
机器翻译
机器翻译(Tencent Machine Translation,TMT)从大规模双语语料库自动学习源语言和目标语言之间的语义映射,实现从源语言文本到目标语言文本的自动翻译,目前可支持十余种语言的互译。
机器翻译的产品功能有哪些?
文本翻译
提供中文、英文、日语、韩语、德语、法语、西班牙语、意大利语、土耳其语、俄语、葡萄牙语、越南语、印尼语、马来语、泰语18种语言文本的翻译服务,翻译内容经过大数据语料库、多种解码算法、翻译引擎深度优化,在新闻文章、生活口语等不同语言场景中都有深厚积累,同时融合统计机器翻译和神经网络机器翻译的优点,翻译结果专业评价处于行业领先水平。
具体支持的语种,请参见 文本翻译 接口文档。
文件翻译
提供中文、英文、日语、韩语、德语、法语、西班牙语、意大利语等共15种语言文档翻译服务,支持 pdf、docx、pptx、xlsx、txt、xml、html、markdown、properties 等文件格式的翻译。
具体支持的语种和格式,请参见 文件翻译请求 接口文档。
端到端图片翻译
提供中文、英语、日语、韩语、俄语、法语、德语等共18种语言的图片翻译服务,可自动识别图片中的文本内容并翻译成目标语言文本,输入图片,输出同版式翻译后的图片。
具体支持的语种和格式,请参见 端到端图片翻译 接口文档。
机器翻译的产品优势有哪些?
翻译准确
采用先进的神经机器翻译模型,通过多层 Transformer 架构深入学习源语言与目标语言之间的语义联系,精准捕捉句子结构、语法规则和上下文逻辑,大幅降低因语序、语法差异导致的翻译错误。
灵活定制扩展
提供灵活的 API 接口参数配置,支持用户根据业务场景自定义术语表,满足不同人群定制化服务需求。
高性能与极速响应
依托腾讯云的云端算力和深度优化的神经网络架构,机器翻译具备毫秒级响应速度,可轻松应对高并发请求。日均处理能力达几十亿字符。
机器翻译的应用场景有哪些?
文档资料翻译
对于合同、文件、资料、论文、邮件等文档类内容均可快速翻译。
文章资讯阅读
适合于快速获取国外资讯、文章阅读或将自有内容快速发布外文版本。
口语对话辅助
针对日常口语对话句型长期训练,可用于对外实时交流、社交沟通等情境中。
境外旅游服务
境外旅游时的吃饭点餐、酒店住宿、购物支付、交通出行、景点浏览都可使用的翻译服务。
机器翻译的准确度怎么样?
腾讯云机器翻译目前支持18个语种,在2018 WMT 国际机器翻译大赛中获得中英翻译第一的成绩。根据以往数据统计,平均翻译可接受度超过92%。
机器翻译有免费额度吗?
开通了以下机器翻译服务,无论选择预付费或后付费的计费方式,以下服务都可以享受免费调用额度,文本翻译免费额度以免费资源包的形式配送,端到端图片翻译10次免费调用、有效期3个月,免费额度在计费结算时优先扣减。具体的免费额度如下:
服务名称 | 免费额度 |
|---|---|
文本翻译 | 每月500万字符 |
端到端图片翻译 | 10次调用、有效期3个月 |
说明:
扣费优先级:按“免费额度 > 预付费 > 后付费”的顺序进行扣费。(如果后付费已关闭,则预付费额度耗尽后会自动停服)
当月首次开通服务的客户,开通当天立即发放文本翻译免费字符资源包;后续该客户的免费资源包从每月1日开始发放。免费资源包在发放之后才正式生效,且仅当月有效。端到端图片翻译免费资源包需前往 机器翻译控制台 > 资源包 手动领取,领取后正式生效,且仅在有效期内有效。
如何使用机器翻译服务?
通过 API 3.0 Explorer 在线调用
适用对象:开发初学者,有代码编写基础人员。
说明:此方式能够实现在线调用、签名验证、SDK 代码生成和快速检索接口等能力。
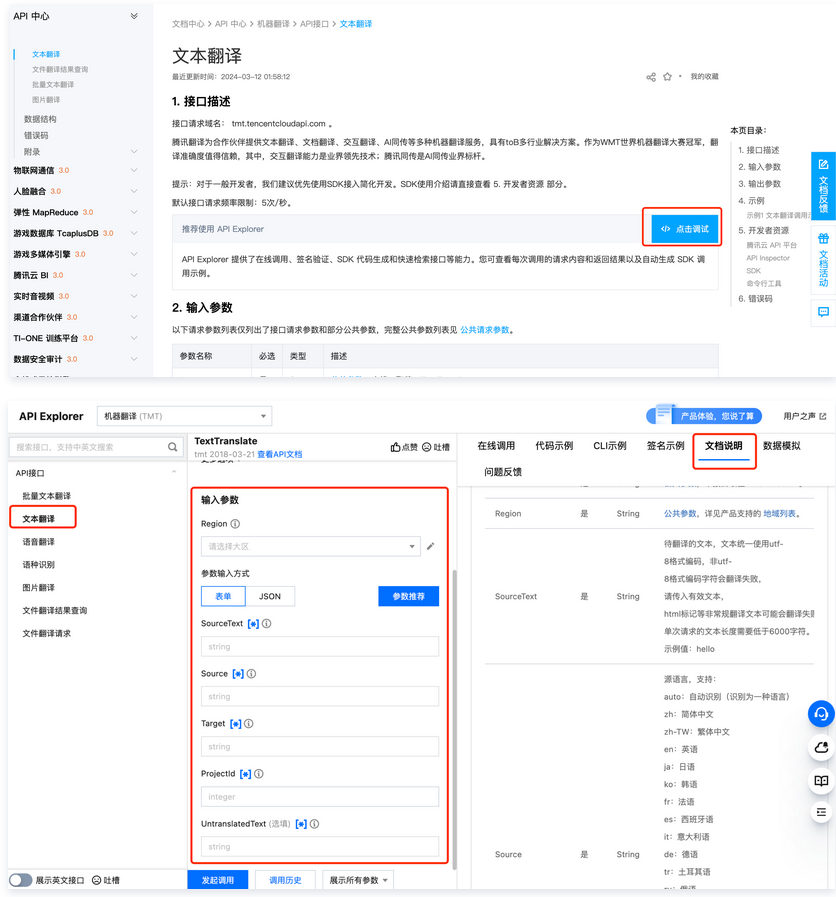
在 API 概览 选择需要调用的接口,选择点击调试进入调试页面。并填写输入参数。输入参数在 API 3.0 Explorer 界面的“文档说明”选项卡中可以查看对应接口输入参数的具体含义。
说明:
平台将对登录用户提供临时 Access Key,以便进行调试。
通过编写代码,调用 API 进行开发
适用对象:开发工程师,熟悉代码编写人员。
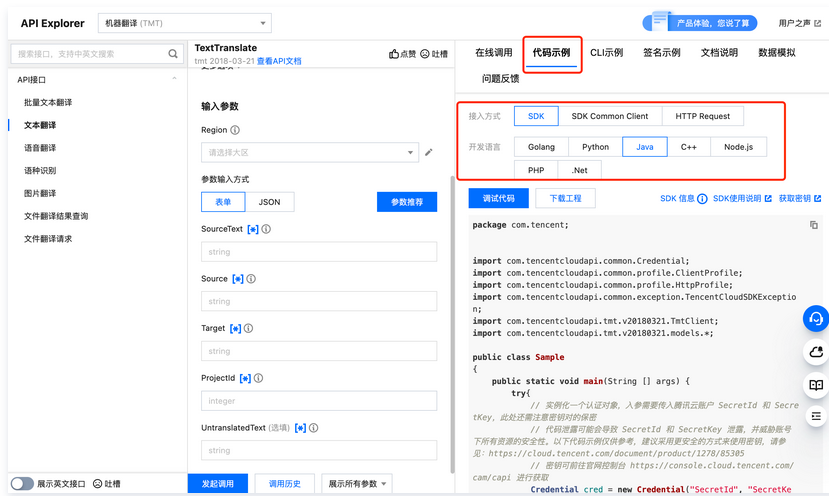
说明:腾讯云已编写好的开发工具集(SDK),支持通过调用语音识别服务 API 开发功能。目前 SDK 已支持多种语言,包括 Python、Java、PHP、Go、Node.js、.Net 等,可在每个服务的文档中下载对应的 SDK。
填写输入参数后,选择“代码示例”选项卡,可以看到自动生成的不同编程语言代码(可支持 Java、Python、Node.js、PHP、GO、.NET、C++ 语言),生成代码中的部分字段信息和填写内容是关联的,如需调整传入参数,可在左侧修改参数值后重新生成代码。
查看密钥
前往官网控制台 腾讯云控制台 API 密钥管理 获取密钥。
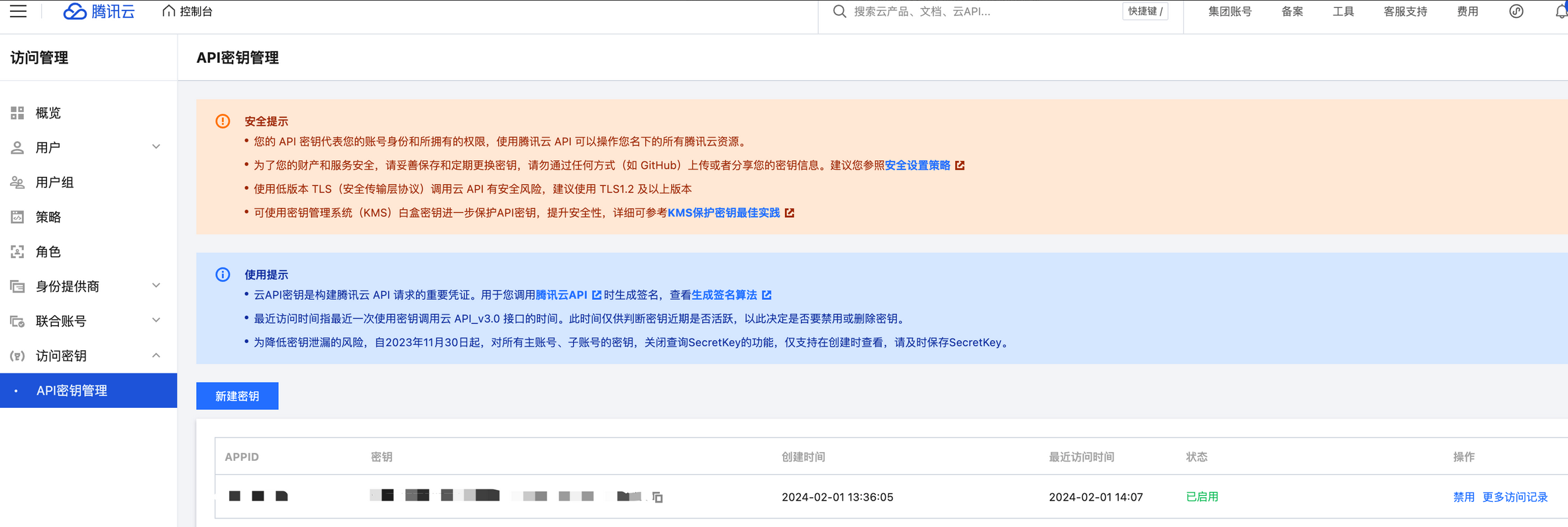
单击新建密钥,弹窗查看自己的 SecretId 和 SecretKey,可单击下载 CSV 文件保存至本地。
注意:
为降低密钥泄漏的风险,自2023年11月30日起,新建的密钥只在创建时提供 SecretKey,后续不可再进行查询,请保存好 SecretKey。
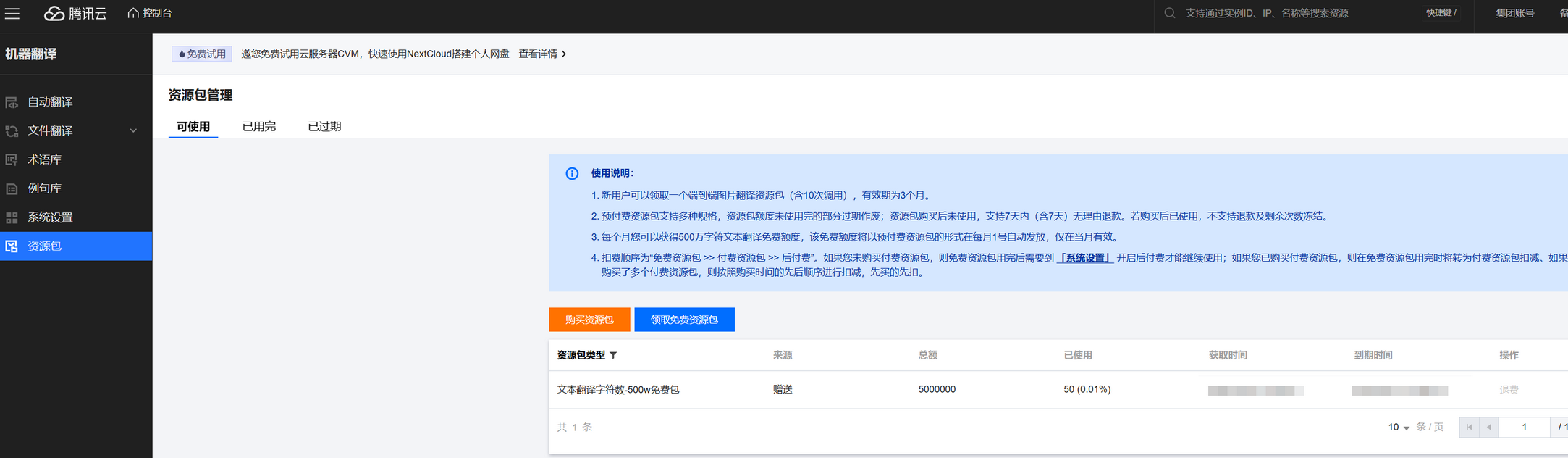
查看用量
登录 机器翻译控制台,进入资源包页面,即可查看机器翻译各个服务的使用情况。
机器翻译的基本原理是什么?
数据预处理
收集大量平行语料,即源语言和目标语言对应的句子对。对这些数据进行清洗,去除噪声、错误或不规范的内容,然后进行分词、标注等处理,将文本转化为模型可处理的格式。
模型构建
采用Transformer架构构建模型,包含编码器和解码器两个部分。编码器负责将源语言句子编码成一系列向量表示,捕捉句子的语义信息;解码器则根据编码器的输出和已生成的翻译结果,逐词生成目标语言句子。
模型训练
使用预处理后的平行语料对模型进行训练。通过定义损失函数(如交叉熵损失)来衡量模型预测结果与真实目标之间的差异,利用优化算法(如随机梯度下降及其变种)不断调整模型参数,使损失函数值最小化,让模型学习到源语言和目标语言之间的映射关系。
翻译过程
当输入源语言句子时,模型先通过编码器将其转换为向量表示,再由解码器根据这些向量生成目标语言句子。解码器在每一步会根据之前生成的词和编码器的输出,预测下一个最可能的词,直到生成完整的句子。
后处理
对模型生成的翻译结果进行后处理,包括词形还原、大小写调整、标点修正等,使翻译结果更符合目标语言的表达习惯和规范。
机器翻译如何处理多义词的翻译?
上下文建模
- 捕捉全局信息:神经网络机器翻译模型,像Transformer架构,能对整个源语言句子建模。在处理多义词时,它会结合多义词前后的词汇、语法结构等信息来理解其在当前语境中的含义。例如“bank”这个词,若句子是 “I put my money in the bank”,模型通过“money”以及金融相关的语境知识,判断此处“bank”应译为“银行”;若句子是 “We sat on the bank of the river”,结合“river”,就会将其译为“河岸”。
- 长距离依赖处理:借助注意力机制,模型能关注到源语言句子中与多义词距离较远但对理解其语义有重要作用的部分。比如在一些复杂句式中,关键信息可能离多义词较远,注意力机制可以让模型聚焦这些关键部分,从而更准确地判断多义词的语义。
词向量表示
- 语义空间映射:模型会把源语言和目标语言的词汇映射到一个高维语义空间中,每个词对应一个向量。多义词在不同语境下会有不同的向量表示,以此区分其不同语义。例如,“run”作“跑步”和“经营”之意时,在语义空间中的向量位置不同,模型依据向量来选择合适的翻译。
- 相似度计算:在翻译时,模型计算源语言多义词向量与目标语言词汇向量的相似度,选择相似度最高的词汇作为翻译结果。这样能更精准地匹配多义词在当前语境下的正确语义。
大规模语料学习
- 丰富语义模式:腾讯云机器翻译使用大量平行语料进行训练,这些语料涵盖了各种领域和语境。通过学习这些语料,模型能掌握多义词在不同领域、不同句子结构中的常见语义和翻译方式。比如在医学语料中,“cell”常译为“细胞”;在监狱相关语境中,可能译为“单人牢房”。
- 语言习惯积累:大规模语料还包含不同语言的表达习惯和搭配信息。模型学习到这些后,在翻译多义词时会考虑目标语言的习惯搭配。例如英语中“make a decision”是常用搭配,模型会将“decision”正确翻译并遵循这种搭配习惯。
机器翻译的上下文理解能力如何提升?
数据处理
- 扩充高质量平行语料:收集更多领域、场景的平行语料,如商务、法律、医疗等专业领域,以及日常对话、新闻资讯等场景。丰富的语料能让模型学习到更多上下文信息和语言表达方式。
- 数据清洗与标注:去除噪声数据,如错误的翻译、不规范的文本等,并对数据进行标注,如词性、句法结构、语义角色等,帮助模型更好理解语言结构和语义信息。
- 构建上下文窗口:在处理文本时,合理设置上下文窗口大小,让模型能关注到足够长的上下文信息。同时采用滑动窗口等技术,处理长文本时确保重要上下文不被遗漏。
模型架构优化
- 采用先进架构:使用Transformer及其改进架构。这些模型具有强大的并行计算能力和对长序列的处理能力,能有效捕捉上下文信息。
- 引入注意力机制:增强模型对上下文中关键信息的关注,让模型在翻译时聚焦与当前词相关的上下文部分,提高翻译准确性。
- 设计层次化模型:构建层次化神经网络结构,先对局部上下文建模,再逐步扩展到更大范围的上下文,使模型能从不同粒度理解上下文。
训练方法改进
- 无监督预训练:在大规模无标注文本上进行预训练,让模型学习通用语言知识和上下文模式。再通过有监督微调,在平行语料上针对翻译任务进行优化。
- 多任务学习:让模型同时学习多个相关任务,如词性标注、句法分析等,借助其他任务的学习信息提升上下文理解能力。
- 强化学习:使用强化学习算法,让模型根据翻译结果和上下文反馈不断调整策略,提高翻译质量和上下文理解能力。
外部知识融合
- 领域知识注入:针对特定领域翻译任务,向模型输入领域专业知识,如术语表、规则等,使模型在翻译时能结合领域知识理解上下文。
机器翻译如何实现实时协同翻译?
技术架构支持
- 分布式系统架构:采用分布式系统,将翻译任务拆解并分配到多个服务器节点并行处理。这样能快速响应用户请求,保证在高并发场景下也能稳定、实时地完成翻译工作。
- 微服务架构:把翻译功能拆分成多个独立的微服务,如文本处理、模型推理、结果整合等。各微服务可独立开发、部署和扩展,便于系统灵活应对不同翻译需求,提升整体处理效率。
高效数据处理
- 数据处理优化:对输入文本进行快速预处理,包括分词、词性标注等操作。通过优化算法和使用高效工具,减少预处理时间,为后续翻译环节争取时间。
- 模型轻量化与加速:采用模型压缩、量化等技术对机器翻译模型进行轻量化处理,在不显著降低翻译质量的前提下,加快模型推理速度。同时利用GPU、TPU等硬件加速计算,提高处理效率。
协同机制实现
- 实时数据同步:当多个用户同时进行翻译协作时,系统通过实时数据同步技术,确保每个用户看到的翻译内容和状态是最新的。采用消息队列等中间件实现数据的快速传递和更新,保证协同的一致性。
- 冲突解决策略:在多人协同翻译过程中,可能会出现对同一内容的不同修改和翻译建议。系统制定冲突解决策略,如根据用户权限、修改时间等因素自动合并或提示用户手动解决冲突。
用户交互设计
- 界面实时反馈:设计友好的用户界面,在用户输入文本时实时显示翻译结果。通过异步加载和局部更新等技术,减少界面卡顿,提供流畅的交互体验。
- 协作功能支持:提供多人协作翻译的界面和功能,如用户可以实时看到其他成员的翻译进度和修改内容,还能进行评论、批注等操作,方便团队成员之间的沟通和协作。
持续优化与学习
- 用户反馈收集:收集用户在使用实时协同翻译过程中的反馈意见,了解用户需求和遇到的问题。根据反馈对系统进行持续优化和改进,提升用户体验。
- 模型持续学习:利用用户的翻译数据和反馈信息,对机器翻译模型进行持续训练和优化。使模型不断学习新的语言表达和翻译模式,提高翻译质量和协同效率。
- 07:机器翻译
- RNN与机器翻译
- 业界 | 搜狗机器翻译团队获得 WMT 2017 中英机器翻译冠军
- 浅谈神经机器翻译
- 【玩转腾讯云】【腾讯云机器翻译TMT】机器翻译入门
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号