进阶RAG | 知识库挂载,让大模型不再"一本正经胡说八道"

进阶RAG | 知识库挂载,让大模型不再"一本正经胡说八道"

dolphin57
发布于 2026-06-23 20:41:12
发布于 2026-06-23 20:41:12
进阶RAG | 知识库挂载,让大模型不再"一本正经胡说八道"
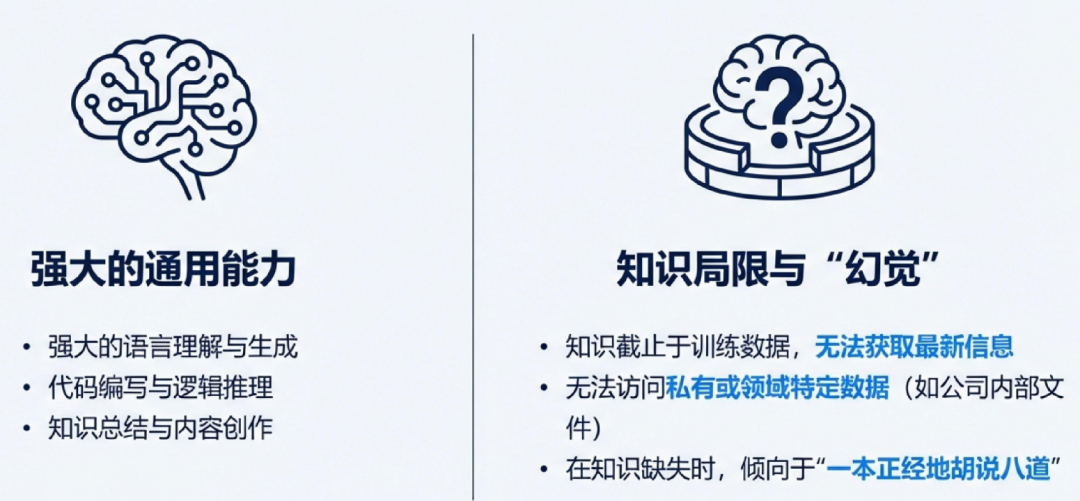
大语言模型的双重困境
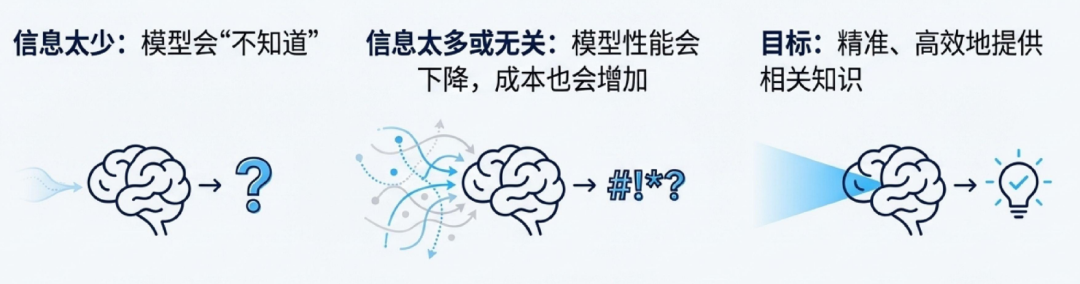
解决方案的核心理念:上下文工程
1
上下文工程是一门专注于为大模型的“上下文窗口”填充恰到好处的信息,以引导其完成特定任务的艺术与科学。
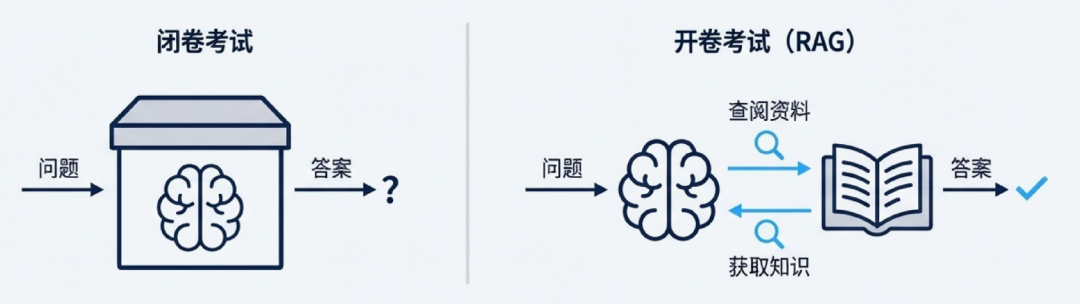
RAG:上下文工程的最佳实践
RAG就像给大模型一场“开卷考试”
普通提问如同“闭卷考试”,模型只能依赖记忆。而RAG允许模型在回答前“查阅”我们提供的相关资料(知识 库),从而给出更准确、更有依据的答案。
RAG系统的两大核心阶段
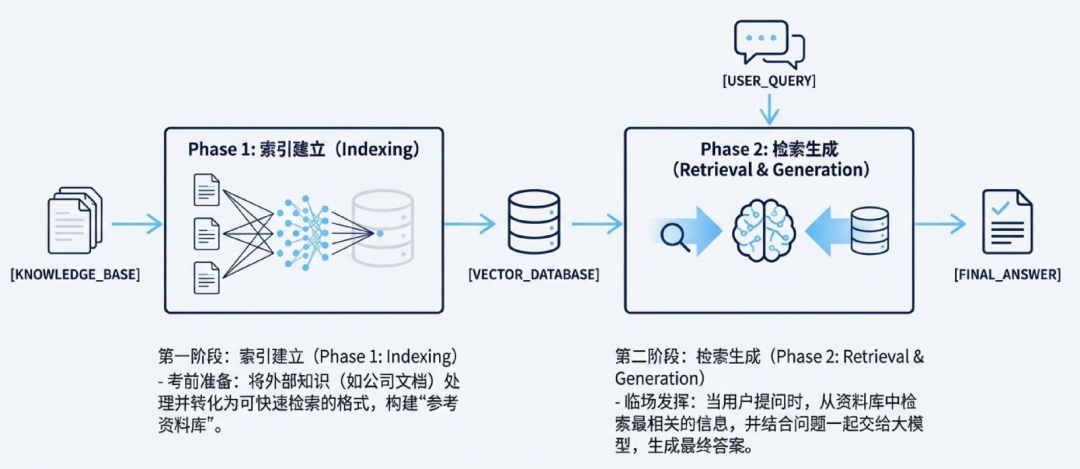
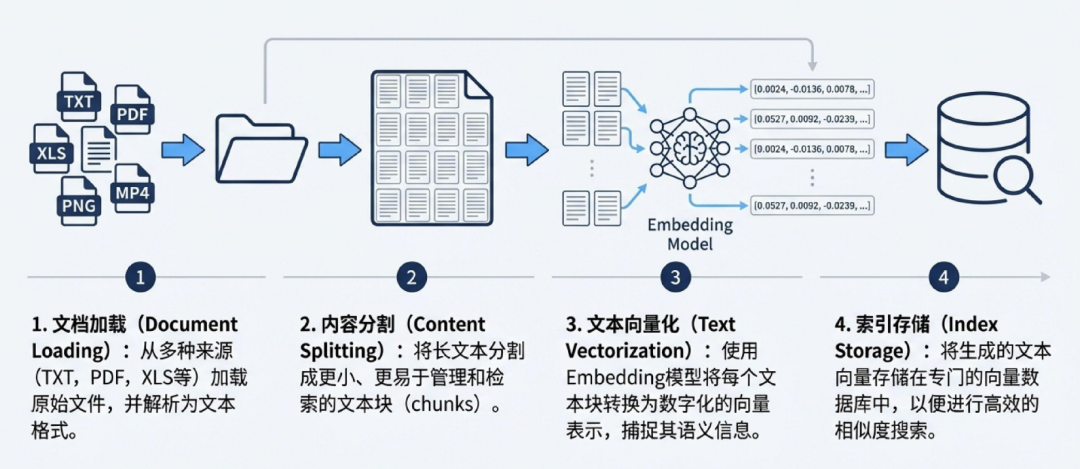
阶段一:建立索引 - 构建“参考资料库”
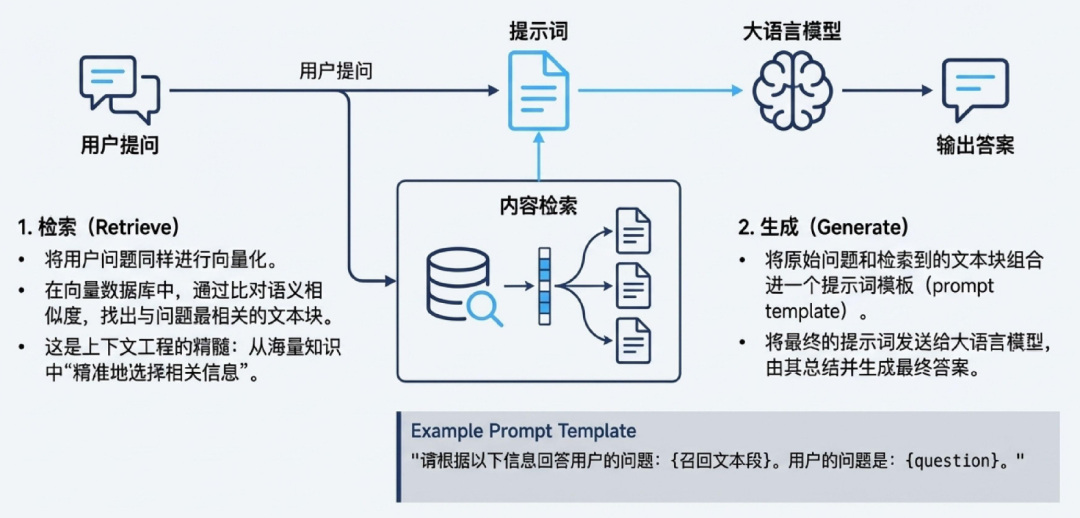
阶段二:检索生成- “开卷考试”进行时
从理论到实践:使用Llamalndex快速构建
Llamalndex是一个强大的框架,它将RAG的完整流程(从数据加载到查询)封装为简洁、易用的组件。

核心逻辑代码概览
只需几行代码即可实现完整的RAG流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 1. 加载文档 (Load Documents)
documents = SimpleDirectoryReader('./docs').load_data()
#2. 创建索引 (Create Index)
# 这一步包含了分割、向量化和初步存储
index = VectorStoreIndex.from_documents(
documents,
embed_model=DashScopeEmbedding(...)
)
# 3. 创建查询引擎(Create Query Engine)
query_engine = index.as_query_engine(
llm=OpenAILike(...)
)
#4. 执行查询(Execute Query)
streaming_response = query_engine.query(
'我们公司项目管理应该用什么工具'
)
streaming_response.print_response_stream()
专家技巧:索引持久化,提升响应效率
问题(Problem) VectorStorelndex.from_documents 过程可能非常耗时,尤其是在知识库很大的情况下。每次启动都重新建立索引是不切实际的。
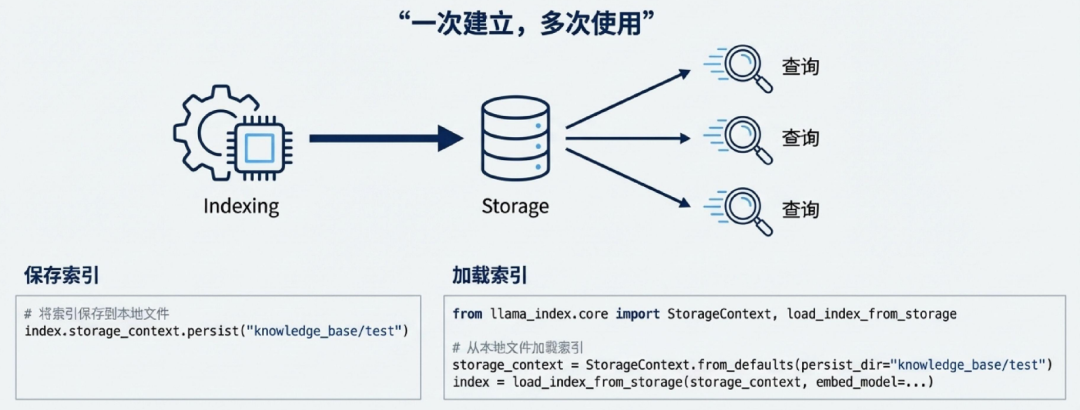
代码封装:从脚本到可复用模块
将RAG的核心功能封装成独立的函数或类,可以极大地提高代码的可维护性和复用性。

通过简单的封装,调用逻辑变得清晰、简洁。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号