vLLM 新特性:批量大小不再影响模型输出

vLLM 新特性:批量大小不再影响模型输出

用户11563501
发布于 2026-06-23 10:21:13
发布于 2026-06-23 10:21:13
vLLM 刚刚推出了批量不变推理功能,解决了大模型推理中的一个关键问题:相同输入在不同批量大小下产生不同结果。
这个问题在实际应用中很常见。同一个模型,单独处理一个请求和批量处理多个请求时,输出概率可能存在细微差异。对于需要严格一致性的生产环境来说,这种不确定性会带来严重问题,会影响模型的可重现性和调试难度。
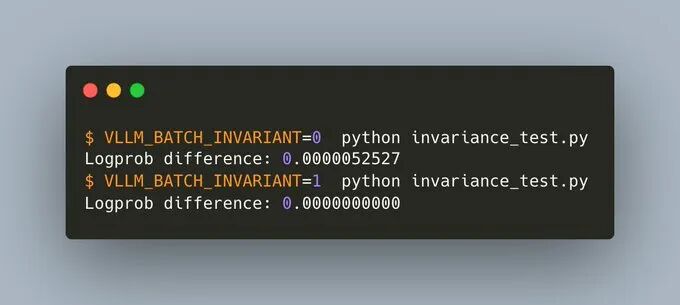
现在只需要设置 VLLM_BATCH_INVARIANT=1,就能保证无论批量大小如何,输出完全一致。
技术实现主要包括三部分:
自定义算子:基于 Triton 构建,添加 RMS norm 实现来修复兼容性问题。
执行重写:通过 torch.library.Library 重写 PyTorch 执行流程,但遇到一个坑点——批量矩阵乘法会被静默丢弃,需要额外 patch。
后端调整:固定 Triton tile 大小,Top-K 设为排序模式,升级 FlashInfer 到 4.0 RC 版本。
测试标准很严格,他们要求不同批量大小下的 logprobs 完全相同,没有容错。
这个功能解决了生产环境中的实际痛点。虽然可能有性能开销,但换来了结果的确定性,让调试和测试变得更可靠。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号