
解密Prompt系列68. 告别逐词蹦字 - Transformer 的新推理范式
Transformer 的核心范式一直是“Next Token Prediction”——像接龙一样,一个词一个词地往后蹦。虽然 OpenAI o1 和 DeepSeek-R1 通过 Chain of Thought (CoT) 开启了“慢思考”时代,但其本质依然是通过生成更多的显性 Token 来换取计算时间。 这就带来了一个巨大的效率悖论:为了想得深,必须说得多。这一章我们看四篇极具代表性的论文(Huginn, COCONUT, TRM, TiDAR),它们不约而同地试图打破这一局限:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归的束缚,进行全局规划? # Hugin:内生循环思考提升深度 >- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach 这篇论文的核心在于打破大模型推理时计算量恒定的限制,提出了一种在“深度”上进行循环的架构,从而实现了在**隐空间(Latent Space)**进行递归推理。 ## 🚨 核心痛点:固定计算图与动态难度的矛盾 传统的 LLM 一旦训练完成,其层数(Depth)是固定的。这意味着无论输入是简单的“1+1”还是复杂的数学证明,模型在生成每一个 Token 时消耗的 FLOPs是一样的 。这显然不符合直觉——难题应该需要更多的“思考时间”。因此我们有了COT和现在的Reasoning模式。 - 现状:为了处理难题,现在的 CoT 策略不得不强迫模型“自言自语”生成大量 Token,这导致了显存(KV Cache)的爆炸式增长和推理速度的线性下降。 - 目标:能否让模型在内部“停下来想一会儿”,但不占用输出带宽? ## 🛠️解决方案:循环深度架构 Huginn 提出了一种特殊的架构设计,试图在 Transformer 中原生实现“慢思考”。 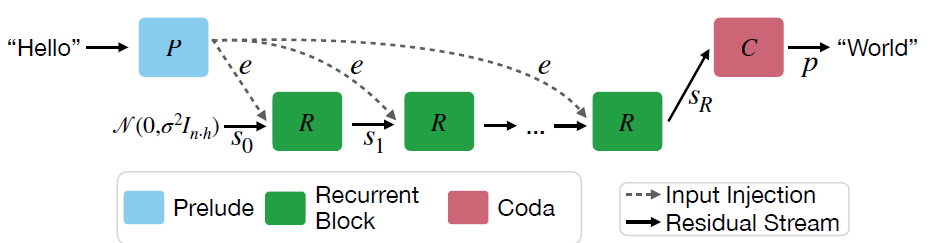 如上图,模型包括三个部分 - (P)Prelude: 相当于Encoder层,负责将 Input Token 映射为隐状态。 - (R)recurrent block: 这是一个多层Transformer Layer,所有的思考都发生在这里,但是和传统Transformer不同的点在于,这个模块可以循环运行任意次。 - (C)Coda:相当于输出头,对思考完成的隐状态进行token解码生成。 **这本质上是“层参数共享”的极致应用**。 模型通过动态决定 R 模块循环的次数,实现了在参数量不变的情况下,动态调整推理时的计算深度。为了防止深层循环导致的梯度消失或遗忘,模型在每一步循环都会注入原始输入的 Embedding,起到锚点(Anchor)的作用。 ## 💡 深度洞察 1. **高效推理**:递归模块不产生线性增长的KV-Cache,只是不断更新递归参数 2. **难度自适应**:可以通过控制递归的轮数来对不同难度的问题实现自适应计算,不需要对所有难度的问题进行统一的思考或者不思考 3. **Test Time Scaling**:论文发现递归的模式同样存在Test-time scaling,更多的递归次数会带来持续的表现提升。 # COCONUT:抛弃语言,用“直觉”思考 >- Meta: Training Large Language Models to Reason in a Continuous Latent Space 如果说 Huginn 是在架构层面“折叠”了深度,那么 COCONUT则是在思维载体上进行了一次革命。它质疑了大模型推理的一个基本假设:为什么思考的过程必须用人类语言(Tokens)来表达? ## 🚨核心痛点:语言空间的局限性 由OpenAI-O1拉开序幕的Reasoning时代,当前的推理过程一般是 :Hidden State $\rightarrow$ Logits $\rightarrow$ Sampling (Token) $\rightarrow$ Embedding $\rightarrow$ Next Input。 这就引入了一些局限性 - **信息丢失**:将高维连续的 Hidden State 坍缩为离散的 Token,会丢失大量非结构化的“直觉”信息。就像你脑海里有大量信息,却必须用一句话说出来。 - **效率低下**:当CoT 中充斥着 "Let's think step by step", "Therefore" 等无意义的连接词。 - **线性约束**:语言是线性的,但思维往往是发散的、网状的。之前很多parrallel思考的方案都是为了打破这个约束。 ## 🛠️解决方案:连续思维链 COCONUT 提出了一种Latent Mode。虽然架构仍基于 Transformer,但它改变了数据流转方式: 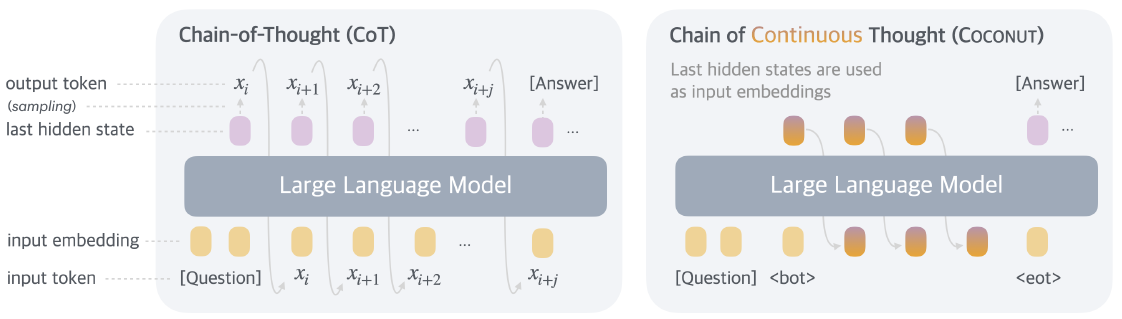 1. **推理模式:Latent Mode (隐模式)** Coconut 引入了一种新的推理模式。模型可以在Language Mode和Latent Mode之间切换。 机制:当模型进入Latent Mode后(输出\<bot\>特殊字符),它不再将 Last Hidden State 解码为 Token。而是直接将这个 Hidden State 作为下一步的 Input Embedding 喂给模型。 这就像是模型在“自言自语”,但是用只有它自己听得懂的“脑电波”(向量)在交流,而不是用人类语言。这种“连续思维”一直持续到模型输出\<eot\>特殊字符,然后再切回语言模式输出最终答案。 2. **训练策略:多阶段课程学习** 为了让模型学会使用上述的思考向量信息,论文使用了渐进式的训练方案,如下图  - Stage 0:先用标准的 CoT 数据训练模型,让它学会逻辑。 - Stage 1 ~ k:逐步“擦除”CoT 中的文本。 - 例如,在 Stage 1,把 CoT 的第 1 步推理文本去掉,替换为 $c$ 个 Continuous Thoughts(隐向量)。模型必须学会用这 $c$ 个向量来承载原本那句话的逻辑信息 - 随着训练进行,逐步把更多的文本推理步骤替换为隐向量。 - 最终形态:所有的中间推理文本都被“内化”成了连续的隐向量,模型只输出最终答案。 ## 💡 深度洞察 1. **核心能力涌现:隐式 BFS (Implicit Breadth-First Search)** 这是最精彩的发现。相比原有COT是线性的,同一时刻只能推理一个思路。但COconut因为Hidden State是高维连续向量,所以它可以处于“叠加态”,可以同时编码多个可能的推理路径。隐式进行了广度搜索。 2. **推理效率提升** 虽然和Hugin相比依旧需要使用KV-cache,但因为连续向量的数量往往显著小于token数,所以推理效率会有提升,同时也因为省略了推理token采样的步骤,而进一步提升吞吐。 3. **超越人了语言思维密度** 尤其对于一些复杂多路径规划任务,以及部分需要`look ahead`推理的任务,因为隐向量比token包含广度更大的思考信息,因此效果有所提升。 看到这里我也有个想法,逻辑上hidden thought一定会比token携带更多的信息量,但最大的问题就是无法可视化,那能否想一会,说两句,想一会说两句,也就是把hidden thought和token reasoning通过interleave串联起来? # TRM: 像改代码一样迭代推理 >- Less is More: Recursive Reasoning with Tiny Networks TRM和前面的Hugin是非常相似的,几乎都是走的“循环思维载体”的思路。但是TRM多了双流递归的设计,把循环过程中的草稿和打磨这两个不同信息拆分开处理。 和COCONUT也有相似之处,只不过COCONUT更像是潜意识在时间轴上(自回归推理)的延伸,而TRM是在质量轴上的不断迭代修正。 ## 🚨 核心痛点:自回归的“落子无悔” Reasoning最大的问题,就是前面COCONUT提到的“落子无悔”问题,想要进一步反思或者修正,就需要继续显性延伸你的思考链路进行反思。 论文的目标:能否构建一个模型,它的推理过程不是“生成下一个词”,而是不断修正当前的答案?这需要模型具备迭代修正的能力。 ## 🛠️ 解决方案:TRM (Tiny Recursive Model) TRM 的架构设计非常精简,它直接回到了最本质的递归结构,如下图 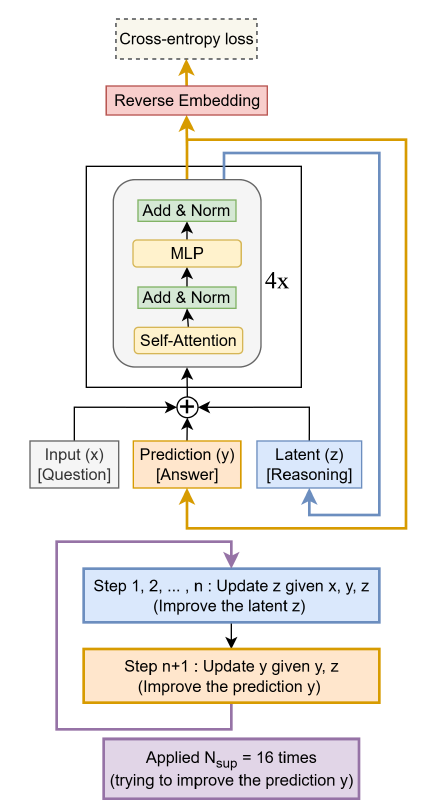 1. **双流递归状态** TRM 维护两个核心状态,并在循环中不断更新它们 : - Latent (Z):推理状态。这和Huginn多步递归循环的R Block类似,都是思维的载体,存储不断更新的思维上下文。 - Prediction (Y):当前答案的草稿。这是 TRM 最独特的地方。它把“当前的预测结果”Embedding 之后,作为下一轮的输入喂给自己。(对比Hugin所有信息都在R,TRM把已经形成的预测结果解耦出来了) 推理循环逻辑 (The Loop): $$\begin{aligned} z_{t+1} &= \text{Net}(x, y_t, z_t) \quad \text{// 思考:基于当前草稿和思维,更新思维} \\ y_{t+1} &= \text{Net}(y_t, z_{t+1}) \quad \text{// 修改:基于新的思维,修正草稿} \end{aligned} $$ 这就像我们写代码:先写个大概 ($y_0$) -> 脑子转一下 ($z_1$) -> 改一行代码 ($y_1$) -> 发现有个 Bug ($z_2$) -> 再改一行 ($y_2$)。 2. **架构极简主义** - Tiny Network:模型只有 2 层 Transformer Layer,参数量仅 5M - 7M - 参数共享:同一个网络(Net)在每一次循环中被反复使用 - 全量推理模式:并非自回归模型token by token的推理,而是每一步循环都生成全量的Y,并且每一步都对全量的Y进行修正 ## 💡 深度洞察 1. **全量生成的思维转换**:TRM 的生成方式更像 Diffusion Model(扩散模型),是从模糊到清晰的过程,而不是从左到右的过程。但这同样也约束了当前TRM只能用于固定长度内容的输出。 2. **Deep Supervision**:训练时,TRM 并不只在最后一步计算 Loss,而是对每一步生成的草稿都计算 Loss。这强迫模型在第一步就给出一个“大致正确”的解,然后在后续步骤中精细化。 # TiDAR >- TiDAR: Think in Diffusion, Talk in Autoregression 英伟达的这篇论文,则是和TRM思路非常相像,都是在生成阶段抛弃自回归“蹦字”的方案,采用全局生成并不断打磨的思路。只不过TIDAR引入了扩散模型,并切让模型在同一个 Forward Pass(前向传播)里,既作为“起草者”并行地想,又作为“验证者”自回归地确认。 ## 🚨 核心痛点:既要还要的困境 在大模型推理中,我们一直面临一个trade-off - AR:自回归模型由于符合语言的因果律,质量最高,但推理速度慢 - Diffusion:非自回归模型可以并行生成,吞吐量极高但往往质量不佳,并且质量会随着生成的token个数而持续下降。 现在已有的一些解决方案例如DeepSeek提出的MTP,同时预测多个token,也是在尝试解决以上的问题,但MTP的本质还是自回归的。 还有Speculative decoding,使用一个轻量级的AR模型去生成多个token的草稿,再用大模型并行对草稿的每个token进行验证,但这样就需要同时部署多个模型进行推理。 ## 🛠️ 解决方案: Think + Talk的双流协同 TiDAR 的模型结构则是在speculative Decoding的基础上,把草稿模型和验证模型合并在了一个模型结构里,通过特殊掩码实现同时推理。 1. **Think in Diffusion** 在推理时,TiDAR 并不像 GPT 那样一次只预测一个词。它使用 Diffusion的方案,在当前位置之后的K个槽位上,同时生成所有候选Token。这 $K$ 个 Token 是**并行**生成的。它利用了扩散模型的全局视野。 2. **Talk in Autoregression"** 生成的这K个候选词并不能直接作为答案,因为 Diffusion 的逻辑一致性不如 AR。TiDAR 在同一个前向传播中,利用 AR 的逻辑对这K个候选词进行拒绝采样。 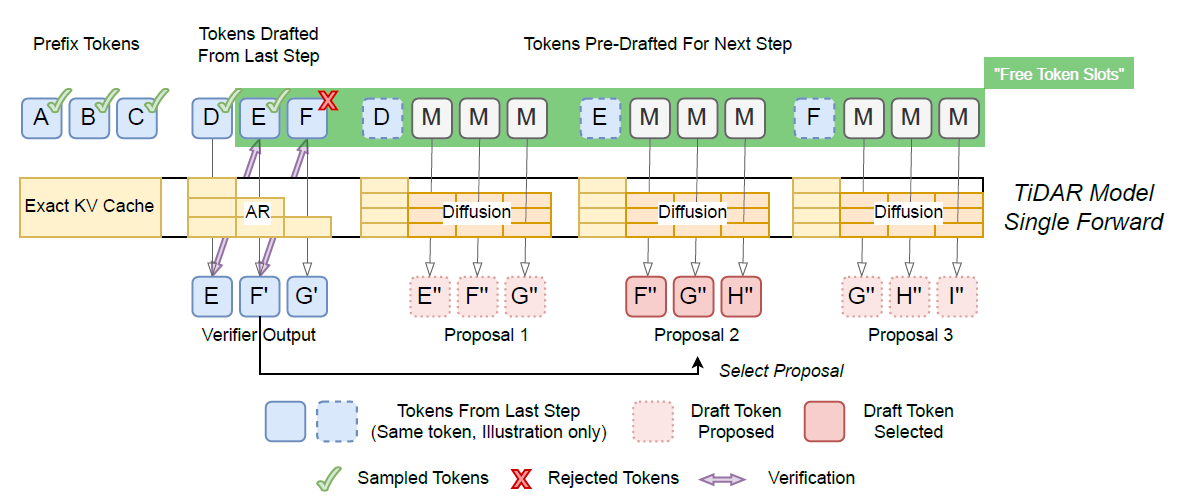 3. **双流的核心实现:结构化注意力掩码** 为了在一次向前推理时,同时实现以上两种推理,TIDAR设计了一个特殊的二维MASK,将序列分成了两个部分 - Diffusion MASK:这个区域的token直接是全连接的,为了让模型能够根据上文同时猜出后面K个词 - AR MASK:这个区域是causal MASK,它负责根据上下文和前面猜出的草稿进行递归生成。 这样在一次向前推理中,Inp亡的KV Cache会参与两次计算 - Input —> Think Mask -> Diffusion Drafts - Input + Diffusion Drafts -> AR Mask -> Final verified Token 4. **多任务联合优化训练** 为了同时训练Diffusion和AR,TIDAR在传统的NSP训练的基础上进行了改良,同时训练两个loss - Diffusion Loss:训练模型在给定上下文和部分噪声的情况下,并行重构出后续 $K$ 个词的能力。 - AR Loss:标准的交叉熵损失,确保模型的最终输出符合语言概率分布 ---- # 总结:推理的未来是“向内生长”? 从以上四篇论文,我们不妨猜测下后Reasoning时代的技术演进方向 1. 从Explicit到Implicit? 2. 从Linear到Recurrent? 3. 从AR到Hybrid? 未来的大模型,或许会变得更像人类的大脑: 表面上沉默寡言,但内心戏极其丰富,并且能够反复推敲,最终给出一个深思熟虑的答案。 想看更全的大模型论文·微调预训练数据·开源框架·AIGC应用 >> [DecryPrompt](https://github.com/DSXiangLi?tab=repositories)
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号