
- 核心功能:简历解析、专项面试、综合面试、RAG 知识库检索、多轮对话、流式响应、评估报告生成。
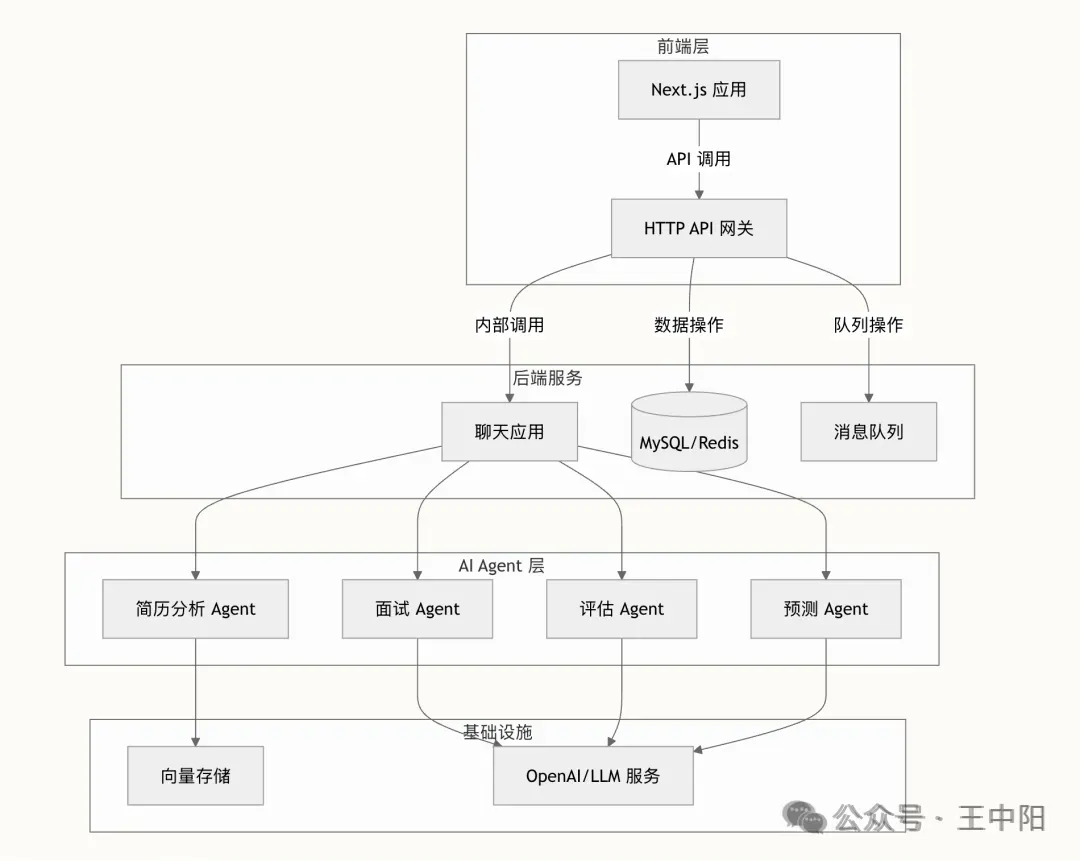
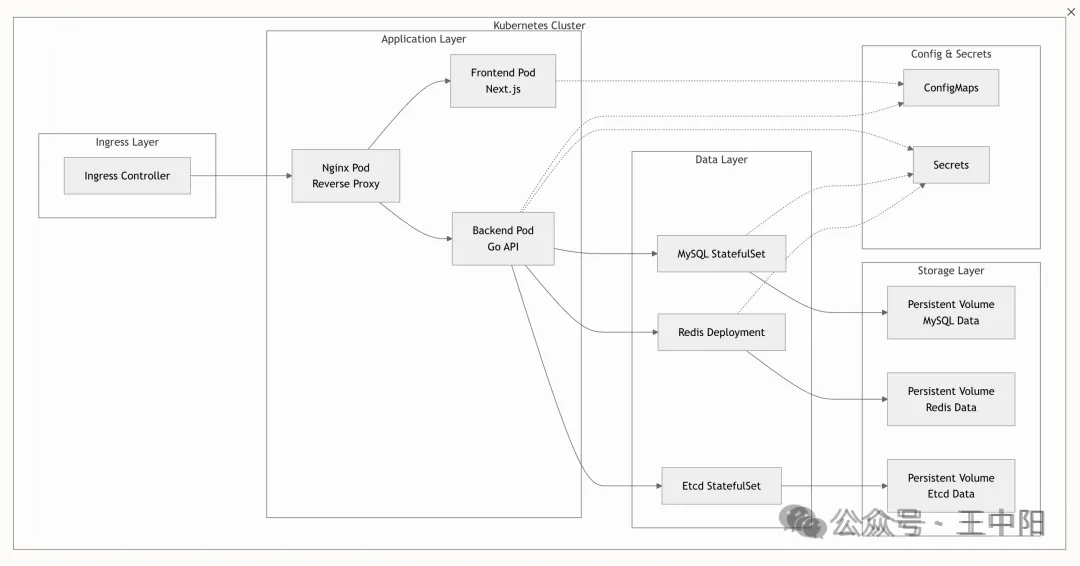
这不是一个玩具项目,而是一个包含前端、后端、数据库、向量库、消息队列的完整分布式系统。
三、整体架构设计
3.1 技术选型
模块 | 技术选型 | 选型理由 |
|---|---|---|
语言 | Go (Golang) | 高并发、高性能、强类型,天然适合后端服务 |
Agent 框架 | Eino (CloudWeGo) | 字节跳动开源,Go 原生的图编排与智能体构建框架,与 Hertz 等生态无缝集成 |
Web 框架 | Hertz | 字节跳动开源,超高性能 HTTP 框架,CloudWeGo 生态成员 |
RPC/IDL | Thrift | 接口定义语言,规范前后端契约,自动生成强类型代码 |
向量数据库 | Milvus | 企业级向量检索引擎,支持标量过滤的混合检索,适合大规模知识库 |
消息队列 | Redis Queue | 轻量级异步解耦方案,项目体量下无需引入 Kafka 的复杂度 |
前端 | Next.js (React) | 现代化全栈前端框架,SSR 支持提升首屏体验 |
3.2 选型中的几个关键决策
为什么选 Eino 不选 LangChain-Go?
LangChain 的 Go 版本长期处于社区维护状态,API 设计是对 Python 版的"翻译",在 Go 的工程实践上水土不服。Eino 是 Go 原生设计的,Graph 编排模型更贴合 Go 的接口和组合思想,而且与 CloudWeGo 生态(Hertz、Kitex)天然集成。
为什么选 Milvus 不选 Chroma?
Chroma 更偏研究原型,生产级的标量过滤和分布式部署能力不足。Milvus 支持向量相似度 + 标量字段过滤的混合检索,这在面试场景中很关键——我们既要语义匹配,也要按技能领域精确筛选。
为什么用 Redis Queue 而不上 Kafka?
AI 推理任务的异步化用消息队列解耦是合理的,但项目当前体量不需要 Kafka 的分布式分区和 Exactly-Once 语义。Redis Queue 足够应对,且运维成本极低。架构要服务于业务阶段,过度设计也是一种浪费。
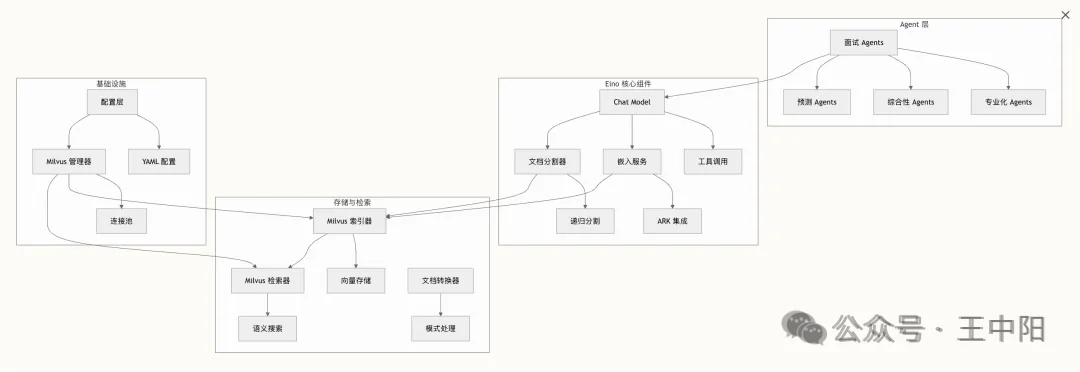
四、核心技术实现
4.1 Eino Graph 编排:Multi-Agent 协作
这是整个项目最核心的部分。面试流程本质上是一个多步骤、有条件分支的决策流程,非常适合用 Graph 编排来建模。
面试流程的 Graph 设计:
用户上传简历 → 简历解析(Tool) → 路由判断 → 专项面试/综合面试 → 多轮提问 → 评估报告生成
Eino 的 Graph 模式允许你将每个步骤定义为一个 Node,通过 Edge 定义流转逻辑,通过 Branch 实现条件路由。这种方式比硬编码的 if-else 链清晰得多,也比传统状态机更灵活。
Multi-Agent 的设计思路:
我们实现了两类 Agent:
- 专项面试官(
agent/interview/specialized/):Go、Java、MySQL、Redis 等 5+ 个专业领域的垂直 Agent,各自维护独立的 System Prompt 和知识上下文,针对不同技术栈的深度提问。 - 综合面试官:基于 ReAct 范式的综合能力评估 Agent,在多个维度(项目经验、系统设计、沟通表达)上进行综合评价。
Agent 之间的上下文传递是关键难点。我们通过 Eino 的 State 机制在 Graph 的不同 Node 之间共享面试上下文(已提问的问题、候选人的回答摘要、评分中间态),确保每个 Agent 都能感知完整的面试进程。
Tool Use 的集成:
Agent 在面试开始时会自动调用简历解析工具(tool/get_resume_info_tool.go),提取候选人的技能标签、项目经历、教育背景等结构化信息,作为后续提问的策略依据。
// Eino Graph 编排的核心逻辑(简化示意)
graph := compose.NewGraph[Map, Map]()
graph.AddNode("parse_resume", resumeParseNode)
graph.AddNode("route_interview", routeNode)
graph.AddNode("specialized_interview", specializedInterviewNode)
graph.AddNode("comprehensive_interview", comprehensiveInterviewNode)
graph.AddNode("generate_report", reportNode)
graph.AddEdge(compose.START, "parse_resume")
graph.AddEdge("parse_resume", "route_interview")
graph.AddBranch("route_interview", compose.NewBranch(...))
graph.AddEdge("specialized_interview", "generate_report")
graph.AddEdge("comprehensive_interview", "generate_report")
graph.AddEdge("generate_report", compose.END)
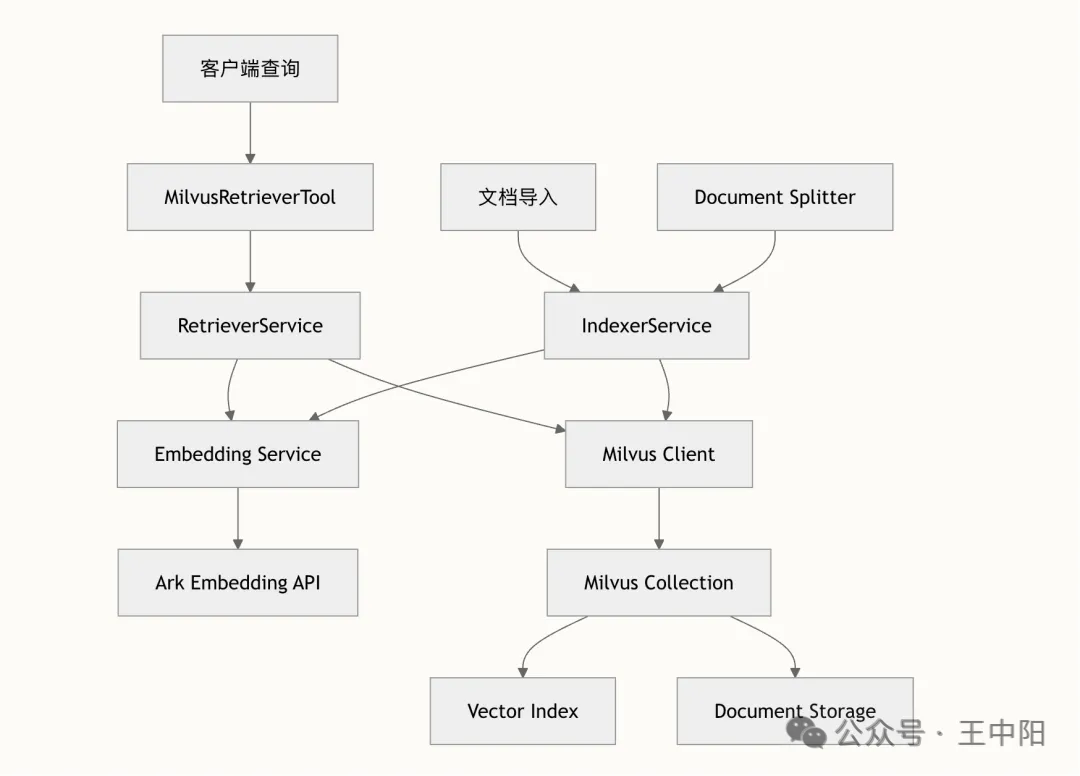
4.2 RAG 引擎:从文档到精准检索
面试官的专业性依赖于知识库的质量。我们搭建了一套完整的 RAG 链路:
ETL 处理:
原始面试题库和技术文档(Markdown/PDF 格式)需要经过解析和清洗,去除无关格式标记,保留语义完整的文本内容。
文档切分策略:
切分粒度直接影响检索效果。太粗会引入噪音,太细会丢失上下文。我们采用基于语义的 Chunking 策略(splitter/),以自然段落和主题段落为切分单元,同时保留必要的上下文窗口。
混合检索实现:
单纯依赖向量相似度检索在面试场景中不够精准。比如候选人问的是"MySQL 索引优化",我们既需要语义匹配相关的面试题,也需要按技术领域(MySQL)进行精确过滤。
Milvus 的混合检索能力正好解决了这个问题(retrieval/retriever.go):
// Milvus 混合检索(简化示意)
results, err := retriever.Search(ctx, milvus.SearchOption{
CollectionName: "interview_knowledge",
Vectors: queryEmbedding,
Expr: "domain == 'mysql'", // 标量字段过滤
TopK: 5,
OutputFields: []string{"question", "answer", "domain", "difficulty"},
})
这种方式有效缓解了大模型的幻觉问题——面试官的提问基于真实知识库内容,而非模型"编造"。
4.3 异步架构:Redis Queue + SSE 流式响应
AI 推理是耗时操作,直接同步调用会阻塞 HTTP 连接,严重影响用户体验和系统吞吐量。我们做了两层优化:
异步任务解耦(mq/redis_queue.go):
用户发起面试请求后,系统将 AI 推理任务投递到 Redis Queue,立即返回任务 ID 给前端。Worker 从队列中消费任务,执行 Agent 编排逻辑,结果通过 SSE 推送给前端。
// 异步任务投递(简化示意)
taskID := uuid.New().String()
err := queue.Push(ctx, Task{
ID: taskID,
Type: "interview",
Payload: interviewPayload,
CreatedAt: time.Now(),
})
SSE 流式响应:
大模型的回答需要一个字一个字地"吐出来",而不是等几十秒后一次性返回。我们实现了 Server-Sent Events,让 AI 的回答像打字机一样流畅展示。
// SSE 流式推送(简化示意)
func (h *Handler) StreamInterview(ctx *app.RequestContext) {
ctx.SetContentType("text/event-stream")
ctx.SetHeader("Cache-Control", "no-cache")
ctx.SetHeader("Connection", "keep-alive")
stream := agent.Stream(ctx, interviewReq)
for chunk := range stream {
ctx.SSEvent("message", chunk)
ctx.Writer.Flush()
}
}
优雅停机与恢复:
服务重启时,正在处理的任务不能丢失。我们在 Worker 退出时将未完成任务重新入队,确保任务不丢、不重复。
4.4 工程基础设施:Thrift IDL + Hertz + JWT
好的架构不仅看核心逻辑,也看基础设施的规范程度。
Thrift IDL 驱动开发:
前后端协作最怕接口定义模糊。我们通过 Thrift IDL 文件(idl/*.thrift)定义清晰的接口契约,自动生成强类型的客户端和服务端代码,杜绝了"字段名拼错"、"类型不匹配"这类低级错误。
Hertz 高性能网关:
作为 CloudWeGo 生态的 HTTP 框架,Hertz 的性能表现和易用性都很出色。我们基于它构建了 API 网关层,承载所有外部请求的路由和鉴权。
JWT 鉴权体系:
完整的 JWT 中间件实现(middleware/jwt.go),包含 Token 签发、校验与续期逻辑。面试过程中的对话数据属于用户隐私,鉴权是必须做扎实的。
全局异常处理:
标准化的错误码设计 + Recovery 中间件,确保单个请求的 panic 不会拖垮整个服务,同时返回结构化的错误信息方便前端处理。
五、踩坑与经验总结
在开发过程中踩了不少坑,挑几个有代表性的分享:
1. Eino Graph 的 State 在多 Agent 间传递容易丢失上下文
Eino 的 Graph State 默认是按 Node 隔离的,如果你在专项面试 Agent 中积累了候选人的回答摘要,综合面试 Agent 默认是拿不到的。解决方案是在 Graph 层面维护一个全局 State,在每个 Node 的回调中显式读写共享上下文。
2. RAG 检索的精度调优比想象中难
初版直接用向量相似度检索,结果经常召回不相关的面试题。加入标量过滤后精度大幅提升,但过滤条件太严格又会导致召回不足。最终我们采用了"宽召回 + 精排序"的两阶段策略:先用较大的 TopK 和较宽的过滤条件召回候选集,再用 LLM 做一轮精排,选择最匹配的 2-3 条。
3. SSE 流式响应的边界处理
SSE 看起来简单,但边界情况很多:网络断开后的重连、多轮对话中上下文的流式拼接、Agent 中途调用 Tool 时前端如何展示中间态……这些问题都需要在前端和后端之间定义清晰的协议。我们最终采用了事件类型区分(message/tool_call/done/error),让前端能针对不同事件类型做不同的渲染逻辑。
4. 异步任务的幂等性保障
Redis Queue 本身不保证 Exactly-Once 语义。Worker 在处理任务时如果崩溃重启,任务可能被重复消费。我们在任务执行逻辑中加入了幂等性校验——基于任务 ID + 状态字段判断是否已处理过,避免重复执行 AI 推理。
踩坑远不止这些,上面只是挑了几个最有代表性的。如果你也在做类似的项目,不想自己踩一遍这些坑,可以翻到文末扫码获取我们的完整源码和内部辅导,少走很多弯路。
六、写在最后
这个项目从构思到上线,前后花了数月时间。过程中最大的收获不是某个具体的技术点,而是对 AI Agent 工程化的整体理解——从 Graph 编排到 RAG 链路,从异步架构到工程规范,每一层都有它自己的复杂度。
Go 在 AI 工程化上的优势是实打实的:高并发、强类型、部署简单。配合 Eino 这样的框架,Go 开发者完全可以在 Agent 赛道上和 Python 生态掰掰手腕。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号