从问题开始:分布式数据库为什么需要分区?
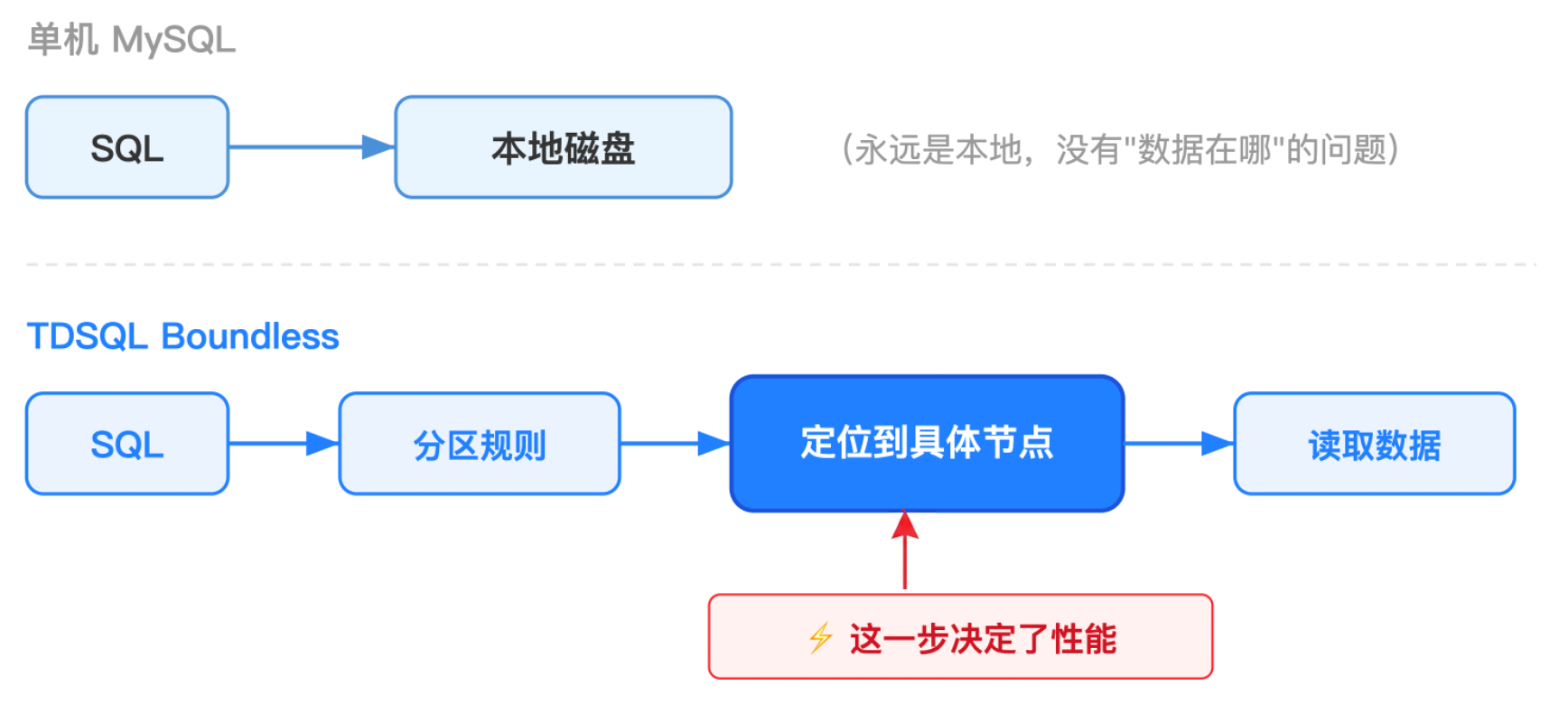
单机 MySQL 所有数据都在一台机器上,任何 SQL 直接访问本地磁盘,没有"数据在哪"的问题。但当数据量超过单机极限,我们需要把数据分散到多个节点,这就是分布式数据库的核心命题。问题随之而来:一条 SQL 进来,数据库怎么知道该去哪台机器找数据?答案就是分区。分区定义了一套规则,告诉数据库在写入时这条数据该放到哪个节点,查询时这条 SQL 该去哪个节点找数据。
分区解决的三个核心问题
核心问题 | 没有分区会怎么样 | 分区怎么解决问题 |
数据在哪里? | 所有数据堆积在一个节点,其他节点空闲 | 按照规则均匀分散到所有节点 |
查询去哪里找? | 每条 SQL 都要问所有节点 | 带分区键的查询直接定位到单个节点 |
怎么消除热点? | 新数据集中写入一个节点 | HASH 打散,写入均衡分布 |
一句话总结:分区等于数据的地址规则。选对了,一条 SQL 只访问一个节点;选错了,每条 SQL 都要问所有节点。
TDSQL Boundless 的数据组织方式
先理解数据组织方式,才能理解分区的意义:
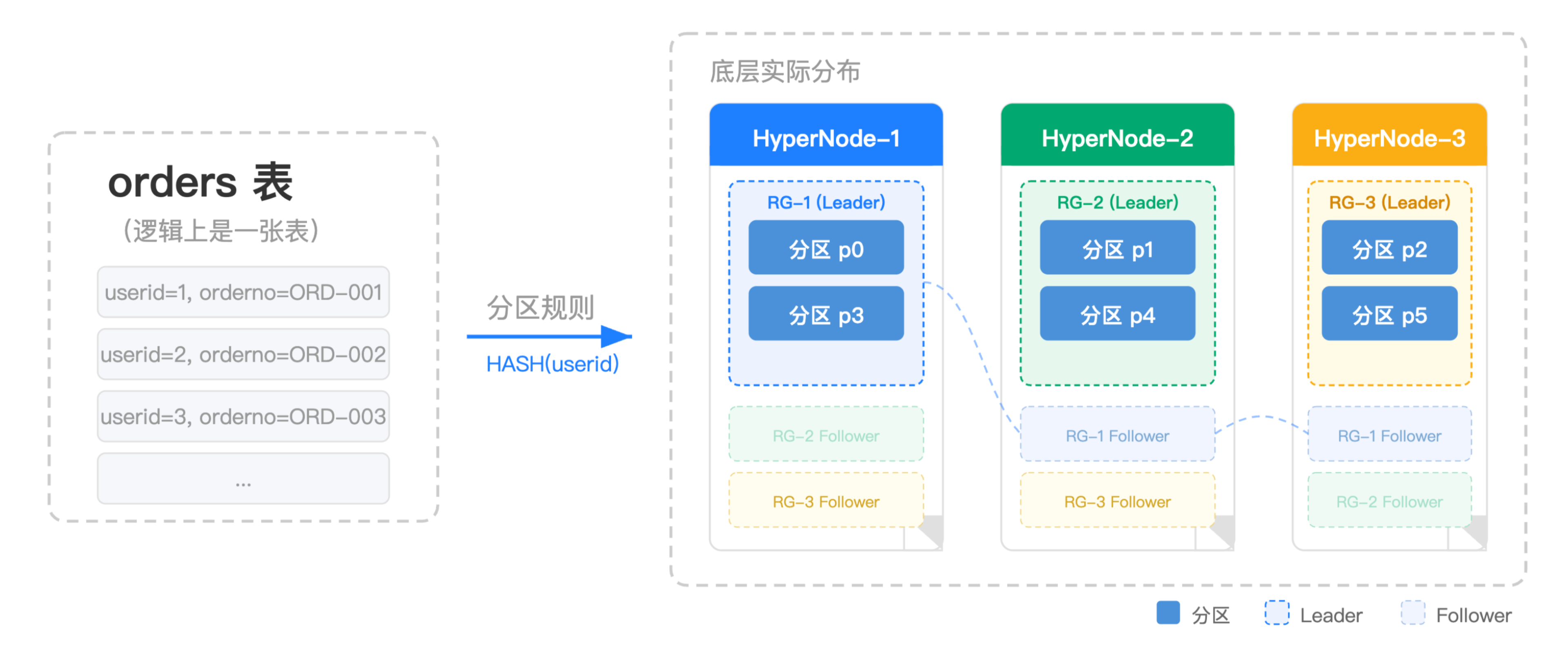
分区:用户定义的数据划分规则,例如,按照 userid 取模。
复制组(Replication Group, RG):数据复制与调度的基本单位,基于 Raft 协议,一个复制组可包含多个分区。
对等节点(HyperNode):一个对等节点上可承载多个复制组。
分区决定数据如何分布,复制组(Replication Group, RG)是底层的调度载体,两者通过 TDSQL Boundless 的智能调度自动映射。
三条铁律
铁律一:分区键必须在主键里
说明:
全局二级索引(Global Secondary Index)是独立于基表分区键的新索引,从而实现按非主键列快速查询、减少全表扫描,并提供全局唯一约束。全局二级索引不能替代主键,TDSQL Boundless 的主键仍需要包含分区键。
因为主键的唯一性检查是在各个分区内部进行的,如果主键不包含全部分区键,这个检查就会失效。为了保证主键/唯一索引的唯一性,强制建表时确保分区键一定在主键里,不满足会直接报错:
-- ❌ 报错:A PRIMARY KEY must include all columns in the table's partitioning functionCREATE TABLE users (id BIGINT PRIMARY KEY,userid BIGINT) PARTITION BY HASH(userid) PARTITIONS 16;-- ✅ 正确:主键包含分区键CREATE TABLE users (id BIGINT AUTO_INCREMENT,userid BIGINT NOT NULL,PRIMARY KEY (userid)) PARTITION BY HASH(userid) PARTITIONS 16;
铁律二:不推荐对单调递增列仅按 RANGE 分区,需要结合 RANGE 分区与 HASH 分区
自增 ID、时间戳等单调递增字段,不适合用它直接做 RANGE 分区键,所有新写入的数据会集中在最后一个分区对应的节点上——一个节点承受所有写入压力,形成写入热点。如果需要 RANGE 分区(例如,按照时间归档清理),适合配合 HASH 二级分区打散写入:
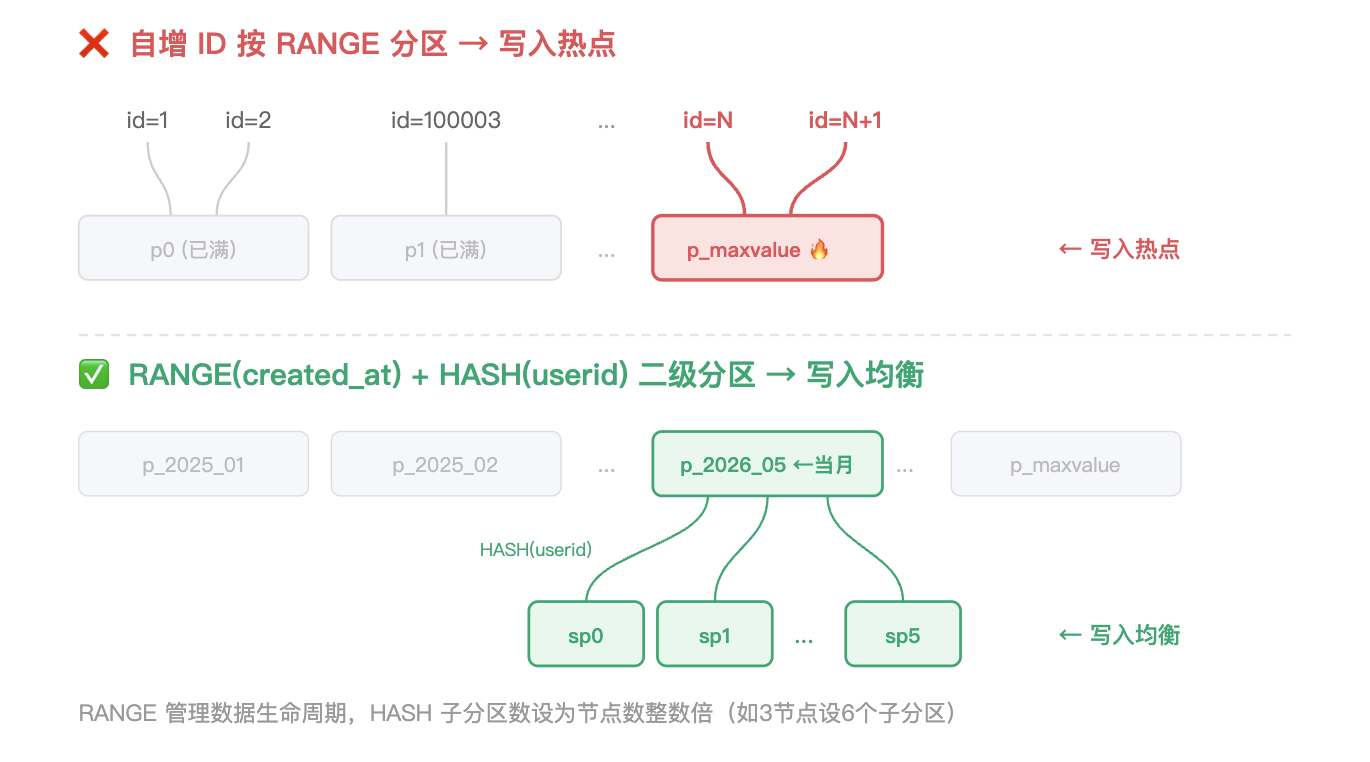
-- ❌ 写入热点:新数据永远写入最后一个分区CREATE TABLE t (id BIGINT AUTO_INCREMENT,...PRIMARY KEY (id)) PARTITION BY RANGE(id) (PARTITION p0 VALUES LESS THAN (100000),PARTITION p1 VALUES LESS THAN (200000),PARTITION p_maxvalue VALUES LESS THAN MAXVALUE -- 所有新数据都在这里);-- ✅ RANGE 按时间管理生命周期 + HASH 打散写入CREATE TABLE t (id BIGINT AUTO_INCREMENT,...PRIMARY KEY (id)) PARTITION BY RANGE COLUMNS(created_at)SUBPARTITION BY HASH(userid) SUBPARTITIONS 6 (...);
铁律三:查询必带分区键或添加全局二级索引
注意:
为什么? 不带分区键,数据库无法知道数据在哪个节点,只能广播到所有节点——这就是"全分区扫描",性能大概率随节点数增加而下降。
-- ✅ 只访问1个节点,毫秒级返回SELECT * FROM orders WHERE userid = 12345;-- ❌ 访问所有节点,每个节点都要查一遍SELECT * FROM orders WHERE orderno = 'ORD-001';
怎么选分区类型?
说明:
TDSQL Boundless 兼容 MySQL 8.0 的分区语法,支持一级分区和二级分区(子分区,又叫复合分区)。二级分区在一级分区的基础上,对每个一级分区再次细分。二级分区仅支持 HASH 和 KEY 两种类型。
简单来说,回答两个问题:
问题1: 需要定期删除历史数据吗?(如日志按月清理)
→ 是:用 RANGE 分区(按时间划分,到期直接 DROP PARTITION)
→ 否:进入问题2
问题2: 分区键是什么类型?
→ 整数(INT/BIGINT):用 HASH 分区
→ 字符串(VARCHAR):用 KEY 分区
实际业务中,用 HASH 分区能解决大部分问题。
常见分区类型速查
类型 | 原理 | 适用场景 | 示例 |
HASH | 对整数取模均匀打散 | 用户表、订单表、通用业务表 | PARTITION BY HASH(userid) |
KEY | 对任意类型内部 HASH 打散 | 分区键是 VARCHAR 的场景 | PARTITION BY KEY(orderno) |
RANGE | 按值的范围划分 | 日志表、流水表、需要按时间清理的表 | PARTITION BY RANGE COLUMNS(created_at) |
RANGE + HASH | 一级按范围,二级再打散 | 大流水表:既要按时间清理,又要打散写入 | |
分区数设置多少?
说明:
推荐创建分区表时设置分区数 = 预期最大节点数 × 2,建议设置为200以内较为合适。
分区数设置少了,扩容后部分节点分不到数据,资源浪费;分区数设置过多,每个分区的数据量太小,管理开销增大。因此,一般推荐为实例预期最大节点数的2倍即可。
当前节点数 | 预期扩容后的节点数 | 推荐分区数 |
3节点 | 6 ~ 8 | 16 |
6节点 | 12 | 24 |
不带分区键的普通 LOCAL 索引会怎样?
这是客户最常问的问题之一:
CREATE TABLE orders (...KEY idx_order_no (orderno) -- 不含分区键 userid 的 LOCAL 索引) PARTITION BY HASH(userid) PARTITIONS 16;
当查询只用 orderno 没有 userid 时:
SELECT * FROM orders WHERE orderno = 'ORD-2026-001';
TDSQL Boundless 的执行过程:
1. 数据库不知道这条数据在哪个分区
2. 只能向所有16个分区发起索引查找
3. 每个分区内部根据 idx_order_no 索引查找
4. 15个分区未命中,1个分区命中
5. 汇总返回
结论:LOCAL 索引不是不能用,但要理解代价。
查询方式 | 访问分区数 | 网络 RPC | 适合场景 |
WHERE userid = X | 1 | 1次 | 高频查询 |
WHERE orderno = X(LOCAL 索引) | 全部 | N 次 | 低频查询、结果集小 |
WHERE orderno = X(全局二级索引) | 1 | 1 次 | ✅ 高频非分区键查询 |
无索引全表扫描 | 全部 | N 次 | ❌ 永远不要 |
优化方案:
1. 最优方案:高频查询带分区键。
-- 从这样SELECT * FROM orders WHERE orderno = 'ORD-001';-- 改成这样(如果业务能拿到 userid)SELECT * FROM orders WHERE userid = 123 AND orderno = 'ORD-001';
2. 次优方案:高频查询且无法带分区键时,添加为全局二级索引(Global Secondary Index),查询时避免全分区扫描。
注意:
-- 订单号 orderno 使用普通 Local 索引时,需要全分区扫描ALTER TABLE orders ADD INDEX idx_local_order_no (orderno);EXPLAIN FORMAT=TREE SELECT * FROM orders WHERE orderno = 'ORD-001';+----------------------------------------------------------------------------------------------+| EXPLAIN |+----------------------------------------------------------------------------------------------+| -> Index lookup on orders using idx_local_order_no (orderno='ORD-001') (cost=5.94 rows=16)|+----------------------------------------------------------------------------------------------+-- 订单号 orderno 添加全局二级索引后,可直接命中索引数据进行回表,不会直接扫描全部分区ALTER TABLE orders ADD INDEX idx_global_order_no (orderno) GLOBAL;EXPLAIN FORMAT=TREE SELECT * FROM orders WHERE orderno = 'ORD-001';+----------------------------------------------------------------------------------------------+| EXPLAIN |+----------------------------------------------------------------------------------------------+| -> Index lookup on orders using idx_global_order_no (orderno='ORD-001') (cost=0.35 rows=1)|+----------------------------------------------------------------------------------------------+
从 MySQL 迁移过来怎么改?
第一步:给每张表选分区键
这是迁移中最重要的决策。核心原则:看哪个维度的"列表查询"最高频,就按哪个维度分区,其他维度用索引兜底。
以订单表为例,userid 和 orderno 都是高频查询字段,怎么选?
| 按 user_id 分区 | 按 order_no 分区 |
查用户订单列表 | ✅ 单分区,天然聚合 | ❌ 散落在各分区 |
按单号查一笔 | LOCAL 索引,扇出所有分区(但每个分区最多1行,可接受) | ✅ 单分区 |
写入均匀性 | ✅ userid 整数,HASH 散列效果好 | ⚠️ orderno 常含日期前缀,散列可能不均 |
分区类型 | HASH(整数) | KEY(字符串,HASH 不支持 VARCHAR) |
绝大多数订单表应该按 userid 分区,因为:
最高频查询是"某用户的所有订单"
按 orderno 查单笔可以用索引兜底,orderno 是全局唯一的,即使出现全分区扫描,每个分区最多命中1行,开销可控;或者添加全局二级索引。
userid 一般情况下是整数,HASH 散列效果最好
说明:
第二步:改造表结构
单机 MySQL | TDSQL Boundless | 为什么改 |
id BIGINT AUTO_INCREMENT PRIMARY KEY | 不再依赖自增 ID,业务键做主键 | 避免写入热点 |
没有分区 | 加 PARTITION BY HASH(业务键1, 业务键2) | 数据打散到多节点 |
DELETE WHERE date < '...' 清理历史 | 改用 DROP PARTITION | 毫秒完成 vs 锁表几小时 |
随便建索引 | 核心查询的索引要包含分区键 | 避免全分区扫描 |
改造对比:
-- 订单表, 改造前( MySQL)CREATE TABLE orders (id BIGINT AUTO_INCREMENT PRIMARY KEY,userid BIGINT,orderno VARCHAR(64),amount DECIMAL(10,2),status TINYINT,created_at DATETIME,KEY idx_order_no (orderno),KEY idx_created (created_at));-- 订单表, 改造后(TDSQL Boundless)CREATE TABLE orders (id BIGINT AUTO_INCREMENT,userid BIGINT NOT NULL,orderno VARCHAR(64) NOT NULL,amount DECIMAL(10,2),status TINYINT,created_at DATETIME DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (userid, orderno), -- 分区键在主键第一位KEY idx_auto_id (id), -- 为自增键添加索引KEY idx_order_no (orderno), -- 单号索引解决根据订单号的检索操作KEY idx_user_created (userid, created_at) -- 用户订单列表查询) PARTITION BY HASH(userid) PARTITIONS 16;
-- 订单表, 改造前( MySQL)CREATE TABLE orders (id BIGINT AUTO_INCREMENT PRIMARY KEY,userid BIGINT,orderno VARCHAR(64),amount DECIMAL(10,2),status TINYINT,created_at DATETIME,KEY idx_order_no (orderno),KEY idx_created (created_at));-- 订单表, 改造后(TDSQL Boundless)CREATE TABLE orders (id BIGINT AUTO_INCREMENT,userid BIGINT NOT NULL,orderno VARCHAR(64) NOT NULL,amount DECIMAL(10,2),status TINYINT,created_at DATETIME DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (userid, orderno), -- 分区键在主键第一位KEY idx_auto_id (id) GLOBAL, -- 为自增键添加索引KEY idx_global_order_no (orderno) GLOBAL, -- 单号索引解决根据订单号的检索操作KEY idx_user_created (userid, created_at) -- 用户订单列表查询) PARTITION BY HASH(userid) PARTITIONS 16;
第三步:改造查询语句
场景1: 用户订单列表,不管是按照创建时间 created_at 排序,还是按照订单号 orderno 排序,都不用修改,天然命中分区:
-- ✅ 不用改,天然命中分区SELECT * FROM orders WHERE userid = 123 ORDER BY created_at DESC LIMIT 20;SELECT * FROM orders WHERE userid = 123 ORDER BY orderno DESC LIMIT 20;
场景2: 按订单号查一笔,最优场景是能补充上用户 userid,如果不能拿到 userid 作为查询条件,那也没有问题:
-- 最优场景,带上用户 userid 查询订单号SELECT * FROM orders WHERE userid = 123 AND orderno = 'ORD-001';-- 次优场景,添加全局二级索引ALTER TABLE orders ADD INDEX idx_global_order_no (orderno) GLOBAL;SELECT * FROM orders WHERE orderno = 'ORD-001';-- 可接受(LOCAL 索引,16次索引查找)ALTER TABLE orders ADD INDEX idx_local_order_no (orderno);SELECT * FROM orders WHERE orderno = 'ORD-001';
第四步(可选):高频 orderno 查询的进一步优化
如果按订单号 orderno 查询频率非常高且对延迟敏感,可以在应用层引入 KV 缓存映射,例如 Redis 等。
同步表:频繁被 JOIN 的小表怎么办?
分区表的 JOIN 可能跨节点,产生网络开销。对于字典表、配置表这类读多写少的小表,用同步表:
CREATE TABLE dim_city (city_id INT PRIMARY KEY,city_name VARCHAR(64)) sync_level = node(all) distribution = node(all);
同步表在每个节点都有完整副本,JOIN 时数据就在本地,零网络开销。
说明:
TDSQL Boundless 支持的表类型如下:
表类型 | 适用场景 | 特点 |
普通表(单表) | 数据量小、无分布需求 | 所有数据在一个复制组内 |
分区表 | 大数据量、需水平扩展 | 数据按规则分布到多个服务组内 |
同步表 | 系统配置、维度表、参数表、读多写少小表 | 全节点强同步副本,若频繁写入可能出现写入卡顿,如 Follower 故障时卡一个 Lease |
验证你的分区设计是否正确
执行 EXPLAIN 语句查看执行计划:
-- 带分区键EXPLAIN SELECT * FROM orders WHERE userid = 12345;*************************** 1. row ***************************id: 1select_type: SIMPLEtable: orderspartitions: p1type: refpossible_keys: PRIMARYkey: PRIMARYkey_len: 8ref: constrows: 2filtered: 100.00Extra: NULL-- 不带分区键EXPLAIN SELECT * FROM orders WHERE orderno = 'ORD-001';*************************** 1. row ***************************id: 1select_type: SIMPLEtable: orderspartitions: p0,p1,p2,p3,p4,p5,p6,p7type: refpossible_keys: idx_order_nokey: idx_order_nokey_len: 258ref: constrows: 9filtered: 100.00Extra: NULL
显式指定分区查询
除了通过 WHERE 分区键 让数据库自动裁剪分区,TDSQL Boundless 完整支持 MySQL 8.0 的显式分区选择语法——直接在 FROM 后用 PARTITION (p_name) 指定要访问的分区,无需带分区键也能实现分区裁剪。
-- 单个分区SELECT * FROM orders PARTITION (p1);-- 多个分区SELECT * FROM orders PARTITION (p0, p2, p5);-- 配合 WHERE 条件(取交集,不是 union)SELECT * FROM orders PARTITION (p1) WHERE status = 1;-- DML 同样支持DELETE FROM orders PARTITION (p_2025_01) WHERE created_at < '2025-01-15';UPDATE orders PARTITION (p3) SET status = 9 WHERE ...;INSERT INTO orders PARTITION (p0) (user_id, ...) VALUES (...);
常见误区
错误示例 | 错误影响 | 正确做法 |
自增 ID 做主键与分区键 | 写入热点 | 改用业务字段做分区键与主键;ORDER BY 排序时,改用业务时间或者其他天然有序的字段排序 |
查询不带分区键且没有命中 GLOBAL 索引 | 全分区扫描 | WHERE 条件补上分区键 |
VARCHAR 用 HASH 分区 | 建表报错 | 改用 KEY 分区 |
RANGE 按天分区保留多年 | 1000+ 分区,元数据膨胀 | 改为按月(36个分区/3年) |



