大模型 API 到底在卖什么?把 Token 成本一次讲透

大模型 API 到底在卖什么?把 Token 成本一次讲透

唐国梁Tommy
发布于 2026-06-25 21:46:00
发布于 2026-06-25 21:46:00
同样是 100 万 token,有的模型只卖几美元,有的能卖到几十美元,价差能拉到三十多倍。
更奇怪的是,买单的人都存在。
这说明一件事:价格表里虽然都写着 token,但它们背后代表的东西,并不完全一样。
先把结论放在这里:贵的模型和便宜的模型,卖的其实是两种不同的东西。贵的卖复杂任务里的确定性,便宜的卖规模化的性价比。
这篇文章会一层一层拆开 token 的成本结构,看清这个答案到底是怎么来的。

01|Token:从技术单位到商业单位
先澄清:这里的 token 跟区块链代币没有任何关系。它是大模型处理信息的基本单位——你输入一句话,模型先把文本切成一个个 token,再进行计算、理解和生成。
如果 token 只是个工程概念,它本该停留在技术文档里。但过去几年,它从技术单位变成了商业单位。
打开主流大模型 API 的价格页,你会看到很多层价格:输入 token、输出 token、缓存命中的输入 token、批处理 token、优先级请求、多模态输入,甚至还有 reasoning token——模型推理时消耗的内部"思考" token。

其实每个成熟行业,都会长出自己的计量单位。电力按"度"卖,云计算按算力时长卖,广告按 CPM 卖。AI 行业正在做同一件事:用 token,把模型能力、GPU 推理、显存占用、缓存、延迟、调度和服务等级,压缩成一个可以报价、预算、优化和采购的单位。

但同样叫 token,并不一定是同一种商品。这就像同样一公里路程,公交、出租、高铁和私人飞机都能送你到,但它们卖的不是同一种东西:有人卖最低成本,有人卖时间,有人卖确定性。
02|输出为什么比输入贵:读题与答题
大模型推理大致分两个阶段:prefill 和 decode。
Prefill 是"读题"。模型把你的输入完整读进去,理解上下文,算出生成答案所需的中间状态。输入是完整给定的,可以大规模并行处理——这正是 GPU 最擅长的,所以输入 token 的成本更容易摊薄。
Decode 是"答题"。模型一个 token 一个 token 地生成:第二个 token 依赖第一个,第三个依赖前两个,每一步都依赖前一步,没法整段并行。这就是自回归生成。
就像考试:读材料可以一目十行,写答案必须一句一句往下写,还不能前后矛盾。
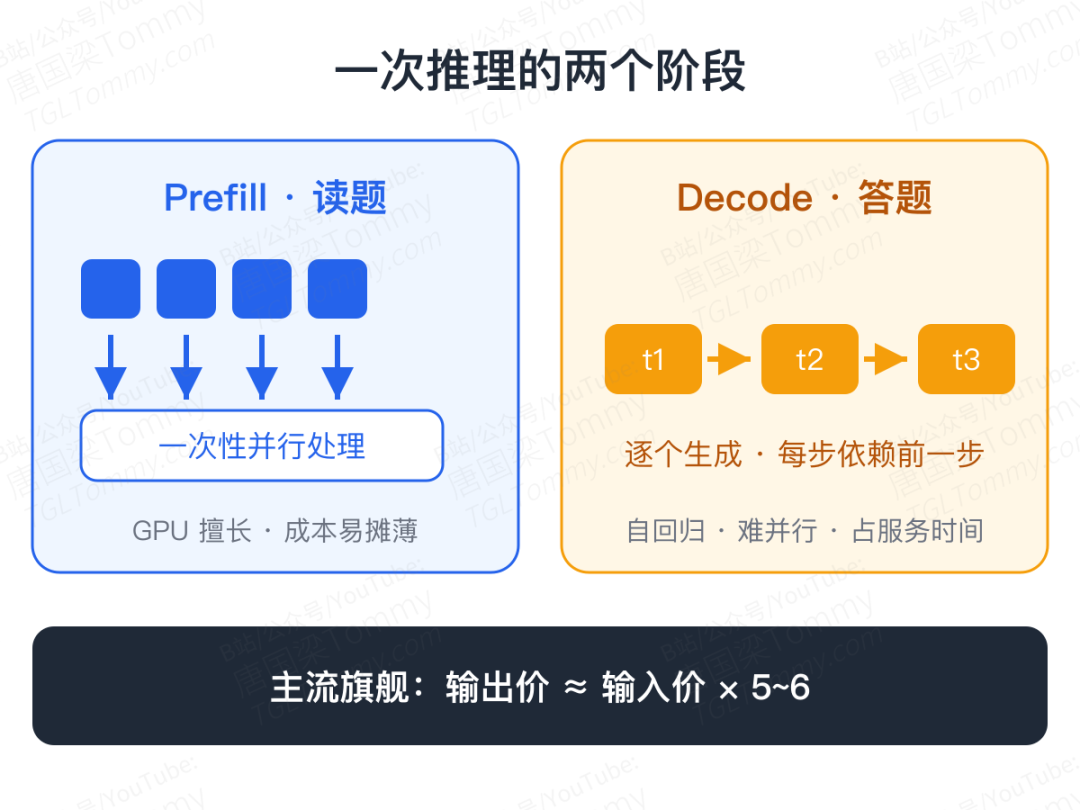
所以输出 token 通常比输入贵,不是厂商拍脑袋定价,而是输出的生产过程更难并行、更占服务时间、更受显存带宽和调度效率限制。这个差距在价格表上很直观:主流旗舰模型的输出价普遍是输入价的五到六倍——比如有的模型输入约每百万 token 5 美元,输出要二十几美元。
还有一个越来越重要的隐藏项:reasoning token。很多模型在给出最终答案前,会先在内部"想"很长一段。这些思考 token 你根本看不到,但照样计费,而且按输出价收钱。你可能只问了一句话,它最后也只回了几百字,中间却悄悄生成了几千甚至上万个思考 token。同一个任务,开不开思考模式,账单可能差好几倍。
多模态也是同样的逻辑:图片、音频送进模型,都会折算成 token 计费。背后是同一套思路——把不同形态、不同环节的智能消耗,全部折算成可计量、可报价的单位。
03|长上下文为什么贵:显存里的草稿纸
大模型处理上下文时,不会每生成一个新 token 就把所有历史从头重算一遍。它会把注意力机制里已经算过的中间状态(attention 的 key 和 value)保存下来,这就是 KV cache。
一句话概括:KV cache 是推理时保存上下文中间状态的高速工作区。它不是人类意义上的记忆,也不是数据库,更像模型工作时铺开的草稿纸。
草稿纸提高了效率,但它本身要占地方——对服务商来说,这个"地方"主要是显存。
很多人看到一个模型支持 128K、200K 甚至 100 万上下文,会觉得这不就是"能塞更多文字"吗?但对服务商来说,长上下文意味着要在显存里维护一个大得多的工作区:上下文越长,KV cache 越大;并发请求越多,总占用越大。
最后的结果是:同一张 GPU 能同时服务的请求变少,吞吐下降,延迟上升,单位 token 成本上涨。
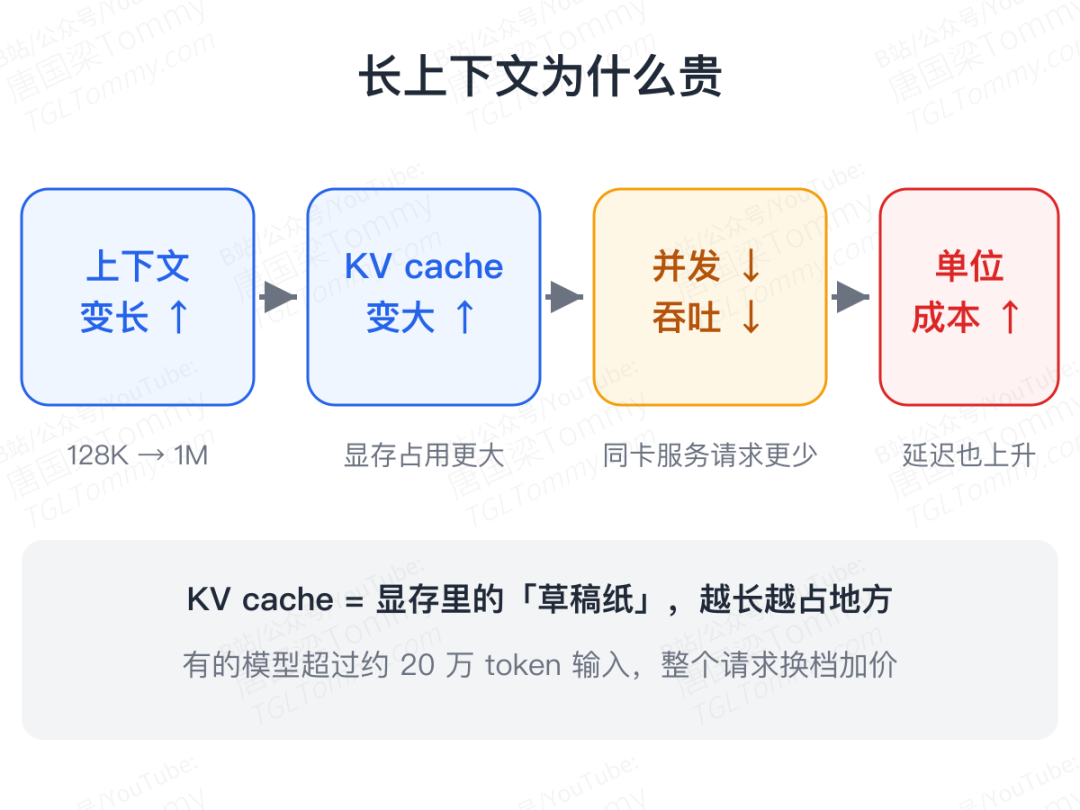
所以你会看到,有的模型干脆把长上下文单独标价:输入一旦超过某个长度(比如二十多万 token),整个请求就换一档更贵的价格,输入翻倍、输出也跟着上浮。
长上下文不是免费的超能力。
04|同样的 token,不同的生产方式
先说 prompt caching(提示词缓存)。 做过 AI 应用就知道,很多请求里有大量重复内容:系统提示词、角色设定、工具定义、JSON schema、知识库说明。这些每次请求都一样,变化的只有用户的问题。每次都重算一遍,很浪费。
所以很多平台支持 prompt caching:如果某段输入与之前的请求形成可复用的稳定前缀,平台就能复用已经算过的状态,不必从头计算。缓存命中的输入价格往往只有原价的十分之一左右;按一些平台官方的说法,最多能省 90% 的输入成本,并把延迟降低最多 80%。

不过各平台缓存规则不同:有的要求前缀够长,有的有缓存有效期,有的要显式设置缓存断点。不能简单理解成"文字一样就一定命中"。
这对开发者意味着:成本优化的关键,是设计 prompt 的结构。 固定的 system prompt、稳定的工具定义和规则放前面,每次变化的用户问题、临时参数放后面,让稳定部分变成可复用的"热 token"。
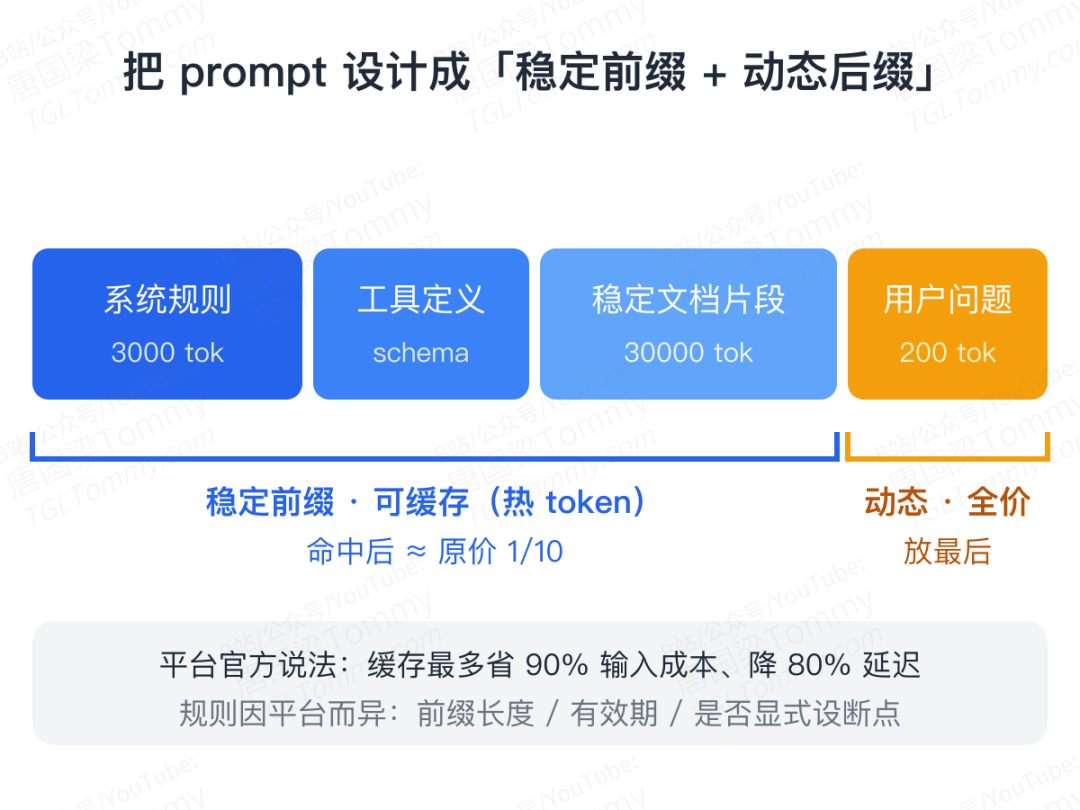
举个具体例子:一个企业知识库问答应用,每次请求前面有 3000 token 的系统规则和工具定义、30000 token 的文档片段,用户问题只有 200 token,输出 1000 token。如果每次都当全新输入,每次都要付这 33000 多个输入 token 的钱;但如果稳定部分能缓存,成本结构就完全变了——优化重点从"让回答短一点",转向让稳定上下文尽量复用、动态上下文尽量精准、输出长度可控。
再说 batch(批处理)。 同样的模型、同样的 token,愿意等一等就更便宜,核心原因是 GPU 利用率。要求实时返回,平台就要为你预留更高优先级的算力;不着急的离线任务——批量标注、数据清洗、自动评测、内容审核——平台可以合并调度、提高利用率,batch token 通常约是标准价的一半。
所以 token 的价格不只取决于哪个模型,还取决于你要多快。AI 价格会越来越像云计算价格:它不是一个单价,而是一组价格维度——标准、批处理、优先级、缓存、长上下文、企业合约。你买的不只是 token 本身,还包括它在什么时间、以什么优先级、由什么资源池生产出来。
05|贵的卖确定性,便宜的卖规模
现在可以回答开头的问题了:为什么高价模型和低价模型能同时存在?
因为大模型行业从来不是单一市场,而是很多个市场叠在一起。
低价 token 的市场,是高频、标准化、容错率相对高的任务:客服、文本分类、信息抽取、摘要、翻译、批量内容处理。在这些场景里,模型只要"足够好",价格就非常关键——调用量大,每百万 token 便宜一点,总账单就差很多。
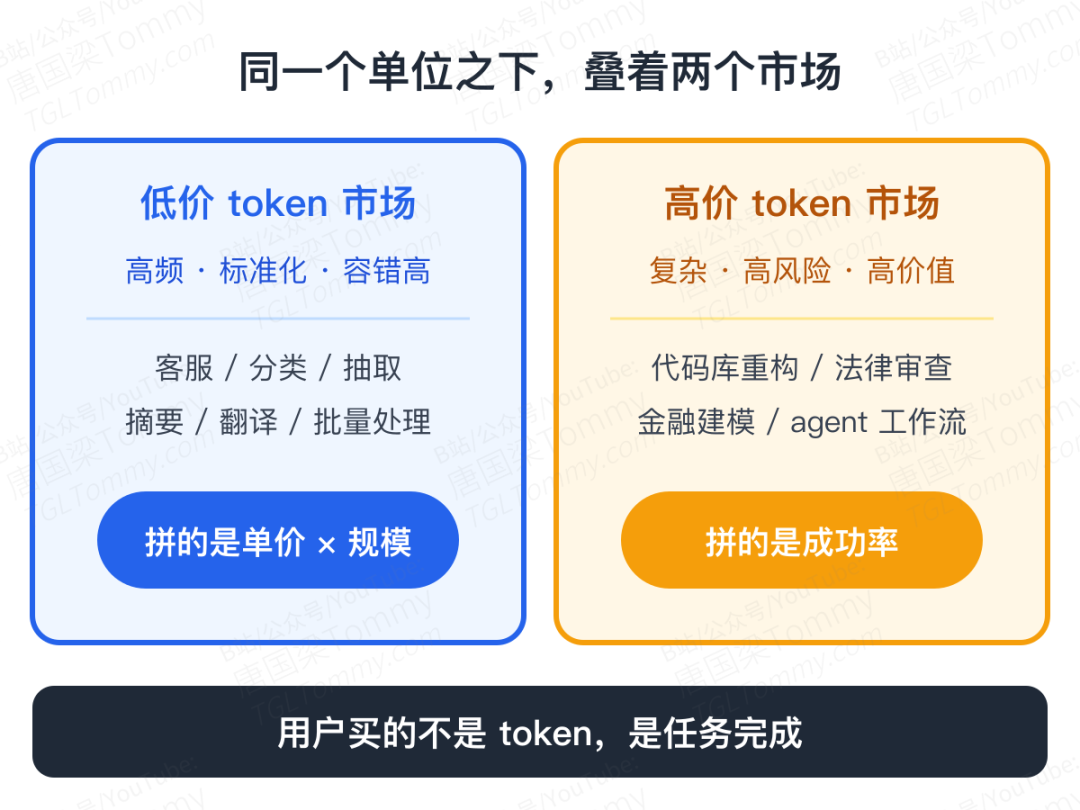
高价 token 的市场,是复杂、高风险、高价值任务:大型代码库重构、复杂数据分析、法律文书审查、金融建模、企业级 agent 工作流。在这些场景里,用户掏钱买的是更高的成功概率,便宜反而排在后面。
这句话很关键:用户买的不是 token,是任务完成。
如果便宜模型做某个任务单次 1 块钱,但失败率高、要反复重试、还要人工审核返工;而贵模型单次 20 块钱,但一次成功、结果稳定。到底谁更便宜?不一定是前者。
很多人比较模型只看每百万 token 单价,但真正该比的是每个成功任务的总成本:

真实 AI 成本 ≈(token 单价 × 用量 + 延迟成本 + 错误成本 + 人工审核成本)÷ 任务成功率
这不是会计公式,而是判断框架。它提醒我们:单价高不代表贵,单价低不代表便宜,关键是它在你的具体任务里能不能稳定完成、能不能减少重试、能不能降低错误风险。
所以 AI 公司表面上按 token 收费,你掏的钱其实落在三件事上:能力本身——模型强度与上下文长度;交付方式——实时还是批处理、普通队列还是优先队列、能否命中缓存;风险与保障——API 稳定性、工具生态、合规、安全、企业支持。
它们卖的不是字,也不只是 API,而是一套智能基础设施。Token 只是这套基础设施的计量单位。
06|给开发者的六条行动清单
- 不看单价看总成本。便宜模型如果输出啰嗦、重试率高、需要大量人工修正,最后可能更贵。
- 区分任务类型。 输入长输出短的任务,重点优化上下文和缓存;输出长的任务,控制生成长度和结构化输出;实时任务关注延迟;离线任务尽量走 batch。
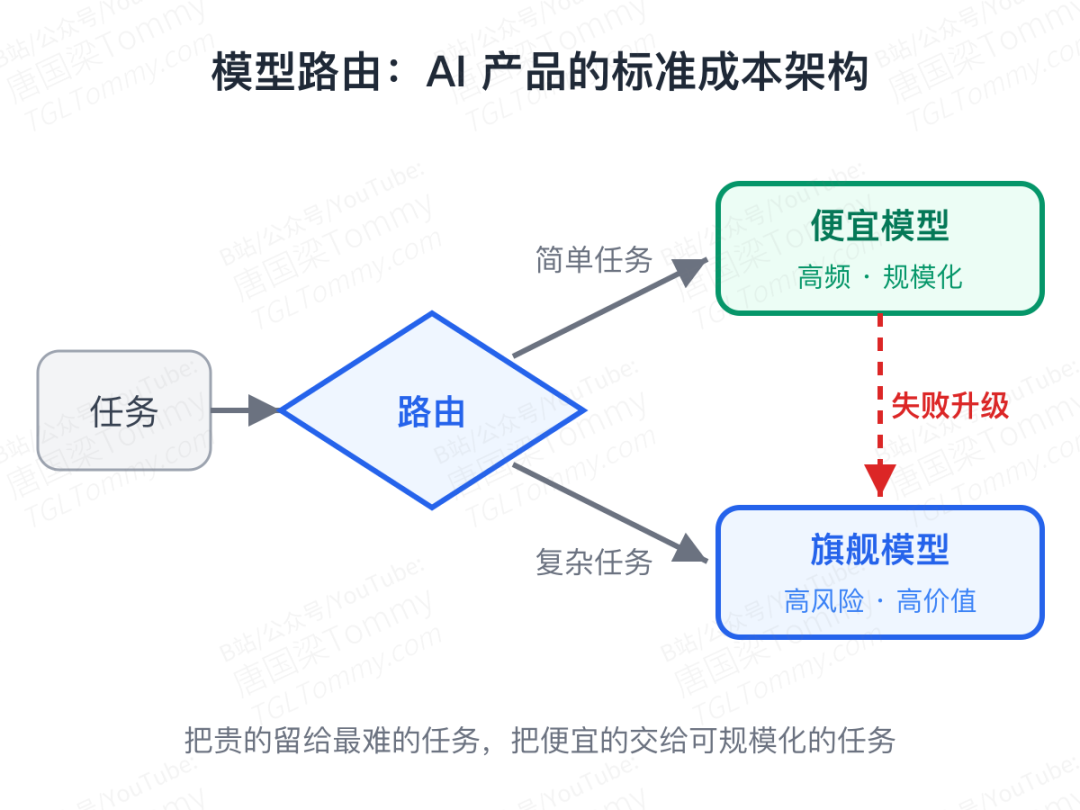
- 做模型路由。 简单任务用便宜模型,复杂任务用强模型,失败后再升级——这会成为很多 AI 产品的标准架构。
- 管理上下文。 别把长上下文当数据库。能检索就检索,能摘要就摘要,能压缩就压缩。把所有历史和文档都塞进 prompt,看着省事,实际是在烧钱。
- 提高缓存命中率。 稳定的系统提示词、工具定义、schema 放在 prompt 前部,减少无意义变化。写 prompt 正在变成一门成本工程。
- 建立 Token FinOps。 像管云账单一样管 token 账单:哪些用户消耗最多?哪些任务输出过长?缓存命中率是多少?平均每个成功任务成本是多少?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号