AI 知识库不是资料仓库,而是 Agent 的业务知识层

AI 知识库不是资料仓库,而是 Agent 的业务知识层

唐斩
发布于 2026-06-29 12:26:19
发布于 2026-06-29 12:26:19
大家好,我是唐斩。
这篇文章来自一场 2026 年 6 月 24 日晚上的线下分享录音,主题是《AI知识库从0到1的思考与实践分享》。
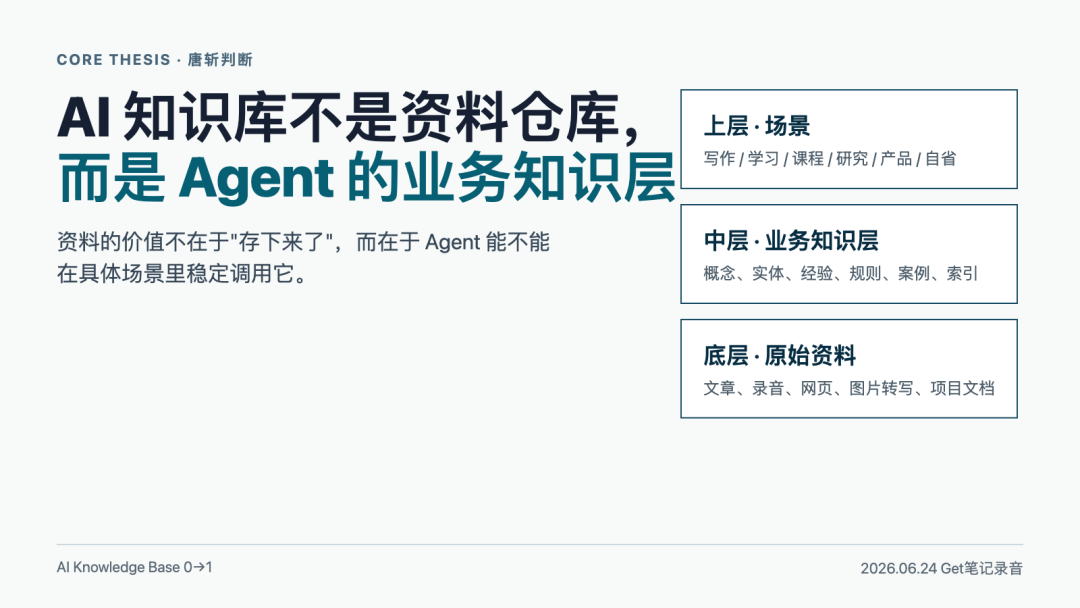
我重新听这段录音时,最想保留的不是某个工具教程,而是一个判断:AI 知识库不是一个更智能的收藏夹,它应该成为 Agent 做事时调用的业务知识层。
如果只是把文章、网页、录音、PDF 全部塞进一个地方,然后告诉自己"我有知识库了",这件事的价值很有限。真正有价值的是,Agent 能不能基于这些资料持续帮你写作、学习、研究、做课程、做产品,甚至帮你更好地理解自己。
核心判断:AI 知识库是 Agent 的业务知识层
核心判断:AI 知识库是 Agent 的业务知识层
1. 为什么现在还要讲知识库
我理解个人使用 AI 提效,大概经历了三个阶段。
第一阶段是 chatbot。从 ChatGPT 开始,我们主要用 AI 获取信息。它缩短的是找资料、问问题、解释概念的时间。
第二阶段是 Agent。AI 开始不只是回答,而是帮我们做事。写代码、改文档、跑脚本、查资料、生成素材,这些白领办公场景已经越来越常见。
第三阶段就是个人 AI 知识库。这个阶段要解决的问题变了:AI 能帮我写,但写得浅;AI 能帮我干活,但每次都要重新解释背景;AI 能生成结果,但风格不稳定,体系也不连续。
所以我才会认为,从长时间对个人收益最大这个角度看,知识库会比单独抓一个 Skill 或直接用别人的 Agent 更重要。因为 Skill 和 Agent 往往给你的是一个压缩后的结果,而知识库保留的是从原始资料到最终结果的链路。
这条链路能积累。
2. 知识库里到底该放什么
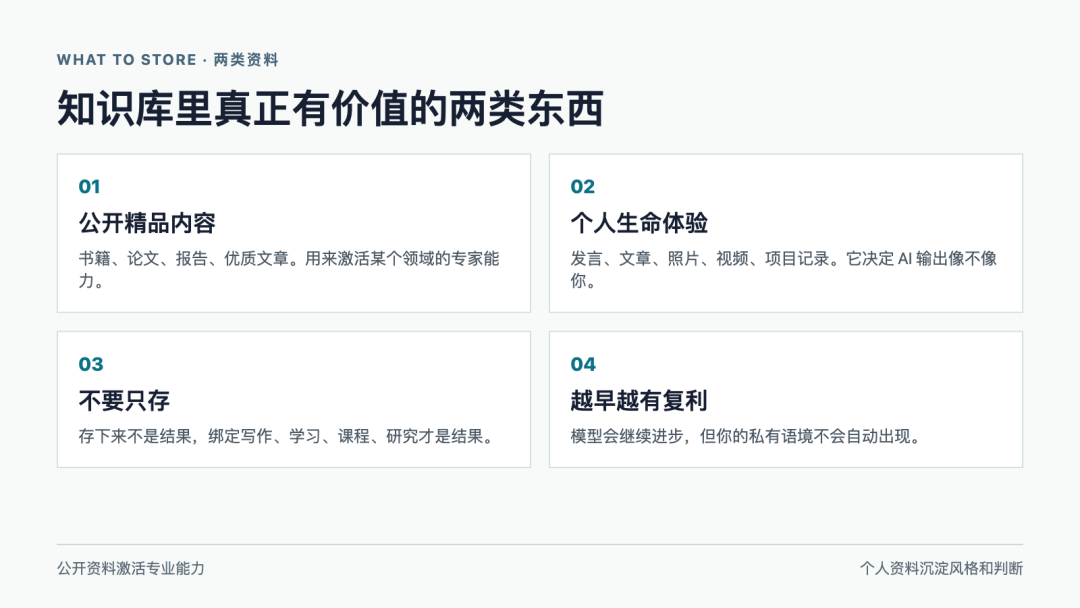
我在分享里把知识库内容分成两类。
第一类是公开精品内容。比如书籍、论文、行业报告、优质文章。这类资料适合做特定领域的知识库,它的作用是激活大模型在某个领域里的专家能力。
第二类是个人生命体验。你的发言、文章、照片、视频、旅行记录、项目记录、每天的想法,这些东西不是网上的公开知识,而是你自己的材料。
我更看重第二类。
因为当模型能力越来越接近,公开资料越来越容易被所有人拿到,真正能区分一个人的就不是"你会不会用 AI",而是 AI 能不能读到你的历史、风格、判断和真实处境。
这也是为什么我现在会把录音、日常想法、历史文章都尽量收集起来。今天这场分享本身就是例子:很多人平时讲出来的话,转头就被忽略了,但这些话很可能就是最有价值的知识库原料。
知识库里的两类资料:公开精品内容和个人生命体验
知识库里的两类资料:公开精品内容和个人生命体验
3. AI 知识库真正要建的是业务知识层
很多人一听知识库,就会想到传统笔记软件。收藏网页,分文件夹,做摘抄,贴标签。
这套方法在 AI 之前就存在,但它很反人类。它要求人像机器一样整理资料,最后还经常出现一个问题:存的时候很认真,用的时候找不到。
AI 之后,事情变了。我们不应该再让人手动承担所有整理工作,而是让大模型负责抽取、关联、索引和重组。
我更愿意把 AI 知识库看成三层:
底层是原始资料。文章、录音、网页、图片转写、项目文档,都放在这里。
中间是业务知识层。Agent 从原始资料里抽取概念、实体、经验、规则、案例,形成可读、可追踪的结构。
上层是具体场景。写文章、做课程、做研究、做自省、做产品、服务客户,都属于上层调用。
这里的关键不是"资料越多越好",而是中间那层能不能被 Agent 稳定调用。
4. 普通人起步,别急着上复杂方案
现在一讲知识库,很多人会先问 RAG。
我的判断很简单:企业级、大规模、资料量特别大的知识库,RAG 很重要。但对个人来说,起步阶段不一定要先上 RAG。
原因是 RAG 更像把资料映射到向量空间,检索有效,但对人不直观。你知道它能搜到东西,却看不到知识到底怎么被组织。
LLM Wiki 这类方式更适合个人早期使用。它生成的是 Markdown、索引、概念、实体、关系和日志,人能看懂,Agent 也能读。
但我也不建议一开始就把架构搞得太复杂。
如果你只有十几篇文章、几十个 Markdown 文件,最小版本就是一个文件夹、一个入口索引、一个 CLAUDE.md 或类似的全局说明。让 Agent 先能找到资料,先能产出结果。
等资料多到你自己和 Agent 都开始管理不过来,再升级成更完整的 LLM Wiki 结构。

从 0 到 1:先跑通最小闭环
从 0 到 1:先跑通最小闭环
5. 我会怎么从 0 到 1 做
最小路径可以很朴素。
第一步,选一个场景。
不要说"我要做一个个人知识库",这个目标太虚。你可以说:"我要用它写公众号",或者"我要用它学习一个新概念",或者"我要用它整理课程资料"。
第二步,准备一个本地 Markdown 文件夹。
我现在更偏向用 Obsidian 做底层存储,因为它本地优先,对 Markdown 友好,Agent 读写也顺。云文档不是不能用,但高频读取时会慢,也会受权限、频率和存储空间限制。
第三步,把真实资料放进去。
如果做内容创作,就放你的历史文章、口播稿、录音转写。如果做行业研究,就放行业报告和高质量文章。如果做数字分身,就放自己的长期输出、想法、照片说明和关键决策记录。
第四步,让 Agent 生成入口索引和知识层。
这里不要只让它总结。要让它告诉你:有哪些主题、有哪些概念、哪些资料互相关联、哪些内容是孤立的、哪些文件应该继续补充。
第五步,立刻产出一次。
写一篇文章,做一份课程大纲,生成一个学习路线,或者让它回答一个你真实工作里会遇到的问题。第一次结果不完美很正常,但你必须通过产出来反推结构。
6. 0 到 1 之后,难点才开始
搭起来不难,难的是持续经营。
我现在会把这件事拆成三类动作。
第一,建立自己的收集体系。
手机上的碎片想法可以用 flomo 这类工具;语音可以用录音卡;微信公众号内容我会通过得到大脑读取;网页可以用 Obsidian 浏览器插件;本地写作和项目资料就直接进 Markdown 文件夹。
第二,让 Agent 定期自检。
比如每周一次,让 Agent 检查孤立内容、重复内容、过期内容、互相冲突的版本,以及最近新增资料有没有进入索引。
第三,让专业知识库自生长,但要有审核队列。
如果你做的是 AI 编程、OPC、出海、教育等持续变化的领域,可以让 Agent 定期检索新资料,先放到待审核目录。你审核之后再入库。否则知识库会被低质量资料污染。
7. 最大的坑:只存不用
很多人担心只存不看。
我反而觉得,AI 时代只存不看不是最大问题。未来很多资料本来就不需要你自己看,AI 可以替你读。
真正的问题是只存不用。
如果知识库没有绑定具体场景,它最后还是收藏夹。你会觉得自己很努力,但它不会改变你的产出。
所以我建议每个知识库都问一个问题:它下一步要帮我做什么?
帮我写文章?帮我学一个概念?帮我给学生写成长报告?帮我复盘自己的决策?帮我准备一场公开课?
这个问题越具体,知识库越容易变成生产系统。

避坑:不要只存不用
避坑:不要只存不用
8. 开发者应该怎么理解这件事
对开发者来说,我觉得 AI 知识库不是一个笔记产品问题,而是上下文工程问题。
Agent 要稳定工作,必须知道三件事:
第一,原始资料在哪里。
第二,哪些资料可以改,哪些资料不能改。
第三,每一次抽取、整理、改写发生了什么。
所以原始资料层要尽量保护起来。知识层可以让 Agent 修改,但要有日志。关键文件可以通过规则声明,必要时直接用操作系统权限设成只读。
这其实跟软件工程很像。你要有源文件,要有构建产物,要有变更日志,还要有边界。
没有这些边界,Agent 改知识库就会变成一件很危险的事。
9. 这件事也有商业机会,但别想得太轻
现场问答里,有人提到给别人搭建个人知识库,尤其是老师群体。
这个方向我觉得有需求。老师有大量资料、学生记录、课程内容、家长沟通文本,确实适合用 AI 知识库提高效率。比如幼儿园老师记录每个孩子的身体、心理和学习情况,期末生成家长报告时,就可以从知识库里拉取信息。
但这里有一个很现实的问题:个性化知识库很难完全代做。
别人可以帮你搭结构、搭工具、做录入接口、做陪跑,但最关键的判断、经验、目标和使用场景,必须由用户自己参与。否则搭出来的东西不会真的贴合你。
所以如果要做商业化,我更看好"陪跑 + 模板 + 录入接口 + 场景交付",而不是单纯帮别人建一个文件夹。
10. 我的建议
如果你还没有开始,不要先研究一个月工具。
今天就做一个最小版本:
- 建一个本地文件夹。
- 放进 10 到 20 篇你真正会用的资料。
- 写一个入口说明,让 Agent 知道这个库用来干什么。
- 让 Agent 生成索引。
- 立刻用它产出一篇文章、一份大纲或一个真实问题的答案。
然后看结果哪里不对。
不够像你,就补个人历史输出。
不够专业,就补高质量资料。
结构混乱,就让 Agent 重做索引和关系。
有冲突,就清理、归档、加版本规则。
AI 知识库不是一次性工程。它更像一个长期协作对象。你每天多喂一点真实材料,多用它解决一个具体问题,半年之后它才会开始像你的东西。
我现在对这件事的判断很明确:未来模型能力会继续进步,但每个人手里的私有语境、生命体验和业务资料不会自动出现。
这部分,越早积累越有复利。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号