Spark Streaming 作为 Spark 生态中专注于实时数据处理的核心组件,凭借其灵活的处理模式、与 Spark 核心引擎的深度融合以及丰富的数据源支持,成为实时大数据领域的重要工具。WeData 平台集成了 DLC Spark Streaming 节点,为用户提供了便捷的任务开发功能。本指南将详细讲解 DLC Spark Streaming 节点的配置方法。
使用限制
1. DLC Spark Streaming 任务节点仅支持使用标准 Spark 引擎。
2. DLC Spark Streaming 任务节点需配置独立调度资源组,切勿与其他任务共用,否则会干扰其他任务的正常调度。
前置条件
1. 需要在项目中绑定 DLC 引擎,引擎内核可参见 DLC 引擎内核版本。
2. 已经在 DLC 中创建任务节点所使用的库表。
3. 当前用户需要拥有对应 DLC 计算资源和库表的权限,有关权限授予,请参见 DLC 文档。
4. 用户需要上传所需资源,包括 py/jar 程序包以及依赖资源等,详情请参见 资源管理。
操作步骤
任务节点参数配置
用户需要选择运行的程序包、填写配置参数、选择执行引擎。相关配置说明如下:
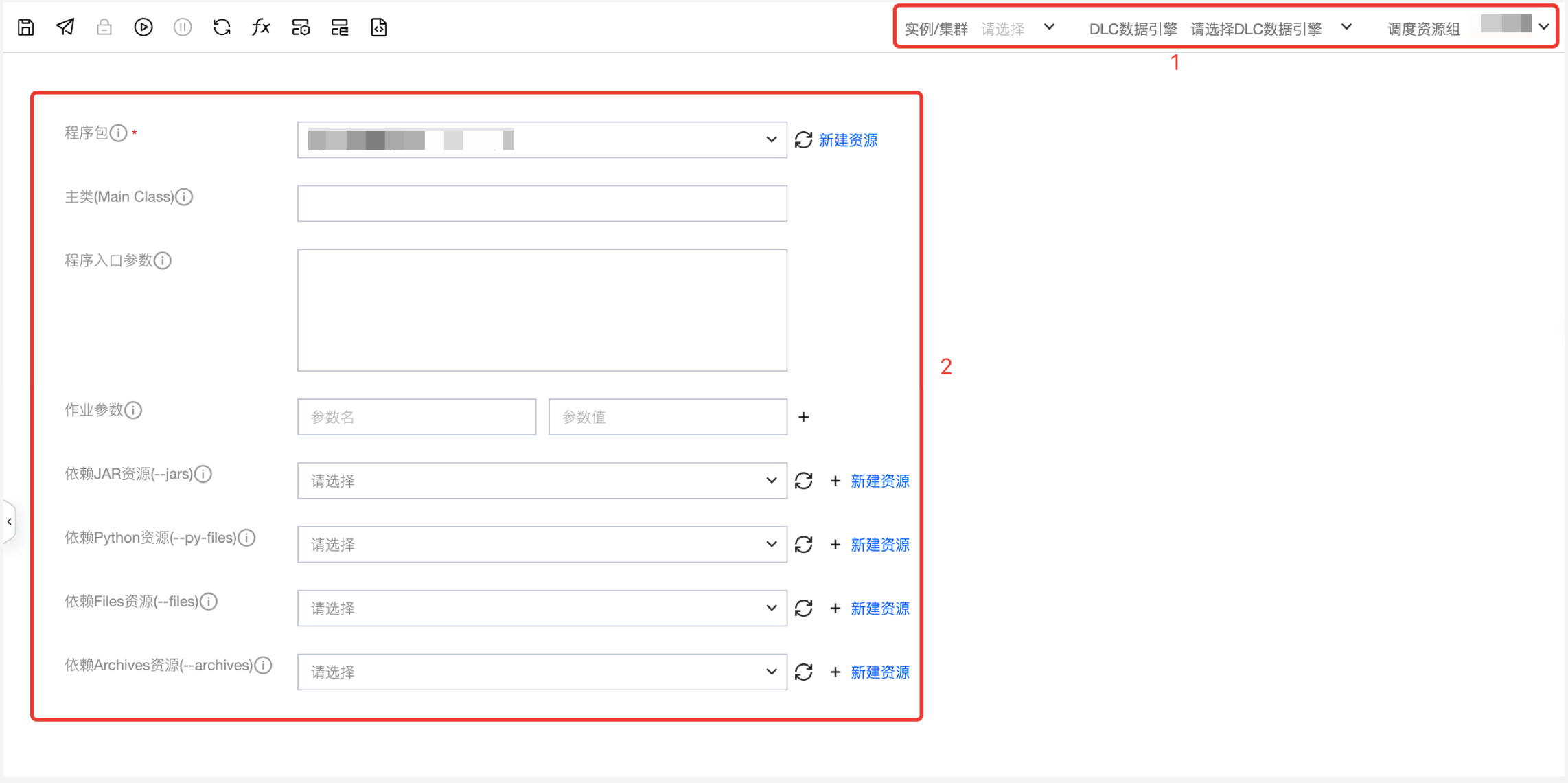
序号 | 配置项名称 | 配置项描述 |
1 | 实例/集群 | |
| DLC 数据引擎 | |
| 调度资源组 | |
2 | 程序包 | 必选,执行任务所使用的 JAR 资源文件或 Python 资源文件。 |
| 主类 | 若程序包为 jar 文件必填 |
| 程序入口参数 | 您可根据需要添加参数,多个参数之间用空格分隔。 |
| 作业参数 | 您可根据需要添加参数,多个参数之间用空格分隔。 |
| 依赖 JAR 资源 | 执行任务所依赖的 jar 文件,可以配置多个。 |
| 依赖 Python 资源 | 执行任务所依赖的 python、zip、egg 格式文件,可以配置多个。 |
| 依赖 Files 资源 | 执行任务所依赖的文件,支持 jar、zip、txt、conf 等格式文件,可以配置多个。 |
| 依赖 Archives 资源 | 执行任务所依赖的压缩包,支持 tar.gz、tgz、tar 格式文件,可以配置多个。 |
任务节点属性配置
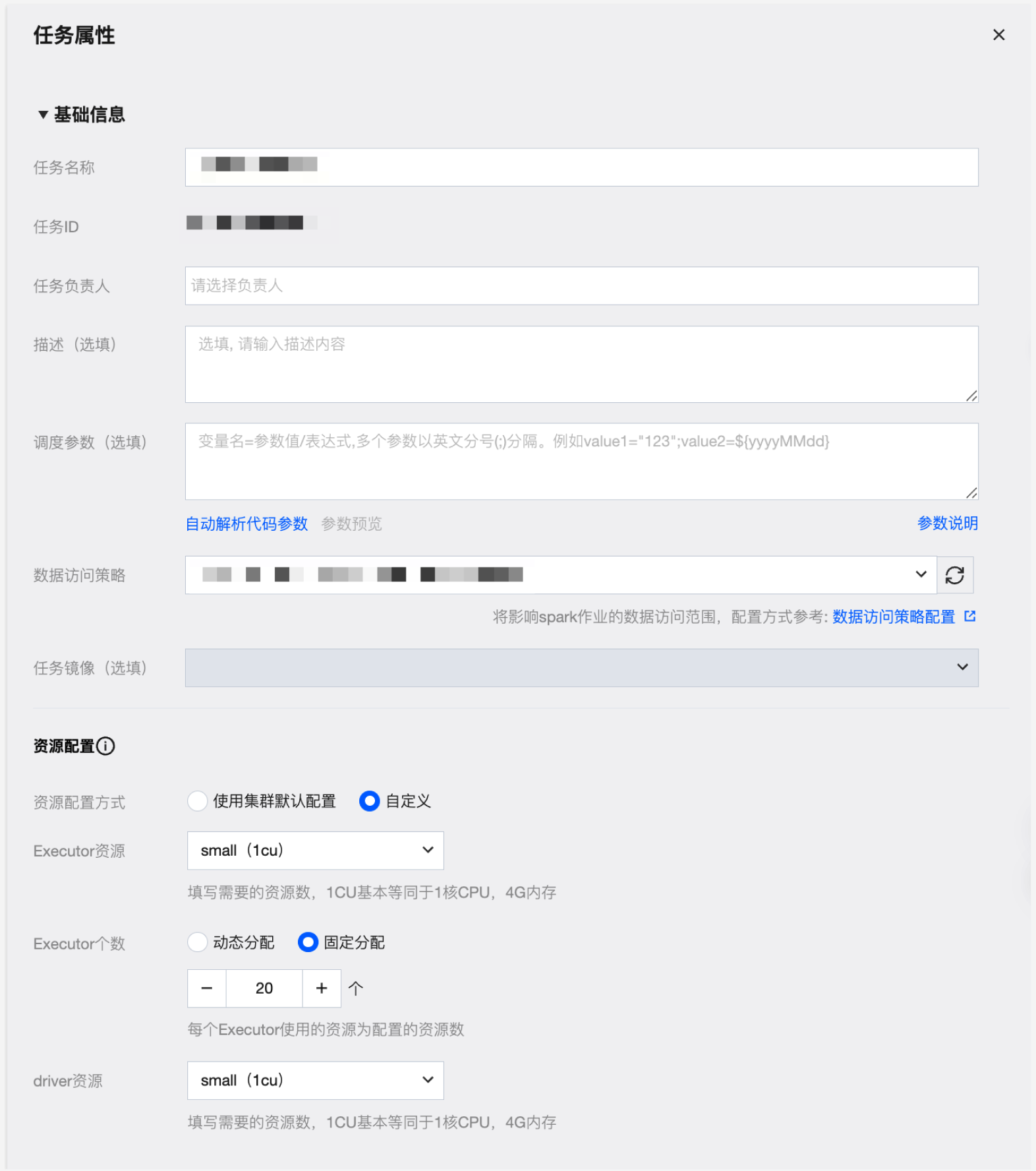
关键配置项说明:
关键配置项 | 关键配置项描述 |
任务镜像 | 任务执行的镜像,如果任务要使用特定的镜像可以选择 DLC 内置镜像和自定义镜像。 |
资源配置 | 资源配置方式 分为集群默认配置与自定义配置两种方式: 1. 使用集群默认配置 使用当前任务计算资源集群配置 2. 自定义 用户自定义 Executor、Driver 配置 Executor 资源 填写需要的资源数,1cu 基本等同于1核 CPU,4G 内存。 1. Small:单个计算单位 (1cu) 2. Medium:两个计算单位 (2cu) 3. Large:四个计算单位 (4cu) 4. Xlarge:八个计算单位 (8cu) 5. 4Xlarge:十六个计算单位(16cu) Executor 个数 Executor 负责执行任务和处理计算工作的计算节点或计算实例,每个 Executor 使用的资源为配置的资源数,支持动态分配和固定分配。 Driver 资源 填写需要的 Driver 资源数,1cu 基本等同于1核 CPU,4G 内存 1. Small(小型):单个计算单位 (1cu) 2. Medium(中型):两个计算单位 (2cu) 3. Large(大型):四个计算单位 (4cu) 4. Xlarge(超大型):八个计算单位 (8cu) 5. 4Xlarge:十六个计算单位(16cu) |
任务节点配置限制
1. DLC Spark Streaming 节点不支持建立上下游依赖关系,不支持离线和实时混合编排,建议 DLC Spark Streaming 节点单独建立工作流维护。
2. DLC Spark Streaming 节点只支持在周期工作流中创建和配置,不支持在手动工作流中创建和配置。



