使用 LangChain 的 Deep Agents 框架与 Elasticsearch 进行系统性研究

使用 LangChain 的 Deep Agents 框架与 Elasticsearch 进行系统性研究

点火三周
发布于 2026-06-22 12:08:59
发布于 2026-06-22 12:08:59
使用 LangChain 的 Deep Agents 框架与 Elasticsearch 进行系统性研究
Agent Builder 现已正式发布 (GA)。立即开始 Elastic Cloud 试用,并在此处查看 Agent Builder 的文档。
耗时较长的研究查询需要规划、委派以及跨多个来源进行交叉验证。一个带有工具的单一 Agent 可以处理简单的查找,但它在上下文限制方面存在困难,并且无法验证结论。本文将展示如何使用 LangChain 的 Deep Agents 框架来构建一个研究流水线,该流水线具备以下功能:
- • 使用由编排器管理的 TODO 列表来规划研究角度。
- • 将每个研究角度委派给具有独立上下文的专业子 Agent。
- • 将结构化研究结果存储在 Elasticsearch 中,并支持语义搜索。
- • 配置一个 Elastic Agent Builder Agent,以便团队无需编写查询即可探索结果。
研究流水线将如何工作?
它会提出一个复杂的问题,例如:“哪种 LLM 最适合小鼠癌细胞的生化分析?”,然后生成一组结构化、经过交叉验证的研究结果,这些结果存储在 Elasticsearch 中,团队成员可以通过 Kibana 随时探索。
该流水线分五步运行:
- 1. 规划: 编排器读取问题并编写一个 TODO 列表,将其分解为三到四个研究角度(例如,性能基准、领域特定能力、成本和可访问性)。
- 2. 研究: 对于每个研究角度,一个专业的子 Agent 会搜索网络并将每个发现与结构化元数据(证据类型、相关性评分和来源可信度)一起索引到 Elasticsearch 中。
- 3. 评估: 一个评估器子 Agent 查询 Elasticsearch,按角度聚合发现并评估证据质量。
- 4. 审查: 一个交叉审查器子 Agent 读取所有发现,标记矛盾之处,并识别不同来源之间的一致性。
- 5. 探索: 一个 Elastic Agent Builder Agent 会自动配置,以便您的团队可以用自然语言询问关于研究结果的问题。
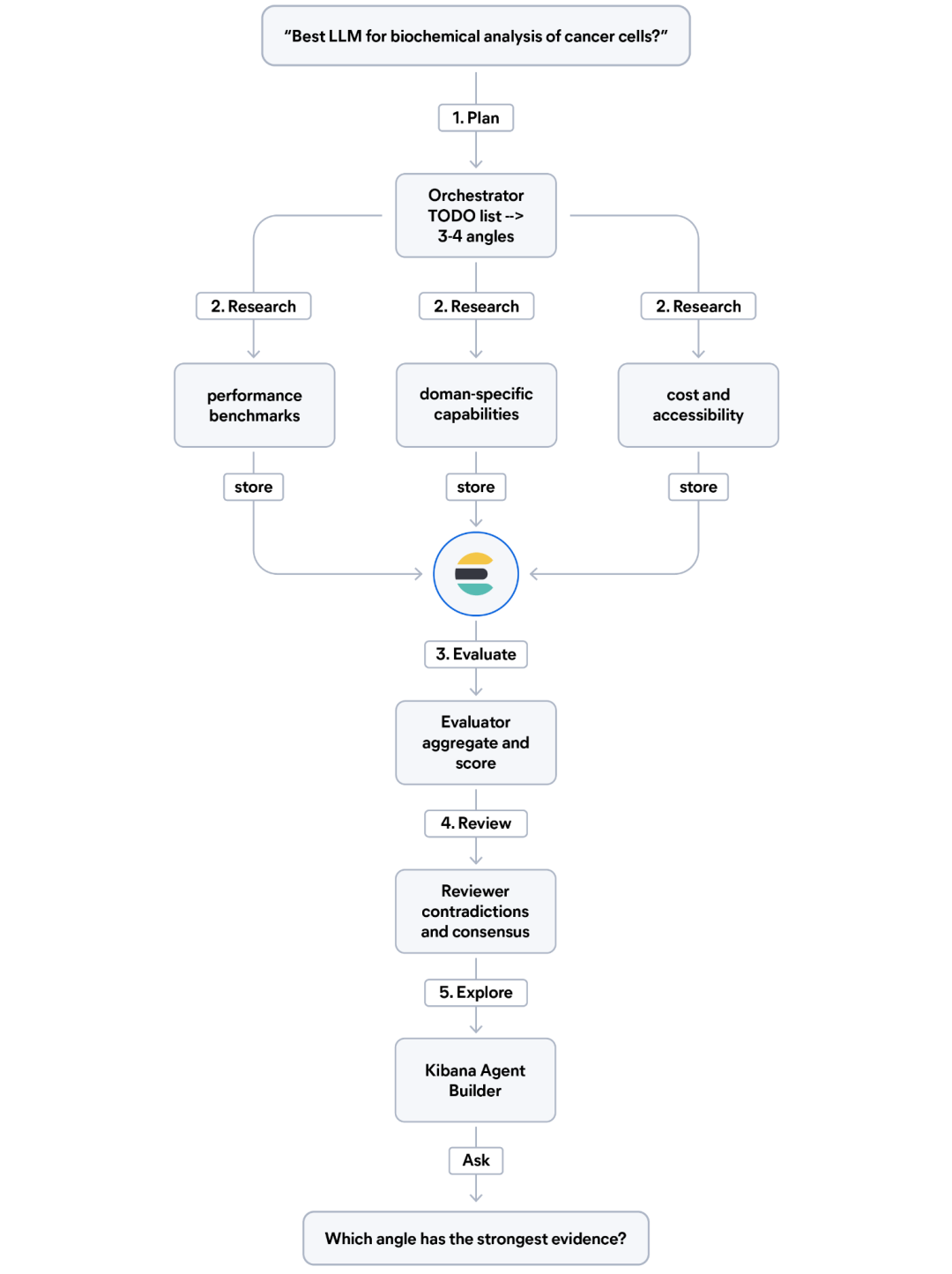
流程图展示了选择 LLM 的五步研究过程,包括规划、研究、评估、审查和探索阶段,每个步骤之间都有箭头连接,最后一个提示询问哪个角度的证据最强。
流程图展示了选择 LLM 的五步研究过程,包括规划、研究、评估、审查和探索阶段,每个步骤之间都有箭头连接,最后一个提示询问哪个角度的证据最强。
先决条件
- • Elasticsearch 集群 9.3+
- • Python 3.10+
- • Elasticsearch、Google Gemini 和 Tavily 的 API 密钥
- • 您的集群的
KIBANA_URL
什么是 LangChain Deep Agents?
Deep Agents 是 LangChain 的 Agent harness,一个基于 LangGraph 构建的预组装框架。它赋予您的 Agent 纯粹的大型语言模型 (LLM) 加上工具所不具备的开箱即用能力,例如:读写文件、使用结构化 TODO 列表管理长期运行的任务、生成具有独立上下文窗口的专业子 Agent,以及在多个步骤中持久化状态。
以下是它在 LangChain 生态系统中的位置:
框架 | 最适合 | 示例 |
|---|---|---|
LangChain | 可组合的构建块:提示、LLM、输出 | 总结文档、回答问题 |
LangGraph | 带有分支和循环的自定义有状态工作流 | 多步骤审批流水线、带有工具使用的聊天机器人 |
Deep Agents | 具有规划、子 Agent 和内存的长期自主研究 | 带有多 Agent 评估的系统性审查 |
Deep Agents 并非 LangGraph 的替代品。它是在 LangGraph 之上提供预组装架构的更高层级。当您调用 create_deep_agent() 时,您将获得一个编译好的 LangGraph 图,它完全支持流式传输、持久化和检查点。
Deep Agents 相较于纯粹的 LangGraph Agent,其主要新增功能包括:
- •
write_todos: 一个内置工具,强制编排器在执行前将复杂任务分解。这是一种上下文工程策略,而不仅仅是视觉辅助。它能让长期运行的工作流保持在正轨上。 - •
task: 一个内置工具,允许编排器生成子 Agent,每个子 Agent 都有自己独立的上下文窗口。编排器的上下文保持清晰,而专家则进行深入工作。 - • 文件 I/O 工具:
read_file、write_file、edit_file等,用于将大量结果卸载到磁盘,而不是将所有内容保留在上下文中。
对于系统性研究查询,一个带有工具的普通 Agent 能够搜索并存储发现,但它无法规划研究角度、将每个角度委派给专家,也无法交叉评估结果。Deep Agents 自动化了这种模式。
设计研究索引
此流水线中的一个关键决策是如何存储研究发现。原始文本并不理想,因为您需要回答诸如“哪些发现有同行评审证据?”或“哪些研究角度的来源最可靠?”之类的问题。
解决方案是将结构化元数据字段与由 Jina Embeddings v5 支持的 semantic_text 字段结合起来:
INDEX_NAME = "deep-agent-research"
INFERENCE_ID = ".jina-embeddings-v5-text-small"
index_body = {
"mappings": {
"properties": {
"query": {"type": "text", "copy_to": "semantic_field"},
"source": {"type": "keyword"},
"title": {
"type": "text",
"fields": {"keyword": {"type": "keyword"}},
"copy_to": "semantic_field",
},
"content": {"type": "text", "copy_to": "semantic_field"},
"timestamp": {"type": "date"},
"tags": {"type": "keyword"},
"research_angle": {"type": "keyword"},
"evidence_type": {"type": "keyword"},
"relevance_score": {"type": "float"},
"source_credibility": {"type": "keyword"},
"semantic_field": {
"type": "semantic_text",
"inference_id": INFERENCE_ID,
},
}
}
}
copy_to 模式将 query、title 和 content 字段路由到一个 semantic_text 字段中。Elasticsearch 在索引时自动生成 embeddings,无需摄入流水线。结构化元数据字段(research_angle、evidence_type、relevance_score、source_credibility)保持独立,用于过滤和聚合。
这种设计允许您在单个查询中按角度过滤、按可信度分组,并对所有发现运行语义搜索。
工具集
流水线中的每个 Agent 都只获取它所需的工具。这使得子 Agent 的行为可预测,并降低了专家执行超出其角色范围工作的风险。
三个工具为流水线提供支持:
- •
web_search: 封装 Tavily 以检索和格式化网络结果。仅由研究员子 Agent 使用。 - •
store_finding: 将结构化文档索引到 Elasticsearch 中。它强制执行元数据 Schema:调用者必须提供research_angle、evidence_type(benchmark、case_study、peer_reviewed、expert_opinion)、relevance_score(1.0-10.0)和source_credibility(peer_reviewed、preprint、industry_report、blog、documentation)。仅由研究员子 Agent 使用。 - •
query_elasticsearch: 接受原始 JSON Elasticsearch 查询体并返回响应。这赋予 Agent 完整的查询灵活性:匹配查询、聚合、术语过滤器等。由评估器和审查员子 Agent 用于分析已存储的发现,而无需编写新的发现。
@tool
def query_elasticsearch(query_body: str) -> str:
"""运行 Elasticsearch 查询并返回结果。接受包含有效 Elasticsearch 查询体的 JSON 字符串。
使用此工具搜索、过滤或聚合已存储的发现。示例:
- 匹配所有: {"query": {"match_all": {}}, "size": 5}
- 按标签聚合: {"size": 0, "aggs": {"by_tag": {"terms": {"field": "tags"}}}}
- 按角度过滤: {"query": {"term": {"research_angle": "performance"}}}
"""
es_client.indices.refresh(index=INDEX_NAME)
body = json.loads(query_body)
response = es_client.search(index=INDEX_NAME, body=body)
return json.dumps(response.body, default=str)
query_elasticsearch 中的 docstring 包含示例查询体。这是有意的:LLM 使用 docstring 来理解哪些查询是可能的,因此具体的示例可以提高子 Agent 的输出质量。
编排器和子 Agent
流水线有四个阶段:规划、研究、评估、审查。编排器通过委派给三个专业子 Agent 来驱动所有这四个阶段。
首先,定义子 Agent。每个子 Agent 只获取它所需的工具。angle-researcher 无法查询发现;finding-evaluator 和 cross-reviewer 无法存储新的发现。这种分离防止了评估器在评估期间添加发现,这会破坏评估结果。
from deepagents import create_deep_agent
from langchain_google_genai import ChatGoogleGenerativeAI
model = ChatGoogleGenerativeAI(model="gemini-3.1-flash-lite-preview", temperature=0)
angle_researcher = {
"name": "angle-researcher",
"description": (
"研究研究查询的特定角度。搜索网络,评估来源,并将每个发现 "
"与结构化元数据一起存储在 Elasticsearch 中。"
),
"system_prompt": (
"你研究科学查询的 ONE 个特定角度。\n"
"1. 使用 web_search 查找给定角度的 3-5 个相关来源。\n"
"2. 对于 EACH 有用的来源,调用 store_finding 并提供:\n"
" - research_angle: 分配给你的角度\n"
" - evidence_type: 'benchmark', 'case_study', 'peer_reviewed', 或 'expert_opinion'\n"
" - relevance_score: 1.0-10.0,基于它直接解决查询的程度\n"
" - source_credibility: 'peer_reviewed', 'preprint', 'industry_report', 'blog', 或 'documentation'\n"
"3. 返回你针对此角度发现的简要摘要。"
),
"tools": [web_search, store_finding],
}
finding_evaluator = {
"name": "finding-evaluator",
"description": (
"评估和分析已存储在 Elasticsearch 中的发现。按研究角度聚合,"
"计算平均分数,并识别哪些角度具有最强的证据。"
),
"system_prompt": (
"你分析存储在 Elasticsearch 中的研究发现。\n"
"使用 query_elasticsearch 来:\n"
"1. 按 research_angle 聚合发现并计算平均 relevance_score。\n"
"2. 按 source_credibility 聚合以评估证据质量。\n"
"3. 按 evidence_type 聚合以了解证据的组合。\n"
"4. 识别哪些角度具有最多和最强的发现。\n"
"返回结构化的评估摘要。"
),
"tools": [query_elasticsearch],
}
cross_reviewer = {
"name": "cross-reviewer",
"description": (
"审查所有已存储的发现,以识别研究角度之间的矛盾、共识和差距。"
"生成最终评估。"
),
"system_prompt": (
"你是一个研究发现的批判性审查员。\n"
"使用 query_elasticsearch 检索所有发现,然后:\n"
"1. 识别出现在多个角度的声明(共识)。\n"
"2. 标记来源之间的任何矛盾。\n"
"3. 注意哪些角度缺乏同行评审证据。\n"
"4. 根据证据生成最终的排名推荐。\n"
"保持怀疑态度。优先考虑同行评审的来源,而不是博客。"
),
"tools": [query_elasticsearch],
}
现在,创建编排器并将其与子 Agent 连接起来。编排器的系统提示强制执行四阶段序列作为编号程序;这是您从长期运行的 Agent 获得可靠行为的方式。子 Agent 具有独立的上下文窗口:每次调用 task 都会启动一个全新的上下文,因此编排器的上下文不会随着每次委派而增长。这是 Deep Agents 在长期运行工作方面的核心架构优势。
agent = create_deep_agent(
model=model,
tools=[web_search, store_finding, query_elasticsearch],
subagents=[angle_researcher, finding_evaluator, cross_reviewer],
system_prompt=(
"你是一个系统性研究编排器。对于每个查询:\n\n"
"1. 规划 (PLAN): 使用 write_todos 将查询分解为 3-4 个研究角度 "
"(例如,'性能基准'、'成本和可访问性'、'领域特定能力')。\n\n"
"2. 研究 (RESEARCH): 对于每个角度,使用 task 工具委派给 'angle-researcher' 子 Agent。 "
"每次子 Agent 调用都应指定角度和原始查询。\n\n"
"3. 评估 (EVALUATE): 委派给 'finding-evaluator' 以分析已存储的发现 "
"并评估跨角度的证据质量。\n\n"
"4. 审查 (REVIEW): 委派给 'cross-reviewer' 以交叉检查发现,标记 "
"矛盾之处,并生成共识分数。\n\n"
"5. 综合 (SYNTHESIZE): 撰写最终报告,根据证据总结最佳答案,"
"并注明置信水平和差距。\n\n"
"完成每个 TODO 后将其标记为已完成。"
),
)
运行流水线
流水线以流式传输方式运行,以实时显示进度。subgraphs=True 标志会暴露来自子 Agent 的事件以及编排器自身的事件:
research_query = (
"What is the best LLM for biochemical analysis of cancer cells in mice?"
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": research_query}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
is_subagent = any(segment.startswith("tools:") for segment in chunk["ns"])
if is_subagent:
tool_call_id = next(
s.split(":")[1] for s in chunk["ns"] if s.startswith("tools:")
)
print(f"Subagent {tool_call_id}: {chunk['data']}")
else:
print(f"Main agent: {chunk['data']}")
在执行期间,您可以观察编排器在委派之前调用 write_todos 并包含研究角度。每次 task 调用都会将任务交给一个子 Agent,chunk["ns"] 中的事件允许您区分子 Agent 的输出与编排器自身的步骤。
Main agent: {'PatchToolCallsMiddleware.before_agent': {'messages': Overwrite(value=[HumanMessage(content='What is the best LLM for biochemical analysis of cancer cells in mice?', additional_kwargs={}, response_metadata={}, id='906965ba-4c4c-48cb-8663-6fcfa7b9a2b6')])}}
Main agent: {'model': {'messages': [AIMessage(content=[], additional_kwargs={'function_call': {'name': 'write_todos', 'arguments': '{"todos": [{"content": "Research LLMs specialized in bioinformatics and biomedical data analysis.", "status": "in_progress"}, {"status": "pending", "content": "Investigate LLM capabilities for processing biochemical assay data (e.g., proteomics, transcriptomics) in cancer research."}, {"status": "pending", "content": "Evaluate LLM performance in mouse model studies and preclinical cancer research."}, {"status": "pending", "content": "Synthesize findings to identify the most suitable LLM or approach for biochemical analysis of cancer cells in mice."}]}'}, '__gemini_function_call_thought_signatures__': {'6bba74f0-41b3-4fc3-b512-27529e99d981': 'EjQKMgG+Pvb7HjHZXrWuOEjj94E8IYS+aAKgZKjvzB8MqxveU5GAhsoq5icieLF6V70r4SfS'}}, ...
流水线在同一会话中处理多个查询。所有查询的发现都累积在同一个 Elasticsearch 索引中,这使得最终的 Agent Builder 探索更加有趣。例如,同时运行“哪种 LLM 最适合生化分析?”和“哪种前端框架最适合 Deep Agent 服务?”会将来自不同领域的发现存储在同一个索引中,Agent Builder 可以比较两者的模式。
使用 Elastic Agent Builder 探索发现
流水线运行后,所有发现都存储在 Elasticsearch 中,但大多数团队成员无法编写 Elasticsearch 查询。Elastic Agent Builder 之所以非常适合这里,是因为它能让您从索引数据快速转换为可用的 Agent,供团队使用。在这种情况下,只需几个 API 调用就足以创建一个基于研究发现的 Agent。让我们以编程方式创建一个,以便人们可以通过 Kibana UI 探索这些发现。
首先,创建一个 Elasticsearch Query Language (ES|QL) 工具,用于聚合研究索引:
tool_body = {
"id": "research-findings-tool",
"type": "esql",
"description": (
"查询 deep-agent-research 索引以探索已存储的发现。 "
"返回按研究角度和来源可信度分组的平均相关性分数和计数。"
),
"configuration": {
"query": (
"FROM deep-agent-research "
"| STATS avg_score = AVG(relevance_score), count = COUNT(*) BY research_angle, source_credibility"
),
"params": {},
},
}
resp = requests.post(
f"{KIBANA_URL}/api/agent_builder/tools", headers=headers, json=tool_body
)
然后创建 Agent Builder Agent,并附加该工具:
agent_body = {
"id": "research-explorer",
"name": "Research Explorer",
"description": "探索和分析来自 deep-agent-research 索引中存储的研究发现。",
"configuration": {
"instructions": (
"你帮助用户探索存储在 Elasticsearch 中的研究发现。 "
"使用 research-findings-tool 按角度查询发现,"
"总结证据质量,并回答有关已存储研究的问题。"
),
"tools": [{"tool_ids": ["research-findings-tool"]}],
},
}
resp = requests.post(
f"{KIBANA_URL}/api/agent_builder/agents", headers=headers, json=agent_body
)
创建后,Research Explorer 将出现在 Kibana 的 Agent Builder UI 中。团队成员可以打开它并用自然语言提问:
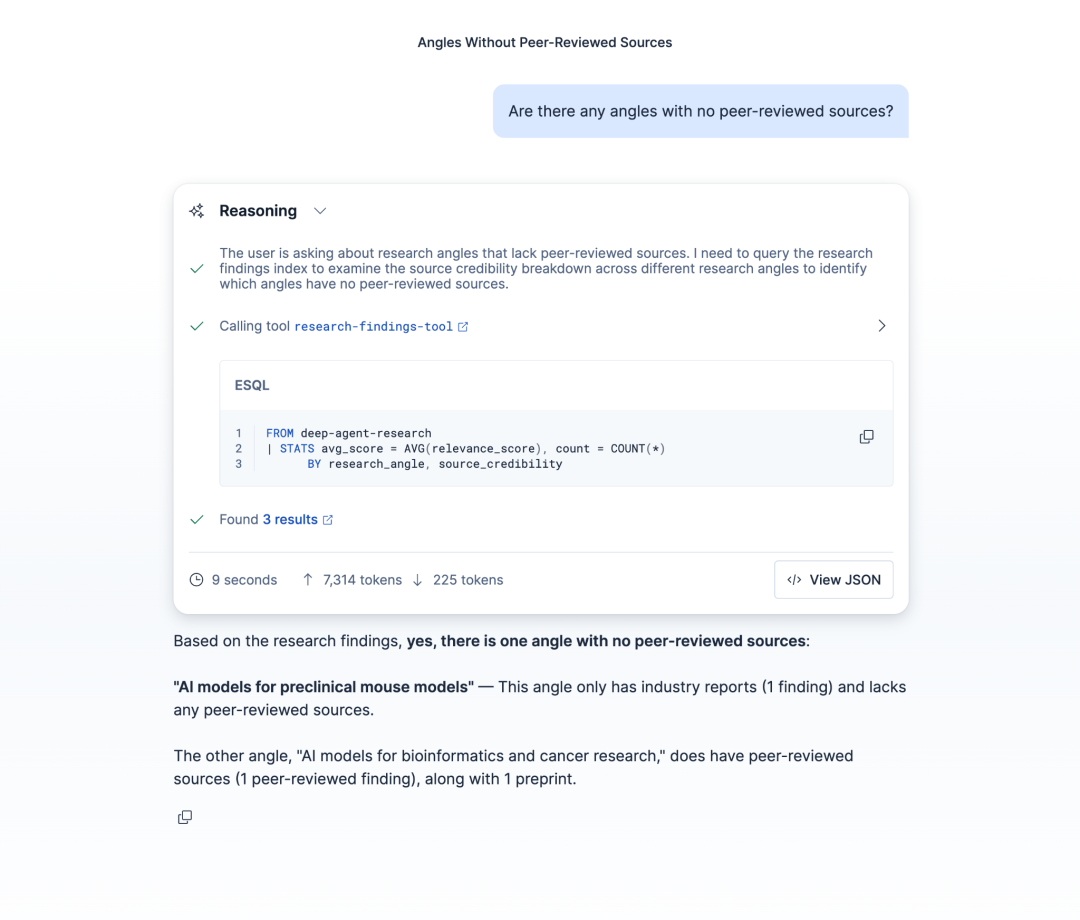
界面展示了一个关于没有同行评审来源的研究角度的查询,包括推理部分、ESQL 代码块、结果计数以及一个总结,指明一个角度只有行业报告而没有同行评审来源。
界面展示了一个关于没有同行评审来源的研究角度的查询,包括推理部分、ESQL 代码块、结果计数以及一个总结,指明一个角度只有行业报告而没有同行评审来源。
该 Agent 使用 ES|QL 工具查询索引并总结结果。无需编写任何查询。
这是一个完整的循环:Deep Agents 进行系统性研究,Elasticsearch 存储结构化发现,而 Agent Builder 使团队中的任何人都可以访问这些发现。
结论
我们涵盖了以下内容:
- • 用于长期研究的 Deep Agents:
write_todos强制在执行前进行规划,而task工具将每个研究角度委派给具有独立上下文窗口的子 Agent。这种模式处理了可能使单一 Agent 不堪重负的查询。 - • Elasticsearch 作为结构化知识存储: 将
research_angle、evidence_type、relevance_score和source_credibility与semantic_text一起存储,从而实现语义搜索和研究质量的结构化聚合。原始文本存储将不支持评估器和审查员 Agent。 - • Agent Builder 作为访问层: 在流水线结束时以编程方式配置 Kibana Agent 意味着可以通过 UI 立即探索发现,无需任何手动设置。
这种模式适用于任何需要从多个角度研究问题并交叉验证结果的领域:竞争情报、科学文献综述、法规遵从研究或多源事实核查。
后续步骤
- • 在 GitHub 上尝试完整笔记本。
- • 使用 LangGraph 的中断模式向流水线添加人工干预 (human-in-the-loop) 审批门。
- • 了解如何使用 Elastic Agent Builder 和 Model Context Protocol (MCP) 构建 Agent 应用程序的参考架构。
- • 扩展 Agent Builder 中的 ES|QL 工具 以支持参数化查询,用于按角度或日期范围进行过滤。
📡 更多 Elastic & AI 可观测性干货
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号