基于RK182X边缘端大模型本地化推理的算力扩容技术方案解析
原创
基于RK182X边缘端大模型本地化推理的算力扩容技术方案解析
原创
飞凌嵌入式
修改于 2026-06-05 17:50:59
修改于 2026-06-05 17:50:59
随着大语言模型与多模态融合技术在边缘场景的深度落地,储能监测、工业网关、自主机器人、边缘视频分析等终端设备,对本地离线推理、低延时实时响应、数据本地化闭环处理的技术诉求持续提升。相较于云端推理,边缘本地化部署能够有效规避网络延迟、数据传输合规、离线业务可用性等核心问题,是当前嵌入式AI技术迭代的核心方向。
在主流嵌入式边缘算力体系中,RK3588、RK3576、RK3568等终端主控芯片凭借成熟的硬件架构和广泛的商用落地基础,被大量应用于各类边缘终端设备。但受限于终端硬件成本、功耗、体积的设计约束,这类主控原生NPU算力规模有限,内存带宽资源存在瓶颈。在部署3B及以上参数量大语言模型、多模态模型时,普遍存在推理延迟过高、并发处理能力不足、模型运行稳定性差等问题,终端原生算力与高阶AI推理业务的性能矛盾,成为制约大模型规模化落地边缘场景的核心技术壁垒。
针对嵌入式边缘终端原生算力不足、大模型适配性差的行业共性问题,行业通用的解决方案为采用外置独立算力扩展硬件,搭配配套全栈软件开发套件,通过硬件算力叠加、软件生态适配的方式,补齐边缘终端的AI推理性能短板,实现LLM、VLM多模态模型在存量边缘设备的稳定本地化部署。本文将基于RK182X算力扩展硬件及RKNN3 SDKV1.0.4软件生态,系统解析边缘端算力扩容的技术架构、性能能力与场景落地逻辑。

一、边缘扩展算力硬件架构与核心性能参数
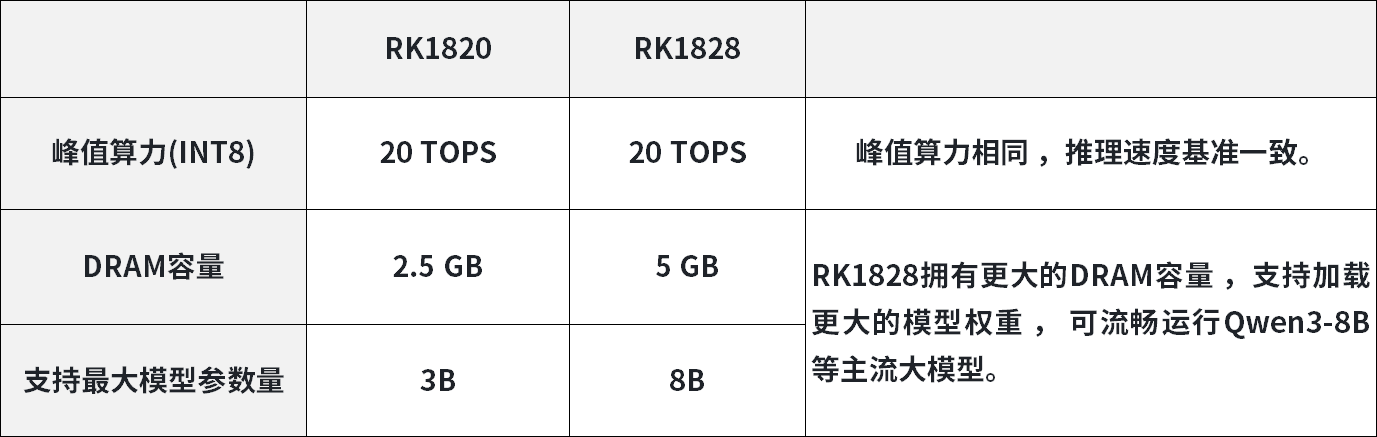
RK182X系列边缘算力扩展卡采用独立AI专用推理架构,硬件层面脱离主控资源约束,专职承担AI模型推理任务。硬件搭载多核RISC-V处理核心与3D堆叠高带宽DRAM模组,配置专用多核NPU推理单元,峰值推理算力可达20TOPS。硬件原生支持INT4、INT8、FP16多精度混合计算模式,可根据不同模型的精度需求、功耗约束灵活切换计算策略,实现推理精度与设备功耗的动态平衡。
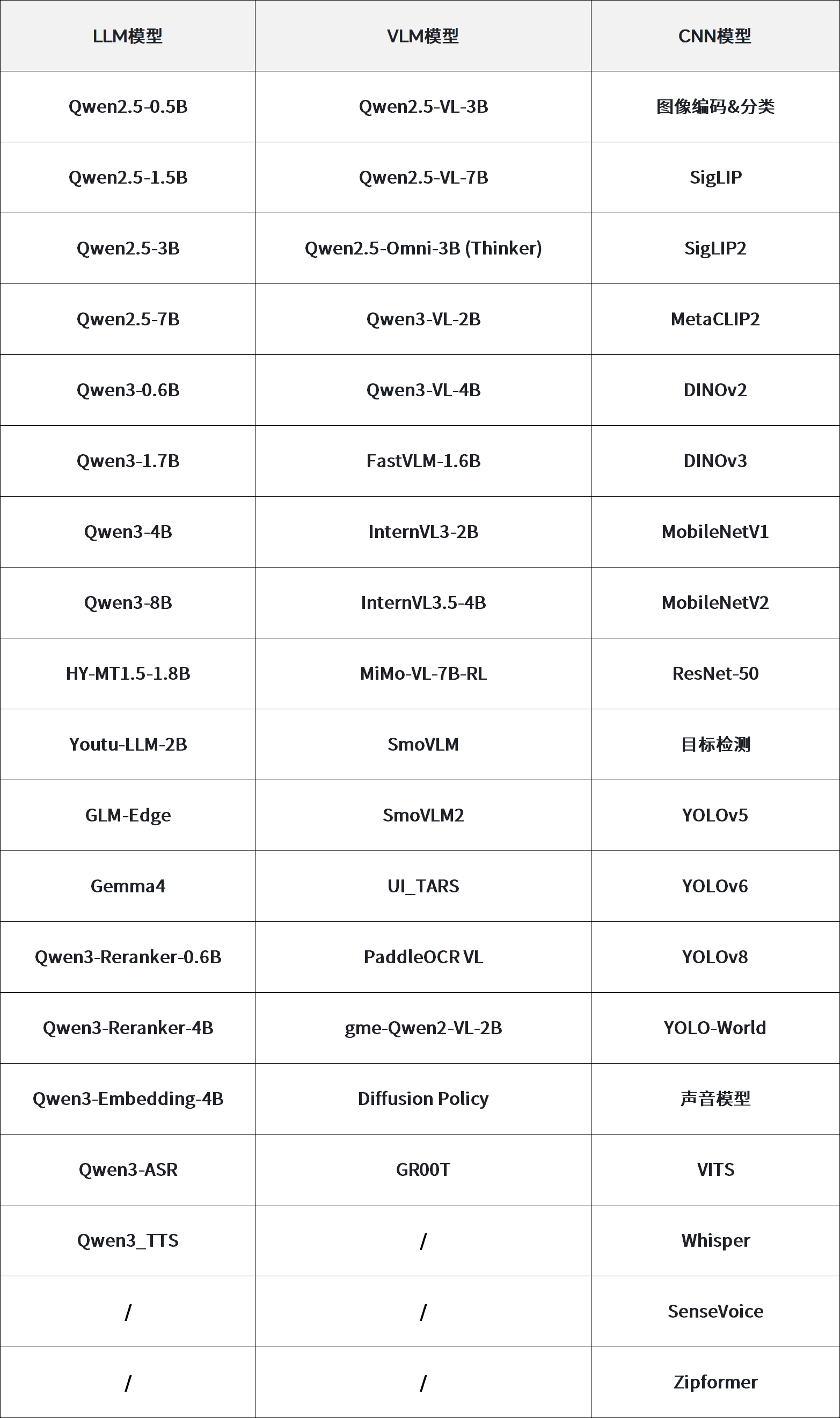
硬件外设支持PCIe、USB双高速传输接口,可与主流嵌入式主控快速互联通信。核心设计优势为算力资源完全独立,运行AI推理任务时,不占用主控设备CPU、内存及原生NPU资源,实现业务控制与AI推理算力物理隔离。在模型适配层面,该硬件架构可兼容0.5B-8B参数量区间的大语言模型、图文多模态模型,同时适配传统CNN卷积神经网络模型,覆盖边缘场景自然语言处理、视觉检测、信号分析等各类AI推理需求。
二、软件生态架构与算法适配能力
算力硬件的落地能力依赖于完善的软件工具链支撑,配套的RKNN3 SDKV1.0.4开发套件,构建了完整的端侧AI模型部署全栈生态。该软件生态原生兼容LLM大语言模型、VLM跨模态模型、CNN卷积模型三类主流AI算法架构,全面适配自然语言交互、图文语义解析、图像分类检测、音频信号处理等边缘AI核心应用场景。
工具链内置模型编译、量化压缩、算子适配、性能调试、推理优化全流程工具,支持主流开源预训练模型的快速嵌入式移植。针对边缘设备算力调度不均衡、推理时延波动大的问题,软件架构搭载了轻量化算力调度机制,可稳定分配推理资源,降低端侧模型运行时延,解决了传统嵌入式设备算法适配难度大、模型投产周期长、运行稳定性不足的技术痛点。
三、跨平台兼容架构与存量设备迭代方案
边缘算力扩容方案的核心价值之一,在于实现存量设备的低成本性能迭代。RK182X算力扩展硬件可全面兼容RK3588、RK3576、RK3568等主流嵌入式主控平台,同时适配Linux、Android两大嵌入式主流操作系统,基于标准PCIe接口即可完成硬件适配,无需开发专用驱动程序。

该跨硬件、跨系统的通用架构,彻底解决了传统边缘设备算力升级成本高、周期长的问题。存量边缘网关、工控主机、AI边缘盒等设备,无需更换主控主板、改造整机结构,也无需重新开展产品资质认证,仅通过外接算力扩展硬件,即可完成AI算力升级,快速具备大模型、多模态模型本地化推理能力,大幅降低设备迭代的硬件改造成本与项目落地周期。
从工程落地层面,该套扩容方案已完成双系统全量驱动调试与全算子适配验证,可稳定适配工业视觉检测、嵌入式机器人、智能交互终端、商用显示设备等多类终端场景。硬件跨平台、跨系统的复用特性,可有效降低设备备货种类,精简后期运维体系,适配规模化工业落地需求。
以下为各主控平台搭配RK182X算力卡前后大模型推理性能对比:
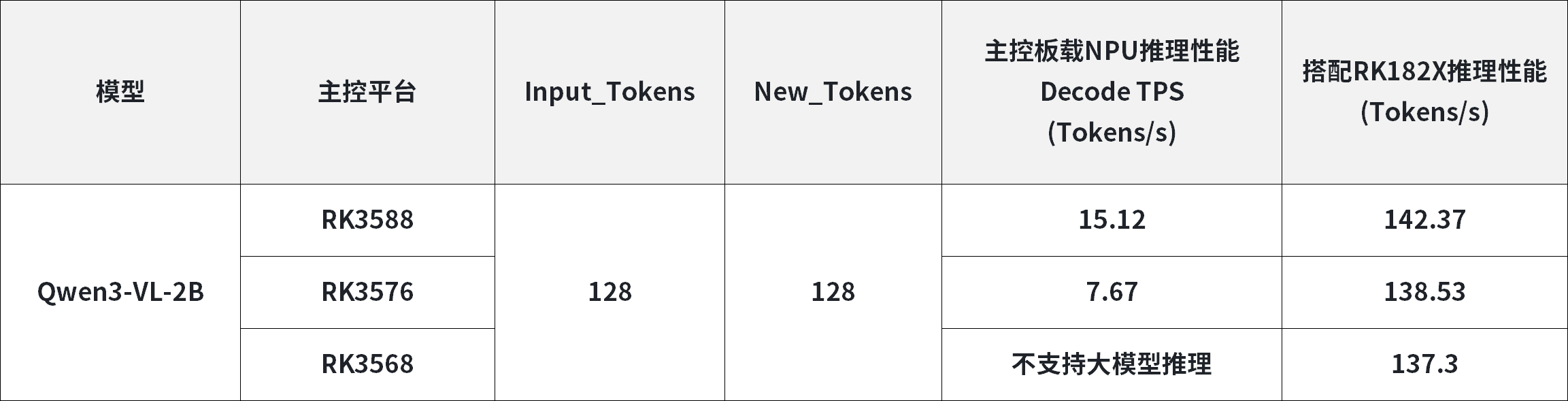
四、主流主控平台算力扩容性能对比分析
以商用普及率最高的RK3568平台为例,其原生板载NPU算力仅1TOPS,算力规模无法支撑3B及以上大模型的稳定推理,仅可满足基础机器视觉、简单信号处理等轻量化AI任务。该平台预留标准PCIe扩展接口,具备算力扩容的硬件基础,外接RK182X独立算力硬件后,可新增20TOPS专用推理算力,在不改动整机结构的前提下,实现高阶大语言模型、多模态模型的本地化稳定运行。
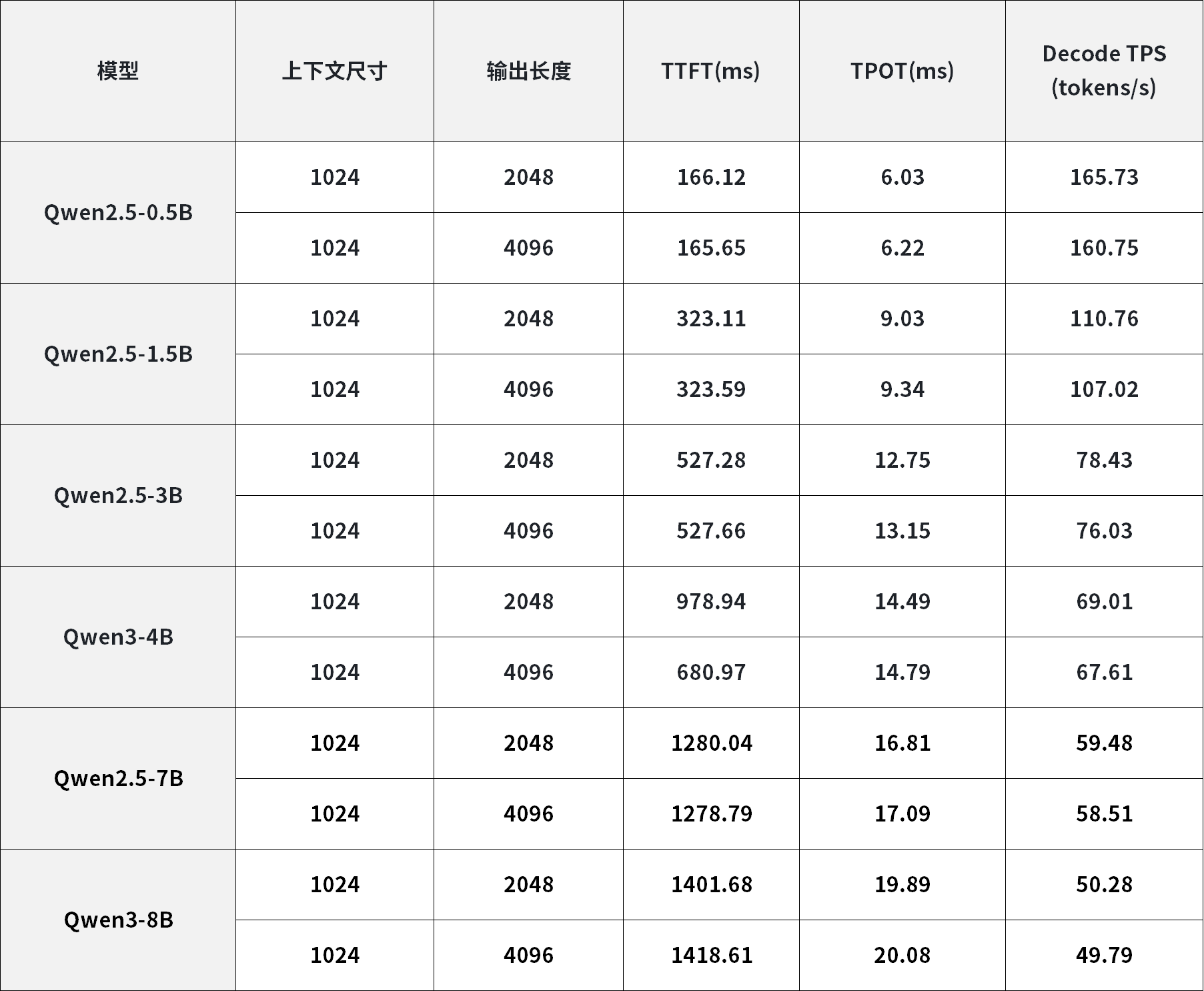
本次性能测试基于各主流主控SOC搭配RK182X算力硬件、PCIe高速互联架构搭建测试环境,统一采用行业通用评测指标:TTFT(首token生成耗时)、TPOT(单token平均生成耗时)、TPS(每秒token生成数量),其中VLM模型的视觉特征提取与语言推理模块进行独立耗时统计,测试数据客观反映各平台扩容后的真实推理性能。各平台详细测试数据如下:
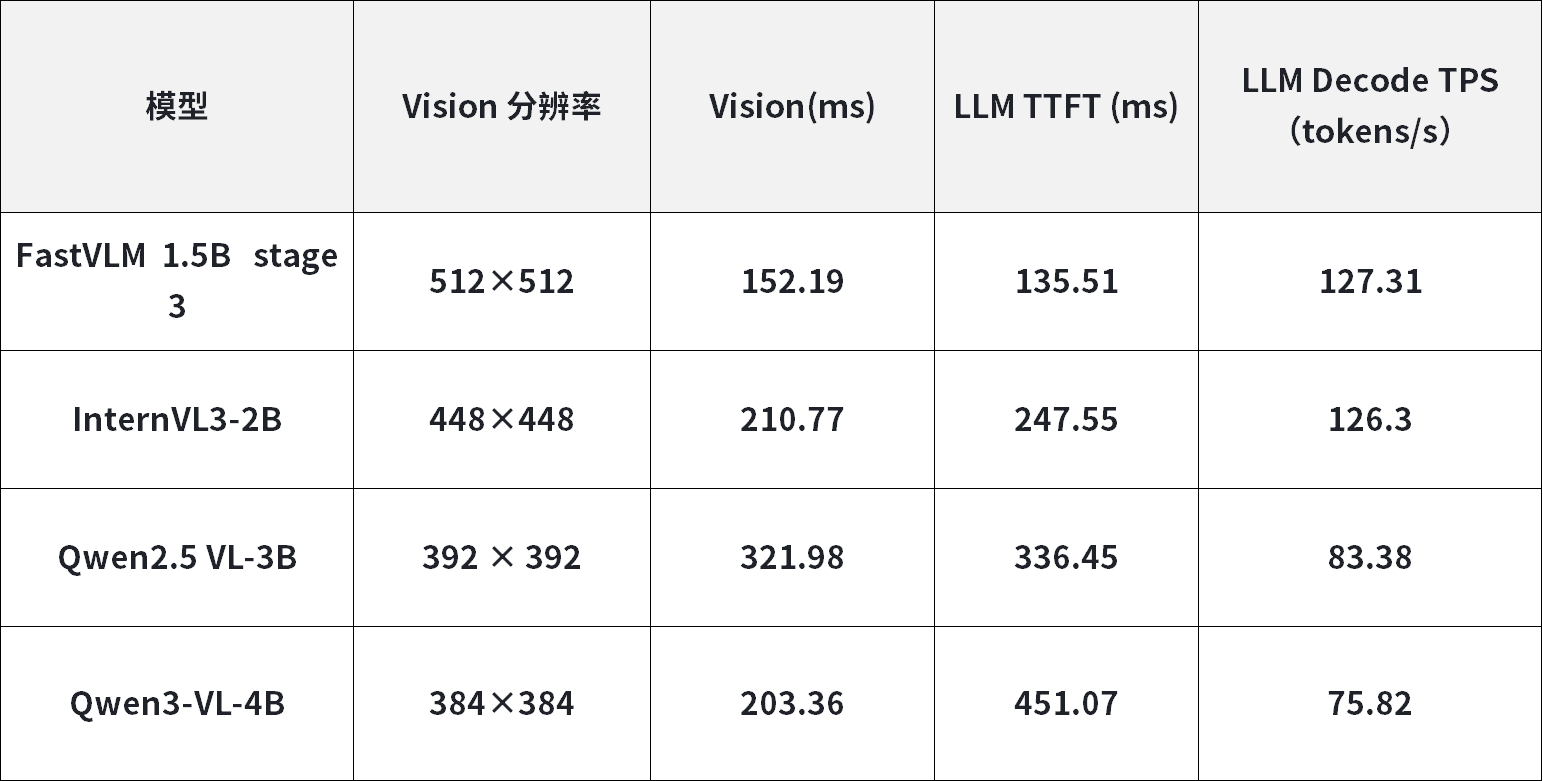
1. Ubuntu系统 - RK3568+RK1828算力扩容方案
含各参数量LLM模型、VLM模型端侧推理核心性能数据
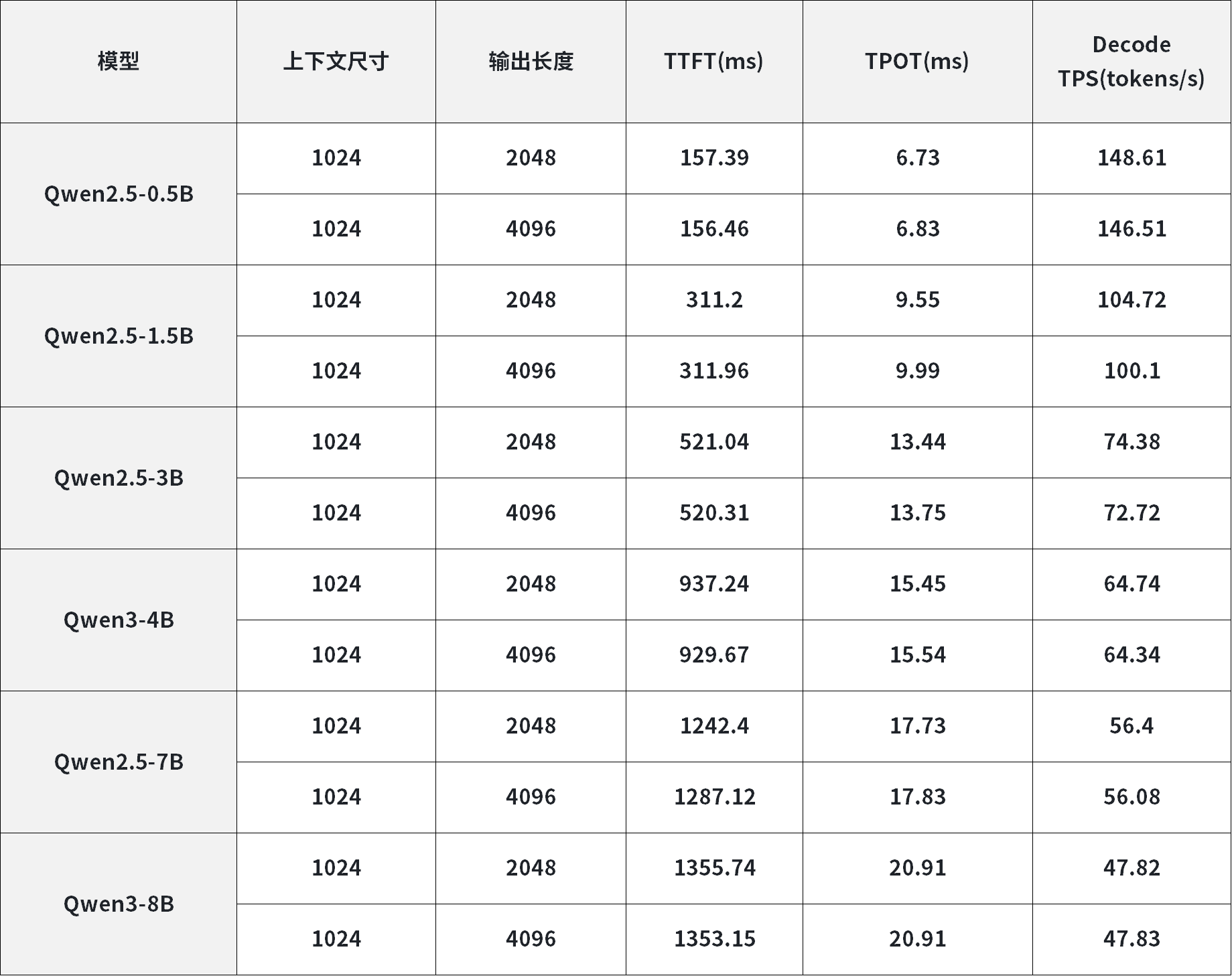
2. Ubuntu系统 - RK3576+RK1828算力扩容方案
含各参数量LLM模型、VLM模型端侧推理核心性能数据
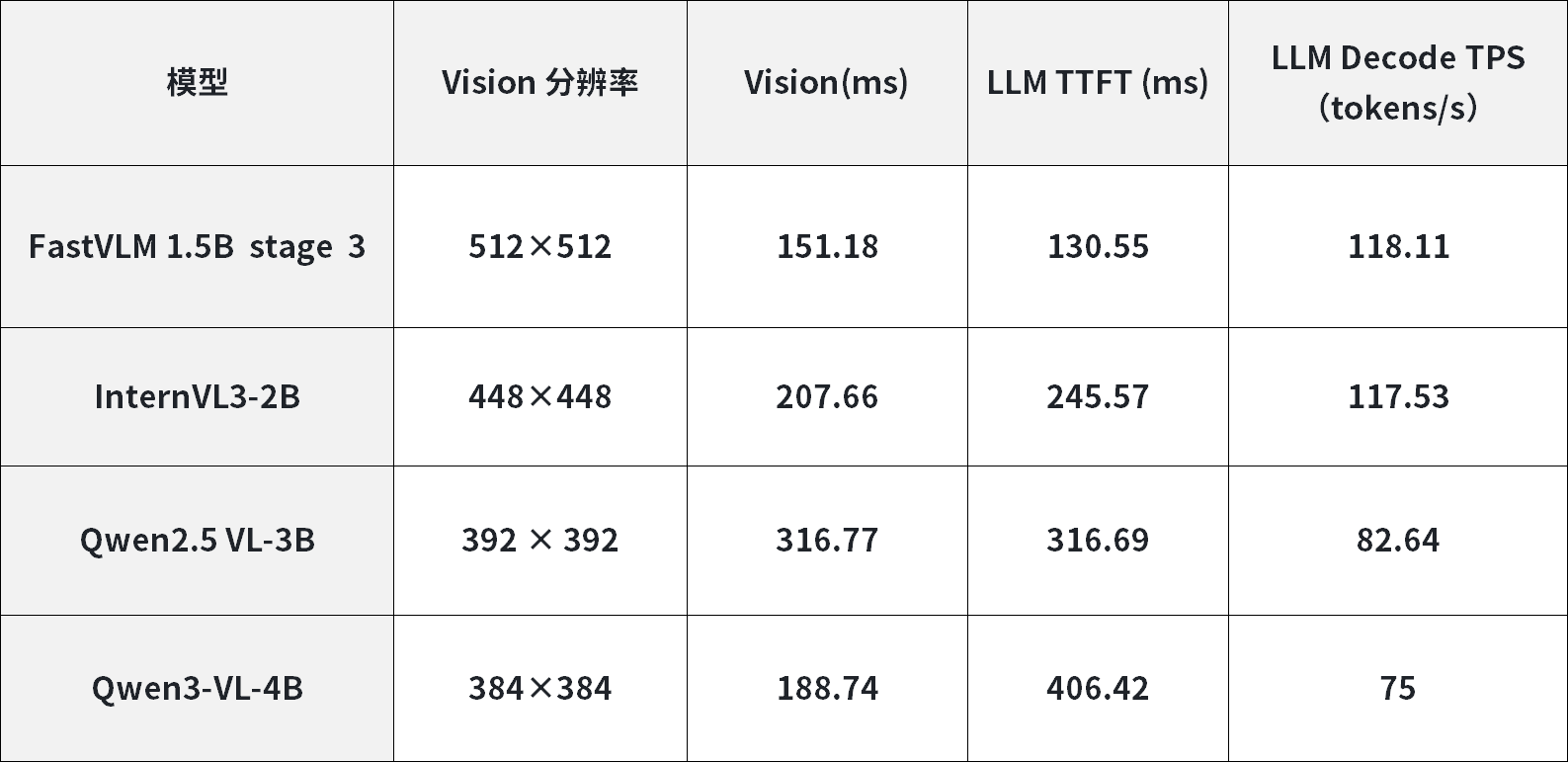
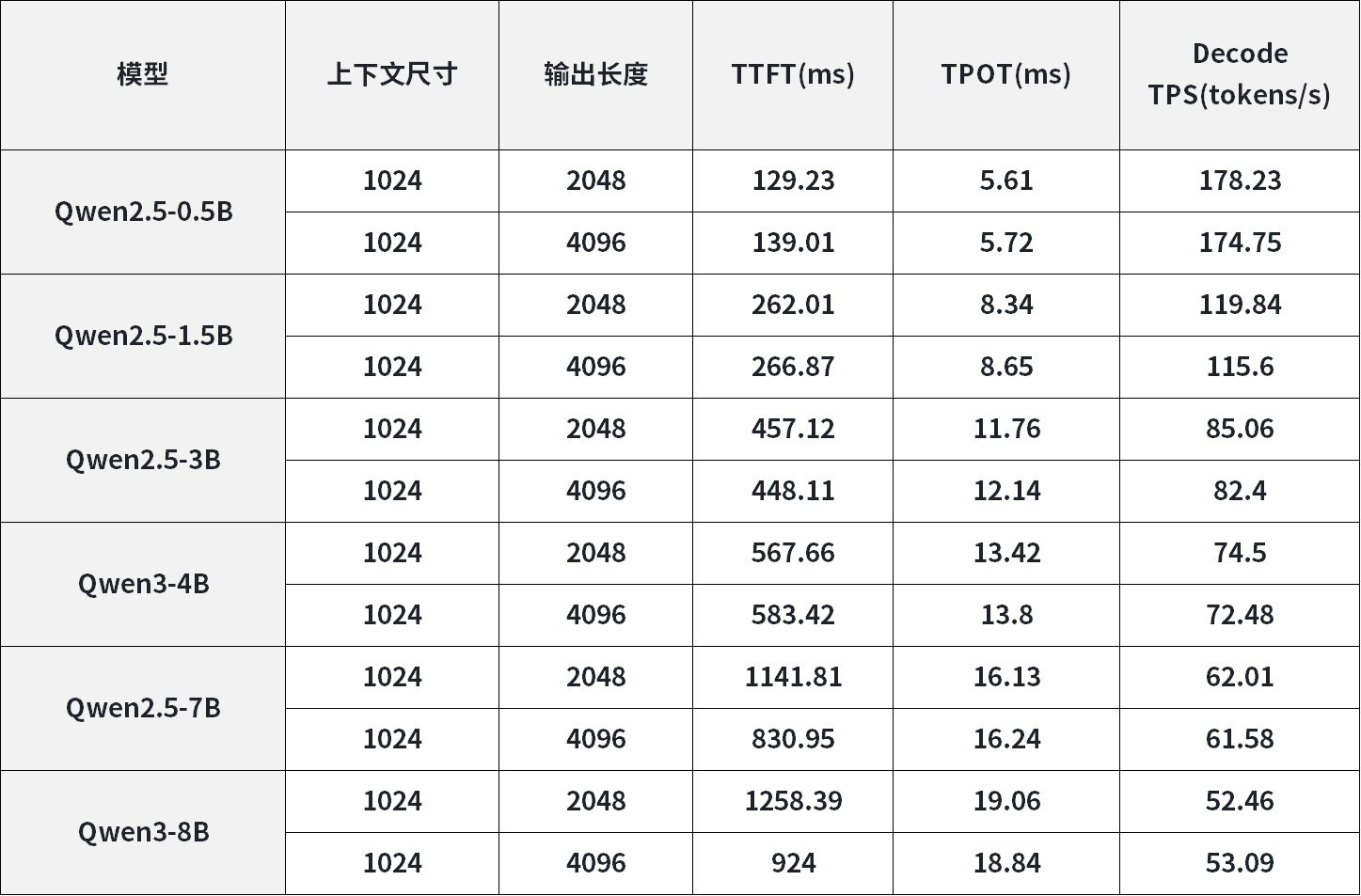
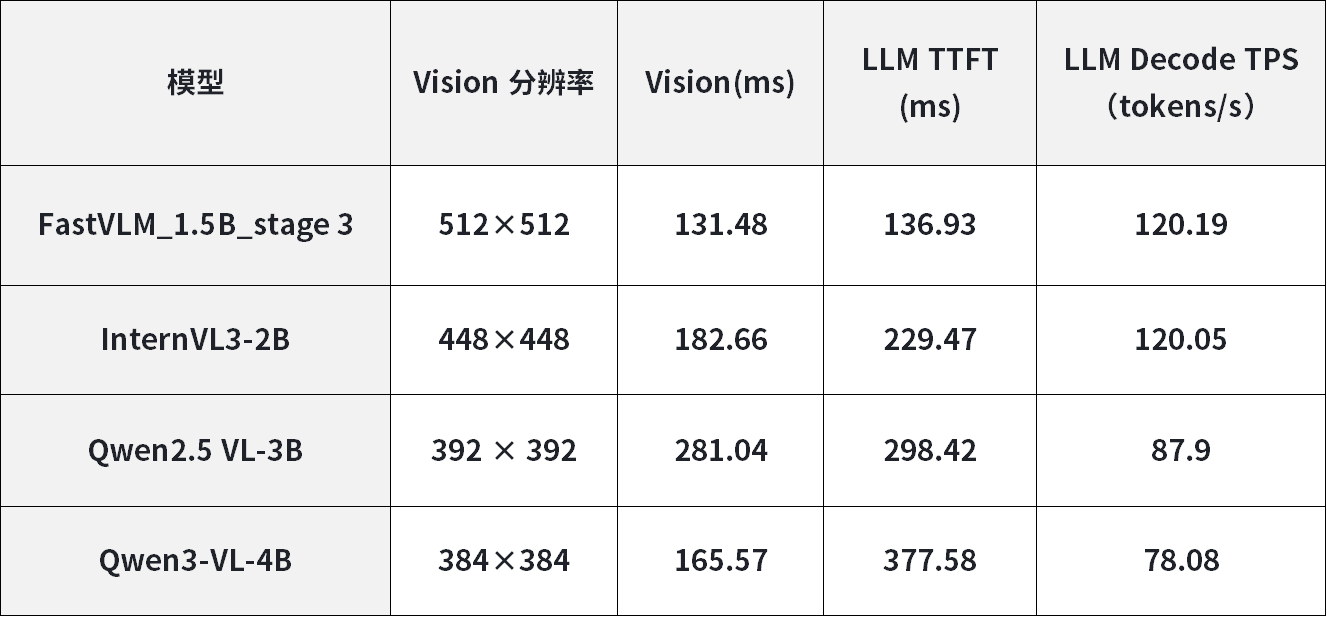
3. Android系统 - RK3588+RK1828算力扩容方案
含各参数量LLM模型、VLM模型端侧推理核心性能数据
五、行业落地场景:储能系统端侧私有化大模型部署
在电力储能BMS运维场景中,数据安全合规、离线自主运维是核心刚需,云端推理方案存在数据传输泄露、断网业务失效等风险,端侧私有化大模型部署成为最优技术路径。基于RK3588主控搭配RK182X算力扩容架构,可搭建本地化储能AI运维交互系统。
该系统集成嵌入式ASR语音识别、TTS语音合成模块,实现本地化人机语音交互功能,可完成多级储能BMS设备运行参数查询、设备异常故障智能诊断、运维数据统计分析等核心业务。依托大模型的语义理解能力,可精准解析复杂运维指令,支持多轮连续交互,适配现场运维的复杂使用场景。
整体方案采用纯端侧离线部署架构,所有设备运行数据、模型推理数据均在本地闭环处理,无外网数据传输,完全契合电力行业数据安全与合规标准。从性能维度,扩容后的端侧大模型推理速度稳定可达60+tokens/s,能够满足故障诊断、数据查询等实时性业务需求,同时支持自定义行业知识库导入、标准化接口二次开发,适配储能场景个性化功能迭代需求。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号