Xpark 是腾讯自研基于 Python 生态的分布式多模态数据计算引擎,基于 Ray Data 实现,并内置丰富的多模数据处理算子,支持分析处理文本、图片、音频、视频等多模态数据,使开发者可以高效的实现多模态数据预处理和分析。
说明:
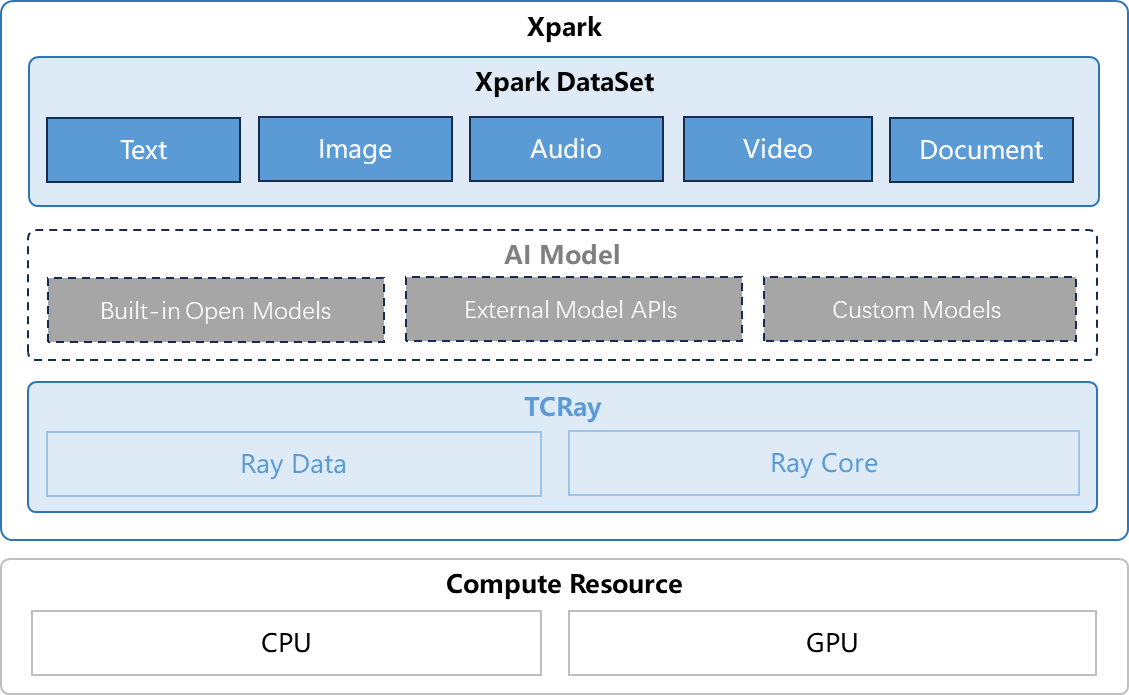
Xpark 原理
Xpark DataSet 基于 Ray 的 Data 模块扩展,内置文本、图片、音频、视频等多模态数据处理算子以及常见数据处理 Pipeline。DataSet 中部分算子基于 AI Model 实现,支持调用兼容 OpenAI 协议的内置开源模型、外部模型 API 或用户自定义模型处理数据。
TCRay 作为 Xpark 的核心依赖组件,提供多模态数据处理基础算子,同时也是 Xpark 作业分布式运行的资源调度基座。借助 TCRay 灵活的异构资源调度能力,Xpark 作业可以按需使用到 CPU 或 GPU 资源。
Xpark 优势
简单智能
更高开发效率:相比传统 Spark 和 Ray Data 需要多次跨生态或函数调用,Xpark 内置经典处理算子实现更简单的多模态数据处理,提升开发效率。
丰富多模态算子:内置40+文本、图片、音频、视频等处理算子,支持用户上传自定义算子,不同模态数据支持联合处理。
智能算子:提供 AI Function 调用领域模型处理多模态数据转换(如多模态数据 Embedding、内容分类、内容理解、情感分析、内容生成等)。
高性能
原生分布式:基于 Ray Data 实现原生分布式多模态数据处理。
高性能文本去重:文本 Minhash 去重算子性能是 Data-Juicer(v1.4.3) 的8倍,独家分布式 Exact Substring 去重较开源版快50倍。
高可靠
完善的错误容忍基础策略:通过算子级重试、任务重分配、跳过策略以及血缘重建保证了单点故障以及在数据异常场景的可靠性。
任务级 Checkpoint 机制:相比于原生 Ray Data,通过轻量级快照、异步持久化、增量快照实现 Checkpoint 机制,有效避免 Ray 故障下的全量重执行,提升系统容错能力。
Xpark 应用场景
LLM 模型预训练数据准备
处理 TB 级规模的网页抓取、文档、代码等原始语料,通过清洗、去重、质量过滤和语言识别等步骤,构建高质量的预训练数据集。
Xpark 快速入门
准备工作
1. 账号和权限准备,已开通腾讯云账号并且开通弹性 MapReduce 购买管理权限。
2. 创建 EMR on TKE 机器学习集群,产品版本选择 EMR-TKE-AI-V1.2.0,在部署服务中需同步部署 TCRay 组件。
创建 TCRayCluster
当前支持通过表单方式和 YAML 两种方式创建和管理 RayCluster。若希望快速完成集群创建,推荐使用表单方式可视化完成配置。
1. 登录 EMR on TKE 控制台,在实例列表中选择已准备好的机器学习实例。
2. 进入实例详情页,选择 RayCluster 页面,点击表单创建 RayCluster,在弹出配置页面进行配置。
配置项 | 配置设置 |
基础配置 | 按需配置 RayCluster 名称、命令空间以及高可用策略。 |
个人镜像配置 | 开启自定义镜像 镜像包搜索 Xpark,选择 tcray-xpark/xpark,选择版本 0.3.0-ray2.53.0-py312-cu125 |
资源组配置 | 测试可使用默认值,实际业务场景按需配置。 |
资源组通用配置 | 配置需要访问存储服务。支持分析 CFS 和 COS 中的数据。示例为简单内置数据处理,无需配置关联存储服务。 |
高级设置 | 按需配置,当前示例配置默认值即可。 |
3. 完成上述配置并阅读并勾选相关服务协议后,点击确定提交任务。创建过程中可在右上角列表页查看进度。
运行 Xpark 作业
1. 登录 TCRayCluster 的 Header 节点:进入 EMR on TKE AI 集群的实例信息页,在基础配置中点击容器集群实例 ID 进入容器集群的详情页,切换至 POD 管理页,筛选 TCRayCluster 所在的命名空间,根据实例名称找到对应 RayCluster 的 Header 所在 POD,单击登录进入 Header 节点。
2. 创建 Xpark 测试脚本:在 OrcaTerm 中输入 vim xpark_quick_start.py 准备如下测试脚本,编写完成后保存脚本。
注意:
部分算子需要调用本地或远程 AI 模型,通用小模型可通过从 Hugging Face 下载到本地。
from xpark.dataset import from_itemsfrom xpark.dataset.expressions import col# Create a dataset from a list of dictionariesds = from_items([{"text": "Hello, world!"},{"text": "Xpark makes data processing easy."},{"text": "Multimodal AI at scale."},])# Add an uppercase column using the string namespaceds = ds.with_column("upper_text", col("text").str.upper())ds.show()
3. 运行 Xpark 脚本:在命令行中输入 python xpark_quick_start.py 运行脚本后查看处理结果。
{'text': 'Hello, world!', 'upper_text': 'HELLO, WORLD!'}{'text': 'Multimodal AI at scale.', 'upper_text': 'MULTIMODAL AI AT SCALE.'}{'text': 'Xpark makes data processing easy.', 'upper_text': 'XPARK MAKES DATA PROCESSING EASY.'}
Xpark 开发指南
配置 AI 模型
Xpark 提供的部分算子需要使用 AI 模型,使用相关算子之前建议提前将模型下载至本地缓存中。如有远程可用的模型推理服务,您也可以在 Xpark 集群与远程模型服务网络互通情况下使用远程模型。
从 Hugging Face 下载模型并缓存
1. 挂载 CFS 至 TCRayCluster 用于缓存模型:创建或修改 TCRayCluster 配置时,挂载 CFS 的路径为 /home/ray/.cache/xpark。
注意:
对应的路径权限需要 Ray 用户可以读写,如果文件夹所有者为 root,可以通过进入 Ray 所在容器中,通过执行如下命令修改目录权限。
sudo suchown -R 1000:1000 /home/ray/.cache/xpark
2. 执行脚本下载所需模型。
注意:
如果国内无法下载,可以配置 HF_HOME 环境变量后(export HF_ENDPOINT=https://hf-mirror.com),再执行 cache 脚本。
python /home/ray/anaconda3/lib/python3.12/site-packages/xpark/dataset/scripts/cache_model.py -g all
配置 Wedata Studio
Wedata Studio 提供一站式大数据和 AI 开发 IDE,支持 Notebook 文件、SQL 脚本,以及 Python、Shell 等类型文件的在线开发。完成 TCRay+Xpark 的集群创建后,可以在 Wedata Studio 里进行 Xpark 作业开发调试。Studio 的 kernel 配置中将 EMR 集群和 ray_cluster_name 配置为对应的 Xpark 集群。



