基于LangGraph搭建故障根因分析平台思考及总结

基于LangGraph搭建故障根因分析平台思考及总结

Wangzy
发布于 2026-06-22 18:52:58
发布于 2026-06-22 18:52:58
01
—
LangGraph、Dify、LlamaIndex介绍及优劣势分析
1、LangGraph:
LangGraph本质上一个Python库 (Framework),核心哲学是:Code-First (代码优先)。提供极高的灵活性,通过代码精确控制图的每一个状态跳转。
优势:
- 复杂的认知架构:如多 Agent 协作、原生支持带状态循环(Loops)、分支、自我修正、长短期记忆管理。
- 细粒度的状态控制: 你可以定义 AgentState 里的每一个变量如何更新(覆盖、追加、计算)。
劣势:
- 它只是代码。你需要自己写Flask/FastAPI 来包装它,自己写前端界面,自己对接向量数据库,自己写鉴权逻辑等。
2、Dify
Dify是全栈 LLM 应用开发平台 (BaaS) Workflow-First (工作流优先)。提供可视化编排、RAG 管道、API 管理、前端 UI。
基础设施与周边。如模型接入管理、RAG 知识库切片/索引、Prompt 调试、日志管理、对外发布 API。
优势:
- 开箱即用的RAG:Dify 内置了极强的 RAG 引擎(支持混合检索、重排序),你不需要自己去维护 Pinecone 或 Milvus 的连接代码,直接上传 PDF/Markdown 即可。
- 模型与工具管理: 企业通常会混用模型(用 GPT-4o 做分析,用 DeepSeek 写 SQL)。Dify 后台可以一键切换模型,还能方便地管理 API Key。
- 快速发布: 画好工作流,直接生成一个 Web App 或 API,立刻就能发布使用。
劣势 (Cons):
- 逻辑天花板: 虽然 Dify 的 DSL (领域特定语言) 越来越强,但如果你要写非常复杂的 if-else 嵌套,或者极其动态的 Agent 路由,在图形界面上连线会变成“蜘蛛网”,维护极其痛苦。
- 黑盒属性: 相比于自己的代码,Dify 封装得较厚,自定义某些底层逻辑(如修改 RAG 的召回算法细节)可能受限。
3、LlamaIndex
LlamaIndex常被视为RAG 框架,但它在 2024 年推出了 LlamaIndex Agents 和 Workflows,在处理“数据密集型”任务上比 LangChain 更强。核心理念:Data-Centric AI。如果任务的核心难点在于“从海量文档/日志中检索信息”,而不是复杂的逻辑跳转,LlamaIndex 是最优解。
优势:
- RAG 能力业界第一;擅长处理结构化数据(SQL)与非结构化数据(文本)的混合查询。
劣势:
- 在纯粹的逻辑编排(如复杂的循环、分支控制)上,不如 LangGraph 直观。
笔者学习调研agent相关内容,目的是为了搭建一个做根因分析(RCA)自主规划的Agent,通过如上分析对比,最适合的应该是LangGraph框架了,可以封装RCA Agent后,再通过api的形式发布,前端通过什么平台来调用都是可以的。
02
—
LangGraph简介
LangGraph 是 LangChain 专为构建复杂、有状态 Agent 打造的编排框架。
它核心解决了传统 Chain 无法处理循环逻辑的痛点,支持循环(Cycles),让 Agent 具备重试、自我反思和修正的能力。
核心亮点:
1、图结构:通过节点(Node)和边(Edge)灵活定义非线性工作流。
2、持久化:内置状态管理(Checkpointer),支持长短期记忆和断点续传。
3、人机协同:支持在执行中设置“断点”,允许人工介入审批或修改状态。
它是目前构建生产级自主 Agent 的首选工具。
03
—
LangGraph的核心能力
基于 LangGraph 官方文档(及架构设计),我们可以将其核心能力提炼为以下5大亮点。这些能力共同支撑起了从“简单脚本”到“生产级 Agent”的跨越:
1、循环与分支能力 (Cycles & Branching)
这是 LangGraph 与传统 LangChain(DAG)最大的区别。
循环 (Loops):原生支持图结构中的“回环”。这使得 Agent 能够执行循环推理(例如:计划 -> 执行 -> 检查 -> 修正 -> 执行),这是构建具备自我纠错能力的 Agent 的基础。
条件控制:通过条件边(Conditional Edges)实现复杂的逻辑分支,让 LLM 动态决定下一步的走向。
2、强大的持久化 (Persistence)
不仅仅是简单的“内存”,而是生产级的状态管理。
自动保存 (Checkpointing):系统会在每一步节点执行后自动保存图的状态(State)。
时间旅行 (Time Travel):你可以随时查看历史步骤的状态,甚至可以“回滚”到之前的某一步,修改状态后重新运行(Fork)。这对于调试和复杂任务重试至关重要。
3、人机协同 (Human-in-the-Loop)
将人类作为图中的一个“节点”或“审批者”。
中断与恢复 (Interrupt & Resume):可以在特定节点前暂停执行,等待人类输入或批准。
状态修改:在暂停期间,人类可以修改 Agent 的内部状态(例如:纠正 Agent 的错误计划),然后让 Agent 基于新状态继续运行。
4、细粒度的流式控制 (Streaming)
专为 LLM 应用优化的输出模式。
事件流:不仅仅流式输出最终文本,还能流式输出中间过程(例如:Agent 调用了什么工具、状态发生了什么变化)。
这对于构建用户体验良好的 Chat UI 至关重要,让用户能看到 Agent "正在思考" 的过程。
5、多 Agent 与子图 (Multi-Agent & Subgraphs)
支持大规模系统的构建。
子图 (Subgraphs):可以将一个复杂的图封装成一个节点,嵌入到另一个更大的图中。
分层架构:利用这一特性,可以轻松构建“多 Agent 系统”,例如让一个负责写作的 Agent 和一个负责搜索的 Agent 协作,通过顶层图进行编排。
如果说 LangChain 是由“线”组成的工具箱,LangGraph 就是用来织“网”的机器,它提供了构建长期运行、具备记忆、可控且可纠错的智能体系统所需的一切基础设施。
04
—
LangGraph基础能力代码实战
1、State(状态)、Nodes(节点逻辑) 和 Edges(流向)。
准备环境,安装langgraph pip install langgraph
如下代码示例模拟了一个数据在两个节点之间流转并被修改的过程。
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
# --- 第一步:定义状态 (State) ---
# 这是图的"记忆",所有节点都从这里读取数据,并将结果写回这里
class State(TypedDict):
content: str
# --- 第二步:定义节点 (Nodes) ---
# 节点就是普通的 Python 函数。它们接收当前 State,返回要更新的字段。
def node_hello(state: State):
print("🤖 节点 1 正在运行: 添加 Hello")
# 返回字典会更新 State 中的对应键
return {"content": state["content"] + " Hello"}
def node_world(state: State):
print("🌍 节点 2 正在运行: 添加 World")
return {"content": state["content"] + " World!"}
# --- 第三步:构建图 (Graph Construction) ---
# 1. 初始化图
builder = StateGraph(State)
# 2. 添加节点
builder.add_node("say_hello", node_hello)
builder.add_node("say_world", node_world)
# 3. 添加边 (Edges) - 定义流转逻辑
# START 是图的入口
builder.add_edge(START, "say_hello") # 开始 -> 节点1
builder.add_edge("say_hello", "say_world") # 节点1 -> 节点2
builder.add_edge("say_world", END) # 节点2 -> 结束
# 4. 编译图 (Compile)
# 编译将图结构转换为可运行的 Runnable
graph = builder.compile()
# --- 第四步:运行 (Execution) ---
# invoke 需要传入初始状态
initial_state = {"content": "Start:"}
print(f"🏁 初始状态: {initial_state}")
result = graph.invoke(initial_state)
print("-" * 30)
print(f"✅ 最终结果: {result['content']}")运行结果如下:

2、Conditional Edges (分支)
在 LangGraph 中,我们不在节点内部写 if/else 来决定下一步去哪里,而是使用 条件边 (Conditional Edges)。这实现了逻辑(路由)与执行(节点)的解耦。
这是 LangGraph 中最关键的一步。
在 LangGraph 中,我们不在节点内部写if/else来决定下一步去哪里,而是使用条件边 (Conditional Edges)。这实现了逻辑(路由)与执行(节点)的解耦。
场景设想:模拟掷硬币。
我们将构建这样一个流程:
a、开始 -> 掷硬币(随机生成 正面/反面)。
b、路由逻辑 -> 判断硬币是哪一面。
c、分支-> 如果是正面,走“赢家通道”;如果是反面,走“输家通道”。
d、结束。
代码如下:
import random
from typing import TypedDict, Literal
from langgraph.graph import StateGraph, START, END
# --- 1. 定义状态 ---
class State(TypedDict):
face: str # 记录硬币是 "heads" 还是 "tails"
message: str # 最终的消息
# --- 2. 定义节点 (Nodes) ---
def node_toss_coin(state: State):
# 模拟掷硬币逻辑
result = random.choice(["heads", "tails"])
print(f"🎲 掷出了: {result}")
# 更新状态中的 face
return {"face": result}
def node_winner(state: State):
print("🏆 走到了赢家节点")
return {"message": "恭喜!是正面,你赢了!"}
def node_loser(state: State):
print("😢 走到了输家节点")
return {"message": "遗憾,是反面,再接再厉。"}
# --- 3. 定义条件逻辑 (The Router) ---
# 这是一个特殊的函数,它不修改状态,只负责"读"状态并返回"路标"
def decide_next_step(state: State) -> Literal["goto_winner", "goto_loser"]:
if state["face"] == "heads":
return "goto_winner" # 返回一个自定义的字符串标识
else:
return "goto_loser"
# --- 4. 构建图 ---
builder = StateGraph(State)
# 添加节点
builder.add_node("toss", node_toss_coin)
builder.add_node("win_path", node_winner)
builder.add_node("lose_path", node_loser)
# 添加普通边 (START -> toss)
builder.add_edge(START, "toss")
# 添加条件边 (核心部分!)
# 语法: add_conditional_edges(来源节点, 路由函数, 路径映射字典)
builder.add_conditional_edges(
"toss", # 从哪个节点出来后开始判断?
decide_next_step, # 执行哪个判断函数?
{ # 路由函数的返回值 -> 实际节点名的映射
"goto_winner": "win_path",
"goto_loser": "lose_path"
}
)
# 两个分支最终都汇聚到 END
builder.add_edge("win_path", END)
builder.add_edge("lose_path", END)
# 编译与运行
graph = builder.compile()
print("--- 开始运行 ---")
result = graph.invoke({"face": "", "message": ""})
print("-" * 30)
print(f"🏁 最终结果: {result['message']}")运行结果如下:

3、Cycles (循环)
这是 LangGraph 相较于传统 LangChain 最核心的优势。循环(Cycle) 允许 Agent 不断重试、自我修正,直到满足条件为止。
实现循环非常简单:你只需要把一条边的“终点”指向它“之前的节点”。
场景设想:甚至更有耐心的作家
我们将构建一个简单的“作家 Agent”:
写作:写一段草稿。
审核 (路由逻辑):检查字数是否足够。
如果字数太少:退回“写作”节点(并在草稿上加点内容)。
如果字数达标:结束。
安全机制:为了防止死循环,我们限制最多重试 3 次。
代码如下:
from typing import TypedDict, Literal
from langgraph.graph import StateGraph, START, END
# --- 1. 定义状态 ---
class State(TypedDict):
draft: str # 当前的草稿内容
count: int # 计数器(防止死循环的关键!)
# --- 2. 定义节点 ---
def node_writer(state: State):
current_count = state["count"] + 1
print(f"✍️ [第 {current_count} 次迭代] 作家正在写作...")
# 模拟:每次迭代都在草稿后追加一点内容
new_content = state["draft"] + " 写了一点内容。"
return {
"draft": new_content,
"count": current_count
}
# --- 3. 定义循环逻辑 (Condition) ---
def check_quality(state: State) -> Literal["retry", "finish"]:
# 逻辑 A: 强制退出机制 (防止死循环)
if state["count"] >= 3:
print("🛑 达到最大重试次数,强制结束。")
return "finish"
# 逻辑 B: 质量检查 (比如模拟长度检查)
if len(state["draft"]) > 20:
print("✅ 字数达标,通过!")
return "finish"
# 逻辑 C: 否则重试
print("🔙 字数太少,退回重写...")
return "retry"
# --- 4. 构建图 ---
builder = StateGraph(State)
builder.add_node("writer", node_writer)
# 入口 -> 作家
builder.add_edge(START, "writer")
# 关键点:条件边的目标可以是它自己,或者之前的节点!
builder.add_conditional_edges(
"writer", # 从 writer 出来
check_quality, # 检查质量
{
"retry": "writer", # <--- 这里形成了循环!指向了自己
"finish": END
}
)
graph = builder.compile()
# --- 5. 运行 ---
print("--- 开始循环测试 ---")
# 初始给一个空草稿,计数器为0
initial_state = {"draft": "", "count": 0}
result = graph.invoke(initial_state)
print("-" * 30)
print(f"📝 最终草稿: {result['draft']}")
print(f"🔢 最终尝试次数: {result['count']}")运行结果如下:

4、Persistence (记忆)
“记忆”功能,在 LangGraph 中被称为 Persistence (持久化)。
你可以把它想象成电子游戏的存档机制:
a、Checkpointer (存档器):就像游戏里的“存储卡”或云存档数据库。
b、Thread ID (线程 ID):就像“存档栏位” (Save Slot 1, Save Slot 2)。只要 ID 相同,Agent 就会读取之前的进度继续玩,而不是重头开始。
如下代码演示记忆效果,我们模拟两轮对话。看第二轮,它是如何记得第一轮的内容的。
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver # <--- 1. 引入存档器
# 定义状态:使用 add_messages 类似的逻辑,这里简化为字符串拼接
class State(TypedDict):
# 关键修复:使用 Annotated 定义 reducer 函数,用于合并新旧状态
# 当 invoke 传入新输入时,reducer 会调用这个函数来合并,而不是直接替换
conversation: Annotated[str, lambda x, y: x + y]
def node_chatbot(state: State):
# 模拟处理:把新输入追加到历史记录中
# 注意:由于 conversation 已经有 reducer,新输入在 invoke 时已经自动追加到历史状态中
# 节点不需要返回 conversation,因为:
# 1. invoke 时传入的新输入已经通过 reducer 合并到恢复的状态中
# 2. 如果节点返回 conversation,会再次通过 reducer 合并,导致重复
# 如果节点需要添加新内容(如 AI 回复),应该只返回新内容,让 reducer 自动合并
# 这里节点不做任何更新,所以返回空字典
return {}
# --- 构建图 ---
builder = StateGraph(State)
builder.add_node("chatbot", node_chatbot)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
# --- 2. 初始化存档器并编译 ---
memory = MemorySaver() # 在内存中保存 (生产环境通常用 PostgresSaver)
graph = builder.compile(checkpointer=memory)
# --- 3. 运行测试 ---
# 设定一个 ID (这就好比你的用户 ID)
config = {"configurable": {"thread_id": "user_123"}}
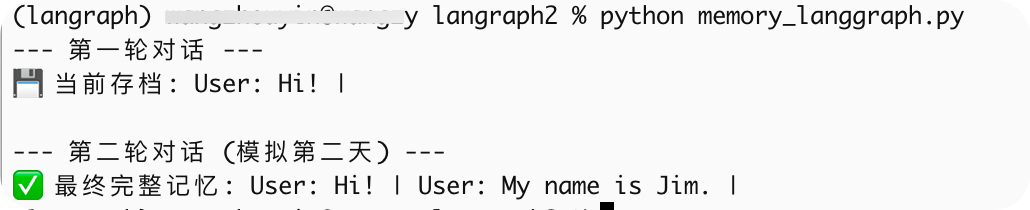
print("--- 第一轮对话 ---")
# 用户说 "Hi"
input_1 = {"conversation": "User: Hi! | "}
# 传入 config,让图知道要存到哪个 ID 下
graph.invoke(input_1, config=config)
# 查看一下当前记忆 (这步不是必须的,仅供调试)
snapshot = graph.get_state(config)
print(f"💾 当前存档: {snapshot.values['conversation']}")
print("\n--- 第二轮对话 (模拟第二天) ---")
# 注意:我们这里不需要把 "User: Hi" 再次传进去,图自己会去 thread_id 读取!
input_2 = {"conversation": "User: My name is Jim. | "} # 只传入新内容
result = graph.invoke(input_2, config=config)
print(f"✅ 最终完整记忆: {result['conversation']}")运行结果如下:
5、Human-in-the-loop(人机协同)
Breakpoints (断点)是LangGraph 最具生产力价值的功能之一。
在许多场景下(比如转账、发邮件、部署代码),你不能让 AI "一路狂奔"。你需要让它在关键步骤前停下来,等待人类确认或修改数据,然后再继续。
场景设想:大额转账审批
我们将构建这样一个流程:
申请:Agent 发起一个转账请求。
断点(关键):程序自动暂停。
人类介入:人类查看金额,把状态修改为 approved=True。
继续:程序恢复运行,执行转账。
程序如下:
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# --- 1. 定义状态 ---
class State(TypedDict):
amount: int
approved: bool
status: str
# --- 2. 定义节点 ---
def step_1_request(state: State):
print(f"🤖 (自动) 步骤 1: 申请转账 ${state['amount']}")
# 默认 approved 是 False
return {"status": "pending_approval"}
def step_2_execute(state: State):
# 这个节点会在"断点"之后运行
if state["approved"]:
print(f"💸 (自动) 步骤 2: 转账成功!金额: ${state['amount']}")
return {"status": "success"}
else:
print(f"🚫 (自动) 步骤 2: 转账被拒绝。")
return {"status": "rejected"}
# --- 3. 构建图 ---
builder = StateGraph(State)
builder.add_node("request", step_1_request)
builder.add_node("execute", step_2_execute)
builder.add_edge(START, "request")
builder.add_edge("request", "execute")
builder.add_edge("execute", END)
# --- 4. 关键设置:添加 Memory 和 断点 ---
memory = MemorySaver()
# interrupt_before=["execute"]:
# 意思是:在进入 "execute" 节点之前,暂停运行!
graph = builder.compile(
checkpointer=memory,
interrupt_before=["execute"]
)
# --- 5. 运行模拟 ---
config = {"configurable": {"thread_id": "tx_999"}}
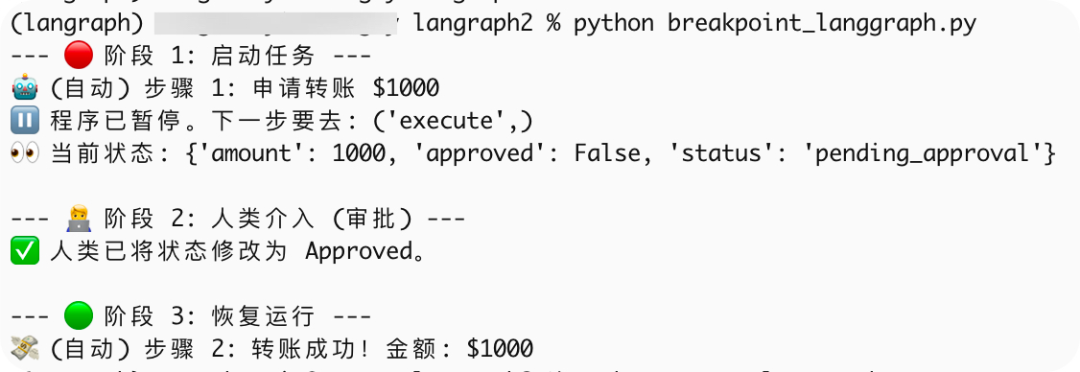
print("--- 🔴 阶段 1: 启动任务 ---")
# 初始请求转账 1000 元
graph.invoke({"amount": 1000, "approved": False}, config=config)
# 此时,程序已经暂停了。我们可以检查一下当前状态。
snapshot = graph.get_state(config)
print(f"⏸️ 程序已暂停。下一步要去: {snapshot.next}")
print(f"👀 当前状态: {snapshot.values}")
print("\n--- 🧑💻 阶段 2: 人类介入 (审批) ---")
# 假设人类看了眼,决定批准。我们使用 update_state 修改内存中的数据。
graph.update_state(config, {"approved": True})
print("✅ 人类已将状态修改为 Approved。")
print("\n--- 🟢 阶段 3: 恢复运行 ---")
# 传入 None 表示"继续执行下一步",它会读取刚才更新过的状态
graph.invoke(None, config=config)运行结果如下:
05
—
LangGraph的多Agent调度模式
1、Supervisor (主管模式)
核心概念:
Supervisor (主管节点): 一个专门的 LLM 节点,它不干活,只负责看当前状态,决定下一步派谁去干活(Router)。
Workers (工人节点): 专注干活的 Agent(如“查日志”、“查数据库”)。它们干完活后,把结果写回状态里,然后流程通常会回到 Supervisor。
Handoff (交接): 通过 Command 或 Conditional Edges 实现控制权的转移。
Supervisor: 收到报警,决定先让 MetricsAgent 查监控。
MetricsAgent: 查完,更新状态:“CPU 正常”。
Supervisor: 看到 CPU 正常,决定让 LogAgent 查日志。
LogAgent: 查完,更新状态:“发现 Error 500”。
Supervisor: 综合信息,输出结论。
2、Network / Collaboration (网状协作模式)
核心逻辑:去中心化 (Decentralized)
在 Supervisor 模式中,所有人都向主管汇报。而在 Network 模式中,Agent 之间是点对点 (Peer-to-Peer) 交互的。Agent A 干完活,可以直接决定把接力棒传给 Agent B,不需要经过“主管”。
图结构:这是一个有向图,每个节点(Agent)都可以有指向其他多个节点的边。
适用场景:需要多角色“头脑风暴”或“相互制衡”的场景。
AIOps 案例:“红蓝对抗”。
Agent A (攻击者):尝试对系统注入故障(Chaos Engineering)。
Agent B (防御者/SRE):尝试识别故障并修复。
两者互相传递 State,直到一方胜利。
3、Hierarchical Teams (层级/分层模式)
核心逻辑:分治 (Divide and Conquer)
这是 Supervisor 模式的进阶版。当系统太复杂,一个主管管不过来时,就需要“主管管主管”。
在 LangGraph 中,这通过 Subgraphs (子图) 来实现:一个图中的“节点”,本身就是另一个完整的编译好的图。
图结构:树状结构。
适用场景:大型企业级排查,涉及多个技术栈。
AIOps 案例:总指挥官 (Incident Commander)。
Top Level: 总指挥官接收报警。它有两个下属:Network_Team 和 Database_Team。
Sub Level 1 (Network_Team): 这是一个子图,里面有自己的 Supervisor 和 Worker (防火墙专家、交换机专家)。
Sub Level 2 (Database_Team): 另一个子图,里面有 DBA 和 SQL 审计员。
优势:封装性。总指挥官不需要知道“SQL 审计员”是如何工作的,它只关心“数据库组”给出的最终结论。
4、Plan-and-Execute (规划-执行模式)
核心逻辑:先想后做 (Planning First)
ReAct 模式是“走一步看一步”,而 Plan-and-Execute 是先生成完整的 To-Do List,然后逐个执行。
图结构: Planner -> Executor -> Re-Planner (循环)。
适用场景: 步骤明确的长链路任务,或者为了减少 Token 消耗(Executor 可以用小模型,Planner 用大模型)。
AIOps 案例:系统升级或数据迁移。
Planner: “为了迁移数据,我需要:1. 备份原库 2. 停止写入 3. 导出数据 4. 导入新库”。
Executor: 默默执行步骤 1, 2, 3...
Re-Planner: 如果步骤 3 失败,修改计划。
5、Map-Reduce (并行/归约模式)
核心逻辑:并行处理 (Parallelization)
这是 LangGraph 区别于普通 Agent 框架的一大杀器。它允许你动态生成多个分支并行运行,最后汇总结果。
图结构:发散 (Fan-out) -> 并行执行 -> 汇总 (Fan-in)。
适用场景:处理大量同质化数据。
AIOps 案例:大规模日志分析。
场景:集群有 50 台服务器同时报警。
Map 阶段:主节点生成 50 个任务,通过 LangGraph 的 Send() API 并行分发给 50 个 Worker 节点。
Execution 阶段:50 个 Worker 同时去查各自机器的日志(速度极快)。
Reduce 阶段: 汇总节点收集 50 份结果,分析共同特征(比如“所有机器都在连同一个挂掉的 Redis”)。
6、Reflection / Self-Correction (反思/修正模式)
核心逻辑:质量控制 (Quality Control)
Agent 做完任务后,不直接输出,而是传给另一个角色(或自己)进行“审查”。
图结构:Generator -> Critiquer -> (if bad) -> Generator。
适用场景:对输出严谨性要求极高的场景。
AIOps 案例:编写故障复盘报告 (Post-Mortem)。
Critiquer: 检查报告中引用的时间戳是否与日志一致?是否有幻觉?
如果 Critiquer 发现错误,打回给 Generator 重写。
06
—
LangGraph记忆管理
在 LangGraph 中,Memory 分为两类:短期上下文 (Context) 和 长期持久化 (Persistence)。
1、管理短期上下文 (Context) —— State
State 就是上下文窗口。所有节点函数代码中定义的state参数,就是当前的全部上下文。
如何管理过长的上下文?
a、Reducer 机制: LangGraph 允许你定义如何更新状态。例如 metricsdata 字段,你可以定义为“直接覆盖”(只保留最新),而 messages 字段通常定义为“追加”(保留历史)。
b、Trim/Filter: 在把 State 传给 LLM 之前,你可以写代码截断它(例如只保留最近 10 条消息),防止 Token 溢出。
2、管理长期记忆 (Persistence) —— Checkpointer
这是 LangGraph 最强的地方。它能把 Agent 的每一步操作都存盘。
假如 AIOps Agent 查了一半,发现需要人工授权重启服务器。此时程序暂停(Human-in-the-loop)。管理员一小时后才批准。Agent 需要恢复之前的“记忆”继续运行。
框架中通常使用 MemorySaver 或连接 Postgres/Redis,来存储长期记忆。
07
—
企业级根因分析(RCA)方案思考
笔者在公司设计aiops落地RCA时,想着最终的形态应该是个自主规划Agent。
完全自主规划(Autonomous Planning)最大的风险是不可控和无限循环。
在分秒必争的故障处理中,Agent自己“思考”了5分钟还没有结果是灾难性的。
所以“半自主”方案可能比“全自主”方案更适合企业级RCA。
1、SOP导向的“工作流Agent” (SOP-Driven Workflow Agent)
适合场景:已知故障类型的标准化排查(如:磁盘满、OOM、特定错误码)。
2、知识图谱增强的RAG (GraphRAG for RCA)
适合场景:复杂拓扑结构下的级联故障分析。
痛点:很多时候根因不在报错的服务,而在它依赖的底层组件(例如:A服务报错是因为B数据库慢,B慢是因为C存储满)。
单纯的Agent很难“猜”到这个链路。
所以可以结合如上两个方案,采用 “SOP自动化为主 + 自主规划为辅”的混合模式来实践RCA。
08
—
结语
笔者了解到目前许多大厂内部的落地方式:把 LangGraph 做成一个微服务,
先用 LangGraph 把最核心的“根因分析算法”跑通,把它封装成一个 API。
然后部署一个 Dify,创建一个 Chatflow,把你的 LangGraph API 挂载上去,同时利用 Dify 的知识库功能挂载的【内部运维知识库】。
本周笔者其实有用cursor写了个基于LangGraph的自主规划Agent demo,cursor 5分钟就完成了所有代码编写,然后自动调试解决代码运行报错,输出一个立马可以运行的demo,其中代码笔者还没有细研究,先截个图展示下运行效果吧,后续有机会再分享基于LangGraph搭建自主规划Agent的实战案例。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号