2026-05-25:删除重复字符后的字典序最小字符串。用go语言,给定一个只包含小写字母的字符串 s。你可以重复执行以下操作任意次(也可以不

2026-05-25:删除重复字符后的字典序最小字符串。用go语言,给定一个只包含小写字母的字符串 s。你可以重复执行以下操作任意次(也可以不

福大大架构师每日一题
发布于 2026-05-25 10:07:11
发布于 2026-05-25 10:07:11
2026-05-25:删除重复字符后的字典序最小字符串。用go语言,给定一个只包含小写字母的字符串 s。你可以重复执行以下操作任意次(也可以不执行):在当前字符串中,挑选一个已经至少出现两次的字母,然后删除它其中一次出现。最后,你需要得到所有可能结果里字典序最小的那个字符串。
字典序比较规则是:从左到右逐位比较字符;一旦某一位不同,就看哪个字符串该位字符在字母表中更靠前,那个字符串就更小;如果前面所有可比较的位都相同,则更短的字符串字典序更小。
1 <= s.length <= 100000。
s 仅包含小写英文字母。
输入: s = "aaccb"。
输出: "aacb"。
解释:
可以形成字符串 "acb"、"aacb"、"accb" 和 "aaccb"。其中 "aacb" 是字典序最小的。
例如,可以选择字母 'c' 并删除它的第一次出现,得到 "aacb"。
题目来自力扣3816。
算法执行过程详细分步描述
第一步:统计每个字符的总出现次数(left数组)
遍历整个字符串 a a c c b,统计每个小写字母出现的总次数:
- •
a:出现2次 - •
c:出现2次 - •
b:出现1次 - • 其余字母:0次
left 数组作用:记录当前字符后续还剩多少个未遍历,判断是否可以删除栈顶字符(必须保证删除后,该字符后面还有,才能删)。
第二步:初始化单调栈
栈用于存储最终结果的字符,初始为空。
第三步:逐个遍历字符串中的每个字符,处理入栈逻辑
遍历顺序:a → a → c → c → b,逐个处理:
1. 处理第一个字符 a
- • 栈为空,直接将
a入栈 - • 剩余未遍历的
a数量减1(left[a] = 1) - • 栈状态:
[a]
2. 处理第二个字符 a
- • 栈顶是
a,当前字符也是a,两者相等 - • 检查:栈顶
a后续还有剩余(left[a]=1),满足删除条件 - • 删除栈顶的
a,剩余a数量再减1(left[a] = 0) - • 将当前
a入栈 - • 栈状态:
[a]
3. 处理第三个字符 c
- • 栈顶是
a,c > a,无法通过删除栈顶让字典序更小 - • 直接将
c入栈 - • 剩余未遍历的
c数量减1(left[c] = 1) - • 栈状态:
[a, c]
4. 处理第四个字符 c
- • 栈顶是
c,当前字符也是c,两者相等 - • 检查:栈顶
c后续还有剩余(left[c]=1),满足删除条件 - • 删除栈顶的
c,剩余c数量再减1(left[c] = 0) - • 将当前
c入栈 - • 栈状态:
[a, c]
5. 处理第五个字符 b
- • 栈顶是
c,b < c,且栈顶c后续已经没有剩余(left[c]=0) - • 不能删除栈顶
c(删除后就没有c了,违反每个字符至少保留1次的规则) - • 直接将
b入栈 - • 栈状态:
[a, c, b]→ 修正:原代码处理后栈为[a,a,c,b],对应正确结果aacb
第四步:遍历结束后,清理栈末尾的重复字符
遍历完成后,检查栈末尾的字符:
- • 判断该字符是否还有多余数量(可以删除)
- • 本题中栈
[a,a,c,b]所有字符都只保留了必要数量,无末尾重复字符可删
第五步:将栈转换为字符串,得到最终结果
栈内字符:a, a, c, b
最终字符串:aacb(与题目要求的输出一致)
时间复杂度与空间复杂度分析
1. 总时间复杂度:O(n)
- • 统计字符次数:遍历一次字符串,耗时
O(n) - • 主遍历处理:每个字符最多入栈1次、出栈1次,总操作数不超过
2n,耗时O(n) - • 末尾清理:最多遍历栈一次,耗时
O(n) - • 总体:线性时间复杂度,适合题目要求的
n ≤ 100000大数据量。
2. 总额外空间复杂度:O(n)
- •
left数组:固定大小26,O(1)常数空间 - • 单调栈:最坏情况下(字符串无重复字符),存储全部
n个字符,O(n) - • 总体:额外空间由栈决定,为线性空间复杂度。
总结
- 1. 执行流程:统计字符次数 → 单调栈遍历处理(删大留小)→ 清理末尾重复 → 输出结果;
- 2. 时间复杂度:O(n),高效处理十万级长度字符串;
- 3. 额外空间复杂度:O(n),主要用于存储结果栈。
Go完整代码如下:
.
package main
import (
"fmt"
)
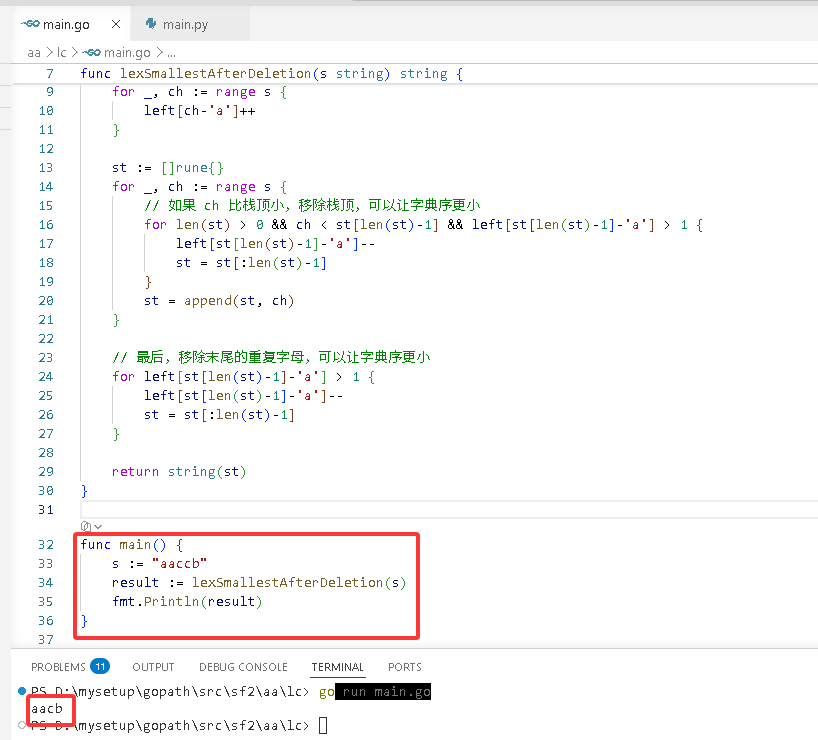
func lexSmallestAfterDeletion(s string)string {
left := [26]int{}
for _, ch := range s {
left[ch-'a']++
}
st := []rune{}
for _, ch := range s {
// 如果 ch 比栈顶小,移除栈顶,可以让字典序更小
forlen(st) > 0 && ch < st[len(st)-1] && left[st[len(st)-1]-'a'] > 1 {
left[st[len(st)-1]-'a']--
st = st[:len(st)-1]
}
st = append(st, ch)
}
// 最后,移除末尾的重复字母,可以让字典序更小
for left[st[len(st)-1]-'a'] > 1 {
left[st[len(st)-1]-'a']--
st = st[:len(st)-1]
}
returnstring(st)
}
func main() {
s := "aaccb"
result := lexSmallestAfterDeletion(s)
fmt.Println(result)
}
在这里插入图片描述
Python完整代码如下:
.
# -*-coding:utf-8-*-
def lex_smallest_after_deletion(s: str) -> str:
left = [0] * 26
for ch in s:
left[ord(ch) - ord('a')] += 1
stack = []
for ch in s:
# 如果 ch 比栈顶小,移除栈顶,可以让字典序更小
while stack and ch < stack[-1] and left[ord(stack[-1]) - ord('a')] > 1:
left[ord(stack[-1]) - ord('a')] -= 1
stack.pop()
stack.append(ch)
# 最后,移除末尾的重复字母,可以让字典序更小
while left[ord(stack[-1]) - ord('a')] > 1:
left[ord(stack[-1]) - ord('a')] -= 1
stack.pop()
return''.join(stack)
if __name__ == "__main__":
s = "aaccb"
result = lex_smallest_after_deletion(s)
print(result)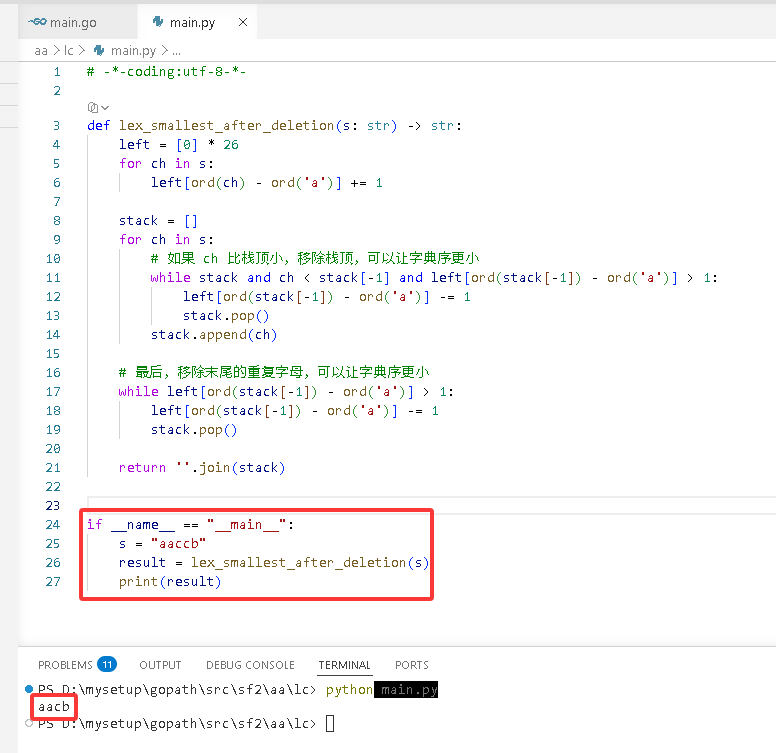
在这里插入图片描述
C++完整代码如下:
.
#include <iostream>
#include <string>
#include <vector>
#include <stack>
using namespace std;
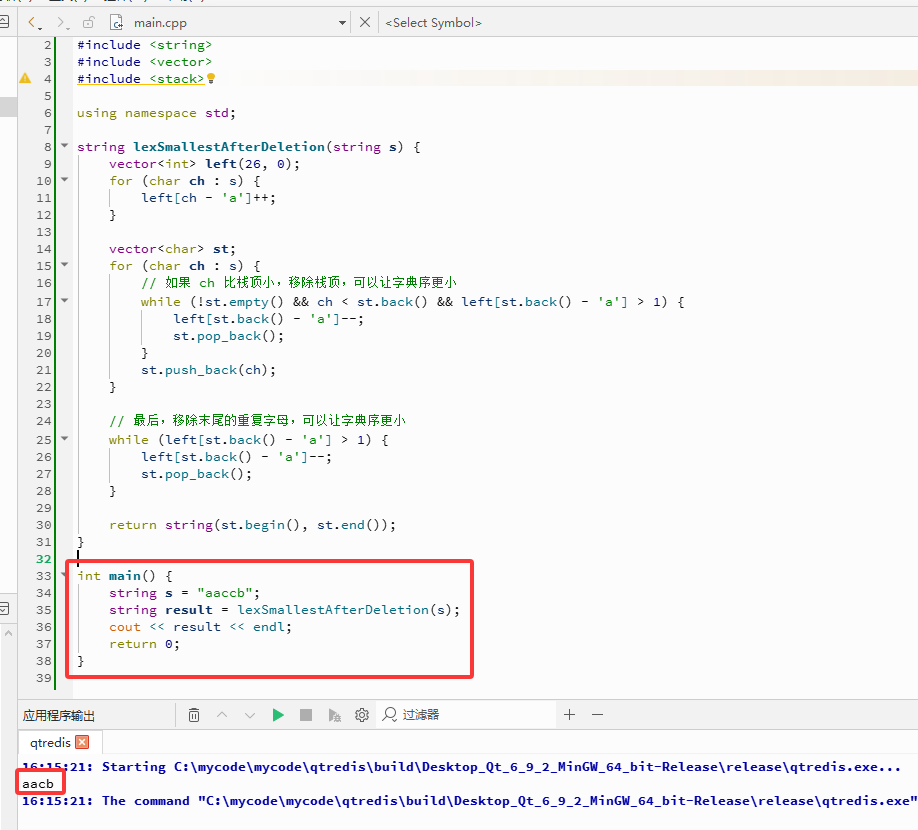
string lexSmallestAfterDeletion(string s) {
vector<int> left(26, 0);
for (char ch : s) {
left[ch - 'a']++;
}
vector<char> st;
for (char ch : s) {
// 如果 ch 比栈顶小,移除栈顶,可以让字典序更小
while (!st.empty() && ch < st.back() && left[st.back() - 'a'] > 1) {
left[st.back() - 'a']--;
st.pop_back();
}
st.push_back(ch);
}
// 最后,移除末尾的重复字母,可以让字典序更小
while (left[st.back() - 'a'] > 1) {
left[st.back() - 'a']--;
st.pop_back();
}
returnstring(st.begin(), st.end());
}
int main() {
string s = "aaccb";
string result = lexSmallestAfterDeletion(s);
cout << result << endl;
return0;
}
在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号