通用问题
调度器只作用于原生节点是什么意思?
原生节点是 TKE 基于云原生场景发布的增强型节点,其中包含了大量容器场景的特殊优化。调度器的功能依赖于原生节点独有的特性,因此只在原生节点上生效。即使选择了普通节点,调度器的参数配置 CRD 也无法生效。
调度器的参数配置 CRD 是什么?
除了可以通过控制台操作外,原生节点专用调度器的参数配置也支持使用 YAML 配置。每个配置文件都保存在名为 clusternoderesourcepolicies 的资源对象中,您可以直接创建或修改该类型的资源对象。
使用 CRD 有什么注意事项?
自定义设置节点放大系数和水位线非常灵活,可以选择一个节点或节点池、一批节点或节点池,甚至整个集群配置相同的节点规格放大系数和水位线。您可以创建多个配置文件并应用到不同的节点上。如果一个节点被多个配置文件声明,并且这些文件声明的参数不同,会导致异常。
集群中既有普通节点又有原生节点会有什么样的效果?
不会影响正常的调度行为。
集群中只有部分原生节点配置了调度参数会有什么样的效果?
如果某些原生节点配置了调度器参数,则这些原生节点将按照配置的调度参数进行调度。其他没有配置调度参数的原生节点和普通节点将按照正常的调度规则进行调度。
调度器里的 CPU 利用率是如何计算的?
1. 获取当前的 CPU 时间(user,nice,system,idle,iowait,irq,softirq,steal,guest,guest_nice)和上一次获取的 CPU 时间。
2. 计算每个 CPU 时间的总和(total = user + nice + system + idle + iowait + irq + softirq + steal + guest + guest_nice)。
3. 计算自上次检查以来 CPU 时间的总增量(delta_total = total - last_total)。
4. 计算自上次检查以来 CPU 空闲时间的增量(delta_idle = idle - last_idle)。
5. 计算 CPU 利用率(cpu_percent = 100.0 * (1.0 - delta_idle / delta_total))。
其中,last_total 和 last_idle 是上一次检查时的 CPU 时间和 CPU 空闲时间。
如何批量配置调度器参数?
每个配置文件保存在名为 clusternoderesourcepolicies 的资源对象里,您可以直接创建或修改该类型的资源对象。
如果两个调度器配置 CRD 作用于同一个原生节点会有什么后果?
CRD 和节点的关系类似于其他资源对象,例如 Deployment 和 Pod 之间、HPA 和 Pod 之间,都是通过 labelselector 来控制的。如果一个原生节点被两个 CRD 同时作用,那么这两个 CRD 会不断对同一个原生节点进行覆盖修改。
如果调度器 OOM 会有什么样的风险?
调度器 OOM 会触发 kubelet 的重启逻辑,导致本节点上的重启。在重启过程中,如果发生了调度或需要驱逐的行为,可能会短暂受到影响。重启完成后,调度器功能将正常工作。
驱逐线、调度线、运行时水位、低负载节点这些都是什么意思?
调度线:即调度时的水位线,对应 CRD 中的 targetLoadThreshold,Pod 在调度时参考的水位线。
驱逐线:即运行时的水位线,对应 CRD 中的 evictLoadThreshold,当节点的利用率达到该水位时,会触发驱逐动作。
低负载节点:在发生驱逐时,为了保证成功率,调度器要求默认至少有三个节点满足低负载利用率。判断低负载节点的标准是节点的利用率低于 targetLoadThreshold。
如果使用的是 Crane Scheduler 1.1.10版本,并且配置了驱逐停止水位,则至少需要三个原生节点的利用率低于驱逐停止水位才行。
驱逐停止水位线:在发生驱逐动作时,当节点的利用率达到一定水平后,停止驱逐。默认值是 targetLoadThreshold。
如果使用的是 Crane Scheduler 1.1.10版本,则为 evictTargetLoadThreshold。如果您没有设置该参数,则默认为 targetLoadThreshold。
节点放大系数
如何配置节点放大参数?
为什么节点放大参数有限制?
节点的 CPU 放大系数在控制台上的最大限制为3,内存放大系数的最大限制为2。这是为了避免设置过大的放大系数导致节点不稳定。较大的放大系数会使节点调度更多的 Pod,增加 Pod 之间的资源竞争,从而增加节点的不稳定性风险。
如何设置更大的放大系数?
您可以通过 CRD 进行配置。每个配置文件都保存在名为 clusternoderesourcepolicies 的资源对象中,您可以直接创建或修改该类型的资源对象。
调度时水位
配置了调度时水位线会有什么样的现象?
例如:某个原生节点的调度时水位配置成了CPU:30%,内存80%。
效果:当一个 Pod 需要调度时,如果这个原生节点的 CPU 利用率大于30%,或者内存利用率大于80%,则该原生节点不是调度的目标节点。
利用率的计算是什么样的?
5分钟平均 CPU 利用率:节点过去5分钟平均 CPU 利用率超过设定阈值,不会调度 Pod 到该节点上。
1小时最大 CPU 利用率:节点过去1小时最大 CPU 利用率超过设定阈值,不会调度 Pod 到该节点上。
5分钟平均内存利用率:节点过去5分钟平均内存利用率超过设定阈值,不会调度 Pod 到该节点上。
1小时最大内存利用率:节点过去1小时最大内存利用率超过设定阈值,不会调度 Pod 到该节点上。
以上一个问题为例,此时 CPU 两个利用率的阈值都是30%;内存的两个利用率的阈值都是80%。
调度器是仅作用在预选阶段吗?
不是,调度器既作用在预选阶段,又作用于优选阶段。预选阶段对原生节点进行过滤,优选阶段对过滤后的节点进行打分排序。
没有配置调度时水位,那预选节点的打分就是0了吗?
Kubernetes 默认调度器和原生节点专用调度器的关系?
它们之间是交集关系,原生节点专用调度器扩展了部分调度能力,但不会覆盖默认调度器。两者会一起进行预选和优选。
如何查看调度器调度的日志?
您可以查看 Deployment:crane-scheduler(kube-system) 的日志。
如何持久化日志信息?
为什么使用了原生节点调度器,还是存在集群节点负载不均衡的问题?
原生节点调度器通过调度时的水位和运行时的水位来帮助集群实现负载均衡。
调度时的水位,可以让 Pod 在调度时考虑节点的真实负载,高负载的不调度,只选择低负载节点,可以让节点的负载相较更均衡。
运行时的水位,可以让节点在高负载时,发生驱逐动作,使集群每个节点更均衡。
从逻辑上,这两个水位都是帮助您的集群变得相对更均衡,但是集群整体负载均衡是一个系统性功能,例如:
业务波动:调度时可能均衡,但运行一段时间后,业务本身流量会波动,有波峰波谷,部分节点利用率低;利用率高的节点也没有触发重调度的动作。
节点问题:节点发生了下线、驱逐、重启等状态,导致 Pod 被驱逐调度,节点的利用率也发生了变化。
运行时水位
配置了运行时水位线会有什么样的现象?
例如:某个原生节点的运行时水位配置成了CPU:50%,内存90%。
效果:当一个 Pod 需要调度时,如果这个原生节点的 CPU 利用率大于50%,或者内存利用率大于90%,则该原生节点会开始发生驱逐,会驱逐节点上的特定 Pod。
发生驱逐的要求有哪些?
节点利用率触达了运行时水位。
有 Pod 可以被驱逐:需要添加 annotation:
descheduler.alpha.kubernetes.io/evictable: 'true'。有空间可以容纳 Pod:沿用社区要求,至少有三个原生节点的利用率低于调度时水位。
如果是 Crane Scheudler 1.1.10版本,且配置了驱逐停止水位,则是至少有三个原生节点的利用率低于驱逐停止时水位才行。
为什么触达了运行时水位,结果并没有 Pod 被驱逐?
可能原因有多种,除了上述问题外,如果您不是通过腾讯云可观测平台查看的监控,可能与监控系统的差异有关。
为什么驱逐出现延迟?
驱逐的延迟可能存在于多个步骤中:
目前驱逐沿用社区的逻辑,最小监控取值点为最近5分钟的利用率均值,每5分钟更新一次。
调度器本身会有检查间隔时间和执行动作时间。
驱逐的 Annotation 打在 Workload 还是 Pod 上面?
都可以。建议打在 Workload 的 metadata 上面,这样的动作不会触发 Pod 的重建,该 Workload 下的所有 Pod 都可以被驱逐。如果打在 Pod 上面或者 Workload 的 Pod 的模板上面,会触发 Pod 的重建。建议在测试环境中进行测试。
如何查看调度器驱逐的日志?
您可以查看 Deployment:crane-descheduler(kube-system) 的日志,例如一个驱逐的日志信息。如下图所示:
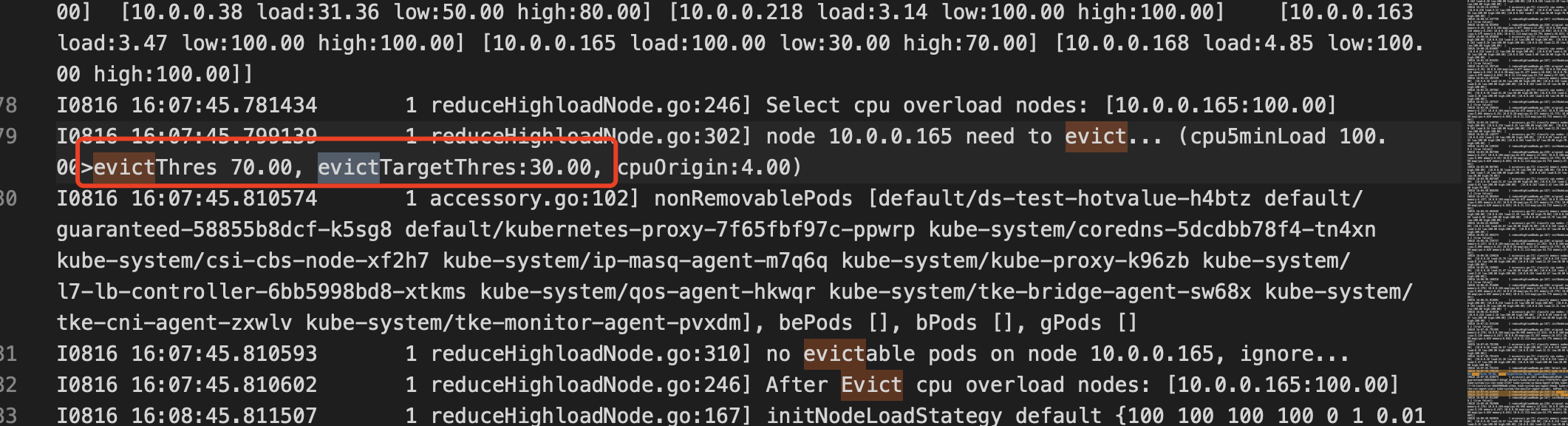
PDB 和驱逐之间的关系是什么?
PDB 的优先级高于驱逐,PDB 可以确保最小 Pod 可用性,Pod 可以被调度到不同的节点上。每个节点进行驱逐时,都会考虑到工作负载的最小可用数量,可以中断驱逐操作,以防止对业务造成影响。
为什么驱逐后,监控指标会大幅下降?
这里有两个原因:
1. 运行中的 Pod 由于资源共享,导致驱逐后的监控数值比实际情况要大。
2. 驱逐过程中的 Pod 利用率计算标准是基于驱逐时刻的,因此当节点的实际负载已经降低时,监控中会显示出多次驱逐的情况。
Pod 驱逐的优先级顺序是怎样的?
优先级:Priority > podQOS > podload 负载
podload 负载是从 metricClient 中读取 Pod 的 CPU/Memory 资源使用量,使用量越高,优先级越高。
Pod 的驱逐动作是怎样的?
当满足驱逐条件时,如果 podLoad/node.Status.Capacity[res]*100 > 驱逐线,则不会驱逐该 Pod,否则开始驱逐操作。
说明:
Pod 占节点的资源用量,如果这个 Pod 的占用量直接超过了驱逐线,这个 Pod 就不会被驱逐。
如果驱逐成功,会从 nodeload 中减去该 Pod 的所有资源占用率,并在最近5分钟的资源负载中减去该 Pod 的资源占用率。
判断最近5分钟的资源负载是否已经小于等于目标值,如果是,则跳过该节点上其他 Pod 的驱逐操作。
如果该节点上的 Pod 已经驱逐完成,在节点上更新驱逐时间:
node.Annot[node.kubernetes.io/last-evicted-time] = time.Now()



