Codex 实践系列 Vol.01:从跑通 CLI 开始,看懂 Codex 怎么工作
原创
Codex 实践系列 Vol.01:从跑通 CLI 开始,看懂 Codex 怎么工作
原创
七牛开发者
发布于 2026-06-05 17:28:00
发布于 2026-06-05 17:28:00
作为 Codex 实践系列的开篇,这里小七先说下我们为什么要做这个系列,以及这个系列的规划。
相比 Claude Code,Codex 对很多人来说有一个很直接的优势:它可以直接使用 ChatGPT 订阅。如果你本来就在用 ChatGPT,那上手成本会低很多。再加上 Codex 这段时间更新很快,后面也会越来越值得关注。
目前,这个系列的规划是:

所以,作为本系列的开篇,我们不聊 Codex 的复杂能力,也不做完整评测。只做一件很基础的事:在本地把 Codex 跑起来,然后让它完成一个边界清楚的小任务。
本文任务
新手开篇,我们只有两个目标:
- 跑起来;
- 让它做个小东西:统计我们的 Codex 余量
为什么先从 CLI 开始
目前,Codex 有几种常见入口:CLI、桌面端和 VS Code 插件。
桌面端更像一个任务工作台,比较适合同时管理多个 Codex 会话的场景。如果你想把不同项目、不同任务分开处理,用桌面端会更直观。
VS Code 插件更贴近日常编码场景。你可以一边看代码,一边让 Codex 帮你解释逻辑、修改代码、补测试。
CLI 则更适合做这篇文章里的第一次实践:进入一个项目目录,启动 Codex,发出任务,然后直接在终端里观察它读了什么、跑了什么命令、生成了什么结果。
所以这一篇,我们先从 CLI 开始。
在 macOS 上安装 Codex
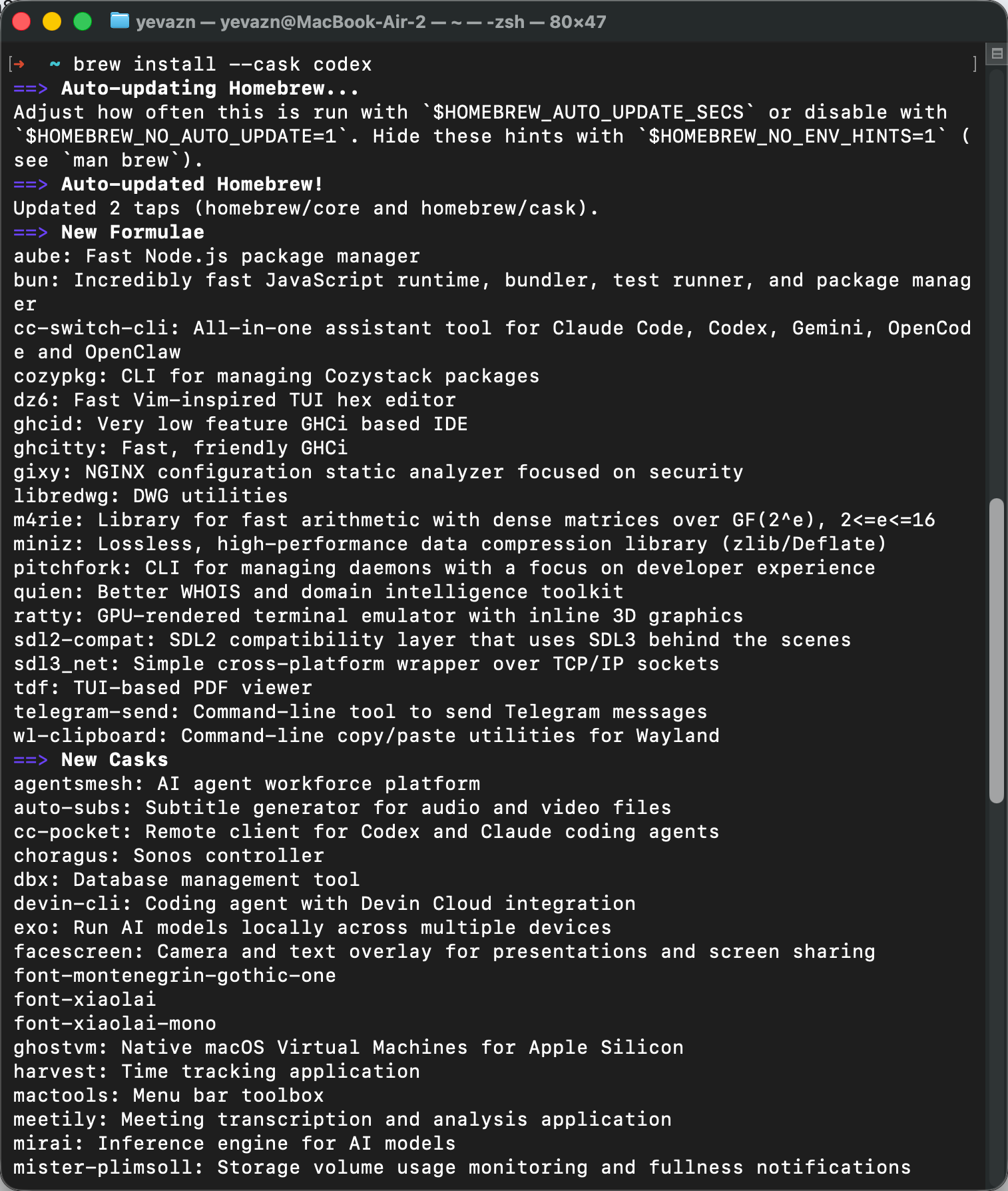
这次我们用的 Homebrew 来安装 Codex,安装命令是:
brew install --cask codex细心的小伙伴可能注意到,上面的命令有一个--cask,并没有直接写成像是下面这样:
brew install codex作为一个插曲,我们来了解下 Homebrew 里常见两种安装方式。
brew install xxx主要用来安装 formula,就是 Homebrew 里的命令行软件包。它一般用来安装命令行工具、依赖库等;brew install --cask xxx主要用来安装 macOS 应用、预编译程序、插件等;
Codex 在 Homebrew 里走的是 cask 路线,就是一个 macOS 应用,所以上面的命令用了 brew install --cask codex。
装完之后,用下面命令查看下版本:
codex --version如果后面 Codex 提醒你升级,或者是你想升级 Codex 版本,可以用下面命令来升级版本:
brew upgrade --cask codex注意,这里我没有走 npm 来安装 Codex,因为 npm 需要本地先有 Node.js / npm 环境。对我来说,在 macOS 上直接用 Homebrew 更省事。
实操命令参考图:

第一次启动
安装完成后,在终端里运行:
codex第一次启动时,会有登录或授权流程。无脑回车就行:
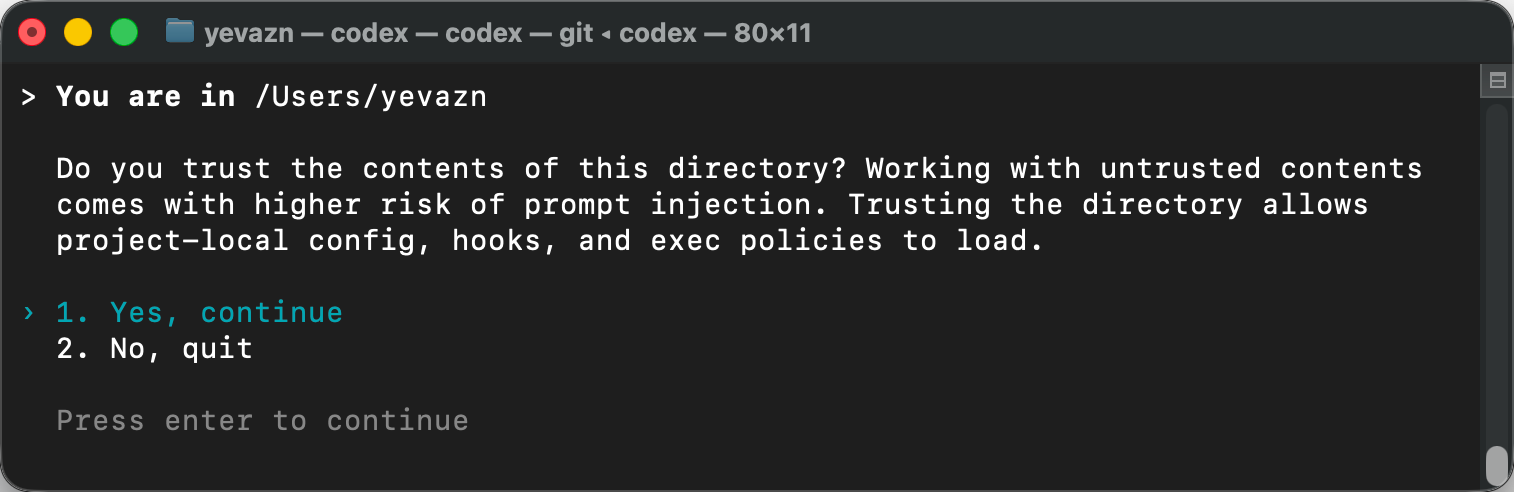
如果你是第一次安装,运行 codex 后一般会进入登录 / 授权流程,按终端提示完成即可。我这里因为之前已经用过 Codex,所以再次启动时没有出现授权页面,而是直接进入了会话。如果你在授权过程中遇到了问题,可以联系小七帮忙解决。
实操前的准备
在正式让 Codex 做事之前,先注意一件事:你在哪个目录里启动 Codex,它就会围绕哪个目录工作。
所以,第一次上手,我不建议直接在真实项目里操作。我们先来创建一个干净的练习目录:
# 创建目录
mkdir codex-usage
# 进入到该目录
cd codex-usage实操参考图:

接下来,我们就在这个干净目录里启动 Codex:
codex实操参考图:
启动后,你会进入 Codex CLI 的交互界面。
使用 Codex 最重要的命令
这个时候,我们先不急着让 Codex 干活。第一次进来,建议先学会一个很重要的命令:/status,它和 Codex 的使用额度有关。
和普通聊天窗口有点不一样,Codex 有自己的使用窗口。这里,你重点记住两个余量指标:
- 5 小时窗口:短周期额度,适合判断接下来几个小时还能不能继续用;
- 1 周窗口:长周期额度,适合判断这一周整体还剩多少。
在 Codex CLI 里查看余量也很简单,直接输入:
/status这个命令会显示当前会话状态,其中就包括当前工作目录、模型信息,以及 Codex 的使用余量。如果你想把余量常驻显示,可以使用 /statusline 命令来配置细节。
实操参考图:
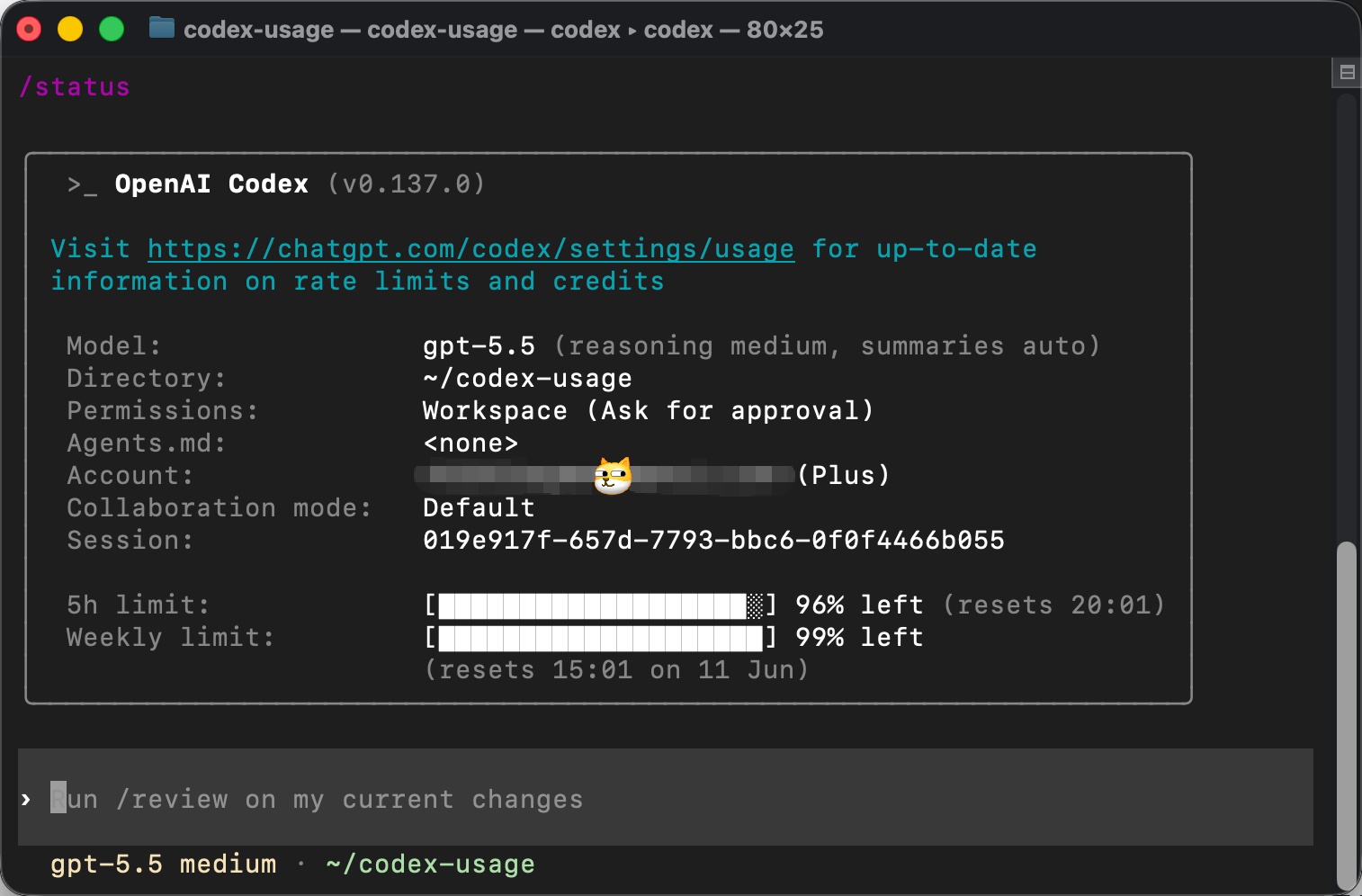
稍微讲解下这张图,其中下面的字段可以重点关注下:
- Model 就是目前使用的模型,及相关设置。上图说明模型用的
gpt-5.5,后面括号里的reasoning medium表示当前推理强度是中间档,summaries auto表示策略由系统自动选择; - Directory:当前 codex 所在的目录;
- Permission:当前权限模式。上图显示的是
Workspace (Ask for approval),可以理解成 Codex 可以在当前工作区里操作,但遇到需要确认的动作时,会先请求用户批准。第一次上手时,这种模式比较适合,因为你可以看到它准备做什么,再决定要不要让它继续。 - Agents.md:当前目录下有没有
AGENTS.md。图里显示<none>,说明这个练习目录里还没有项目规则文件。后面我们会单独讲AGENTS.md,它可以用来告诉 Codex 这个项目的结构、规则和限制。 - Account:当前登录的账号和套餐。图里显示的是当前账号(敏感信息,马赛克了下),以及对应的 ChatGPT 套餐。这个信息可以用来确认 Codex CLI 是否已经正确登录。
- 5h limit:5 小时窗口的余量;
- weekly limit:一周窗口的余量;
不过,/status 只能帮我们看到当前状态。如果你想记录自己一天里、这一周里不同时间点的余量变化,就需要自己手动保存。
所以,接下来,我们就让 Codex 做一个小工具:把每次看到的余量记录到本地。
让 Codex 做一个本地余量记录器
这里我一开始的想法是:能不能做到「每次运行 /status,就自动把这次的 5h limit 和 Weekly limit 记录到 CSV 里」。
这里,我们先要来先确认一件事:/status 是 Codex CLI 交互界面里的命令,不一定能像普通 shell 命令一样,被外部脚本直接调用。
所以,这个小任务的第一步,不是马上写脚本,而是让 Codex 先帮我们验证当前环境里有没有安全、公开的方式拿到这些状态信息。
我们直接把下面这段需求发给 Codex:
请你帮我做一个本地 Codex 余量记录工具。
目标:
我希望尽量实现“一次命令完成查看和记录”。也就是说,运行 record_usage.py 后,脚本会尝试获取当前 Codex CLI 的状态信息,解析 5h limit 和 Weekly limit,并写入 usage_log.csv,同时在终端打印本次余量。
请你先验证当前环境里是否存在安全、公开的方式获取 Codex 状态,例如:
1. 是否存在 codex status / codex usage 这类命令;
2. 是否可以用 codex exec 或其他 CLI 参数拿到 /status 输出;
3. 是否可以通过官方支持的方式读取 statusline 或 usage 信息。
要求:
1. 不要读取或修改 Codex 的登录凭据、配置文件或缓存文件;
2. 不要访问隐藏目录里的 Codex 内部文件;
3. 如果无法安全自动获取 status 信息,请说明原因,并提供一个 fallback 版本;
4. 创建 usage_log.csv;
5. 创建 record_usage.py;
6. 记录 timestamp、5h limit 剩余百分比、weekly limit 剩余百分比、reset 时间;
7. 创建 summary.py,显示最近一次记录、历史最低余量、余量下降最快的相邻两次记录;
8. 全部用 Python 标准库实现,不额外安装依赖;
9. 最后说明当前实现能自动到什么程度,以及还差什么能力才能做到“执行 /status 后自动写入 CSV”。实操参考图:
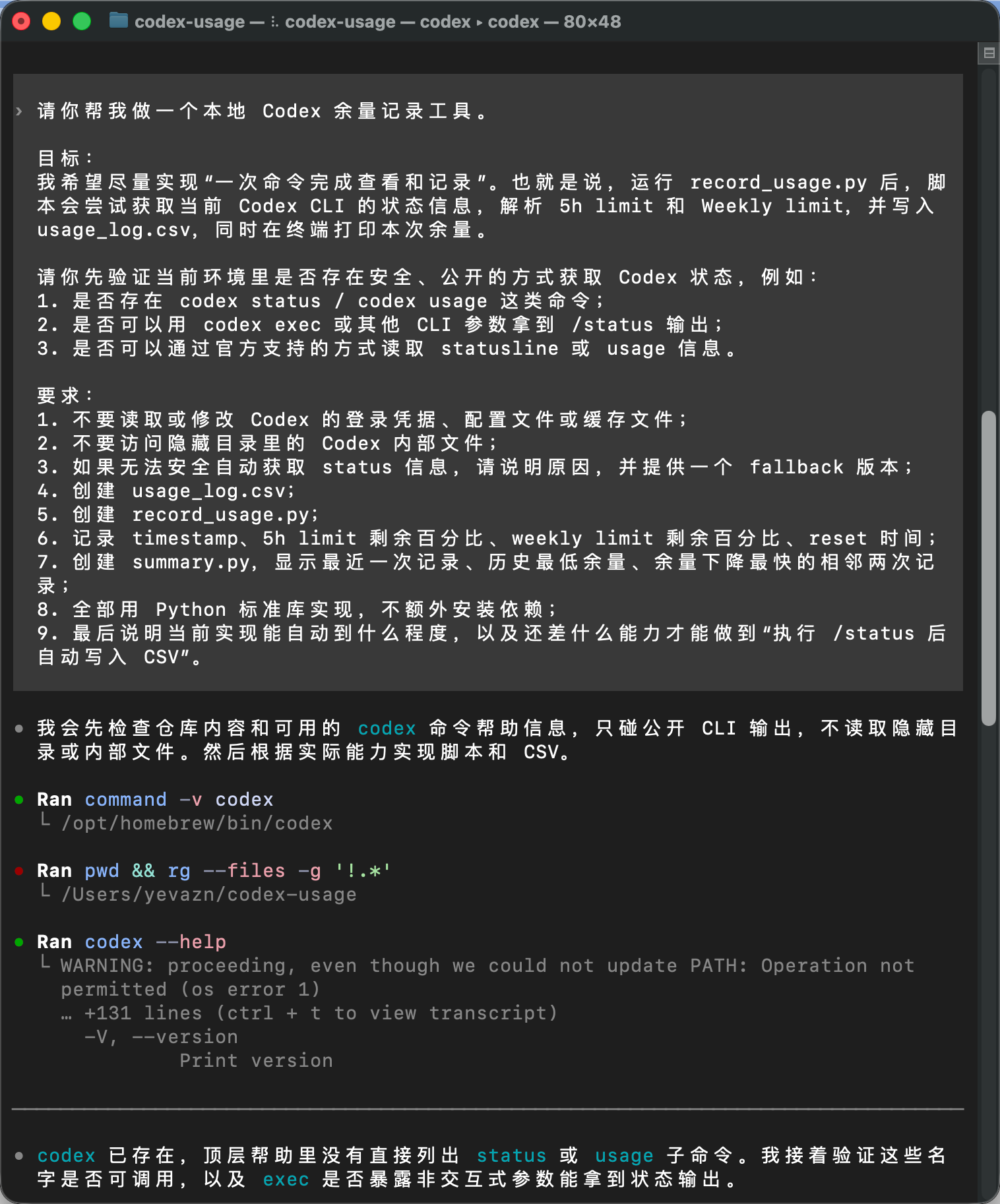
这张图里可以看到,Codex 接到需求后,先说明自己会检查当前目录、可用的 codex 命令帮助信息,只碰公开 CLI 输出,不读取隐藏目录或内部文件。
这一步挺重要。我们让它做的是一个「余量记录器」,但并不希望它为了拿到余量,去翻 Codex 的登录凭据、配置文件或者缓存文件。所以 prompt 里提前把边界写清楚:
- 不读取或修改 Codex 的登录凭据、配置文件或缓存文件。
- 不访问隐藏目录里的 Codex 内部文件。
- 先验证有没有公开方式,比如
codex status、codex usage,或者codex exec能不能拿到/status输出。
这样做的好处是,任务一开始就被限制在比较安全的范围里。Codex 可以查公开命令、看帮助信息、写本地脚本,但不能为了自动化去碰认证信息。
接下来,Codex 会继续验证当前 CLI 支持哪些能力。比如它会尝试检查有没有类似下面这样的命令:
codex status
codex usage
codex exec实操参考图:
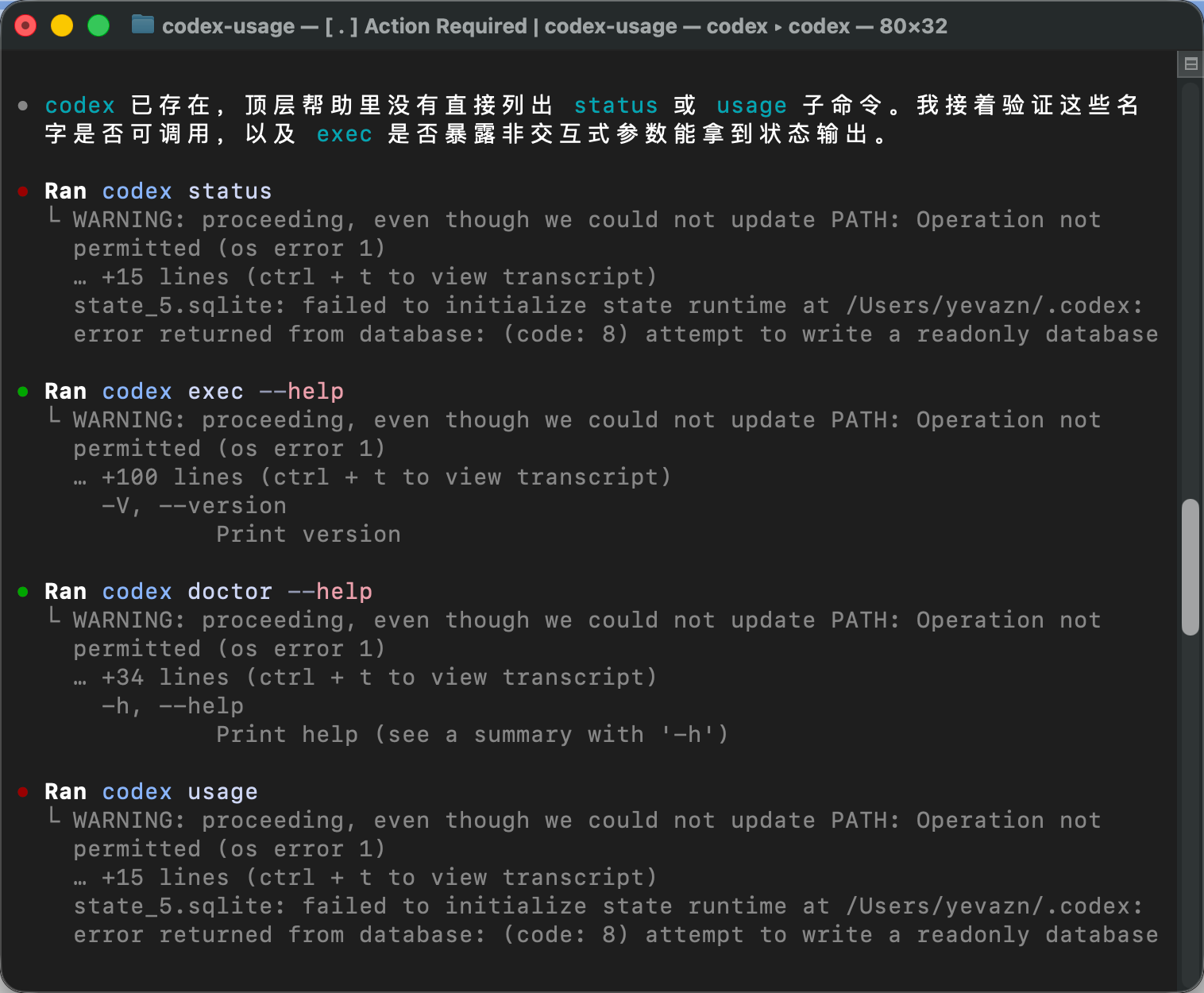
从图里可以看到,Codex 确实在尝试执行这些检查。
比如它先试了 codex status、codex usage,看有没有现成的命令可以直接拿到余量信息;然后又查看了 codex exec --help、codex doctor --help,确认有没有其他可用的非交互方式。
这里有一个细节也值得注意:它不是一上来就写 Python 脚本,而是先判断当前 CLI 有没有现成能力。这个动作很像真实开发里的第一步:先看工具链有没有已有接口,再决定要不要自己实现。
继续往下看:
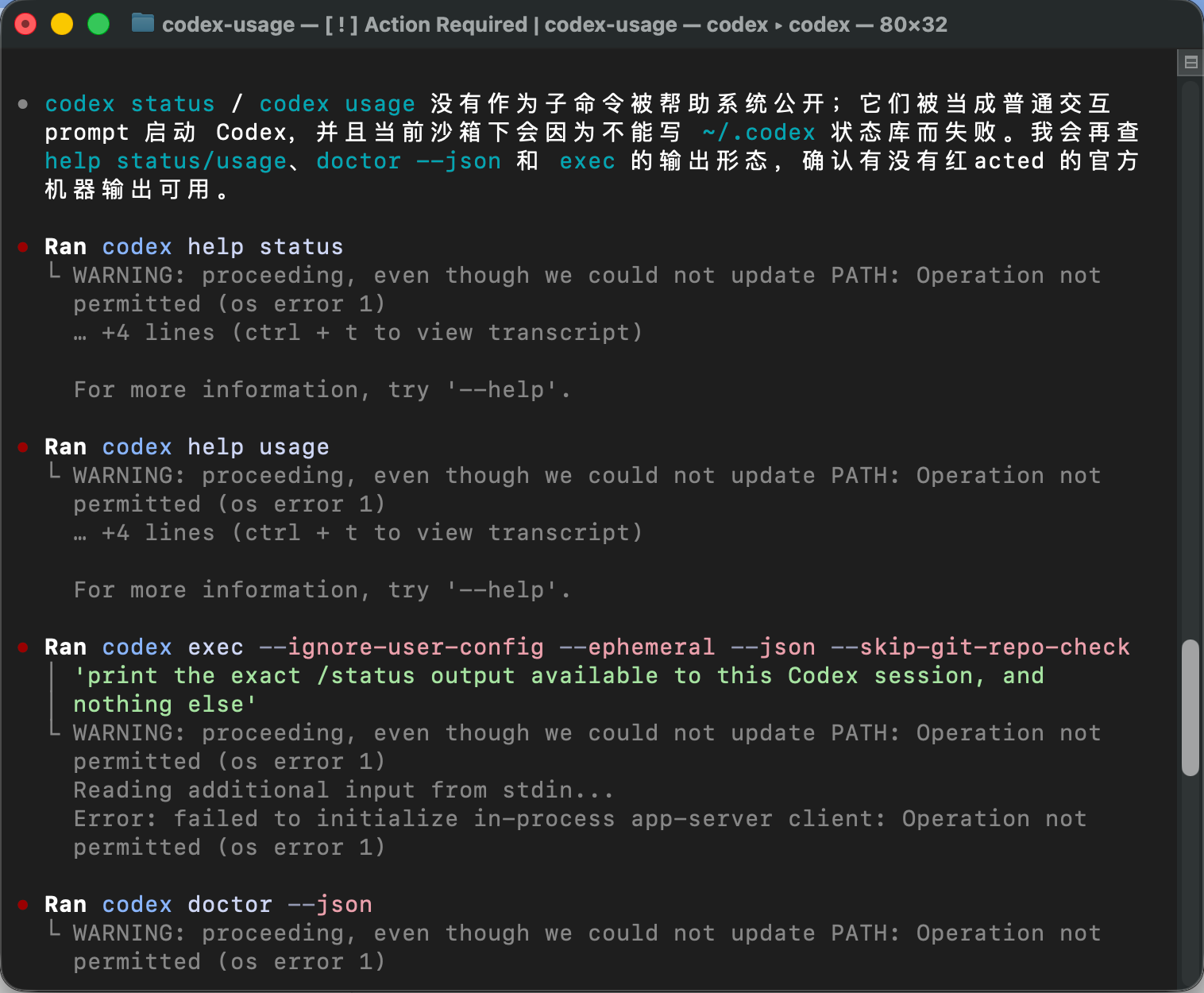
这张图里,Codex 又尝试了 codex help status、codex help usage,以及用 codex exec 去测试能不能拿到当前会话里的 /status 输出。
从返回结果来看,目前这些路径并没有直接给出一个稳定、结构化的 status / usage 输出。也就是说,我们一开始想要的「执行 /status 后自动写入 CSV」这件事,当前版本并没有一个特别直接的公开接口。
这个结果并不算失败。
因为它说明我们已经知道了当前版本的边界:/status 可以在 Codex CLI 交互界面里查看当前余量,但要把它变成一个外部脚本可以稳定读取的结构化数据,还需要 CLI 提供更明确的输出接口,或者后续有官方支持的 status / usage 命令。
中间还有一个很值得放出来的截图:
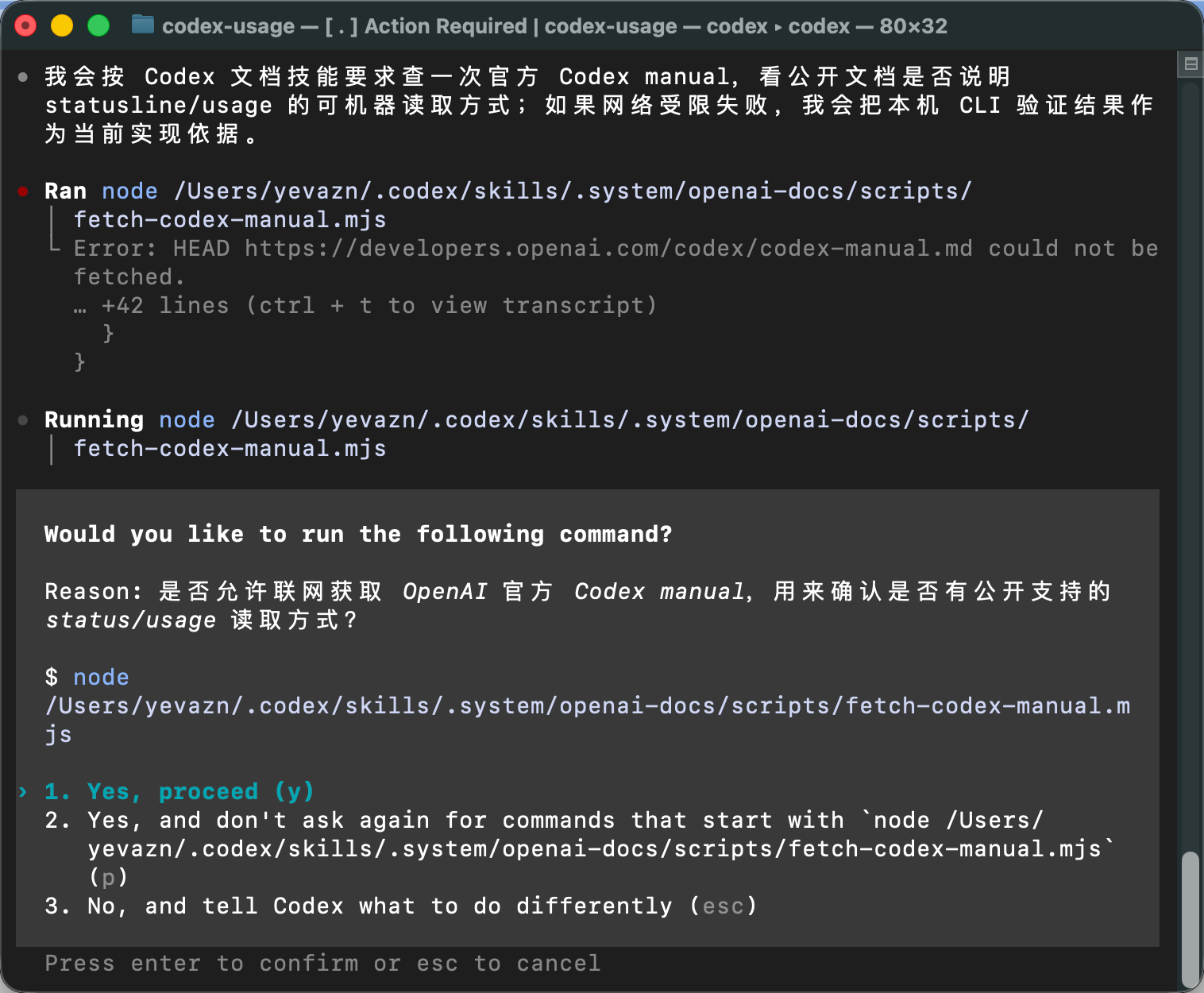
这张图是 Codex 的命令授权提示。
它准备运行一条命令去获取 OpenAI 官方 Codex manual,用来确认有没有公开支持的 status / usage 读取方式。执行前,Codex 会把命令和原因展示出来,并让你确认。
这里重点看三部分:
- 它要运行什么命令。图里显示的是一条
node ... fetch-codex-manual.mjs命令。 - 它为什么要运行这个命令。Reason 里写得很清楚:它想联网获取 OpenAI 官方 Codex manual,确认是否有公开支持的 status / usage 读取方式。
- 你要不要批准。下面有几个选项,
Yes, proceed表示只允许这一次;Yes, and don't ask again...表示以后同类命令不再询问;No, and tell Codex what to do differently表示拒绝,并告诉 Codex 换一种做法。
第一次使用时,我更建议先选第一项,只允许这一次。这样既能继续任务,也能保留对后续命令的确认。
这张图也能说明 Codex CLI 和普通聊天窗口的区别:它不只是给你建议,而是真的会尝试运行命令。也正因为如此,执行命令前看一眼授权提示很重要。
回到这次任务本身,经过这些验证后,结论就比较清楚了:
当前 Codex CLI 可以在交互界面里用 /status 查看余量,但暂时没有特别直接、稳定的公开方式,让外部脚本自动拿到这份 /status 结构化输出。
所以这次任务会进入 fallback 方案。
接下来,Codex 会开始实现这个 fallback 版本。
它会在当前目录里创建几个文件:
record_usage.py
summary.py
usage_log.csv其中,usage_log.csv 用来保存历史记录;record_usage.py 负责写入一次余量记录;summary.py 用来查看最近一次记录、历史最低余量,以及相邻两次记录之间余量下降最快的一段。
过程参考图:
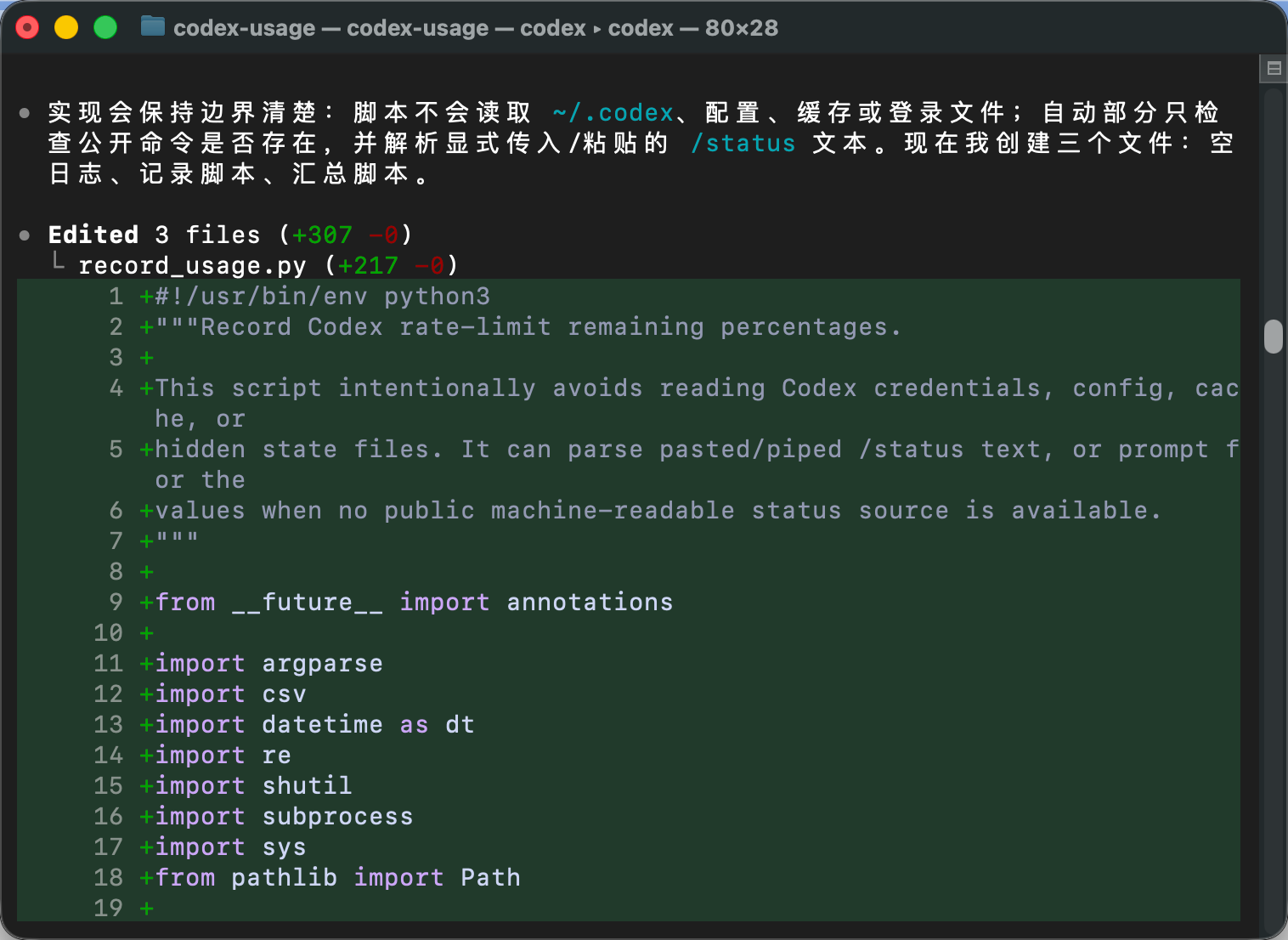
从这里开始,这个小工具就真正落地了。
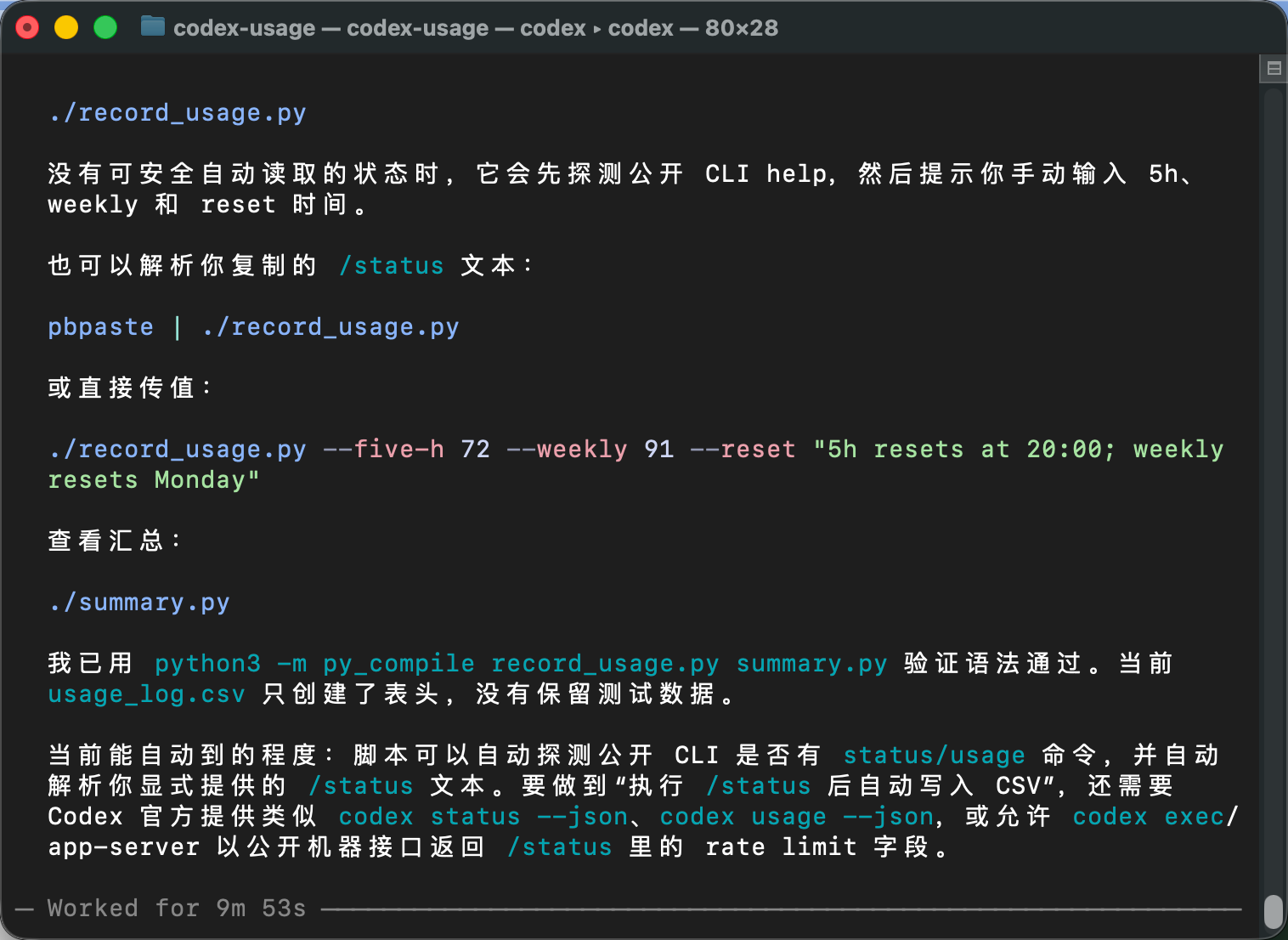
虽然它没有做到「执行 /status 后自动写入 CSV」,但它已经把记录和分析的框架搭好了。后面每次我们查看完 /status,就可以用这个工具把本次余量记录下来。等记录多了之后,再通过 summary.py 看余量变化。
现在,我们来运行下 Codex 给我们开发的余量记录脚本:
python3 record_usage.py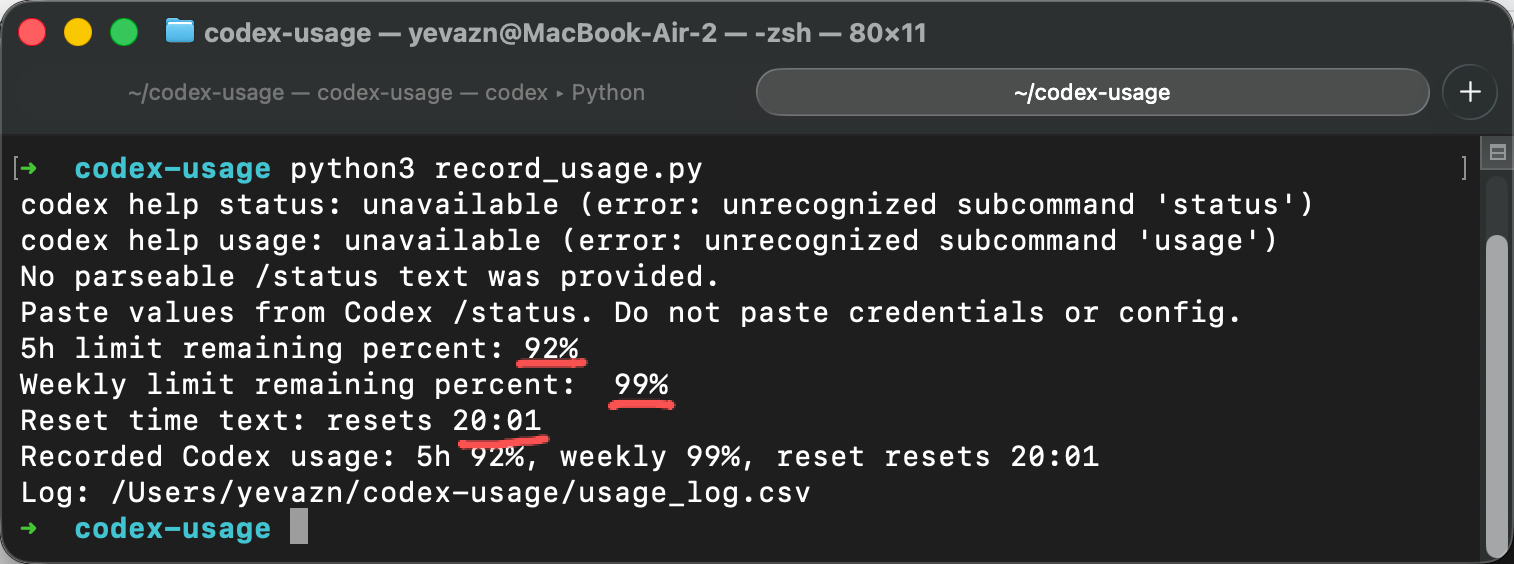
我们把 Codex 那边读取到的余量填入到脚本里,回车。我们再通过下面的命令来查看下这条记录:
cat usage_log.csv实操参考图:

可以看见,它把 92% 的百分比变成了纯数字。我们和 C 老师对话几个来回,消耗下余量之后,再记录几条数据。再运行摘要脚本:
python3 summary.py它会读取 usage_log.csv,输出最近一次记录、历史最低余量,以及相邻两次记录之间余量下降最快的一段。
实操参考图:
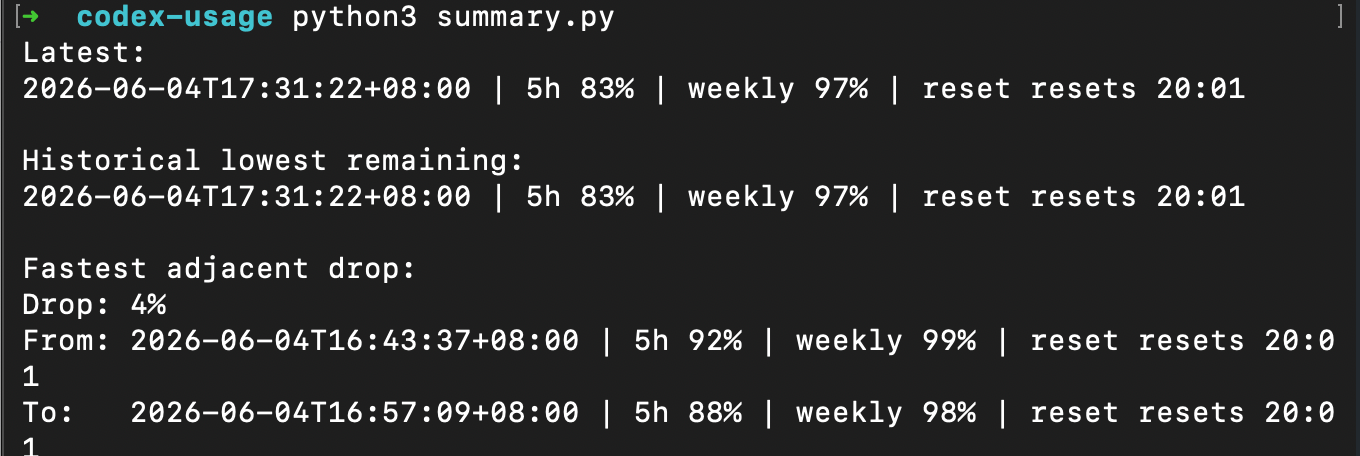
到这里,这个很小的 Codex 余量记录器就跑通了。我们可以记录每次余量,也可以用 summary.py 查看最近记录、历史最低余量和下降最快的一段。
这个任务并不复杂,但对于第一篇来说已经够用了。因为它完整走了一遍 Codex CLI 的基础流程:
提出需求
→ 检查当前环境
→ 尝试验证已有命令
→ 遇到限制后转向 fallback
→ 创建本地文件
→ 运行 Python 脚本
→ 生成可检查的结果这个过程比单纯问 Codex「你能做什么」更有价值。
因为我们能看到它怎么判断工具能力,怎么请求命令授权,怎么在当前目录里创建文件,也能看到它在发现原始设想走不通时,如何转向一个可落地的方案。
第一次上手 Codex,不一定要做复杂功能。先用一个安全的小任务,观察它怎么工作、怎么执行命令、怎么处理限制,反而更适合新手。
Codex 哪些任务更消耗用量
在消耗 Codex 用量,来增加记录数据的过程中,我问了 Codex 一个问题:哪些任务会比较耗你的用量,它给的回复是:
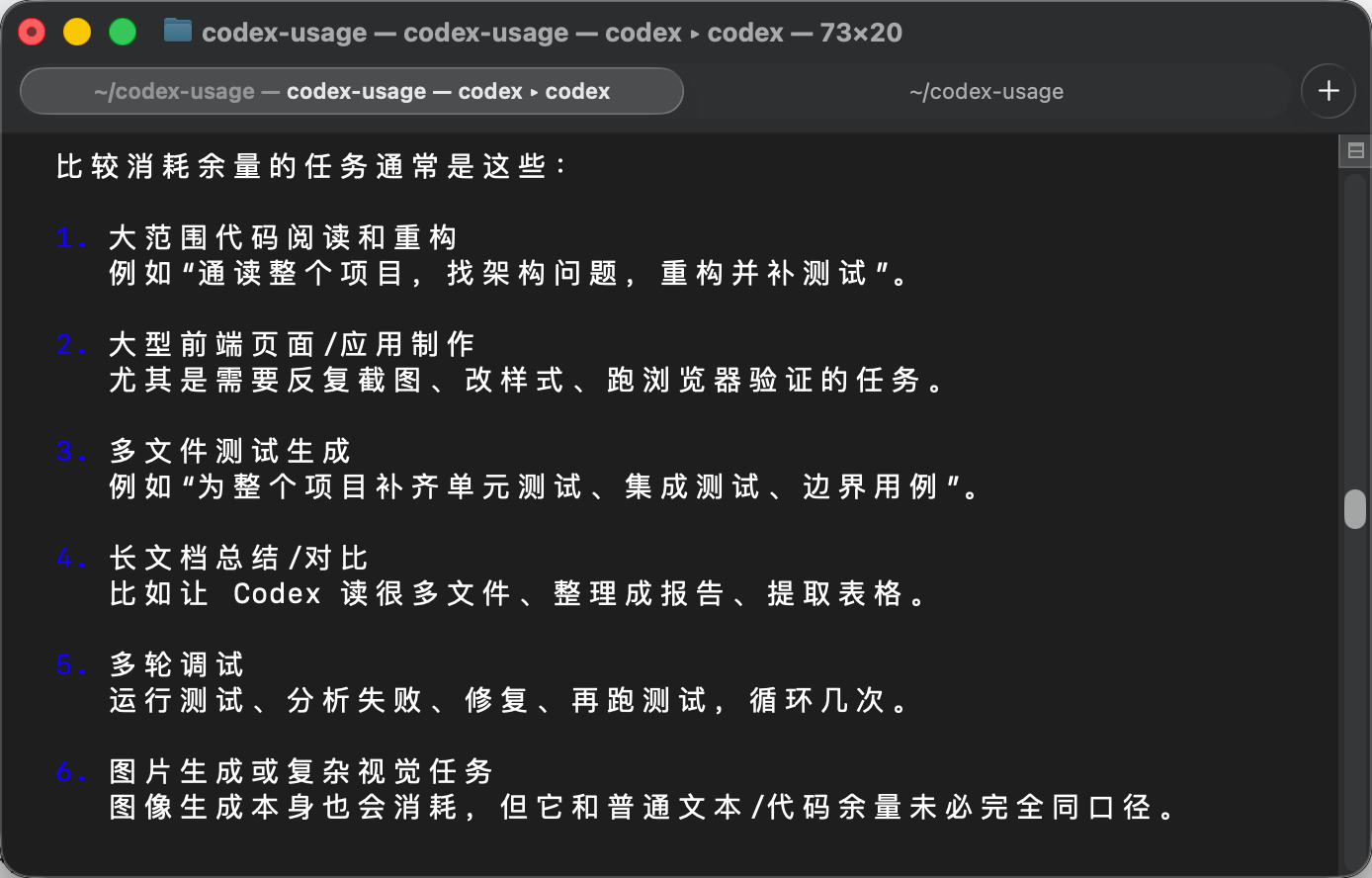
作为本篇文末的小彩蛋,记住这些任务会比较耗用量。
以上,为本次 Codex 系列的第一篇。
这一篇先把 Codex 跑起来,并用一个小任务看清楚它的基本工作方式。下一篇我们继续往前走一步:让 Codex 读懂一个真实项目。因为真正开始用 Coding Agent 做开发时,光启动它还不够,更重要的是让它知道项目结构、文件边界、规则和限制。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号