Claude Code vs 字节 Trae:记忆工程深度对决,谁才是真正的 "长期同事"?

Claude Code vs 字节 Trae:记忆工程深度对决,谁才是真正的 "长期同事"?

瑭宋元
发布于 2026-06-19 08:15:35
发布于 2026-06-19 08:15:35
当 AI 编程助手从 "代码补全工具" 进化为 "自主开发 Agent",记忆系统就成了决定其上限的核心能力。一个优秀的记忆系统能让 AI 记住你的编码习惯、项目架构、历史决策,甚至从错误中学习,真正成为与你长期协作的 "同事"。
2026 年上半年,Anthropic 的 Claude Code 和字节跳动的 Trae 先后完成了记忆系统的重大升级,代表了当前 AI 编程领域记忆工程的最高水平。下面我将从技术架构、实现原理、实际体验、适用场景四个维度,对两者进行一次彻底的拆解对比。
一、为什么记忆工程是 AI 编程的 "生死线"?
在深入对比之前,我们需要先理解一个基本事实:大模型本身是无状态的。每次调用都是独立计算,关掉终端再打开,它连上次改了哪个文件都不知道。
想要让 Agent"记住" 什么,只有一条路 —— 在每次调用时把相关信息塞进上下文窗口。而窗口是有限的。
所以,记忆系统的核心矛盾从来不是 "怎么存更多",而是 "怎么存对的东西"。它需要解决三个致命问题:
多会话一致性断裂:一关终端就失忆,每次都要重新 "教育"AI
约束漂移:项目架构变了,但 AI 还在按三个月前的方案执行
信息腐败:记忆库同时存在有效信息和过期信息,AI 行为变得不可预测
Claude Code 和 Trae 给出了不同的答案。
二、Claude Code:文件系统驱动的 "五层记忆金字塔"
Claude Code 的记忆系统是目前行业内最成熟、最系统化的设计。它基于文件系统构建,将所有信息按生命周期和变化频率切成五层,形成了一个严格的 "记忆金字塔"。
2.1 五层架构全景
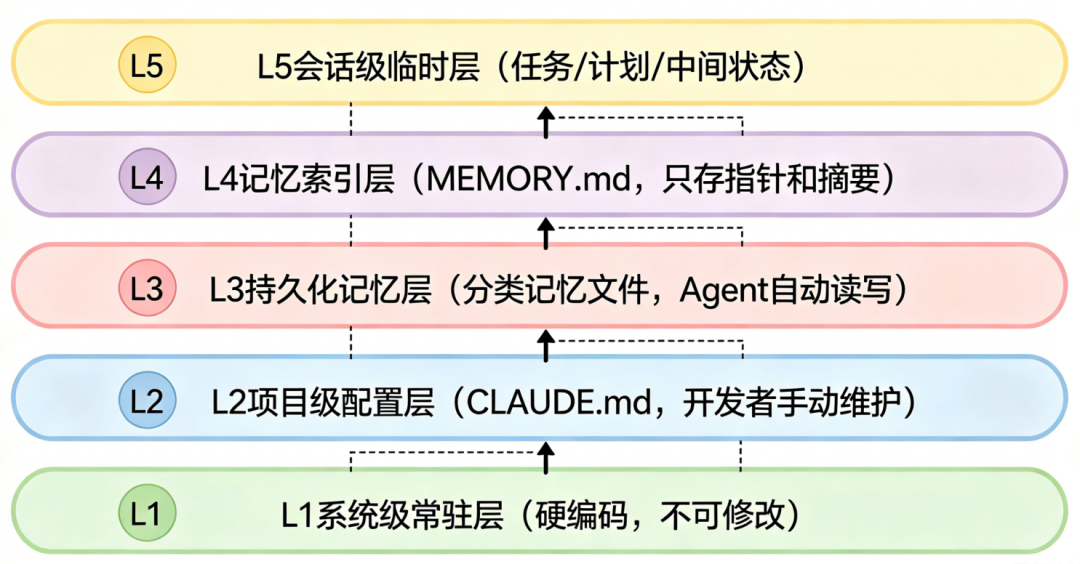
核心设计哲学:越往下变化越慢,越往上变化越快。不同层级采用完全不同的加载和淘汰策略。
2.2 逐层深度解析
L1:系统级常驻层
物理位置:硬编码在 Claude Code 内部
存储内容:Agent 行为规则、工具 schema、安全约束、环境信息
加载策略:强制全量加载,常驻整个会话
设计亮点:安全约束硬编码,保证不可篡改性。对于能执行
rm -rf和git push --force的工具来说,这是必要的安全底线。
L2:项目级配置层(CLAUDE.md)
物理位置:项目目录下的CLAUDE.md文件,支持多级并存
存储内容:项目技术栈、编码规范、架构决策、工作流程
加载策略:会话启动时全量加载,支持路径级按需激活
设计亮点:采用 Markdown 格式而非 YAML/JSON,因为 LLM 对 Markdown 的理解和遵循率更高
支持六级作用域:企业级→用户全局→用户规则→项目级→项目规则→本地覆盖,与.gitignore逻辑类似
官方提供/init命令,可自动分析代码库生成初始 CLAUDE
L3:持久化记忆层(Auto Memory)
物理位置:
~/.claude/projects/[项目路径]/memory/目录,每条记忆是独立的.md文件
存储内容:分为四种类型,按生命周期差异化管理:
类型 | 内容 | 生命周期 | 淘汰策略 |
|---|---|---|---|
user | 用户角色、偏好、背景知识 | 长期,跨项目 | 不主动淘汰 |
feedback | 用户纠正和确认 | 长期,项目级 | 持续积累 |
project | 项目进度、架构决策 | 中期,随项目演进 | 主动更新 |
reference | 外部资源指针 | 按需 | 使用前验证 |
写入机制:双路写入 + 互斥
设计亮点:不用数据库或向量库,直接用文件系统。LLM 原生可读,人工可审计,零依赖记忆文件采用 frontmatter 驱动,description字段同时作为摘要和检索关键词
L4:记忆索引层(MEMORY.md)
物理位置:
~/.claude/projects/[项目路径]/memory/MEMORY.md
存储内容:只存指针和一行摘要,不存完整内容
加载策略:每次会话自动全量加载,被 prompt cache 缓存
设计亮点:将 "判断需要什么记忆" 从 LLM 的隐式推理变成显式的工具调用
严格限制 200 行 / 25KB 硬截断,保证不会占用过多上下文
L5:会话级临时层
物理位置:内存中,不持久化
存储内容:当前任务列表、执行计划、中间状态
加载策略:会话开始为空,运行时动态写入,结束自动清空
设计亮点:重要信息可通过 "晋升通路" 写入 L3 持久化层
2.3 Claude Code 记忆系统的优势与不足
优势:架构清晰,分层明确,可观测性强
完全基于文件系统,Git 友好,可与团队共享
双路写入机制保证记忆不遗漏
2026 年 5 月新增的 "AutoDream" 功能可自动整理和清理过期记忆
不足:L4 层只有关键词匹配,没有语义检索,召回率有限
MEMORY.md 的 200 行硬截断会静默丢弃最新写入的记忆
没有团队级共享记忆,只能通过 CLAUDE.md 间接共享
国内使用门槛高,存在网络和封号风险
三、字节 Trae:IDE 原生的 "双轨记忆 + 技能融合" 体系
与 Claude Code 的终端定位不同,Trae 是基于 VS Code 架构的AI 原生 IDE。它的记忆系统深度集成在 IDE 中,其“记忆系统”(Memory)与 Rules、Skills、MCP 共同构成字节跳动官方宣传的四大协同能力(非三大),且深度集成于 IDE。
3.1 核心架构:分层 + 双轨
Trae 的记忆系统采用三层架构 + 双轨模式的设计:

双轨模式是 Trae 记忆系统最核心的特点:
全局记忆:在所有项目中生效,最多保存 20 条,适合个人偏好(如缩进宽度、引号风格)
项目记忆:仅在当前项目生效,隔离不同项目上下文,最多保存 20 条
3.2 四大核心能力协同
Trae 的记忆系统不是孤立存在的,而是与 Rules、Skills、MCP 深度融合,形成了 "输入 - 处理 - 输出 - 迭代" 的完整闭环:
Memory:提供 "是什么" 的背景知识
Rules:定义 "必须做什么",约束 AI 行为
Skills:提供 "怎么做" 的具体流程
MCP:连接外部数据和服务
这种协同模式让 Trae 的记忆不仅仅是 "存储信息",更是 "驱动行为"。
3.3 技术实现细节
存储与检索
存储引擎:基于 SQLite+FTS5,单文件数据库,部署简单
检索方式:全文检索 + 时间线检索。当搜到一条记录时,可自动查看前后 5 分钟发生的所有事件,精准还原思维现场
隐私保护:支持标签,敏感内容会被清洗,不会进入索引
上下文注入
当你在新会话中需要用到之前的知识时,Trae 会生成一个结构化的 Context Block。
这个 Block 会直接喂给当前会话,让 AI 瞬间 "想起" 之前的上下文。
与 Skills 的深度集成
Trae 的记忆可以被 Skills 直接调用。例如,你可以创建一个 "代码审查"Skill,让它自动从记忆中读取团队的编码规范,然后应用到审查过程中。
3.4 Trae 记忆系统的优势与不足
优势:
IDE 原生集成,使用体验流畅,无需额外配置
双轨模式有效隔离了个人偏好和项目上下文
与 Rules、Skills、MCP 深度协同,记忆能真正转化为生产力
中文指令理解精准,对国内开发者极其友好
支持多模型切换,记忆可在不同模型间共享
不足:
记忆条目数量限制较严格(全局和项目各 20 条)
自动记忆能力较弱,很多时候需要手动添加
团队级共享记忆功能还在开发中
批量修改时需要逐个确认,影响效率
四、全面对比:谁的记忆更 "好用"?
为了让对比更直观,我们制作了一张详细的对比表:
对比维度 | Claude Code | 字节 Trae |
|---|---|---|
核心定位 | 终端式 AI Agent | AI 原生 IDE |
架构设计 | 五层文件系统架构 | 三层 + 双轨数据库架构 |
存储方式 | 纯文件系统(Markdown) | SQLite+FTS5 |
检索方式 | 关键词匹配 | 全文检索 + 时间线检索 |
记忆类型 | 系统 / 项目 / 用户 / 反馈 / 参考 | 全局 / 项目双轨 |
自动记忆 | 强(双路写入 + 后台提取) | 中(需手动添加较多) |
可观测性 | 极高(直接查看文件) | 高(IDE 内可视化管理) |
团队共享 | 弱(仅通过 CLAUDE.md) | 中(即将推出) |
跨平台能力 | 终端跨平台 | 基于 VS Code 跨平台 |
与其他能力协同 | 与 MCP 集成 | 与 Rules/Skills/MCP 深度融合 |
中文支持 | 一般 | 极好 |
国内可用性 | 差(需外网 + 美区支付) | 极好 |
Token 效率 | 高(分层加载 + 索引) | 中(固定 20 条限制) |
适用场景 | 资深开发者、大型项目重构、复杂系统分析 | 全层级开发者、快速原型开发、前端开发 |
4.1 实际体验对比
我们在同一个 React+Node 全栈项目中,分别使用 Claude Code 和 Trae 进行了一周的开发,测试了以下几个关键场景:
场景 1:跨会话上下文保持
Claude Code:表现优秀。自动记住了项目的构建命令、测试命令、编码规范,甚至记住了我们之前遇到的一个端口冲突问题及其解决方案。
Trae:表现良好。需要手动添加几条关键记忆,但添加后在后续会话中都能正确调用。
场景 2:从错误中学习
Claude Code:表现出色。当我们纠正了它的一个错误后,它会自动写入 feedback 记忆,后续遇到类似问题时会主动避免。
Trae:表现一般。需要我们明确说 "记住这个错误",它才会保存到记忆中。
场景 3:团队协作
Claude Code:通过将 CLAUDE.md 提交到 Git,团队成员可以共享项目规范。但个人记忆无法共享。
Trae:目前只能通过导出 / 导入记忆文件来共享,团队级共享功能还在灰度测试中。
场景 4:多项目切换
Claude Code:表现优秀。每个项目有独立的记忆目录,切换项目时自动加载对应记忆。
Trae:表现优秀。双轨模式完美隔离了不同项目的上下文,不会出现混淆。
五、结论与建议
5.1 谁更适合你?
如果你是如下开发者,选择 Claude Code:
你是习惯终端工作流的资深开发者
你需要处理大型代码库重构、复杂系统分析等深度任务
你身处海外或有稳定的外网环境
你重视记忆系统的可观测性和可定制性
如果你是下面这样的开发者,建议选择字节 Trae:
你是国内开发者,希望获得流畅的国内使用体验
你习惯使用 VS Code 等可视化 IDE
你需要快速原型开发、设计稿转代码等前端友好功能
你希望记忆与规则、技能、数据连接形成完整闭环
5.2 记忆工程的未来趋势
通过对比 Claude Code 和 Trae,我们可以看到 AI 编程助手记忆系统的几个明确发展方向:
从被动存储到主动学习:未来的记忆系统将能主动从交互中学习,而不仅仅是记录用户明确告知的内容
从个人记忆到团队记忆:团队级共享记忆将成为标配,让整个团队的经验得以沉淀和复用
从单一模态到多模态记忆:不仅能记住文本,还能记住设计稿、流程图、甚至语音讨论
从静态记忆到动态演化:记忆系统将能自动检测过期信息并更新,保持与项目的同步
5.3 写在最后
Claude Code 和 Trae 代表了 AI 编程记忆工程的两种不同路线:Claude Code 走的是 "极简主义" 路线,用最朴素的文件系统解决了最复杂的记忆问题;Trae 走的是 "集成主义" 路线,将记忆与 IDE 的其他能力深度融合,打造了更完整的开发体验。
没有绝对的 "更好",只有 "更适合"。对于大多数国内开发者来说,Trae 的综合体验已经非常出色,而且还在快速迭代中。而对于追求极致深度和可定制性的资深开发者,Claude Code 依然是不可替代的选择。
无论你选择哪一个,有一点是确定的:记忆系统正在将 AI 编程助手从 "用完即扔的工具" 变成 "与你共同成长的长期同事"。这才是 AI 编程真正的革命所在。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Agent 政企应用研习社 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号