字节跳动 Seedance 2.0:当 AI 视频生成学会了"听声辨位"

字节跳动 Seedance 2.0:当 AI 视频生成学会了"听声辨位"

唐国梁Tommy
发布于 2026-06-25 21:40:04
发布于 2026-06-25 21:40:04
2026 年 2 月,字节跳动 Seed 团队悄然发布了 Seedance 2.0。这不是又一次例行的版本迭代——它是目前业界第一个在文生视频和图生视频两大任务上同时登顶 Arena.AI 排行榜的模型,Elo 分数分别达到 1450 和 1449,720p 画质击败了一众 1080p 竞品。
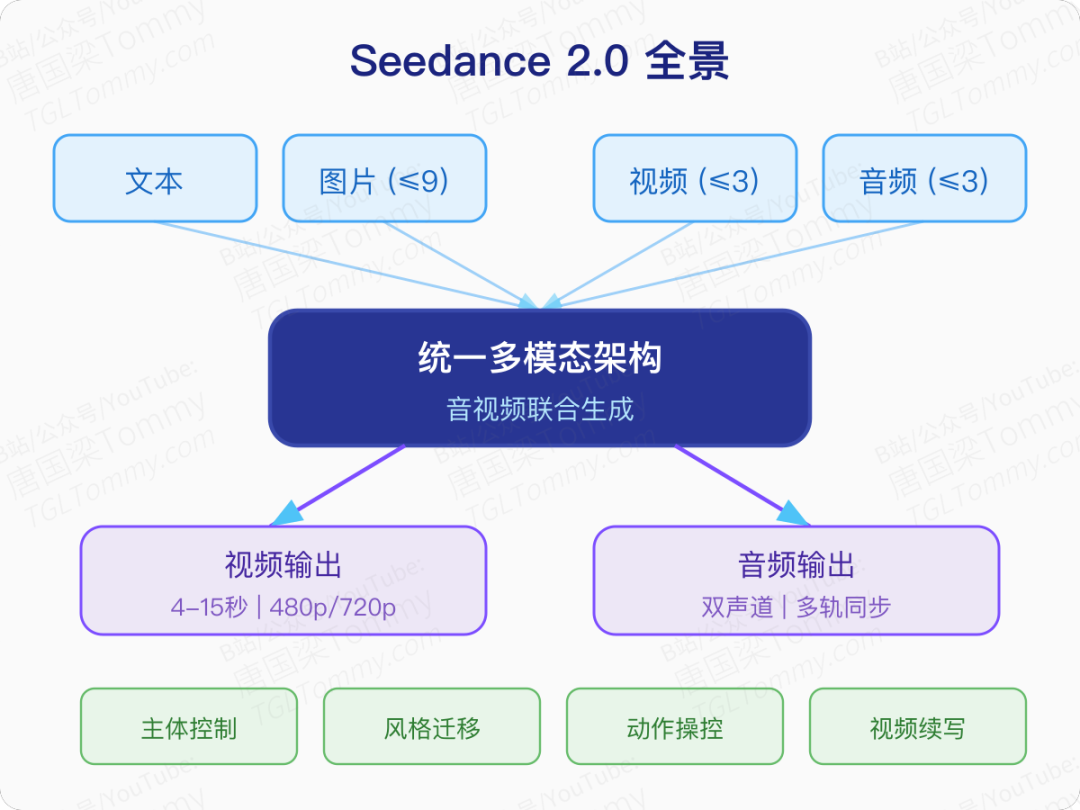
更关键的是,它不只是画面好看。Seedance 2.0 真正的突破在于:它是一个原生的多模态音视频联合生成模型,能同时理解文字、图片、音频和视频四种输入,并输出画面与声音深度同步的内容。
视频生成的"最后一公里"在哪?
过去几年,从 Sora 到可灵,文生视频领域经历了爆发式发展。但当你真正尝试用这些工具做内容创作时,几个痛点非常明显:
动作崩坏——人物做复杂运动时手指变形、身体穿模,花样滑冰变成恐怖片;音画割裂——视频和音频各走各的,角色嘴型对不上台词,脚步声和落地画面差了半拍;控制力不足——你很难精确告诉模型"我想要一个从低角度跟拍到慢动作特写的转场",更别说指定风格、参考动作和背景音乐了。
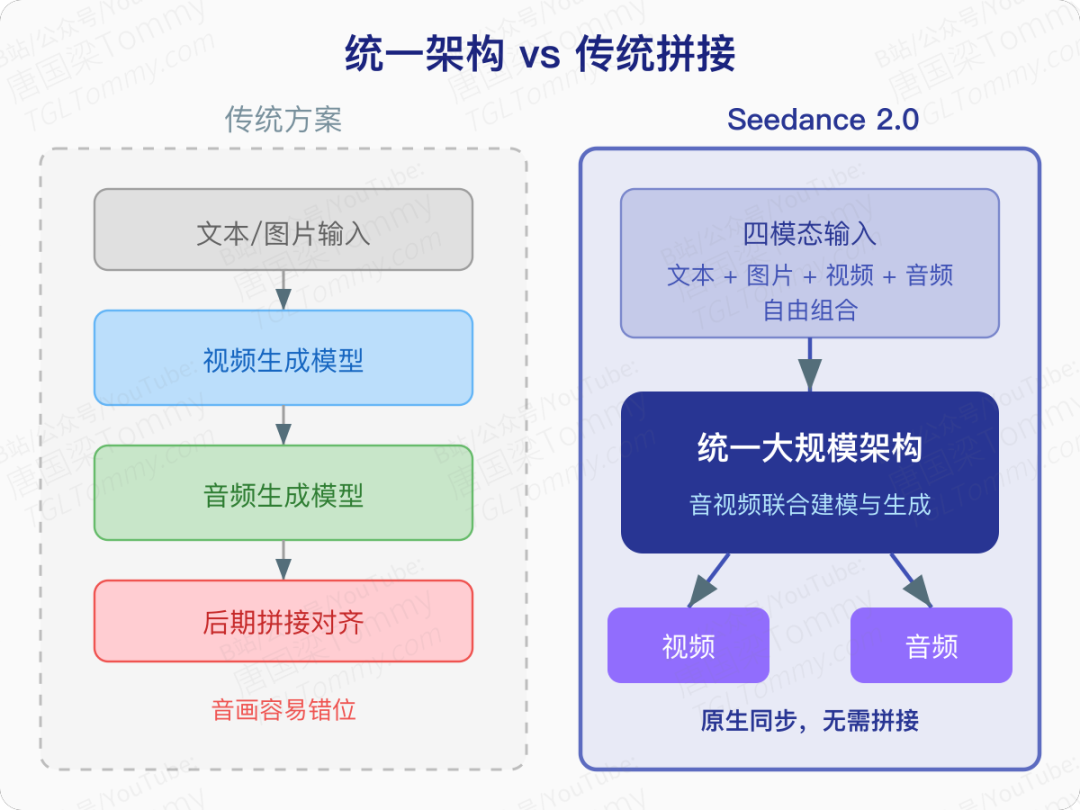
这些问题的根源在于:大多数模型把视频生成和音频生成当作两个独立的管线来处理。先生成画面,再拼接声音,两边各管各的。当视频内容变得复杂——比如一段武打戏需要刀剑碰撞声、脚步声、环境风声同时与画面对齐——这种拼接式架构就力不从心了。

统一架构下的音视频联合生成
Seedance 2.0 的解法是用一个统一的大规模架构同时完成音频和视频的生成。这不是简单地在视频模型后面接一个音频模型,而是在架构层面将两者融为一体。
具体而言,模型支持四种输入模态组合使用:文本描述、参考图片(最多 9 张)、参考视频(最多 3 段)、参考音频(最多 3 段)。输出则是 4 到 15 秒的音视频内容,原生支持 480p 和 720p 分辨率。
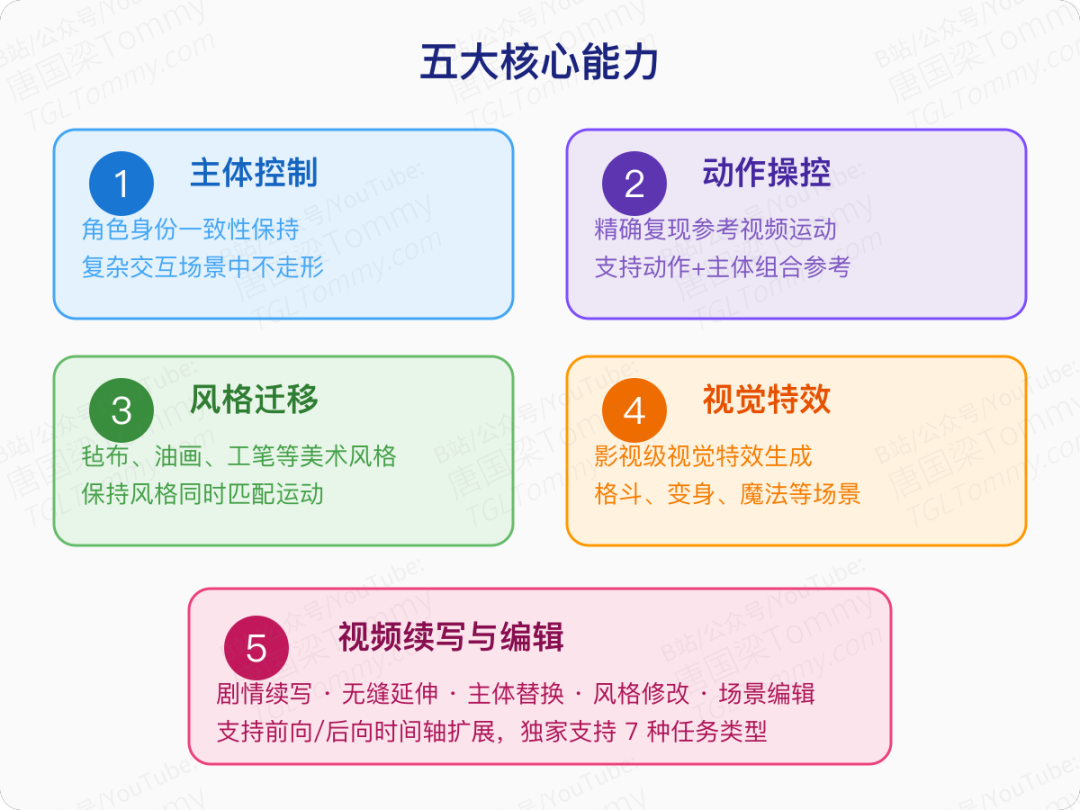
在这个框架下,Seedance 2.0 整合了业界最全面的多模态编辑能力套件:
- 主体控制:保持角色身份一致性,即使在复杂交互场景中
- 动作操控:精确复现参考视频中的身体运动
- 风格迁移:将特定美术风格(毡布、油画、工笔画等)应用到生成视频中
- 视觉特效:生成专业级别的影视特效
- 视频续写与延伸:基于已有片段生成连贯后续镜头
个维度全面领先
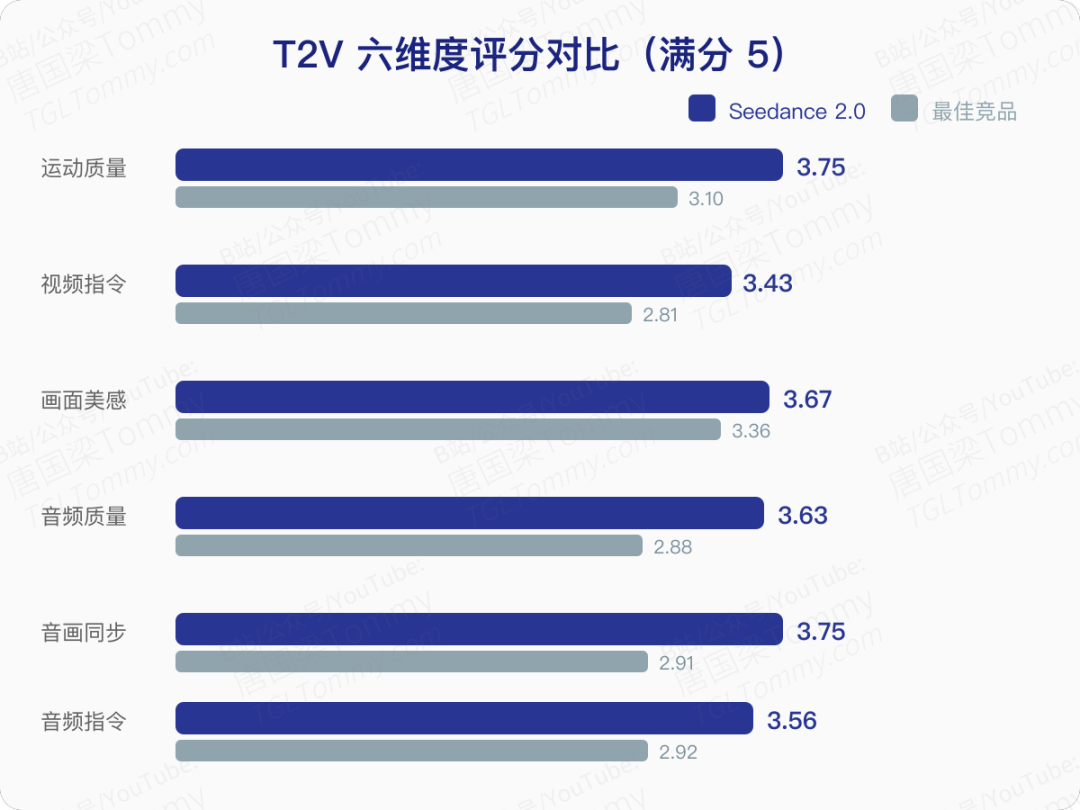
论文中最有说服力的部分是其系统性的评测体系——SeedVideoBench 2.0。研究团队与媒体行业专家合作,从运动质量、视频指令跟随、画面美感、音频质量、音画同步、音频指令跟随六个维度进行了详尽对比。
文生视频(T2V)
在与 Kling 3.0、Sora 2 Pro、Veo 3.1 等主流模型的对比中,Seedance 2.0 在全部六个维度排名第一,是唯一一个每个维度都超过 3.4 分(满分 5 分)的模型。
几个关键数字:
- 运动质量得分 3.75,领先第二名 0.65 分以上
- 可用率(≥3 分)在运动维度达到 97.55%
- 音频质量满意度(≥4 分)为 62.05%,而所有竞品均低于 10%
- 在 30 个细分运动类别中,Seedance 2.0 在 29 个类别排名第一
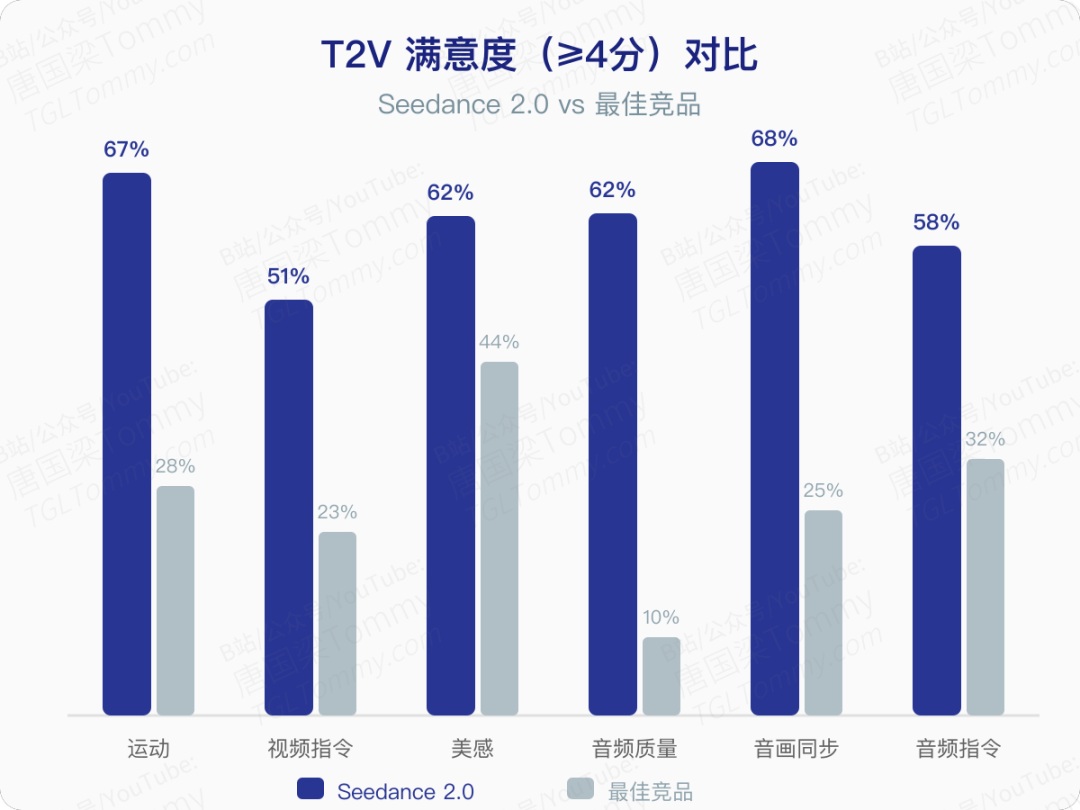
音频维度是竞品差距最大的地方。Seedance 2.0 的双声道音频技术支持多轨输出——背景音乐、环境音效、角色配音同时生成,并与画面节奏精确对齐。在英语语音生成上得分高达 4.17,中国戏曲从上一代的 2.50 飙升到 3.75。
图生视频(I2V)
同样全面领先,六个维度得分在 3.31 到 3.70 之间,而没有任何竞品超过 3.18。音频提示跟随维度上,Seedance 2.0 得到 3.70 分,最接近的竞品 Seedance 1.5 Pro 仅有 3.10 分。格斗视觉特效是差距最惊人的场景——运动质量得分 3.63,而可灵 3.0 和上一代 Seedance 1.5 Pro 都只有 2.25,差了整整 1.38 分。
在多语种音频方面表现同样突出:西班牙语音频质量达到 4.14,英语音频提示跟随达到 4.20,印尼语也有 4.14。方言处理能力也是亮点——四川话、东北话、粤语生成都表现精准,中国戏曲音频从上代的 2.38 提升到 3.75。
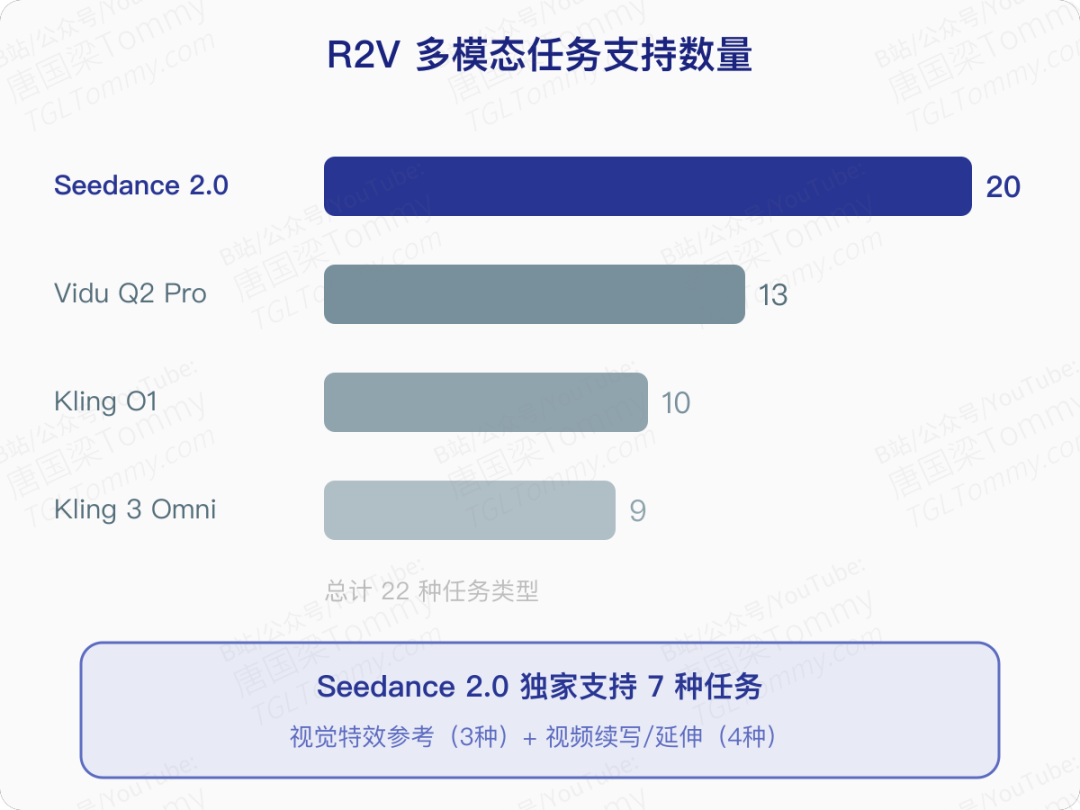
多模态参考生成(R2V)
这是 Seedance 2.0 独特的竞争力所在。在 22 种多模态任务类型中,它支持 20 种——是所有模型中最广的。其中有 7 种任务类型是 Seedance 2.0 独家支持的,包括所有视觉特效/创意参考变体和所有视频续写/延伸变体。
Arena.AI 公开排行榜的验证
除了自家评测,Arena.AI(原 LMArena,由 UC Berkeley 研究者创建)的公开排行榜提供了独立验证。该平台让真实用户对匿名模型的输出进行盲选投票,生成 Elo 排名。
Seedance 2.0(Dreamina 版本,720p)在文生视频和图生视频排行榜上均排名第一。T2V 上领先第二名 Veo 3.1(1080p)79 个 Elo 分。值得注意的是,它以 720p 分辨率击败了 1080p 的竞品——这说明运动动态和视觉连贯性在用户感知中比分辨率本身更重要。

还有哪些不足?
论文没有回避模型的局限性,这值得肯定:
- 细微变形伪影仍然存在,极端动作场景下偶尔出现
- 多说话人场景的唇音同步还不够精确
- 高频视觉噪声和音频失真在部分输出中可见
- 视频延伸质量落后于 Veo 3.1(任务跟随率仅 31.82% vs Veo 3.1 的 88.89%)
- 高级摄像机运动仍是所有模型的共同难题,分数普遍低于 3.2
- 多主体一致性在复杂编辑任务中还有优化空间

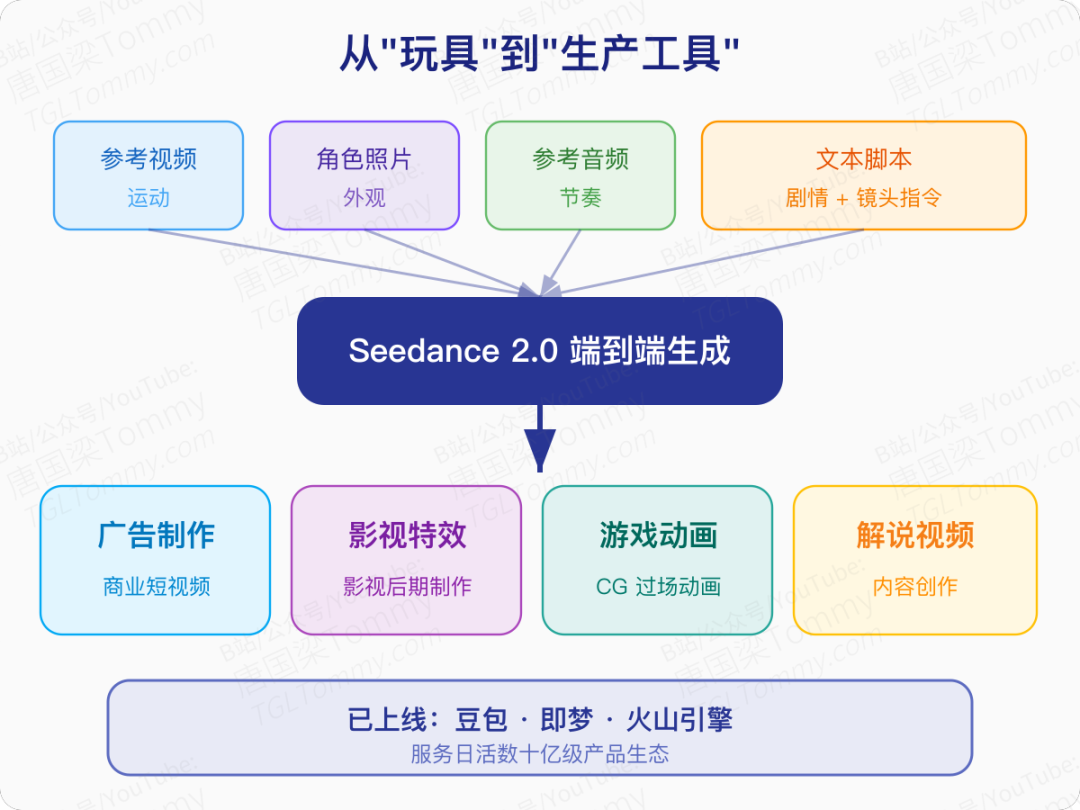
从"玩具"到"生产工具"
Seedance 2.0 的真正价值不仅在于跑分第一。
以一个具体场景为例:假设你要制作一条商业广告。传统流程需要拍摄团队、后期剪辑、音效师、调色师协同工作。而在 Seedance 2.0 的框架下,你可以同时输入一段参考视频的运动节奏、一张角色照片的外观、一段背景音乐的旋律,再加上一段文本脚本描述镜头语言——模型会输出一段音画同步、风格统一的成品视频。论文中展示的花样滑冰场景就是一个典型:模型能渲染出起跳、空中旋转、落冰的完整动作序列,同时冰刀划过冰面的声音与画面精准对齐。
这让 AI 视频生成从"看着好玩"向"真正能用"迈进了一大步。
论文特别提到,模型已经在豆包、即梦和火山引擎上线,服务于日活数十亿级别的产品生态。对于广告制作、影视特效、游戏动画、解说视频等场景,它可以显著降低制作成本、缩短生产周期。
写在最后
Seedance 2.0 代表的是视频生成领域的一个关键转折:从"能生成画面"到"能生成完整的视听体验"。当模型不仅能画出逼真的人物动作,还能同步生成与之匹配的脚步声、对话声和背景音乐时,AI 视频生成才真正具备了替代传统制作流程的潜力。
但也要注意几个值得思考的点。首先,论文本质上是一份技术报告(Model Card),170 多位作者的署名和未公开的架构细节意味着这是一项典型的重工程驱动成果,外部团队很难复现。其次,评测体系虽然全面,但 SeedVideoBench 2.0 毕竟是团队自建的——虽然有 Arena.AI 的独立验证作为补充,但更多第三方评测会让结论更加可信。最后,模型目前最长只能生成 15 秒内容,距离真正替代传统影视制作流程还有相当距离。
但无论如何,Seedance 2.0 在音视频联合生成这条路上,确实走出了令人信服的一步。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号