YOLO-IOD:面向实时增量目标检测的研究
原创

本文核心贡献如下:
1)问题剖析:首次系统识别YOLO增量检测中三大知识冲突——前景-背景混淆、参数干扰与知识蒸馏错位。
2)模块创新:提出CPR(伪标签细化)、IKS(核选择)与CAKD(非对称蒸馏)三模块,协同缓解灾难性遗忘。
3)基准构建:发布LoCo COCO新基准,消除阶段间图像重叠并考虑类别共现,实现更真实评估。
4)性能领先:在COCO及LoCo COCO上达到SOTA,保持实时推理速度,验证了框架的有效性与实用性。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
0.原理介绍

论文:https://openreview.net/pdf?id=C33Mhxs9ve
摘要:当前的增量目标检测方法主要依赖于Faster R-CNN或DETR系列检测器;然而,这些方法并不适用于实时的YOLO检测框架。本文首先识别了导致基于YOLO的增量检测器出现灾难性遗忘的三种主要类型的知识冲突:前景-背景混淆、参数干扰和知识蒸馏错位。随后,我们引入了YOLO-IOD,一个实时增量目标检测框架。该框架构建于预训练的YOLO-World模型之上,通过分阶段参数高效微调过程促进增量学习。具体而言,YOLO-IOD包含三个主要组件:1) 冲突感知伪标签细化模块,该模块通过利用伪标签的置信水平并识别与未来任务相关的潜在物体,来缓解前景-背景混淆;2) 基于重要性的核选择模块,该模块在当前学习阶段识别并更新与当前任务相关的关键卷积核;3) 跨阶段非对称知识蒸馏模块,该模块通过将学生目标检测器的特征经由先前和当前教师检测器的检测头进行传递,从而在现有类别和新引入类别之间实现非对称蒸馏,解决了知识蒸馏错位冲突。我们还引入了LoCo COCO,一个更真实的基准数据集,它消除了跨阶段的数据泄露。在传统基准和LoCo COCO基准上的实验表明,YOLO-IOD以最小的遗忘取得了优越的性能。
本文的伪代码:
算法:YOLO‑IOD 实时增量目标检测训练流程
输入:
预训练模型 M_base (基于 YOLO‑World),
任务序列 T = {T₁, T₂, ..., Tₙ},每个任务 T_t 包含数据集 D_t(仅含当前任务类别 C_t 的标注),
已见类别集 C_{seen} 初始为空,
超参数:核选择比例 K,蒸馏权重 α, β,阈值 δ 等。
输出:检测器 M_n (能够检测所有已见类别 C_{seen} ∪ C_n)
初始化:
M₀ ← M_base
C_{seen} ← ∅
I_hist (历史重要性) 初始化为零向量
对于每个任务 t = 1 到 n:
// ---------- 阶段 1:冲突感知伪标签细化 (CPR) ----------
// 1.1 伪标签生成
使用当前检测器 M_{t-1} 在 D_t 的图像上预测,获得所有检测框。
对于每个图像,将预测结果通过置信度阈值过滤,得到候选伪标签。
// 1.2 增强伪标签损失 (Enhanced Pseudo‑label Loss)
对于每个伪标签 (类别预测 p, 置信度 s):
计算损失 L_cls_pseudo = -|s - p|^γ log(p) + λ·(1-s)^δ·H(ŷ) // 软监督 + 熵正则
// 1.3 聚类未知伪标签 (Clustered Unknown Pseudo Labeling)
构建通用词汇集 V_gen (含常见类别及LLM总结的超类别)
使用 YOLO‑World 在图像上检测,找出所有未标注的物体预测 F。
对 F 中的类别标签进行频率加权的 K‑Means 聚类,得到未知超类别 U。
将 F 中的标签替换为对应的超类别,并替换其文本嵌入为聚类中心。
将这些未知超类别视为伪标签,参与后续蒸馏。
// ---------- 阶段 2:基于重要性的核选择 (IKS) ----------
// 2.1 计算参数重要性 (Fisher 信息)
对于当前模型 M_{t-1} 中的每个卷积核 w_k:
利用当前任务数据 D_t 计算 Fisher 重要性 I_t(w_k) = (1/N_t) Σ_{n=1}^{N_t} (∂log p / ∂w_k)²
结合历史重要性,计算差异重要性 ΔI_t(w_k) = I_t(w_k) - ρ·Σ_{i=1}^{t-1} I_i(w_k)
// 2.2 选择重要核并冻结其余
选择 ΔI_t 最大的前 K% 的卷积核作为可更新核,其余冻结。
初始化学生模型 M_t 为 M_{t-1},但仅允许选中的核参与梯度更新。
// ---------- 阶段 3:跨阶段非对称知识蒸馏 (CAKD) ----------
// 3.1 双教师准备
旧教师:M_{t-1} (冻结)
当前教师:M_s_t (在 D_t 上用当前类别 C_t 训练的基础检测器,冻结)
// 3.2 蒸馏损失计算
对于每个图像,获取学生 M_t 的颈部特征 F_student_neck。
将 F_student_neck 分别送入旧教师和当前教师的检测头,得到跨阶段后头特征。
计算每个空间位置 p 的焦点权重 w_focal(p) = max_j logit_teacher(p,j) // 基于教师最大置信度
分类蒸馏损失 L_cls_kd = Σ_p ||E_teacher(p) - E_student_cross(p)||²₂ · w_focal(p)
回归蒸馏损失 L_reg_kd = Σ_p L_IoU(bbox_teacher(p), bbox_student_cross(p)) · w_focal(p)
总蒸馏损失 L_CAKD = α·L_cls_kd + β·L_reg_kd
// ---------- 阶段 4:联合优化 ----------
总损失 L_total = L_CPR (来自伪标签) + L_CAKD + L_det (原始 YOLO 检测损失)
使用 SGD 优化器更新 M_t 中的可训练参数(仅 IKS 选中的核)
更新历史重要性:I_hist(w_k) += I_t(w_k)
// 训练完成后,M_t 可检测 C_{seen} ∪ C_t
C_{seen} ← C_{seen} ∪ C_t
返回最终模型 M_n1.引言
增量目标检测的目标是在连续任务的学习过程中持续获取新的物体类别,同时保留过去所学类别的知识。尽管近期研究在IOD方面取得了显著进展,但现有方法大多基于Faster R-CNN或DETR等检测器构建。当这些已开发的方法应用于实时的YOLO系列检测器时,由于任务间的知识冲突,它们通常会遭遇泛化性能的显著下降,并且难以保留先前类别的知识。
在本工作中,我们首先将基于YOLO的增量检测器中遗忘的根本原因归结为如图1所示的三种主要类型的知识冲突:1) 前景-背景混淆,即在训练过程中,先前和未来任务中未标注的物体被错误分类为背景。这个问题对YOLO检测器尤为关键,因为它们依赖于诸如Mosaic和MixUp等激进的、假设标注准确的数据增强技术。在IOD设置中,来自伪标签的噪声会被这些增强方法放大,从而损害模型性能。2) 参数干扰。此问题源于不同任务通常依赖于模型内相交的参数子集。针对新任务的更新可能会改变这些共享参数,从而可能破坏先前习得的表示,导致对旧任务的灾难性遗忘。3) 知识蒸馏错位冲突,即教师模型和学生模型针对不匹配的类别分布进行优化,违反了标准知识蒸馏中两个模型共享一致学习目标的核心假设。以在空间网格上进行密集预测而著称的YOLO系列检测器,受到此问题的显著影响。
为克服上
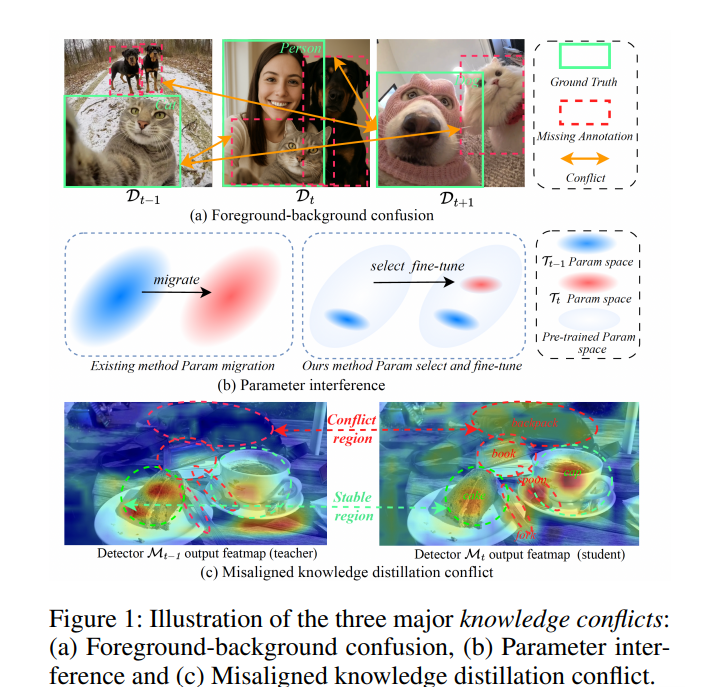
述挑战,我们提出YOLO-IOD,一个实时的IOD框架,它构建于预训练的YOLO-World模型之上,并在每个增量学习阶段执行参数高效的微调。YOLO-IOD包含三个旨在解决已识别知识冲突的主要模块:1) 冲突感知伪标签细化模块,该模块通过整合两种策略来减轻前景-背景混淆:增强伪标签损失,它通过基于预测的置信度和不确定性对来自伪标签的监督进行加权,从而提高其可靠性;以及聚类未知伪标签,它通过执行开放词汇目标检测和特征空间聚类来识别来自未来任务的潜在物体。2) 基于重要性的核选择模块,该模块通过基于Fisher信息差异重要性估计,选择并仅微调与当前任务相关的重要卷积核,从而缓解参数干扰。3) 跨阶段非对称知识蒸馏模块,该模块通过将跨阶段的学生特征同时经由旧教师和当前教师检测器的检测头传递,从而实现新旧类别间的非对称蒸馏,解决了知识蒸馏错位冲突。
此外,当前的IOD基准并不适用于实际应用,因为它们任意划分类别,忽视了类别的自然共现,并且允许图像在增量阶段间重复。在实际场景中,某些类别(如汽车和行人)经常同时出现,而其他类别(如汽车和船只)则不然。必须严格防止阶段间图像重叠,以避免数据泄露。这引发了一个问题:在当前基准上观察到的性能是否能有效转化到现实世界应用中,特别是对于依赖伪标签的近期IOD方法而言。因此,我们引入了LoCo COCO,一个新颖的基准,旨在消除阶段间图像重叠并遵循类别共现统计,为IOD提供一个更公平、更现实的评估基准。
我们的贡献可总结如下:
- 我们引入了YOLO-IOD,一个集成的实时IOD框架,并指出了遗忘的三个原因:前景-背景混淆、参数干扰和知识蒸馏错位冲突。
- YOLO-IOD集成了三个旨在缓解遗忘的创新模块,特别强调了双教师CAKD模块。该模块通过将目标学生检测器的特征经由先前和当前教师检测器的检测头进行传递,从而应对知识蒸馏错位的挑战。
- 我们引入了LoCo COCO,一个实用的基准,旨在消除阶段间的图像重叠并考虑类别共现,从而允许对增量目标检测进行更公平的评估。
- 在传统COCO和LoCo COCO基准上、多种设置下进行的大量实验表明,我们的方法在保持实时推理速度的同时,持续实现了最先进的性能。
2.相关工作
增量学习 增量学习使模型能够在不遗忘先前知识的情况下获取新信息。方法包括基于重演的方法,即重放或生成来自先前任务的样本;基于正则化的方法,通过约束重要参数来维持稳定性;基于架构的方法,分配任务特定的子网络;以及知识蒸馏方法,通过师生学习传递来自过去任务的信息。最近,基于基础模型的持续学习也吸引了许多研究兴趣,包括L2P、CODA-Prompt和VPT-NSP2等方法。
增量目标检测 与分类相比,IOD由于需要同时定位和分类物体,涉及更复杂的场景和更大的挑战。在IOD中,由于检测框架中可用的丰富特征表示和多级监督信号,蒸馏特别有效。弹性响应蒸馏引入了自适应传递知识的弹性响应蒸馏。BPF通过双教师模型桥接过去-未来的知识,CL-DETR在DETR架构内应用蒸馏,强调来自旧模型的可靠预测。然而,这些方法通过仅选择那些不与新标签重合的旧任务输出作为蒸馏目标来处理知识蒸馏问题。这种策略不适用于YOLO风格的密集预测。此外,这种方法只能从教师模型中蒸馏部分知识,未能完全解决潜在的冲突。我们提出了CAKD,它通过利用检测头抑制不相关特征的响应,提供跨阶段非对称知识蒸馏。
预备知识与基准
问题定义 在IOD中,任务按顺序依次到达:T = {T1, T2, ... , Tt, ... , Tn}。每个任务Tt旨在学习一组特定的物体类别Ct,且对于任意i≠j,有Ci ∩ Cj = ∅。对于每个任务Tt,提供了一个数据集:Dt = {(X_i_t, Y_i_t)},其中X_i_t表示第i张图像,Y_i_t是其对应的标注。重要的是,数据集Dt仅针对Ct中的类别进行标注。也就是说,即使图像中存在属于C1:t-1 ∪ Ct+1:n的物体,它们也未被标注。在训练任务Tt期间,只能访问Dt。IOD的目标是在每个阶段训练一个目标检测器Mt,使其能够正确检测来自当前任务类别Ct和所有已见类别C1:t-1的物体。
YOLO-World 开放词汇目标检测使检测器能够在文本输入的指导下识别任意类别。最近的方法如GLIP、Grounding DINO和YOLO-World在大规模视觉-语言数据上学习区域-文本对齐。我们的方法构建于预训练的YOLO-World模型之上。图像由视觉编码器fv处理,类别文本由文本编码器ft处理,特征使用RepVL-PAN进行融合:V, P = fRepVL(fv(I), ft(T)),其中V = {e_k}是区域级视觉嵌入,P = {p_j}是文本原型。分类得分计算为s_k,j = η · ⟨Norm(e_k), Norm(p_j)⟩ + ζ。
LoCo COCO基准 在先前的IOD基准中,每个阶段t通常从完整数据集中选择所有包含Ct类别物体的图像。现实世界的图像经常包含来自各种类别的物体,这意味着单张图像将在多个训练阶段中被使用。根据统计,在20+20 4阶段设置下,每张图像平均出现在1.84个阶段中。这种重叠挑战了持续学习的基本前提,并通过允许检测器在重复使用的训练图像上生成伪标签,人为地夸大了伪标签方法的有效性。
为解决此问题,我们引入了一种新的数据划分协议,称为低共现COCO。我们首先构建一个类别共现矩阵A ∈ R^{N×N},其中A_{ij}表示类别c_i和c_j共同出现的图像数量。该矩阵定义了一个无向加权图G = (V, E),节点为类别,边权重由A_{ij}给出。然后我们对G进行图聚类,将类别集C = {c_1, c_2, ... , c_n}划分为n个阶段的n个不相交子集。这确保了频繁共现的类别被分配到同一个任务中,从而最小化任务间的图像重叠。在上述类别划分之后,仍然存在一部分重叠图像,这些图像包含来自多个阶段的类别。对于每个跨越多个候选类别集的重叠图像I,我们将图像I随机分配给其中一个候选任务。此策略确保每张图像仅出现在一个阶段中,消除了跨阶段的任何数据泄漏。我们提出的LoCo COCO基准与现实世界的IOD场景更好地对齐,并消除了基于伪标签的IOD方法中的评估偏差。
3.方法
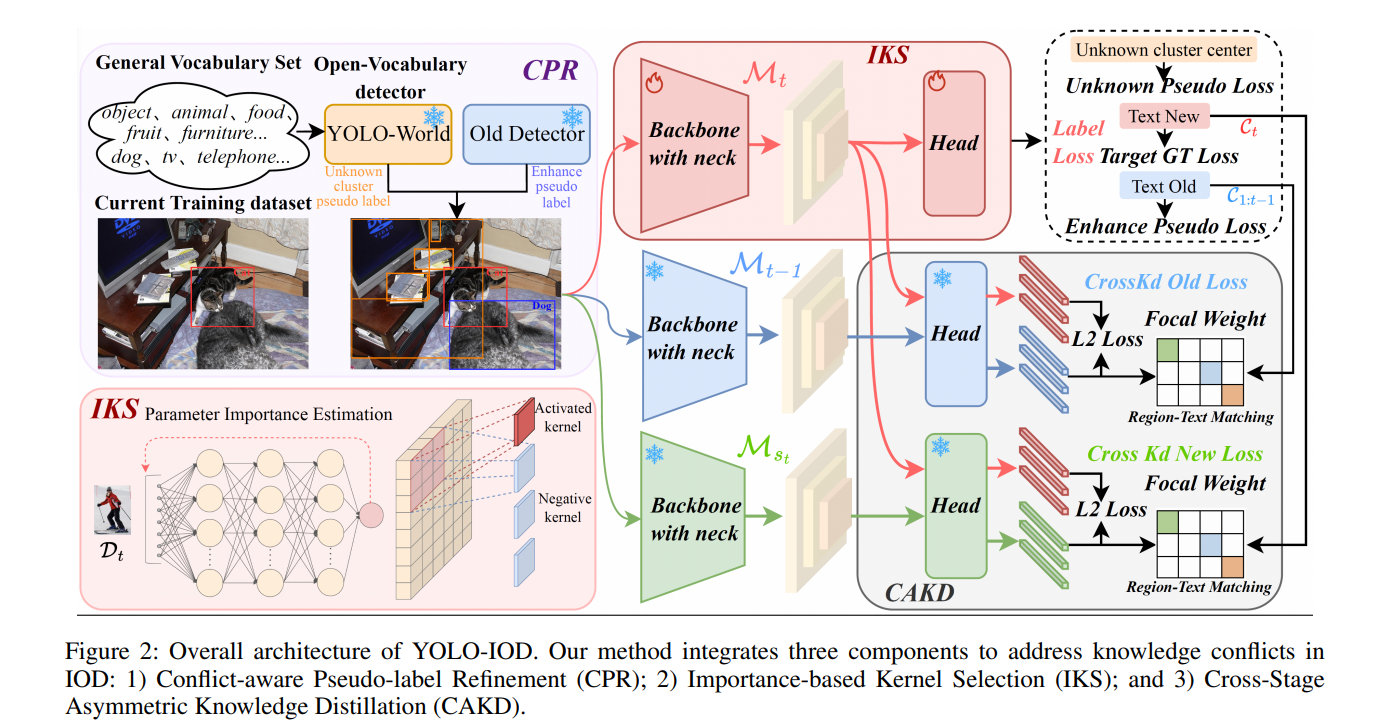
整体框架 所提出的YOLO-IOD利用预训练的YOLO-World作为其基础模型。如图2所示,YOLO-IOD通过分阶段的部分微调来执行增量学习,其中参数更新由基于重要性的核选择所引导。整体架构由三个组件构成。在左上部分,冲突感知伪标签细化模块通过增强的伪标签损失为旧任务生成高质量的监督,以缓解来自先前任务的前景-背景混淆,同时通过聚类未知伪标签来处理未来任务上潜在的前景-背景混淆。在图2的左下部分,基于重要性的核选择模块决定在每个增量阶段更新哪些卷积核,在允许对新类别进行部分微调的同时,保留来自先前任务的关键知识。最后,跨阶段非对称知识蒸馏模块实现了两种不同的知识蒸馏损失。第一种涉及将旧检测器M_{t-1}与目标检测器M_t进行比较,通过将它们各自的密集特征馈送到旧检测器M_{t-1}的检测头中实现。第二种涉及将当前检测器M_{s_t}(在标注了类别C_t的当前阶段数据集D_t上训练的检测器)与目标检测器M_t进行比较,利用当前检测器头内的密集特征。
冲突感知伪标签细化 CPR包含两个组件。增强伪标签损失利用置信度感知的监督以及熵正则化来更好地使用伪标签。同时,聚类未知伪标签结合开放词汇目标检测和特征聚类,为未来任务中未标注的物体提供一致的监督。
增强伪标签损失。IOD中传统的伪标签方法依赖于置信度阈值来选择可靠的伪标签,这引入了基于置信度的选择偏差。这种偏差导致低置信度类别在训练过程中逐渐被忽略。此外,高于阈值的伪标签被统一对待,而未考虑其实际可靠性,导致监督信号不一致。为解决此问题,我们提出了一种增强伪标签损失,它将每个伪标签的置信度分数s视为软监督目标,将置信度感知加权与熵正则化相结合:
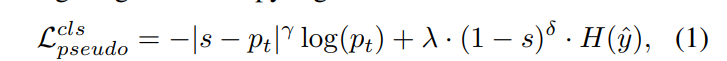
聚类未知伪标签。针对未来任务类别缺失标注的问题,我们提出了聚类未知伪标签方法。我们构建了一个通用词汇集V_gen,包含由大语言模型总结的500个常见物体类别和50个抽象超类别。在每个增量阶段,我们应用YOLO-World,使用V_gen来识别除真实标注之外的所有前景物体。令F表示YOLO-World预测的这些未标注前景物体的集合,C_F ⊆ V_gen表示F的类别标签集。为了将这些预测转化为稳定的未知监督,同时最小化与未来任务的冲突,我们对C_F的文本特征表示f_t(·)执行频率加权的K-Means聚类,其中每个类别的权重与其在F中的出现频率相对应。得到的聚类中心定义了一组未知超类别U = {u_1, u_2, ... , u_K}。然后,我们将F中的每个标签替换为其在U中分配的相应超类别,并在训练期间将其文本嵌入替换为相应的聚类中心。这种方法将源于未标注的未来任务类别的知识冲突转化为一个从未知超类别中发现和学习新类别的过程。
基于重要性的核选择 我们利用基于重要性的参数选择机制来缓解YOLO-IOD中的参数冲突。具体来说,我们在每个增量任务中仅选择和微调重要的卷积核,从而最小化对整体参数分布的干扰。为避免破坏来自先前任务的关键知识,我们通过从当前任务特定的重要性中减去历史重要性来计算差异重要性。
参数重要性估计。我们采用Fisher信息来量化参数重要性,但将其定义在卷积核的粒度上,以保留归纳结构并避免随着任务增加而产生过高的存储成本。给定一个由d_k个标量参数组成的卷积核w_k = {w_k_j},其基于Fisher的重要性可计算为:
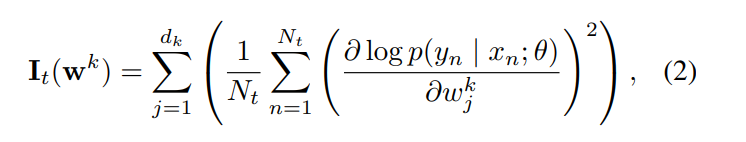
对所有j求和,其中(x_n, y_n)是来自任务T_t的训练样本,θ表示模型参数。为避免干扰先前学习的任务,我们计算差异重要性,其中ρ表示加权因子:
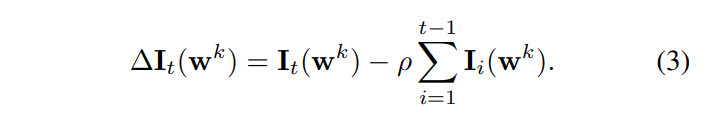
跨阶段非对称知识蒸馏 如图2所示,我们的CAKD模块采用双教师框架,其中目标检测器M_t作为学生。第一个教师是旧检测器M_{t-1},它专精于先前学习的类别C_{1:t-1},主要关注C_{1:t-1}的前景特征,其检测头抑制对无关特征的响应。第二个教师是当前检测器M_{s_t},其特征聚焦于当前阶段类别,同时抑制其他类别的特征。这种跨阶段非对称知识蒸馏设计使目标检测器M_t能够避免任务间的错位监督和特征干扰,同时最大限度地蒸馏和整合新旧类别的知识。
蒸馏过程通过将学生颈部特征F_student_neck传递到教师的检测头,生成跨阶段的检测头后特征。检测头包括分类和回归组件:回归头为每个锚点输出边界框位置,而分类头生成图像编码,这些编码与文本嵌入进行区域-文本匹配以产生分类逻辑值。
我们在整个特征图上全局应用蒸馏损失。为了抑制噪声或背景区域,并聚焦于信息量最大、最可靠的预测,我们为每个空间位置p引入一个焦点权重w_focal(p) = max_j logit_teacher(p, j),该权重基于教师的最大置信度来强调可能的前景区域。
分类蒸馏损失衡量每个位置上教师和学生图像区域编码之间的L2距离,并由焦点因子加权:
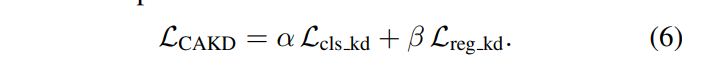
4.实验
实验设置 数据集与指标。为评估我们的方法,我们使用MS COCO 2017数据集,并遵循先前研究建立的评估协议。我们还在提出的LoCo COCO基准上进行评估,以提供更现实的评估。我们使用标准的COCO指标:跨IoU阈值0.5-0.95的mAP、mAP@0.5和mAP@0.75。我们还报告与联合训练相比的AbsGap和RelGap,以量化灾难性遗忘。
实现细节。我们的方法在YOLO-World上实现。我们在4块RTX 3090 GPU上使用批量大小16,学习率设置为2×10^{-5}和2×10^{-4}。训练使用AdamW优化器进行20个轮次,并在第10个轮次后禁用马赛克增强。在IKS模块中,基础阶段选择的核比例K设置为20%,增量阶段设置为12%。
与最先进方法的比较 我们在COCO上的单步和多步IOD设置下评估我们的方法。我们将YOLO-IOD与近期最先进的方法进行比较,包括两阶段检测器、基于DETR的方法,以及基于开放词汇模型构建的方法。此外,我们在YOLO-World架构上复现了经典的基于响应的蒸馏方法ERD和近期的生成式重演方法RGR,以进行进一步比较。
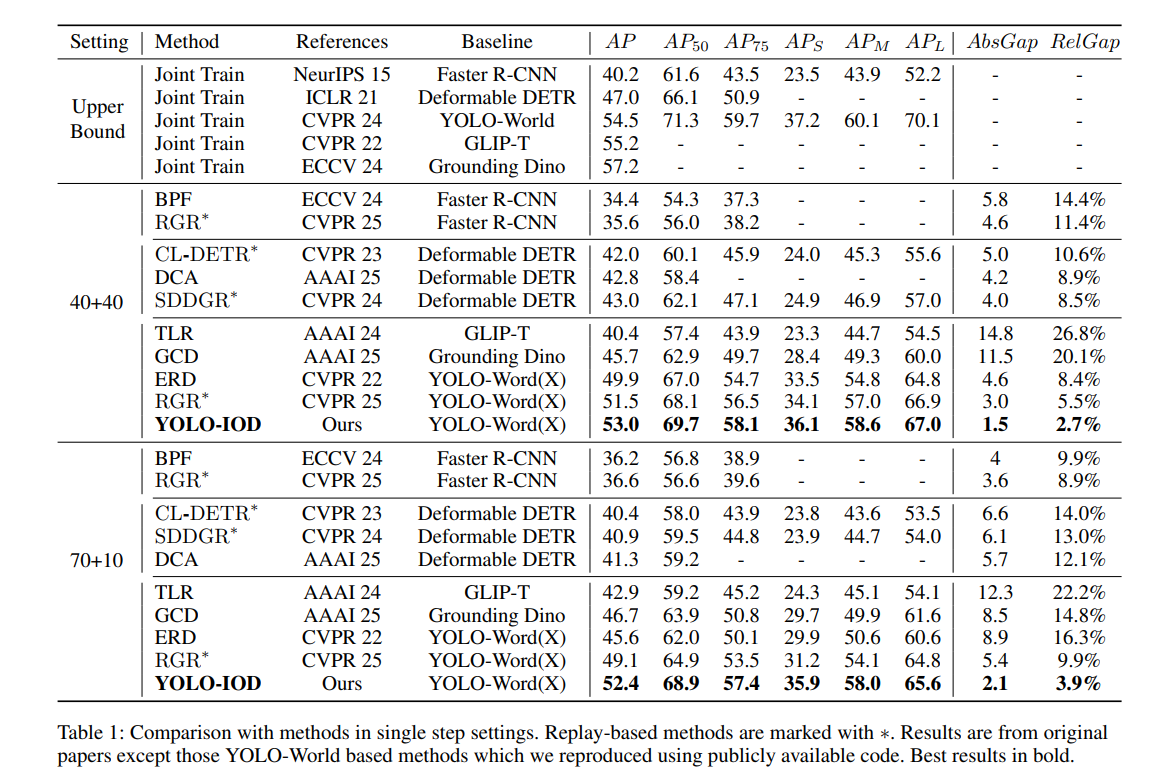
单步增量设置。我们首先评估40+40和70+10设置下的性能,分别添加40类和10类。如表1所示,YOLO-IOD相较于先前方法取得了持续的性能提升。具体而言,在40+40配置下,我们的方法在AP上超过之前最佳方法RGR 1.5%,AbsGap仅为1.5,并将与联合训练的相对性能差距从5.5%大幅降至2.7%。在70+10设置下,YOLO-IOD在AP上优于RGR 3.3%,并实现了与上界相比极低的3.9%的RelGap,同时在所有指标上保持强劲性能。需要注意的是,RGR是一种基于生成式重演的方法,而我们的方法完全不需要重演。
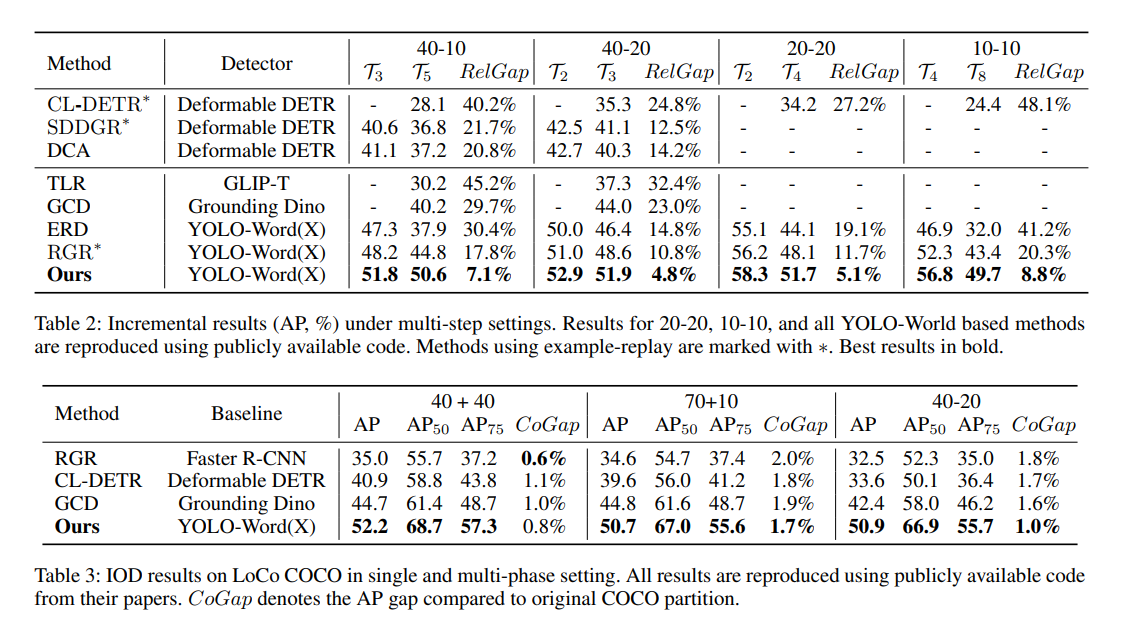
多步增量设置。为了更好地反映新类别不断被引入的现实场景,我们在40-10、40-20设置的基础上,增加了更长的20-20和10-10设置的多阶段评估,即每个阶段分别增量添加20或10个类别,直到学习完所有80个类别。这些更长的配置对于在现实部署场景中评估增量检测器尤为重要。如表2所示,我们的方法在这些长期设置中始终取得最佳性能,相较于RGR的AP提升从3.3%到6.3%不等。值得注意的是,在具有8个增量阶段的挑战性10-10设置下,YOLO-IOD表现出卓越的性能,在最后阶段仅达到8.8%的RelGap,显著优于RGR和CL-DETR。结果表明,YOLO-IOD通过充分解决知识冲突,可以成功适用于需要持续适应新兴物体类别的现实场景。
在LoCo COCO上的评估 我们在更现实的LoCo COCO基准上评估了近期方法和我们的YOLO-IOD,如表3所示。与原始COCO基准相比,所有方法在LoCo COCO上的AP均下降了0.6%到2.0%,这表明了先前增量设置中数据泄露的影响。尽管如此,YOLO-IOD在所有增量场景下始终取得强劲性能,即使在消除了阶段间图像重叠的情况下也表现出鲁棒性。具体而言,在40+40、70+10和40+20设置中,YOLO-IOD分别超过之前最佳方法GCD达7.5、5.9和8.5 AP。这些结果既凸显了YOLO-IOD在现实持续检测中的实用价值,也证明了LoCo COCO作为IOD实用评估基准的必要性。
消融研究
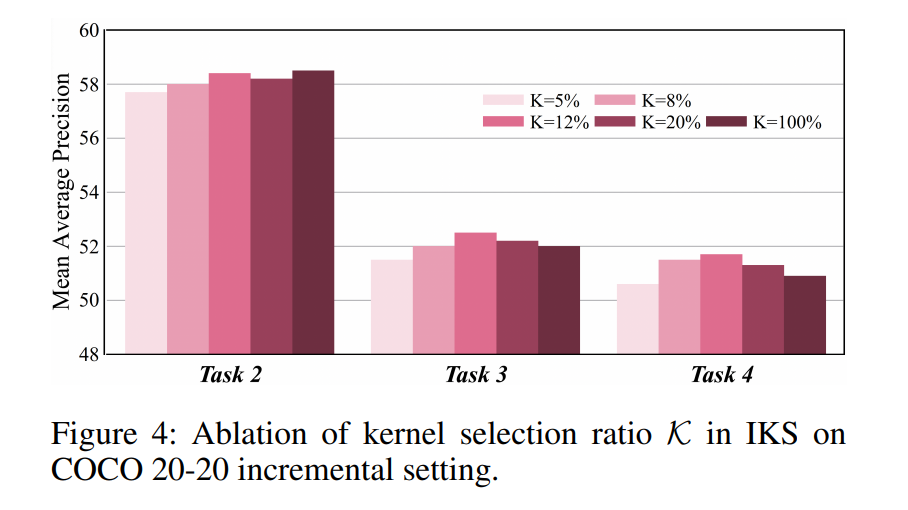
主要组件的有效性。如表4所示,我们逐步添加模块以展示它们在70-10和40-10设置中的各自贡献。从标准的伪标签基线开始,其在70-10上达到48.4% AP,在40-10上达到44.3% AP;添加CPR显著提升了性能,分别达到50.3%和47.3%,证明了其在缓解前景-背景混淆方面的有效性。结合IKS进一步将结果提升至70-10的51.5% AP和40-10的49.1% AP,突显了选择性参数更新的价值。值得注意的是,当单独应用CAKD时,AP从48.4%提升至70-10的50.8%,从44.3%提升至40-10的49.2%,展示了其强大的蒸馏能力。当CAKD与之前的模块结合时,可获得进一步的增益,将AP从70-10的51.5%提升至52.4%,从40-10的49.1%提升至50.6%。这些结果证实了CPR、IKS和CAKD三个组件协同工作,各自贡献显著的性能提升,并共同解决基本的知识冲突。因此,完整的YOLO-IOD框架取得了优越的结果。
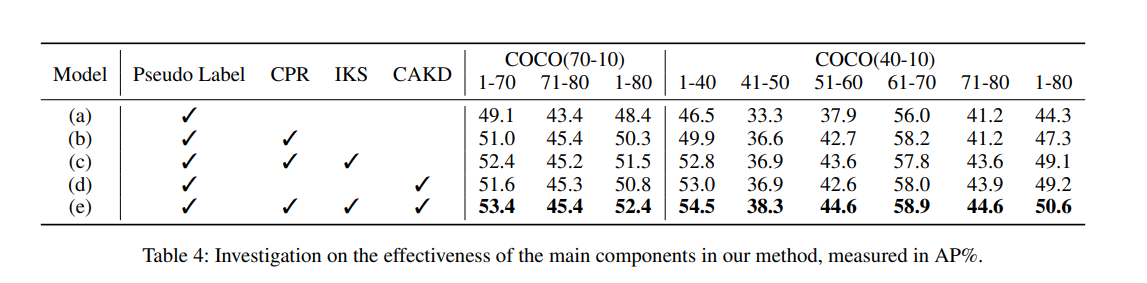
CAKD的消融研究。如图3所示,我们比较了三种CAKD变体:仅使用旧教师检测器、仅使用当前教师检测器,以及完整的双教师。在早期阶段,仅当前变体通过促进对新类别的快速适应而表现更好。随着任务积累,仅旧变体在保留先前知识方面变得更加有效,反映了从可塑性到稳定性的转变。完整的CAKD始终取得最佳结果,验证了结合两种知识来源的非对称蒸馏的优势。
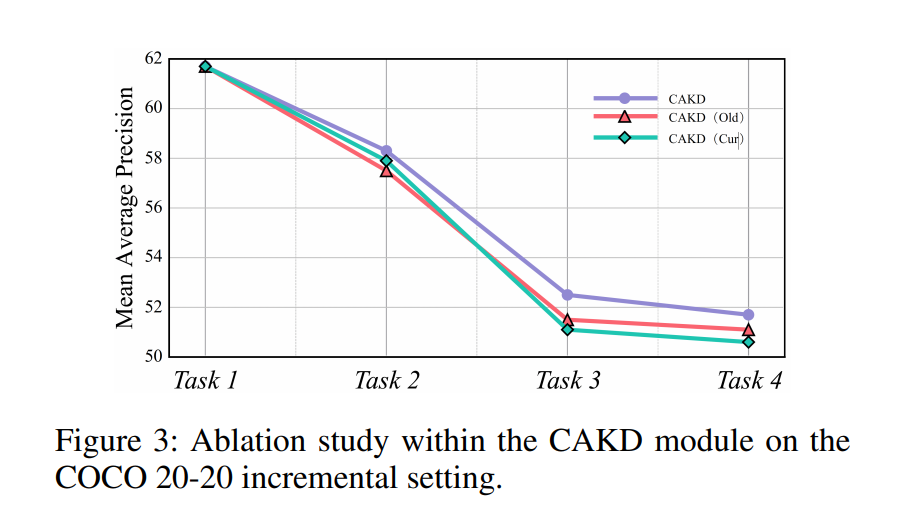
IKS核选择比例K的影响。如图4所示,较小的比例限制了模型的适应能力,而较大的比例由于过度更新参数而导致遗忘。我们观察到,当设置K=12%时,它达到了最佳权衡,这强调了在IOD中调节待更新参数量的重要性。
5.结论
本研究引入了YOLO-IOD,一个新颖的实时IOD框架,它利用预训练的YOLO-World模型。通过部署三个精心设计的模块:冲突感知伪标签细化、基于重要性的核选择和跨阶段非对称知识蒸馏,有效解决了前景-背景混淆、参数干扰和知识蒸馏错位的挑战,YOLO-IOD在保留先前知识和获取检测新类别物体能力之间实现了最佳平衡。此外,我们提出了LoCo COCO基准,它成功缓解了数据泄露问题,并使类别划分与现实世界的共现情况对齐。YOLO-IOD在传统COCO基准和LoCo COCO基准上,在各种单步和多步设置下均显示出卓越的性能。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号