实现方案
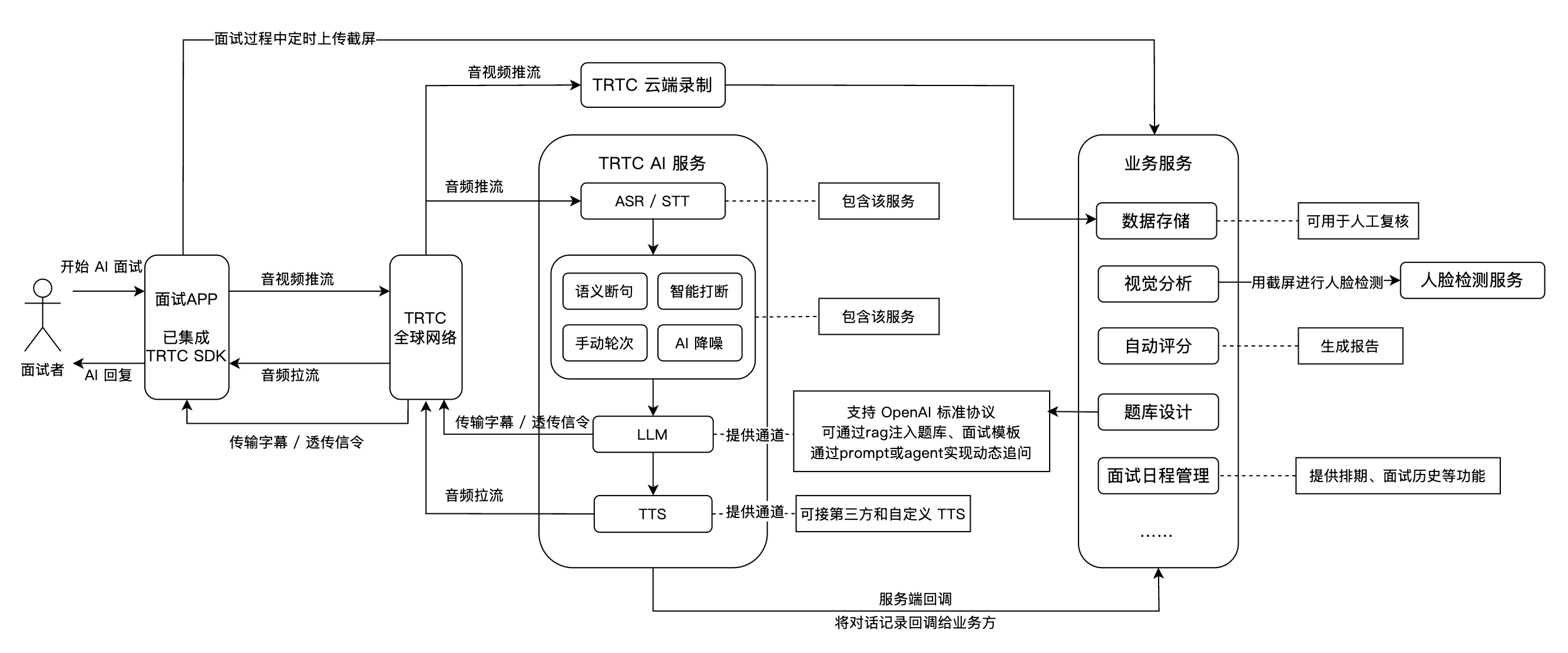
一个完整的 AI 面试场景一般包括:实时音视频、TRTC AI 实时对话、大语言模型 LLM、文字转语音 TTS、面试管理后台等关键模块。以下为各模块在 AI 面试场景下的功能和特色:
功能模块 | AI 面试场景应用 |
实时音视频 | 基于 TRTC 提供高质量、低延迟的音视频连线,支持720P/1080P/2K 高清画质和48kHz 高音质。无论网络环境如何,均能保障流畅互动,模拟真实面试场景。 |
TRTC AI 实时对话 | 腾讯 AI 实时对话解决方案,支持客户灵活接入多家 AI 大模型服务,实现 AI 与用户之间的实时音视频互动,打造符合业务场景的 AI 实时对话能力。基于腾讯 RTC 全球低延迟传输,对话效果自然拟真,接入便捷,开箱即用。 |
大语言模型 LLM | 智能理解候选人的语音内容和语境,精准提炼应答要点,动态生成后续面试问题,实现个性化和结构化的面试流程。LLM 技术还可根据不同岗位算法自动调整评分标准,提高评测的公平性与准确性。 |
文字转语音 TTS | 支持接入第三方 TTS,支持多种语言和语音风格输出,AI 面试官可通过 TTS 技术展现不同语气、性格,最大程度模拟真人面试官,提升候选人体验。 |
即时通信 IM | 通过 IM SDK 完成关键业务信令的透传。 |
面试管理后台 | 包含题库与面试设计、自动评分、数据存储、视觉分析、面试日程管理等能力。 |
技术架构
以下针对 AI 面试接入的主要流程进行介绍。
接入准备
准备 LLM
TRTC AI 实时对话支持任何符合 OpenAI 标准协议的 LLM 模型,也支持腾讯云智能体开发平台、Dify、Coze 等 LLM 应用开发平台,具体支持的平台可参见 LLMConfig 配置说明。
准备 TTS
使用腾讯云 TTS:
您需要 开通应用的 TTS 服务 以使用 TTS 语音合成功能。您可以点击 免费领取语音合成资源包。
APPID 可前往 账号信息 获取。
SecretId 和 SecretKey 可前往 API 密钥管理 获取,SecretKey 仅支持在创建密钥时查看,请及时保存。
可前往 音色列表 获取可调整的音色。
使用第三方或自定义 TTS:目前支持的 TTS 文字转语音配置(TTSConfig)。
准备 TRTC
注意:
1. 创建 TRTC 应用。
2. 开通 语音转文字 服务。
接入步骤
业务流程图
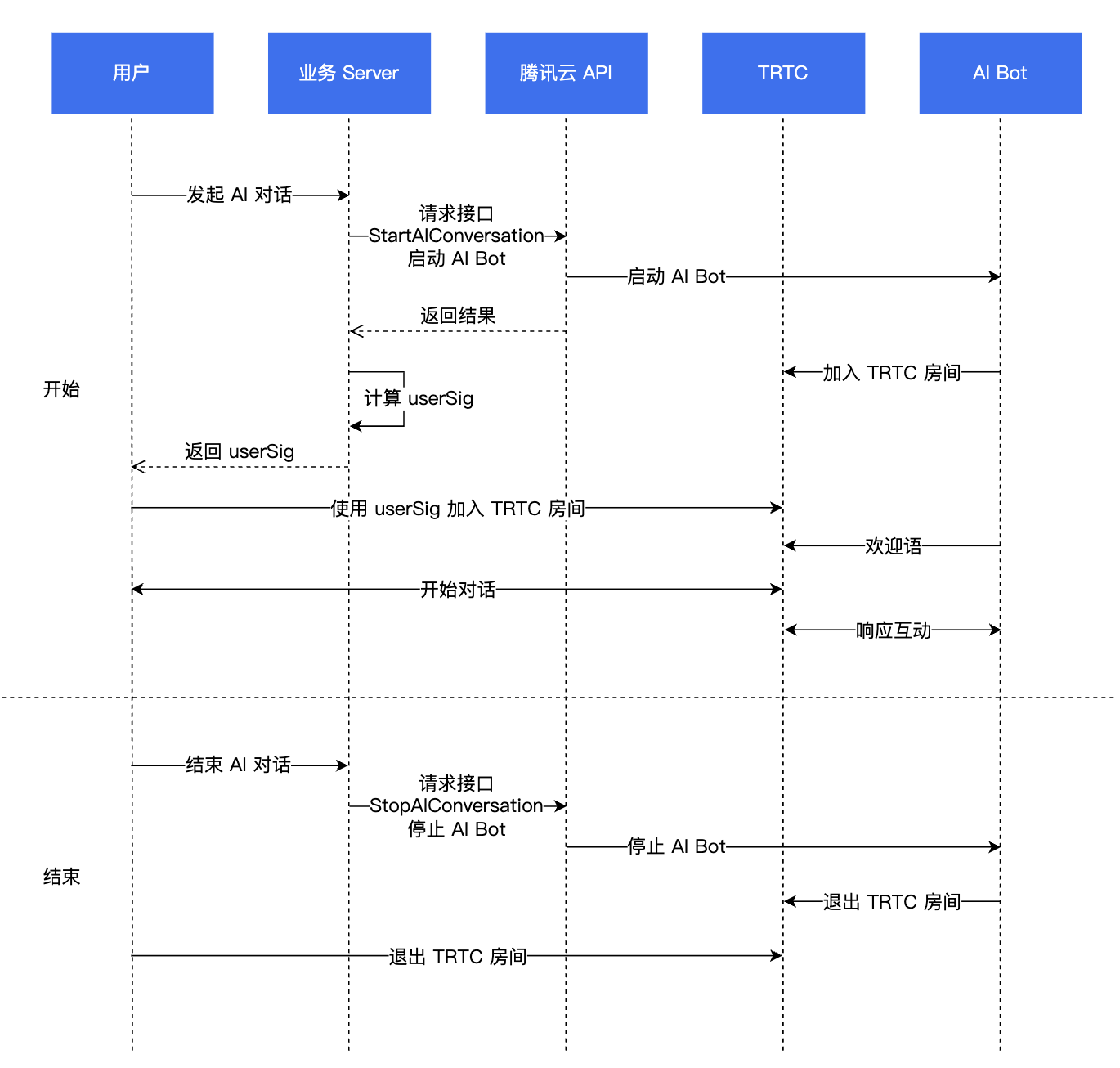
步骤1:集成 TRTC SDK
步骤2:进入 TRTC 房间
AI 面试场景推荐使用
TRTCAppSceneAudioCall 进房。步骤3:发布音频流
您可以调用 startLocalAudio 来开启麦克风采集,该接口需要您通过 quality 参数确定采集模式。虽然这个参数的名字叫做 quality,但并不是说质量越高越好,不同的业务场景有最适合的参数选择(这个参数更准确的含义是 scene)。
AI 对话场景下推荐使用 SPEECH 模式,该模式下的 SDK 音频模块会专注于提炼语音信号,最大限度地过滤周围的环境噪音,同时该模式下的音频数据也会获得较好的差质量网络的抵抗能力,因此该模式特别适合于“视频通话”和“在线会议”等侧重于语音沟通的场景。
// 开启麦克风采集,并设置当前场景为:语音模式(高噪声抑制能力、强弱网络抗性)trtcCloud.startLocalAudio(TRTCCloudDef.TRTC_AUDIO_QUALITY_SPEECH );
self.trtcCloud = [TRTCCloud sharedInstance];// 开启麦克风采集,并设置当前场景为:语音模式(高噪声抑制能力、强弱网络抗性)[self.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
// 开启麦克风采集,并设置当前场景为:语音模式(高噪声抑制能力、强弱网络抗性)trtcCloud.startLocalAudio(TRTCAudioQuality.speech);
await trtc.startLocalAudio();
enterRoom(options) {this.setData({pusher: this.TRTC.enterRoom({sdkAppID: 1400xxxxx, // 您的腾讯云账号userID: 'trtc-user', //当前进房用户的userIDuserSig: 'xxxxxxx', // 您服务端生成的userSigroomID: 1234, // 您进房的房间号,enableMic: true, // 进房默认开启音频上行}),}, () => {this.TRTC.getPusherInstance().start() // 开始进行推流})},
// 开启麦克风采集,设置当前场景为:语音模式// 具有高的噪声抑制能力,有强有弱的网络阻力ITRTCCloud* trtcCloud = CRTCWindowsApp::GetInstance()->trtc_cloud_;trtcCloud->startLocalAudio(TRTCAudioQualitySpeech);
// 开启麦克风采集,设置当前场景为:语音模式// 具有高的噪声抑制能力,有强有弱的网络阻力AppDelegate *appDelegate = (AppDelegate *)[[NSApplication sharedApplication] delegate];[appDelegate.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
步骤4:发起 AI 对话
开始 AI 对话:StartAIConversation
通过业务后台调用 开始 AI 对话任务 接口,来发起 AI 实时对话,调用成功后,AI 机器人会进入 TRTC 房间。将 前提条件 中的 LLM 和 TTS 相关信息填入
LLMConfig 和 TTSConfig中。下面以 OpenAI 标准协议的 LLM 模型举例,介绍如何配置 LLMConfig。
配置说明
名称 | 类型 | 是否必填 | 描述 |
LLMType | String | 是 | 大模型类型,只要是符合 OpenAI API协议的大模型,都填写openai。 |
Model | String | 是 | 具体的模型名称,例如 gpt-4o、deepseek-chat。 |
APIKey | String | 是 | 大模型的 APIKey。 |
APIUrl | String | 是 | 大模型的 APIUrl。 |
Streaming | Boolean | 否 | 是否流式,默认为 false,建议填true。 |
SystemPrompt | String | 否 | 系统提示词。 |
Timeout | Float | 否 | 超时时间,取值范围 [1~50], 默认为 3 秒(单位:秒)。 |
History | Integer | 否 | 设置 LLM 的上下文轮次,默认值:0(不提供上下文管理),最大值:50(提供最近50轮的上下文管理)。 |
MaxTokens | Integer | 否 | 输出文本的最大 token 限制。 |
Temperature | Float | 否 | 采样温度。 |
TopP | Float | 否 | 采样的选择范围,控制输出 token 的多样性。 |
UserMessages | Object[] | 否 | 用户提示词。 |
MetaInfo | Object | 否 | 自定义参数,会放在请求的 body 中透传给大模型。 |
配置示例
"LLMConfig": {"LLMType": "openai","Model": "gpt-4o","APIKey": "api-key","APIUrl": "https://api.openai.com/v1/chat/completions","Streaming": true,"SystemPrompt": "你是一个个人助手","Timeout": 3.0,"History": 5,"MetaInfo": {},"MaxTokens": 4096,"Temperature": 0.8,"TopP": 0.8,"UserMessages": [{"Role": "user","Content": "content"},{"Role": "assistant","Content": "content"}]}
下面以腾讯 TTS 举例,介绍如何配置 TTSConfig。
{"TTSType": "tencent", // String TTS类型, 目前支持"tencent" 和 “minixmax”, 其他的厂商支持中"AppId": 您的应用ID, // Integer 必填"SecretId": "您的密钥ID", // String 必填"SecretKey": "您的密钥Key", // String 必填"VoiceType": 101001, // Integer 必填,音色 ID,包括标准音色与精品音色,精品音色拟真度更高,价格不同于标准音色,请参见语音合成计费概述。完整的音色 ID 列表请参见语音合成音色列表。"Speed": 1.25, // Integer 非必填,语速,范围:[-2,6],分别对应不同语速: -2: 代表0.6倍 -1: 代表0.8倍 0: 代表1.0倍(默认) 1: 代表1.2倍 2: 代表1.5倍 6: 代表2.5倍 如果需要更细化的语速,可以保留小数点后 2 位,例如0.5/1.25/2.81等。 参数值与实际语速转换,可参考 语速转换"Volume": 5, // Integer 非必填,音量大小,范围:[0,10],分别对应11个等级的音量,默认值为0,代表正常音量。"PrimaryLanguage": 1, // Integer 可选 主要语言 1-中文(默认) 2-英文 3-日文"FastVoiceType": "xxxx" // String 可选参数,快速声音复刻的参数"EmotionCategory":"angry",// String 非必填,控制合成音频的情感,仅支持多情感音色使用。取值: neutral(中性)、sad(悲伤)..."EmotionIntensity":150 //Integer 非必填,控制合成音频情感程度,取值范围为 [50,200],默认为 100;只有 EmotionCategory 不为空时生效。}
目前支持的
LLMConfig 和 TTSConfig 配置说明:注意:
RoomId 需要和客户端进房的 RoomId 保持一致,并且房间号的类型(数字房间号、字符串房间号)也必须相同(即机器人和用户需要在同一个房间)。TargetUserId 需要和客户端进房使用的 UserId 一致。LLMConfig 和 TTSConfig 均为 JSON 字符串,需要正确配置才能成功发起 AI 实时对话。步骤5:开始对话
此时,用户已经可以正常和 AI 客服进行对话。
步骤6:停止 AI 对话,退出 TRTC 房间
1. 服务端停止 AI 对话任务。通过业务后台调用 停止 AI 对话 接口,停止该对话任务。
2. 客户端退出 TRTC 房间,建议参见 退出房间。
高级功能
远场人声抑制
在与 AI 面试中,可能会出现 AI 将用户侧其他人声识别为用户说的话,进行回复。为了尽量避免此类情况的发生,我们需要用到远场人声抑制的能力。在调用 开始 AI 对话任务 接口时,可以将
STTConfig.VadLevel 设置为2或者3,有较好的远场人声抑制能力。对话延迟优化
TRTC AI 实时对话中,AI 回复的延迟主要由 LLM、TTS 的首包耗时,和 ASR 的 VadSilenceTime、TRTC 通道的时延组成。
TRTC 自研多重最优寻址算法,具有全网调度能力,端到端平均时延 < 300ms,相比 LLM 和 TTS 的首包耗时,TRTC 的时延非常小,开发者一般无需关心其延迟。
ASR 的耗时基本由 VadSilenceTime 决定,太高会增加对话的延迟,太低会让 ASR 断句间隔太短,用户说话时稍微停顿一下,就会被当成完整的话,送去请求 LLM。一般推荐将 VadSilenceTime 设置为500ms - 1000ms,然后打开 语义断句功能。
指标名称说明
状态代码 | 描述 |
asr_latency | ASR 延迟。注意:指标包含启动 AI 对话时 VadSilenceTime 所设置的时间。 |
llm_network_latency | LLM 请求的网络耗时。 |
llm_first_token | LLM 首 token 耗时,指标包含网络耗时。 |
tts_network_latency | TTS 请求的网络耗时。 |
tts_first_frame_latency | TTS 首帧耗时,指标包含网络耗时。 |
tts_discontinuity | TTS 未连续的次数,代表 TTS 流式请求播放完成之后,下一个请求还没有返回结果,通常是 TTS 延迟比较高导致。 |
interruption | 表示此轮对话被打断。 |
其中最重要的数据就是 llm_first_token(LLM 的首包耗时)和 tts_first_frame_latency(TTS 的首包耗时)。
llm_first_token
LLM 的首包耗时建议控制在2秒以内,越低越好。在语音对话场景中,推荐 LLM 使用流式返回(需要把 LLMConfig 的
Streaming 设为 true),可以极大降低延迟。不建议选用 DeepSeek-R1等思考型模型,此类 LLM 延迟太大,没办法应用在语音对话中。如果对对话延迟特别敏感,可以选用一些参数更小的模型,很多模型可以把首包耗时控制在500ms左右。此外,额外接入一些 Agent 或工作流平台,可能会导致首包耗时变高。单独使用 LLM + Prompt 的耗时普遍更低。
tts_first_frame_latency
大部分 TTS 的首包耗时一般在500ms - 1000ms左右,如果耗时特别高,可以更换音色或 TTS 提供商,以优化对话延迟体验。
接收 AI 对话字幕及 AI 状态
接收实时字幕
消息格式:
{"type": 10000, // 10000表示是下发的实时字幕"sender": "user_a", // 说话人的userid"receiver": [], // 接收者userid列表,该消息实际是在房间内广播"payload": {"text":"", // 语音识别出的文本"start_time":"00:00:01", // 这句话的开始时间"end_time":"00:00:02", // 这句话的结束时间"roundid": "xxxxx", // 唯一标识一轮对话"end": true // 如果为true,代表这是一句完整的话}}
接收机器人状态
消息格式:
{"type": 10001, // 机器人的状态"sender": "user_a", // 发送者userid,这里是机器人的id"receiver": [], // 接受者userid列表,该消息实际是在房间内广播"payload": {"roundid": "xxx", // 唯一标识一轮对话"timestamp": 123,"state": 1, // 1 聆听中 2 思考中 3 说话中 4 被打断 5 说完话}}
示例代码
@Overridepublic void onRecvCustomCmdMsg(String userId, int cmdID, int seq, byte[] message) {String data = new String(message, StandardCharsets.UTF_8);try {JSONObject jsonData = new JSONObject(data);Log.i(TAG, String.format("receive custom msg from %s cmdId: %d seq: %d data: %s", userId, cmdID, seq, data));} catch (JSONException e) {Log.e(TAG, "onRecvCustomCmdMsg err");throw new RuntimeException(e);}}
func onRecvCustomCmdMsgUserId(_ userId: String, cmdID: Int, seq: UInt32, message: Data) {if cmdID == 1 {do {if let jsonObject = try JSONSerialization.jsonObject(with: message, options: []) as? [String: Any] {print("Dictionary: \\(jsonObject)")} else {print("The data is not a dictionary.")}} catch {print("Error parsing JSON: \\(error)")}}}
trtcClient.on(TRTC.EVENT.CUSTOM_MESSAGE, (event) => {let data = new TextDecoder().decode(event.data);let jsonData = JSON.parse(data);console.log(`receive custom msg from ${event.userId} cmdId: ${event.cmdId} seq: ${event.seq} data: ${data}`);if (jsonData.type == 10000 && jsonData.payload.end == false) {// 字幕中间状态} else if (jsonData.type == 10000 && jsonData.payload.end == true) {// 一句话说完了}});
void onRecvCustomCmdMsg(const char* userId, int cmdID, int seq,const uint8_t* message, uint32_t msgLen) {std::string data;if (message != nullptr && msgLen > 0) {data.assign(reinterpret_cast<const char*>(message), msgLen);}if (cmdID == 1) {try {auto j = nlohmann::json::parse(data);std::cout << "Dictionary: " << j.dump() << std::endl;} catch (const std::exception& e) {std::cerr << "Error parsing JSON: " << e.what() << std::endl;}return;}}
void onRecvCustomCmdMsg(String userId, int cmdID, int seq, String message) {if (cmdID == 1) {try {final decoded = json.decode(message);if (decoded is Map<String, dynamic>) {print('Dictionary: $decoded');} else {print('The data is not a dictionary. Raw: $decoded');}} catch (e) {print('Error parsing JSON: $e');}return;}}
代理 LLM
TRTC AI 对话服务支持标准的 OpenAI 规范,这使得开发者能够在自己的业务中实现定制化的 LLM。开发者可以在自己的业务后台实现与 OpenAI API 兼容的大模型接口,并将封装了上下文逻辑、RAG 的大模型请求发送给第三方大模型。实现流程如下:
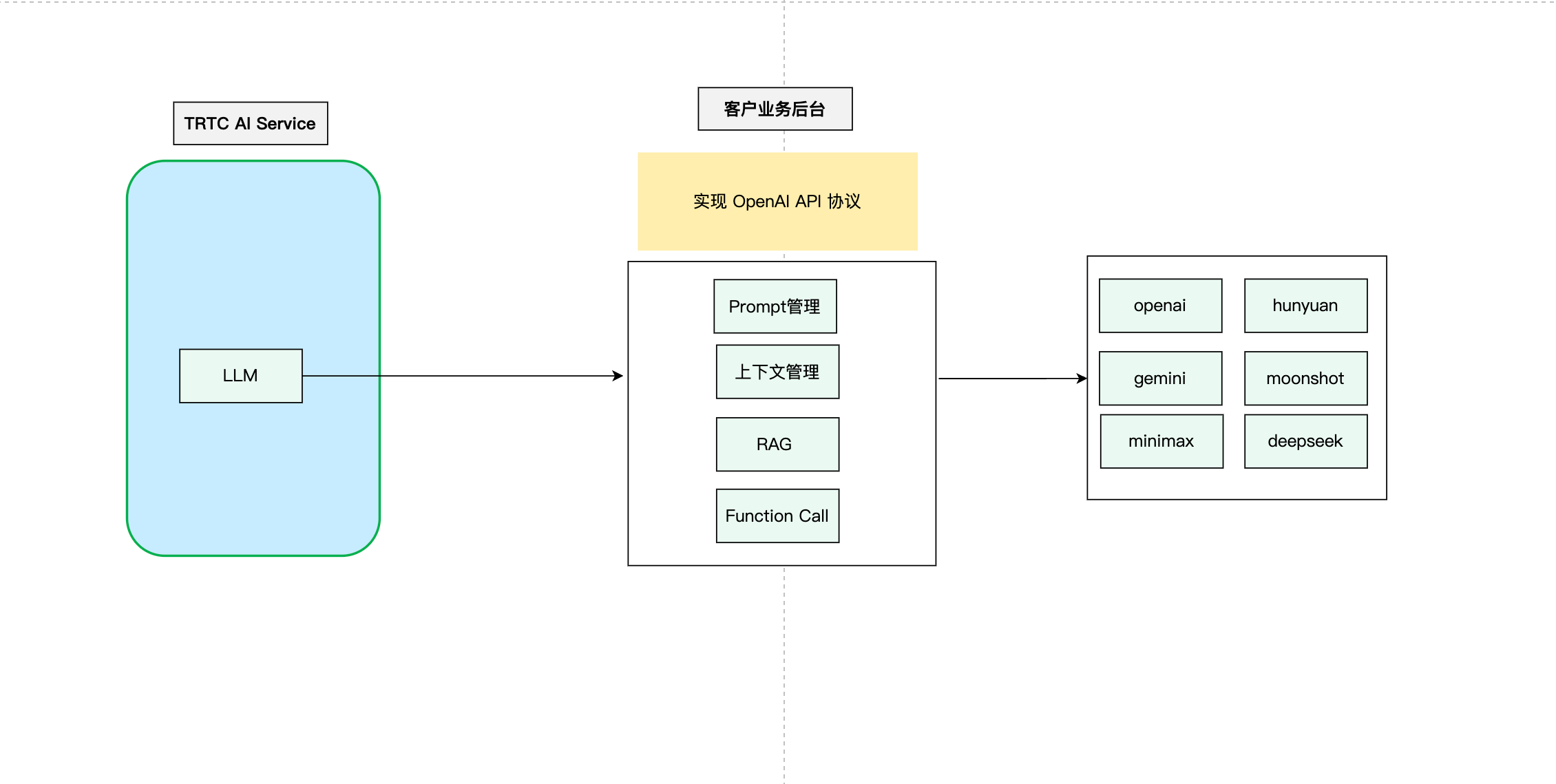
这个流程图展示了自定义上下文管理的基本步骤。开发者可以根据自己的具体需求对这个流程进行调整和优化。
代码示例
import timefrom fastapi import FastAPI, HTTPExceptionfrom fastapi.middleware.cors import CORSMiddlewarefrom pydantic import BaseModelfrom typing import List, Optionalfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIapp = FastAPI(debug=True)# 添加 CORS 中间件app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)class Message(BaseModel):role: strcontent: strclass ChatRequest(BaseModel):model: strmessages: List[Message]temperature: Optional[float] = 0.7class ChatResponse(BaseModel):id: strobject: strcreated: intmodel: strchoices: List[dict]usage: dict@app.post("/v1/chat/completions")async def chat_completions(request: ChatRequest):try:# 将请求消息转换为 LangChain 消息格式langchain_messages = []for msg in request.messages:if msg.role == "system":langchain_messages.append(SystemMessage(content=msg.content))elif msg.role == "user":langchain_messages.append(HumanMessage(content=msg.content))# add more historys# 使用 LangChain 的 ChatOpenAI 模型chat = ChatOpenAI(temperature=request.temperature,model_name=request.model)response = chat(langchain_messages)print(response)# 构造符合 OpenAI API 格式的响应return ChatResponse(id="chatcmpl-" + "".join([str(ord(c))for c in response.content[:8]]),object="chat.completion",created=int(time.time()),model=request.model,choices=[{"index": 0,"message": {"role": "assistant","content": response.content},"finish_reason": "stop"}],usage={"prompt_tokens": -1, # LangChain 不提供这些信息,所以我们使用占位值"completion_tokens": -1,"total_tokens": -1})except Exception as e:raise HTTPException(status_code=500, detail=str(e))if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
通过 LLM 透传自定义信令
如需要大模型返回不参与 TTS 的内容,可在大模型返回内容中增加自定义字段
metainfo, TRTC AI 探测到 metainfo 后,通过 自定义消息 推送到客户端 SDK 上,完成 metainfo 的透传。大模型侧发送方式:在大模型流式返回
chat.completion.chunk 对象时,同时返回 meta.info 的 chunk。{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}// 增加如下自定义消息{"id":"chatcmpl-123","type":"meta.info","created":1694268190,"metainfo": {}}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
客户端侧接收方式:TRTC AI 检测到有
metainfo 之后,通过 TRTC SDK 的 自定义消息 进行下发。客户端可通过 SDK 回调中的 onRecvCustomCmdMsg 接口接收。{"type": 10002, // 自定义消息"sender": "user_a", // 发送者userid,这里是机器人的id"receiver": [], // 接受者userid列表,该消息实际是在房间内广播,"roundid": "xxxxxx","payload": {} // metainfo}
通过 IM 透传关键信令
服务端发送消息:
单发单聊消息
批量发单聊消息
客户端接收消息:
Flutter
避免 AI 面试官 “抢话”
使用手动轮次模式
可以将 启动 AI 对话接口 里的
AgentConfig.TurnDetectionMode 参数设置为 1,以打开手动轮次模式。此时客户端在收到字幕消息后,自行决定是否手动发送聊天信令触发一轮新的对话。参数说明
参数 | 类型 | 描述 |
TurnDetectionMode | Integer | 控制新一轮对话的触发方式,默认为0。 0表示当服务端语音识别检测出的完整一句话后,自动触发一轮新的对话。 1表示客户端在收到字幕消息后,自行决定是否手动发送聊天信令触发一轮新的对话。 示例值:0 |
聊天信令
{"type": 20000, // 端上发送自定义文本消息"sender": "user_a", // 发送者userid, 服务端会check该userid是否有效"receiver": ["user_bot"], // 接受者userid列表,只需要填写机器人userid,服务端会check该userid是否有效"payload": {"id": "uuid", // 消息id,可以使用uuid,排查问题使用"message": "xxx", // 消息内容"timestamp": 123 // 时间戳,排查问题使用}}
示例代码
public void sendMessage() {try {int cmdID = 0x2;long time = System.currentTimeMillis();String timeStamp = String.valueOf(time/1000);JSONObject payLoadContent = new JSONObject();payLoadContent.put("timestamp", timeStamp);payLoadContent.put("message", message);payLoadContent.put("id", String.valueOf(GenerateTestUserSig.SDKAPPID) + "_" + mRoomId);String[] receivers = new String[]{robotUserId};JSONObject interruptContent = new JSONObject();interruptContent.put("type", 20000);interruptContent.put("sender", mUserId);interruptContent.put("receiver", new JSONArray(receivers));interruptContent.put("payload", payLoadContent);String interruptString = interruptContent.toString();byte[] data = interruptString.getBytes("UTF-8");Log.i(TAG, "sendInterruptCode :" + interruptString);mTRTCCloud.sendCustomCmdMsg(cmdID, data, true, true);} catch (UnsupportedEncodingException e) {e.printStackTrace();} catch (JSONException e) {throw new RuntimeException(e);}}
@objc func sendMessage() {let cmdId = 0x2let timestamp = Int(Date().timeIntervalSince1970 * 1000)let payload = ["id": userId + "_\\(roomId)" + "_\\(timestamp)", // 消息id,可以使用uuid,排查问题使用"timestamp": timestamp, // 时间戳,排查问题使用"message": "xxx" // 消息内容] as [String : Any]let dict = ["type": 20001,"sender": userId,"receiver": [botId],"payload": payload] as [String : Any]do {let jsonData = try JSONSerialization.data(withJSONObject: dict, options: [])self.trtcCloud.sendCustomCmdMsg(cmdId, data: jsonData, reliable: true, ordered: true)} catch {print("Error serializing dictionary to JSON: \\(error)")}}
const message = {"type": 20000,"sender": "user_a","receiver": ["user_bot"],"payload": {"id": "uuid","timestamp": 123,"message": "xxx", // 消息内容}};trtc.sendCustomMessage({cmdId: 2,data: new TextEncoder().encode(JSON.stringify(message)).buffer});
注意:
使用语义断句
对话语义断句是一种高级断句功能,通过结合传统声学信号和上下文语义分析来实现更精准的对话断句识别,有效解决传统方法中的限制,显著提升对话体验质量。
启用语义断句功能非常简单,只需在启动对话任务时进行适当配置。
// 在调用 StartAIConversation 接口时AgentConfig.TurnDetectionMode = 3
参数说明:TurnDetectionMode = 3表示启用语义断句模式。
灵敏度调节(可选)
当启用语义断句模式后,您可通过以下参数调整断句的灵敏度:
// 在调用 StartAIConversation 接口时AgentConfig.TurnDetection.SemanticEagerness = "low" | "medium" | "high" | "auto"
参数说明
参数 | 说明 |
auto | 默认设置,与 medium 级别相同,提供平衡的响应时机。 |
low | 保守模式,给予用户充分表达时间,等待更长的停顿才判定为语音结束。 |
medium | 均衡模式,在用户表达与系统响应间取得平衡。 |
high | 积极模式,更快速地对音频进行分块处理,实现更频繁的交互响应。 |
说明:
无论选择哪种灵敏度,系统最终都会将语音内容分段并传送给大模型进行处理和回复。
打断时延优化
如果觉得对话时打断 AI 说话的时延较高,可以通过将 启动 AI 对话接口 里的
AgentConfig.InterruptSpeechDuration 和 STTConfig.VadSilenceTime 参数设置低一点,以降低打断时延。建议同时打开 远场人声抑制 能力,以降低误打断的概率。参数说明
参数 | 类型 | 描述 |
AgentConfig.InterruptSpeechDuration | Integer | InterruptMode 为0时使用,单位为毫秒,默认为500ms。表示服务端检测到持续 InterruptSpeechDuration 毫秒的人声则进行打断。 示例值:500 |
STTConfig.VadSilenceTime | Integer | 语音识别 vad 的时间,范围为240 - 2000,默认为1000,单位为ms。更小的值会让语音识别分句更快。 示例值:500 |
服务端回调
云端录制
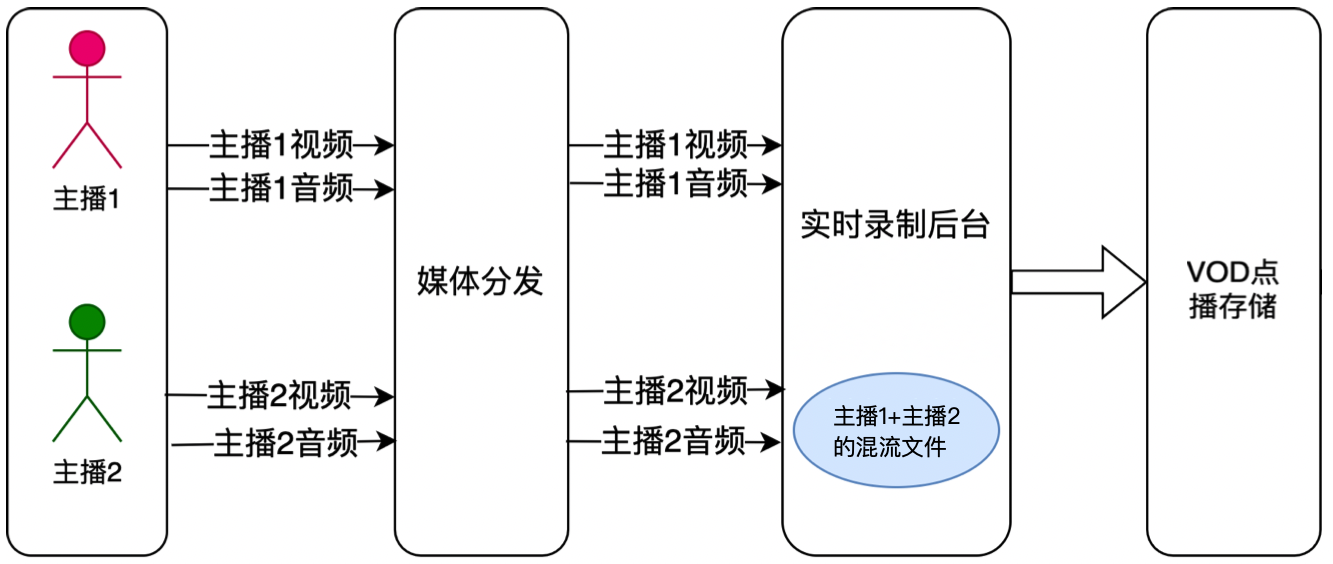
TRTC 最新升级的云端录制,不依赖云直播的能力,无需旁路转推云直播,使用 TRTC 内部的实时录制集群进行音视频录制,拥有更完整统一的录制体验。
单流录制:通过 TRTC 的云端录制功能,您可以将房间中通话双方的音视频流都录制成独立的文件。
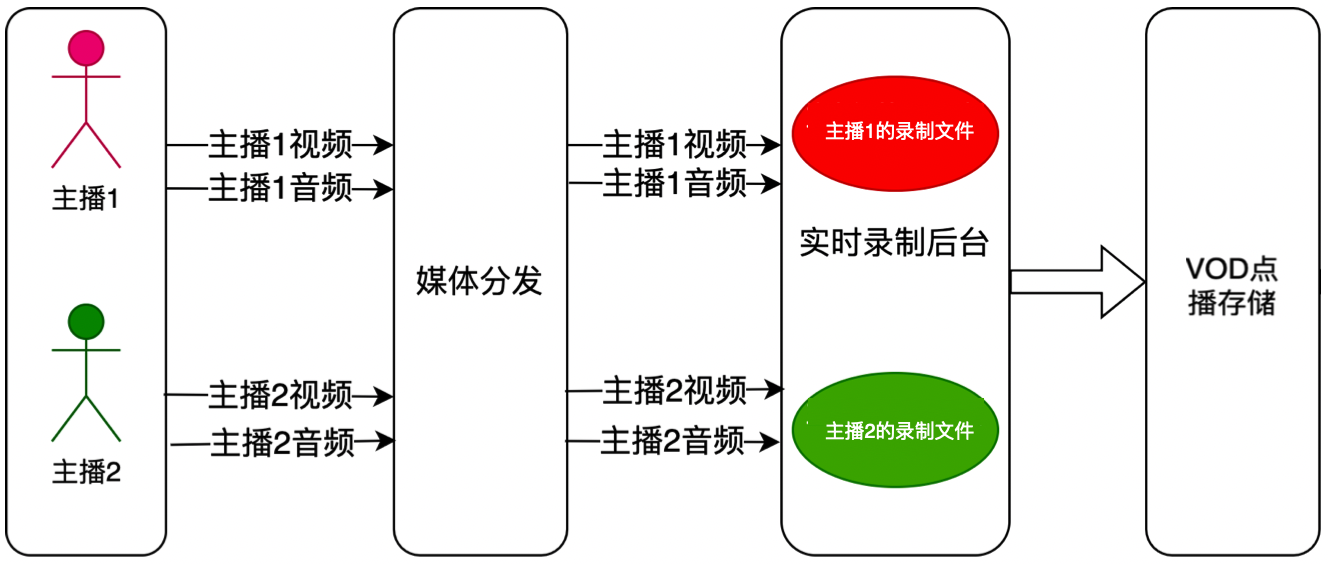
混流录制:将同一个房间中的所有音视频媒体流混流录制成一个文件。
常见问题
为什么机器人没有说话?
1. 检查客户端是否开启麦克风采集,并发布音频流。
2. 通过 TRTC SDK 接收自定义消息功能,检查是否可以接收到实时字幕与 AI 状态等数据。如果接收不到,建议检查在调用 StartAIConversation 接口时的
RoomId 是否和客户端进房的 RoomId 一致,并且房间号的类型(数字房间号、字符串房间号)也必须相同(即机器人和用户需要在同一个房间)。另外检查 TargetUserId 是否和客户端进房使用的 UserId 一致。3. 如果能接收到自己说话的字幕,但收不到机器人的回复字幕,建议检查 LLM 相关的配置。
4. 如果能收到机器人回复的字幕,但听不到机器人的声音,建议检查 TTS 相关的配置。
服务类别 | 错误码 | 错误描述 |
ASR | 30100 | 请求超时 |
| 30102 | 内部错误 |
LLM | 30200 | 请求 LLM 超时 |
| 30201 | LLM 请求被频率限制 |
| 30202 | LLM 服务返回失败 |
TTS | 30300 | 请求 TTS 服务超时 |
| 30301 | TTS 请求被频率限制 |
| 30302 | TTS 服务返回失败 |
大模型 Timeout 报错
如果遇到 LLM Timeout 报错,如提示
llm error Timeout on reading data from socket ,一般是 LLM 请求超时了,可以将 LLMConfig 里的 Timeout 参数设置大点(默认为3秒)。此外,当 LLM 的首包耗时超过3秒时,较高的对话延迟会影响 AI 对话的体验,如果没有特殊需求,建议可以优化一下 LLM 的首包耗时,可参见 对话延迟优化。腾讯 TTS 报错
如果遇到腾讯 TTS 报错,例如以下报错:
TencentTTS chunk error {'Response': {'RequestId': 'xxxxxx', 'Error': {'Code': 'AuthorizationFailed', 'Message': "Please check http header 'Authorization' field or request parameter"}}}
可从以下几个方面排查:
1. 检查是否有开通应用的 TTS 服务。
2. 检查 APPID、SecretId、SecretKey 是否填写正确。
3. 检查是否有领取免费的 TTS 资源包。
4. 检查填写的音色 ID 是否包含在免费资源包内。
为什么用户回答单个文字时,不会去请求 LLM?
当用户回答“是”、“好”等单个文字时,如果不去请求 LLM,可以检查是否将 启动 AI 对话接口 里的
AgentConfig.FilterOneWord 参数设置为 false (默认为 true)。参数 | 类型 | 描述 |
FilterOneWord | Boolean | 是否过滤掉用户只说了一个字的句子,true 表示过滤,false 表示不过滤,默认值为 true 示例值:true |
TRTC 异常错误处理
1. UserSig 相关。UserSig 校验失败会导致进房失败,您可参见 UserSig 生成与校验 进行校验。
枚举 | 取值 | 描述 |
ERR_TRTC_INVALID_USER_SIG | -3320 | 进房参数 UserSig 不正确,请检查 TRTCParams.userSig 是否为空。 |
ERR_TRTC_USER_SIG_CHECK_FAILED | -100018 | UserSig 校验失败,请检查参数 TRTCParams.userSig 是否填写正确或已经过期。 |
2. 进退房相关。进房失败请先检查进房参数是否正确,且进退房接口必须成对调用,即便进房失败也需要调用退房接口。
枚举 | 取值 | 描述 |
ERR_TRTC_CONNECT_SERVER_TIMEOUT | -3308 | 请求进房超时,请检查是否断网或者是否开启 VPN,您也可以切换4G进行测试。 |
ERR_TRTC_INVALID_SDK_APPID | -3317 | 进房参数 sdkAppId 错误,请检查 TRTCParams.sdkAppId 是否为空。 |
ERR_TRTC_INVALID_ROOM_ID | -3318 | 进房参数 roomId 错误,请检查 TRTCParams.roomId 或 TRTCParams.strRoomId 是否为空,注意 roomId 和 strRoomId 不可混用。 |
ERR_TRTC_INVALID_USER_ID | -3319 | 进房参数 userId 不正确,请检查 TRTCParams.userId 是否为空。 |
ERR_TRTC_ENTER_ROOM_REFUSED | -3340 | 进房请求被拒绝,请检查是否连续调用 enterRoom 进入相同 ID 的房间。 |
3. 设备相关。可监听设备相关错误,在出现相关错误时 UI 提示用户。
枚举 | 取值 | 描述 |
ERR_MIC_START_FAIL | -1302 | 打开麦克风失败,例如在 Windows 或 Mac 设备,麦克风的配置程序(驱动程序)异常,禁用后重新启用设备,或者重启机器,或者更新配置程序。 |
ERR_MIC_NOT_AUTHORIZED | -1317 | 麦克风设备未授权,通常在移动设备出现,可能是权限被用户拒绝了。 |
ERR_MIC_OCCUPY | -1319 | 麦克风正在被占用中,例如移动设备正在通话时,打开麦克风会失败。 |