您的搜索索引本身就是智能体记忆系统:为 Claude Code 提供基于 Elasticsearch 的持久化智能体记忆

您的搜索索引本身就是智能体记忆系统:为 Claude Code 提供基于 Elasticsearch 的持久化智能体记忆

点火三周
发布于 2026-06-22 12:12:28
发布于 2026-06-22 12:12:28
您的搜索索引本身就是智能体记忆系统:为 Claude Code 提供基于 Elasticsearch 的持久化智能体记忆
当您需要为 AI 智能体提供持久化记忆时,通常的答案是使用专门构建的记忆层,例如专用的记忆编排服务和独立的向量数据库。这些确实是解决方案,但它们也意味着又一个服务、又一个 API、又一项需要构建和维护的工作。如果您的技术栈中已经有 Elasticsearch,那么您可能已经拥有所需的一切。
仅会话记忆的问题
Claude Code 智能体是无状态的。每个会话都从零开始。您的智能体不记得它昨天做出的决定、上周重构的文件,或三天前标记的阻塞依赖项。如果指定文件,它可以读取它们,但读取文件与回忆相关上下文不同。
由此产生的具体成本体现在几个方面:
- • 重复推导结论。 一个不记得之前推理过程的智能体,会重复读取相同的文件,重新审视相同的权衡,有时甚至会得出不同的答案。开发者最终会面临跨会话的智能体行为不一致,却不明白原因。
- • 多设备协作摩擦。 跨多台机器工作的开发者对此感受尤为强烈。如果没有跨设备记忆,切换机器意味着需要从头加载智能体的上下文:
git pull、搜索相关文件,并手动将项目状态粘贴到对话中。这给每次交接都带来了摩擦成本。 - • 会话间上下文丢失。 智能体生成的最有用的信息——架构决策、阻塞依赖项的任务 ID、方法变更的理由、解释为何选择特定路径的上下文锚点——都存在于工作记忆中,并在会话结束时消失。文件提交捕获的是产物,而不是推理过程。
常见的解决方案是专门构建的记忆层或独立的向量数据库。这些工具都很可靠。但如果您的系统已经运行了 Elasticsearch,那么再添加一个服务到您的技术栈中,可能是您不需要的额外开销。
您的搜索索引已具备的功能
在具体探讨 agent-memory 之前,有必要先了解 Elasticsearch 无需任何自定义即可为该问题带来的优势。
- • 开箱即用的混合搜索。 Elasticsearch 将 BM25 词法评分与密集向量搜索结合。
semantic_text字段类型会自动处理嵌入生成。将字段映射为semantic_text,并将其指向推理端点,您无需自行管理嵌入管道即可获得混合召回。 - • 通过 ES|QL 实现查询表达能力。 在 Elasticsearch 中,您的记忆是可使用完整查询语言进行查询的文档。ES|QL 允许您按类型、日期范围、智能体 ID、访问范围或任意组合进行过滤,还支持聚合、时间函数以及用于多检索融合的
FUSE。ES|QL 是一种带有聚合、时间函数和 FUSE 的完整查询语言,比大多数向量存储公开的元数据过滤功能更广泛。一些专用向量存储提供了更具表达力的查询接口,但与该类别中常见的轻量级过滤 API 相比,差距最大。 - • 语义评分前的元数据过滤。 跨智能体的作用域记忆、时间窗口、基于类型的过滤:所有这些都是标准的 Elasticsearch 查询行为。您无需构建自定义逻辑,只需组合现有原语即可。
- • 通过
BRIDGE_MEMORY_DECAY_WINDOW实现时间衰减。 在混合召回部分将详细介绍,但系统会应用近期权重,使近期记忆的排名高于陈旧记忆。这使用了 ES|QL 中的 ElasticsearchDECAY函数。注意:DECAY需要 Elasticsearch 9.3+ 或 Elasticsearch Serverless。使用时间间隔字面量语法 —45 days(而不是带引号的字符串"45d"),因为某些 Serverless 部署会拒绝带引号的形式。如果您仍然看到类型错误(third argument of [DECAY(...)] must be [time_duration]),请改用备用评分:EVAL final_score = _score / (1 + DATE_DIFF("day", created_at, NOW()) / 45.0)。备用方案会产生等效的近期权重,并适用于所有版本。 - • 您已有的运维体系。 监控、告警、索引生命周期管理、备份:您已经为您的 Elasticsearch 部署拥有了这些。添加更多索引不会增加新的运维负担。
记忆存储的实际索引映射显示了其模式的简单性:
{
"mappings": {
"properties": {
"memory_id": { "type": "keyword" },
"agent": { "type": "keyword" },
"type": { "type": "keyword" },
"category": { "type": "keyword" },
"title": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },
"title_semantic": { "type": "semantic_text", "inference_id": "jina-v5-embeddings" },
"content": { "type": "text" },
"content_semantic": { "type": "semantic_text", "inference_id": "jina-v5-embeddings" },
"tags": { "type": "keyword" },
"source": { "type": "keyword" },
"created_at": { "type": "date" },
"updated_at": { "type": "date" },
"access_scope": { "type": "keyword" }
}
}
}semantic_text 字段(title_semantic、content_semantic)是 Jina v5 嵌入的存储位置。Elasticsearch 通过推理端点在索引时处理嵌入生成。您写入一个记忆文档,嵌入会自动计算。在 Elasticsearch Serverless 上,semantic_text 默认通过 Elastic Inference Service 使用 Jina v5 text-small 模型。
实际上,Elasticsearch 在这里有两点与众不同:
- • 查询表达能力。 ES|QL 是一种完整的查询语言,而不是一个过滤 API。您可以在一个查询中结合基于嵌入的检索、精确匹配、时间衰减和聚合。
- • 运维整合。 如果 Elasticsearch 已经存在于您的技术栈中,这只是又一个索引,而不是另一个服务。其他向量数据库也允许您定义模式,但区别在于定义后您可以做什么,以及是否会增加新的运维依赖。
agent-memory 架构
agent-memory 是一个层,它使 Elasticsearch 能够作为 Claude Code 智能体的专用记忆系统。入口点是一个名为 bridge 的 CLI。其背后有七个 Elasticsearch 索引。
各部分协同工作如下:
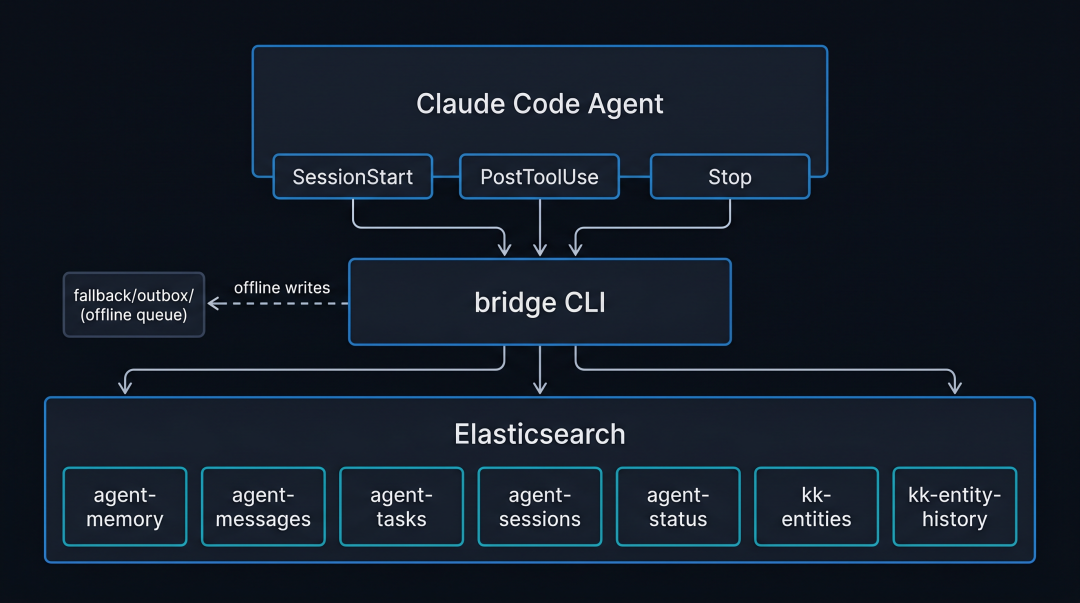
agent-memory architecture
agent-memory architecture
Claude Code 智能体完全通过 bridge CLI 与 Elasticsearch 通信。三个钩子自动将 bridge 挂接到智能体生命周期中,无需智能体显式调用。当 Elasticsearch 可达时,bridge 直接写入。离线时,写入会进入本地 fallback/outbox/ 队列作为 JSON 文件,bridge sync 会在下次在线会话时通过批量 API 清空该队列。
在 bridge 背后,Elasticsearch 维护着七个索引:agent-memory(决策、模式、上下文)、agent-messages(智能体间通信)、agent-tasks(任务生命周期)、agent-sessions(操作历史)、agent-status(心跳)、{agent}-entities(Markdown 知识图谱)和 {agent}-entity-history(用于差异比较的时间快照)。bridge graph 命令(search、related、check-blockers、semantic-diff 和 gen-handoff、reconcile)对实体索引进行操作。
七个索引
索引 | 存储内容 |
|---|---|
agent-memory | 决策、模式、上下文、反馈(记忆存储) |
agent-messages | 智能体之间带线程和优先级支持的类型化消息 |
agent-tasks | 从创建到完成或失败的任务生命周期 |
agent-sessions | 会话级操作日志,可按智能体、时间范围或标签查询 |
agent-status | 心跳记录:哪些智能体在哪些机器上处于活跃状态 |
{agent}-entities | 作为可搜索知识图谱实体的 Markdown 文件 |
{agent}-entity-history | 实体状态快照,用于时间差异比较 |
钩子集成
集成点是钩子。三个 Claude Code 钩子将系统连接到正常的智能体行为中,无需显式调用:
- • SessionStart:运行
bridge sync-memories将自动记忆文件同步到 Elasticsearch,并运行bridge heartbeat注册智能体为活跃状态。 - • PostToolUse(在 Write、Edit、MultiEdit 时触发):在每次
.md写入时调用bridge entity index-file。您的项目文件在您工作时会持续被索引。 - • Stop:将会话结束事件记录到
agent-sessions。
结果是:智能体无需记住更新记忆。它会自动发生。SessionStart 同步会散列本地记忆文件,并且只重新索引已更改的文件——未更改的文件会被跳过。首次会话同步(所有文件都是新的)比后续会话需要更长的时间。
离线队列
当 Elasticsearch 不可达时,写入不会失败。它们会作为 JSON 文件存储在 fallback/{agent}/outbox/ 中。当连接恢复时,bridge sync(在 SessionStart 时自动调用)会通过批量 API 清空队列。您可以离线工作,不会丢失任何内容。当 ES 不可达时,读取(bridge recall、bridge graph search)会优雅地失败并返回非零退出代码。没有本地读取缓存。然而,智能体会话会正常继续,但记忆功能会降级。回退队列没有自动大小限制。对于长时间离线的情况,请使用 bridge sync --batch-size 100 进行同步,以避免过大的批量请求。
智能体直接使用的 bridge CLI 命令:
# 存储带有类型和范围的决策
bridge remember decision "Use Jina v5 for all embedding inference" \
--title "embedding model choice" \
--tags "ml,infrastructure" \
--scope shared
# 使用混合搜索进行召回(默认)
bridge recall "embedding model decisions"
# 仅使用关键词进行召回(精确术语匹配)
bridge recall "Jina v5" --keyword
# 知识图谱搜索
bridge graph search "blocked infrastructure projects" --types initiative --days 90
# 生成跨设备交接载荷
bridge graph gen-handoff --hours 8
# 找出陈旧的阻塞项
bridge graph check-blockers --stale-days 3混合召回:记忆检索的实际工作方式
许多智能体记忆的实现都使用单一的向量查找。查询输入,余弦相似度找到最近邻,然后返回结果。这适用于语义召回,但在两种常见模式上会失败:精确术语匹配和近期性。
agent-memory 的混合召回使用两种融合策略。记忆召回查询使用 ES|QL 的 FUSE(Reciprocal Rank Fusion,k=60,ES|QL 默认值)。图实体查询使用 FUSE LINEAR 并带有显式权重——0.3 BM25 / 0.7 语义——因为实体搜索从语义匹配中受益更多。这是 lib/memory.sh 中的记忆召回查询:
FROM agent-memory METADATA _id, _score, _index
| FORK (
WHERE (access_scope == "shared" OR access_scope == "kk-only" OR agent == "kk")
AND (content:"vector search" OR title:"vector search" OR tags:"vector search")
| SORT _score DESC | LIMIT 50
) (
WHERE (access_scope == "shared" OR access_scope == "kk-only" OR agent == "kk")
AND content_semantic:"vector search"
| SORT _score DESC | LIMIT 50
)
| FUSE
| EVAL final_score = _score * DECAY(created_at, NOW(), 45 days)
| EVAL display = COALESCE(title, SUBSTRING(content, 1, 80))
| SORT final_score DESC | LIMIT 5
| KEEP memory_id, type, display, access_scope, agentFORK 并行运行两次检索:第一个分支对标题、内容和标签进行 BM25 词法搜索;第二个分支对 content_semantic 字段进行语义搜索。FUSE 使用 Reciprocal Rank Fusion 合并这两个排名列表。DECAY 函数根据 created_at 应用时间权重。
为什么混合搜索在智能体记忆方面优于纯语义搜索
关键词查找可以捕获语义搜索遗漏的精确引用。如果智能体存储了一条关于“任务 ID kk-task-20260428-deploy-blocker”的记忆,对“deploy blocker”的语义查询会找到概念上相似的内容,但特定的任务 ID 只会在 BM25 分支中获得高排名。没有它,您会得到概念,但无法获得所需的引用。
语义搜索可以捕获精确匹配遗漏的相关概念。一条标题为“将默认分块策略切换到句子级别,以在短查询上获得更好的召回”的记忆,与“分块配置”的查询相关,尽管这些词没有重叠。语义分支会找到它;仅靠关键词搜索则不会。
BRIDGE_MEMORY_DECAY_WINDOW 变量(默认为 45d)设置了时间衰减函数的半衰期。在其他条件相同的情况下,今天写入的记忆比 90 天前写入的相同记忆得分更高。这反映了智能体记忆在实践中的实际工作方式:最近的上下文几乎总是比旧上下文更相关,即使旧上下文在语义上更接近查询。
lib/graph.sh 中的图搜索使用 FUSE LINEAR(而不是普通的 FUSE),因为实体召回从语义匹配中受益更多,而不是关键词精确度。这是该查询:
FROM kk-entities METADATA _id, _score, _index
| FORK (
WHERE MATCH(title, "vector search projects") OR MATCH(content, "vector search projects")
| WHERE updated_at >= NOW() - 180 days
| SORT _score DESC | LIMIT 20
) (
WHERE MATCH(title_semantic, "vector search projects") OR MATCH(content_semantic, "vector search projects")
| WHERE updated_at >= NOW() - 180 days
| SORT _score DESC | LIMIT 20
)
| FUSE LINEAR WITH { "weights": { "fork1": 0.3, "fork2": 0.7 }, "normalizer": "minmax" }
| SORT _score DESC | LIMIT 10
| KEEP _id, entity_id, entity_type, title, status, priority, updated_at带有显式权重的 FUSE LINEAR 语法是您在 ES|QL 中调整 BM25/语义平衡的方式。将权重偏向 0 可获得更高的关键词精度;偏向 1 可获得更高的语义泛化能力。
知识图谱层
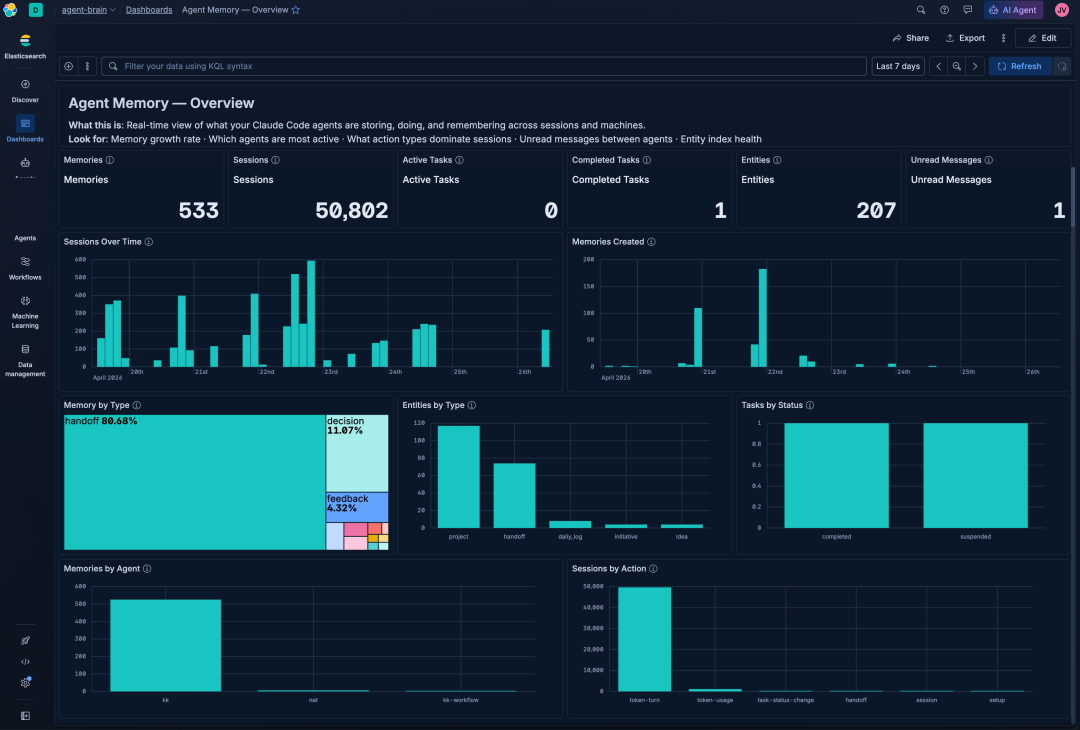
Agent Memory — Kibana Overview Dashboard showing 533 memories, 50,802 sessions, 207 entities, and memory/entity breakdowns
Agent Memory — Kibana Overview Dashboard showing 533 memories, 50,802 sessions, 207 entities, and memory/entity breakdowns
运行中的实例数据显示:跨会话跟踪了 533 条记忆、50,802 个会话、207 个实体以及每个项目、决策和阻塞依赖项;从 frontmatter 字段(initiative、blocked_by、depends_on)解析出大约 1,364 条关系边。这些是 Kuchi Kopi 智能体实例在两台笔记本电脑上运行数月后获得的真实数据。
需要提前说明:这不是图数据库。遍历深度上限为 2,没有 Cypher 查询语言或属性图模型,并且一致性完全取决于一致的 frontmatter。它的作用是一个可查询的实体层,包含足够的关系数据,可以发现智能体工作中的阻塞项和差异。
此索引存储的是智能体自身随时间推移的工作记录(决策、项目状态和阻塞依赖项),而不是外部事实或世界知识的精选知识库。检索是通过嵌入相似度和对该工作记录的 BM25 实现的。
实体层是基于 Elasticsearch 文档构建的知识图谱。通过 PostToolUse 钩子,监视目录中的每个 Markdown 文件都被索引为一个实体。实体 ID 为 {agent}-{type}-{slug},这使得重新索引具有幂等性。重写文件后,实体会在原地更新。关系边从三个 frontmatter 字段中提取:initiative(父级分组)、blocked_by(依赖项)和 depends_on(软依赖项)。实体 ID 通过 {agent} 前缀按智能体进行命名空间划分——不检查跨智能体冲突,因此运行多个智能体的团队应强制执行唯一的智能体标识符。
图命令对该索引进行操作:
# 对所有实体进行混合语义搜索
bridge graph search "infrastructure blockers"
# 从特定实体遍历关系(深度 1 或 2)
bridge graph related kk-initiative-platform --depth 2 --rel-type blocks
# 找出陈旧的阻塞或等待实体
bridge graph check-blockers --stale-days 3
# 比较两个日期之间的实体状态差异
bridge graph semantic-diff 2026-04-01 2026-04-20
# 生成用于跨设备交接的结构化上下文载荷
bridge graph gen-handoff --hours 8
# 移除源文件不再存在的 ES 实体
bridge graph reconcile关系边是从 Markdown 文件本身中存在的 frontmatter 字段(initiative、blocked_by、depends_on)推断出来的。该图谱不需要单独的关系存储。它读取您现有的文档结构。
图谱之所以具有一致性,是因为 Markdown 文件具有结构化的 frontmatter,并且系统能够一致地读取该结构。模式规范是其工作的基础。如果您的文件没有一致的 frontmatter 字段,图谱将退化为扁平的实体搜索。缺少或格式错误的 frontmatter 字段会导致关系边被静默跳过;实体仍会被索引,但不会出现在图谱遍历中。运行 bridge graph reconcile 可以找出缺少关系的实体。实体删除不会级联,并且 bridge graph reconcile 还会修剪指向已删除实体的边。
就规模而言,这已在数月活跃使用中,针对数百个实体进行了测试。Elasticsearch 应该能够处理更大的语料库,但 agent-memory 尚未进行大规模负载测试。对于非常大的实体集,请使用 --types 和 --days 过滤器来限制遍历范围。
graph semantic-diff 命令是更有用的应用之一。它比较两个日期之间的实体状态快照:新实体、状态变更、新阻塞的工作和已完成项。在每周同步之前运行它,可以为您提供智能体所做工作的结构化变更日志,而无需阅读每个会话日志。注意:如果请求的日期范围没有实体快照,该命令会返回错误(Cannot iterate over null)。请先运行 bridge entity index-all 以填充初始快照基线。
实践中的跨设备记忆
我在我的旅行笔记本电脑上开始了一个会话,三天前我曾在我公司的两台机器上,用我的办公工作站处理一个项目。智能体在一个搜索往返中回忆起了相关的记忆条目。没有等待 git pull。没有文件扫描来重建上下文。跨设备交接通过 Elasticsearch 完成。
原因如下:我在两台机器上工作,并且 Elasticsearch 在两台机器上都可访问。共享索引是真相的来源,而不是本地文件系统。智能体调用 bridge recall 并从共享索引获取上下文,无论哪个机器存储了它。
没有 agent-memory:除了 Git 仓库中的内容,什么都没有。智能体可以读取文件,但它无法回忆起上一个会话的推理过程、未在任何提交中捕获的决策,或者已标记但尚未解决的阻塞依赖项。
使用 agent-memory:SessionStart 钩子运行 bridge sync-memories,它会读取 Claude Code 的自动记忆文件(~/.claude/projects/<cwd>/memory/*.md),对每个文件进行哈希,并只将更改的文件重新索引到 Elasticsearch 中。本地记忆文件被视为每台机器上的事实来源,bridge sync-memories 将本地状态推送到 Elasticsearch。在切换之前未推送的在另一台机器上进行的编辑将被新机器的本地状态覆盖。Elasticsearch 的文档版本控制可以正确处理来自两台设备的并发写入。不会丢失数据,但每个文档以最后一次写入为准,因此请避免同时在两台机器上编辑相同的记忆文件。
坦诚的警告:这需要 Elasticsearch Serverless(或可从两台机器访问的任何 Elasticsearch 实例)。位于 VPN 或防火墙后面的自管理 Elasticsearch 也可以工作,但连接性要求是真实的。这不是一个纯本地解决方案。
bridge graph gen-handoff 命令生成一个结构化的 JSON 载荷,涵盖了在窗口内更新的实体、活跃的阻塞项和最近的会话日志。通过可选的 --synthesize 标志,它会通过 Agent Builder 智能体生成一个叙述性段落。该载荷是新会话加载以重建上下文而无需读取单个文件的内容。
何时适用此方案(何时不适用)
这种方法在以下情况中效果良好:
- • 您的技术栈中已包含 Elasticsearch。 在现有部署中添加索引的摩擦力很小。运维体系是您熟悉的。
- • 查询表达能力很重要。 您希望使用完整的查询语言,而不是供应商的过滤 API,将记忆作为数据进行查询。
- • 您的智能体生成结构化产物。 带有一致 frontmatter 的 Markdown 文件是知识图谱保持一致性的基础。如果您的智能体不生成结构化输出,图层不会增加太多价值。
- • 您需要跨设备或跨智能体的记忆。 共享的 Elasticsearch 索引无需额外基础设施即可实现此功能。
当以下情况出现时,专用记忆服务更具优势:
- • 您没有现有的搜索基础设施。 从 Elasticsearch 开始解决记忆问题是合理的,但它是一项重要的基础设施投入。
- • 您希望纯粹的语义召回,且无需任何模式管理。 专用的向量数据库服务完全抽象了索引映射。如果您不想考虑映射和字段,这种权衡是有价值的。
- • 您预期频繁的模式演进。 您控制的模式也是您维护的模式。如果您的记忆结构需要随时间变化,自管理索引映射的迁移开销可能会超过其灵活性。专用服务通常会为您处理模式演进。
- • 您需要一个运维开销最小的托管 SaaS 服务。 Elasticsearch Serverless 大幅缩小了这一差距,但并非零开销。
坦率地说:agent-memory 并非万能答案。如果您已经运行 Elasticsearch 并希望避免为 AI 技术栈增加额外的依赖,那么它才是正确的选择。
开始使用
三个命令即可启动运行系统:
git clone https://github.com/jeffvestal/agent-memory && cd agent-memory
./install.sh
./bridge statusinstall.sh 会交互式地引导您完成凭据设置(或读取现有的 .env 文件),如果 Jina v5 语义推理端点不存在,则会创建它,创建所有七个具有正确映射的索引,并安装 Claude Code 钩子。它是幂等的。如果出现问题或添加新机器,可以重新运行它。
运行安装程序前需要了解的一些事项:
- • Jina v5 推理端点:在自管理 Elasticsearch 上,安装程序会创建此端点,但它需要
service_settings中的 Jina API 密钥。在 Elasticsearch Serverless 上,Elastic Inference Service 会自动提供 Jina v5,无需 API 密钥;安装程序会检测到 Serverless 并跳过此步骤。 - • Elasticsearch Serverless vs. 9.3+:两者都适用。召回查询中使用的
DECAY函数和FUSE语法需要 Serverless 或 Elasticsearch 9.3+。 - • 仪表板导入:当
.env中设置了KIBANA_URL时,Kibana 仪表板(位于setup/dashboards/)将由install.sh自动导入。如果您跳过了该步骤,请设置KIBANA_URL并重新运行install.sh(它是幂等的)。
您需要:
- • 一个 Elasticsearch Serverless 端点(或 Elasticsearch 9.3+)。
- • 一个对
agent-*索引具有索引权限的 API 密钥。 - • 本地安装
jq(在 macOS 上使用brew install jq)。
bridge status 确认连接后,运行:
bridge entity index-all # 索引现有 Markdown 文件
bridge remember decision "First memory — install confirmed working" --title "setup"
bridge recall "install" # 确认混合召回工作正常然后将 hooks/settings.json.template 中的钩子添加到您的 Claude Code settings.json 中。从那时起,每个会话开始、文件写入和会话结束都会自动更新记忆存储。
包括用于记忆分析的 Kibana 仪表板在内的完整源代码位于 github.com/jeffvestal/agent-memory。
请在您的智能体上试用。如果您遇到问题或将其扩展到不同的 AI 框架,请提出 issue 或 PR。
常见问题
什么是智能体记忆?AI 智能体为何需要它?
像 Claude Code 这样的 AI 智能体在会话之间是无状态的:一旦会话结束,它们就没有了之前对话、决策或上下文的记忆。智能体记忆是一个持久化存储,允许智能体在不同会话和设备之间回忆先前的推理、决策和项目上下文。没有它,智能体会重复推导结论,在多设备工作流中丢失上下文,并且无法在之前的工作基础上进行构建。
Elasticsearch 能否取代专用向量数据库作为智能体记忆系统?
对于已经运行 Elasticsearch 的团队来说,是的,并且具有显著优势。Elasticsearch 通过 semantic_text 字段提供混合 BM25 + 语义搜索,通过 ES|QL 提供对记忆的结构化查询访问,支持元数据过滤和时间衰减评分。权衡在于您需要自行管理模式和运维。专用向量数据库抽象了这些,如果您没有现有的搜索基础设施,这会是正确的选择。
混合搜索如何比纯语义搜索更好地改善智能体记忆召回?
纯语义搜索匹配概念上相似的内容,但会错过精确引用:任务 ID、文件名、特定版本号。纯关键词搜索可以捕获精确匹配,但会错过相关概念。混合搜索(BM25 + Jina v5 密集向量通过 Reciprocal Rank Fusion 结合)可以同时处理这两种情况。在实践中,这意味着无论您是在搜索概念还是特定标识符,都能召回正确的记忆。
agent-memory 项目是什么?如何安装它?
agent-memory 是一个开源层,为 Claude Code 智能体提供由 Elasticsearch 支持的持久化、跨会话、跨设备的记忆。通过三个命令即可安装。安装脚本会自动创建 Elasticsearch 索引和推理端点。
跨设备记忆如何在多台机器之间工作?
在会话开始时,SessionStart 钩子会运行 bridge sync-memories,它将 Claude Code 的自动记忆文件同步到 Elasticsearch。由于两台机器都指向同一个 Elasticsearch 实例,因此无论哪台机器写入,召回的记忆都是一致的。切换笔记本电脑无需 git pull 或手动重建上下文。智能体调用 bridge recall 并从共享索引获取上下文。
使用 Elasticsearch 作为智能体记忆系统有哪些限制?
主要限制:跨设备记忆需要 Elasticsearch Serverless(或可网络访问的集群),这不是一个纯本地解决方案。知识图谱遍历深度上限为 2。图谱的一致性取决于 Markdown 文件中一致的 frontmatter;松散的模式规范会降低图谱质量。Elasticsearch 也比托管的记忆 SaaS 服务需要更多的初始设置。对于长时间中断,请在本地运行会话,并在连接恢复时使用 bridge sync 手动同步;回退队列中的内容不会丢失。要导出或归档记忆:bridge export --format ndjson 会生成一个可由 Elasticsearch 批量导入的文件。
BRIDGE_MEMORY_DECAY_WINDOW 设置是什么?它如何影响召回?
BRIDGE_MEMORY_DECAY_WINDOW 设置应用于记忆召回分数的时间衰减半衰期。默认值为 45d(45 天)。在其他条件相同的情况下,今天写入的记忆比 90 天前写入的相同记忆得分更高。这反映了智能体上下文的实际工作方式:最近的决策几乎总是比旧决策更相关,即使旧决策在语义上更接近查询。如果您希望旧记忆能够更平等地竞争,请增加此窗口;如果希望更积极地权衡近期性,请减小此窗口。
📡 更多 Elastic & AI 可观测性干货
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号