一、 Inference API 介绍
Elasticsearch 的 Inference API 是一组用于集成和使用机器学习模型(尤其是自然语言处理模型)的 RESTful 接口,旨在简化将外部或内置的 AI 模型和 ES 数据结合使用的流程。
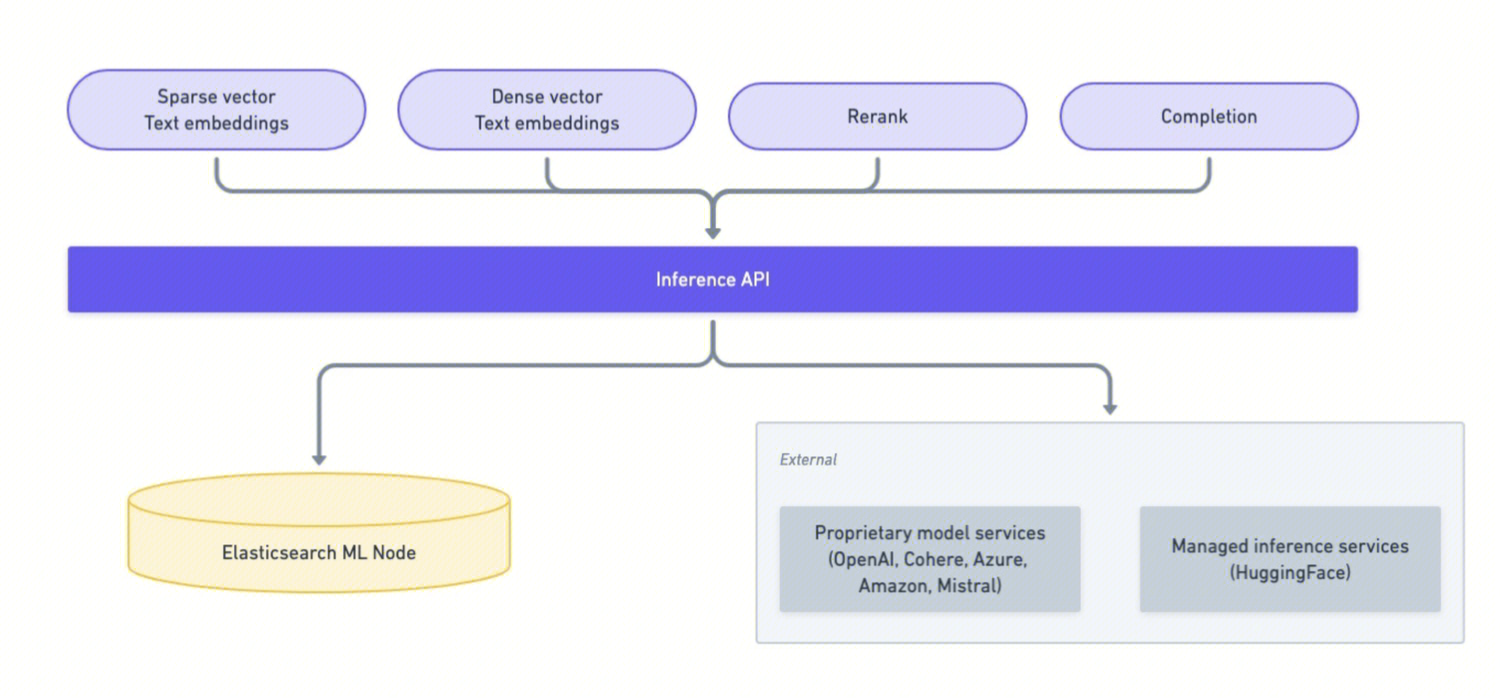
Inference API 可以理解为一个 ES 内部的统一模型网关,你可以通过一套标准化的 API,调用各种机器学习模型,核心功能:
创建模型推理服务:将模型注册为一个可直接调用的服务;
执行推理:对输入文本进行处理,如生成向量(Embedding)、Rerank、回答问题、生成摘要等;
管理模型生命周期:包括更新、获取和删除推理配置;
集成第三方 AI 服务:支持在 API 中直接调用第三方 AI 服务,如腾讯云 ES 原子服务、OpenAI、Anthropic、Hugging Face等。
主要 API 列表:
API | 说明 |
PUT _inference/{task_type}/{inference_id} | 创建/注册模型推理服务 |
POST _inference/{task_type}/{inference_id} | 执行推理(同步) |
POST _inference/{task_type}/{inference_id}/_stream | 流式推理(适用于 LLM) |
GET _inference/{task_type}/{inference_id} | 获取推理服务 Endpoint 配置 |
DELETE _inference/{task_type}/{inference_id} | 删除推理服务 Endpoint |
POST _inference/{task_type}/{inference_id}/_chat_completion | 调用内容生成服务模型(如对接 hunyuan) |
二、调用指引
1. 前置条件
在腾讯云控制台创建集群,选择 AI 搜索增强版,内核版本为 9.1.3
2. 调用 Embedding 服务
2.1 创建 text_embedding 模型推理服务
以 bge_base_zh-v1.5 模型和 Qwen3-Embedding-0.6B 模型举例。
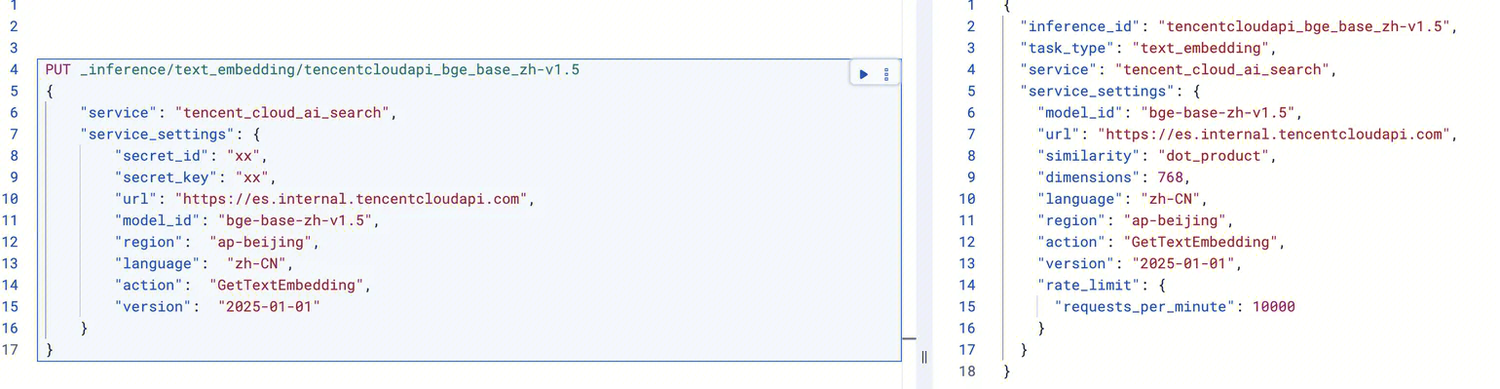
PUT _inference/text_embedding/tencentcloudapi_bge_base_zh-v1.5{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://es.internal.tencentcloudapi.com","model_id": "bge-base-zh-v1.5","region": "ap-beijing","language": "zh-CN","action": "GetTextEmbedding","version": "2025-01-01"}}
参数说明:
参数名称 | 参数说明 |
<task_type> | text_embedding,模型将执行推理任务的类型 |
<inference_id> | 自定义的 inference endpoint 名称,如:tencentcloudapi_bge_base_zh-v1.5 |
secret_id/secret_key | 调用原子服务的 API 密钥信息,需前往云 API 创建 |
url | 调用原子服务的地址,url 需要以http/https 开头,默认不用修改 |
model_id | Embedding 模型 id,填写具体模型名称即可 |
region | 填写 ap-beijing,当前原子服务暂部署在北京地域 |
action | 原子服务云 API 名称 |
version | 原子服务云 API 版本 |
language | 使用的语言 |
在 Kibana 上运行,响应如下:
同样,添加 Qwen3-Embedding-0.6B 模型:
PUT _inference/text_embedding/qwen3-embedding-0.6b{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://es.internal.tencentcloudapi.com","model_id": "Qwen3-Embedding-0.6B","region": "ap-beijing","language": "zh-CN","action": "GetTextEmbedding","version": "2025-01-01"}}
注意:inference_id 值必须要是小写,否则会报错,报错详情如下:
{"error": {"root_cause": [{"type": "action_request_validation_exception","reason": "Validation Failed: 1: Invalid inference_id; 'Qwen3-Embedding-0.6B' can contain lowercase alphanumeric (a-z and 0-9), hyphens or underscores; must start and end with alphanumeric;"}],"type": "action_request_validation_exception","reason": "Validation Failed: 1: Invalid inference_id; 'Qwen3-Embedding-0.6B' can contain lowercase alphanumeric (a-z and 0-9), hyphens or underscores; must start and end with alphanumeric;"},"status": 400}
2.2 查看模型推理服务
执行如下代码,可以查看当前集群下的所有推理服务端点。
GET _inference/text_embedding/_all
响应如下:
{"endpoints": [{"inference_id": "qwen3-embedding-0.6b","task_type": "text_embedding","service": "tencent_cloud_ai_search","service_settings": {"model_id": "Qwen3-Embedding-0.6B","url": "https://es.internal.tencentcloudapi.com","similarity": "dot_product","dimensions": 1024,"language": "zh-CN","region": "ap-beijing","action": "GetTextEmbedding","version": "2025-01-01","rate_limit": {"requests_per_minute": 10000}}},{"inference_id": "tencentcloudapi_bge_base_zh-v1.5","task_type": "text_embedding","service": "tencent_cloud_ai_search","service_settings": {"model_id": "bge-base-zh-v1.5","url": "https://es.internal.tencentcloudapi.com","similarity": "dot_product","dimensions": 768,"language": "zh-CN","region": "ap-beijing","action": "GetTextEmbedding","version": "2025-01-01","rate_limit": {"requests_per_minute": 10000}}}]}
2.3 调用 Embedding 服务推理
使用 bge 模型执行 Embedding:
POST _inference/text_embedding/tencentcloudapi_bge_base_zh-v1.5{"input": ["腾讯云ES在混合检索场景业界第一"]}
2.4 通过 Ingest Pipeline 批量向量化后写入
Ingest Pipeline 是 ES 从 5.x 版本开始引入的一个非常重要的数据预处理功能,它允许在数据写入索引之前,对文档进行批量转换、加工、过滤,从而实现数据清洗、标准化、丰富化等操作。
PUT _ingest/pipeline/tencentcloudapi_bge_base_zh-v1.5_embeddings{"processors": [{"inference": {"model_id": "tencentcloudapi_bge_base_zh-v1.5","input_output": {"input_field": "message","output_field": "message_embedding"}}}]}
然后通过在 Bulk API 中指定上面创建的 Ingest Pipeline,可以实现文本到向量的转换和索引存储。
POST my_vector_index/_bulk?pipeline=tencentcloudapi_bge_base_zh-v1.5_embeddings{"index":{}}{"message": "腾讯云Elasticsearch Servie(ES)基于开源引擎打造,包含Elasticsearch、Kibana 及常用插件,集成了安全、监控告警、SQL、机器学习等高级特性(X-Pack)。使用腾讯云 ES,您可以快速部署、轻松管理、按需扩展您的集群,简化复杂运维操作,快速构建日志分析、异常监控、 网站搜索、企业搜索、BI 分析等各类业务。" }
响应如下:
{"errors": false,"took": 400,"ingest_took": 0,"items": [{"index": {"_index": "my_vector_index","_id": "v2bYh5sBFFtqFpK7c7SF","_version": 1,"result": "created","_shards": {"total": 3,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1,"status": 201}}]}
执行 search 查询来验证是否写入成功
GET my_vector_index/_search
响应如下,可以看到在 my_vector_index/_search 中返回的数据中,自动包含了 message 的原始数据和 message_embedding 向量数据,同时包含了 model_id 对应的模型 id 名称。
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "my_vector_index","_id": "v2bYh5sBFFtqFpK7c7SF","_score": 1,"_source": {"message_embedding": [0.0022983653470873833,0.026788894087076187,# 向量数据省略],"model_id": "tencentcloudapi_bge_base_zh-v1.5","message": "腾讯云Elasticsearch Servie(ES)基于开源引擎打造,包含Elasticsearch、Kibana 及常用插件,集成了安全、监控告警、SQL、机器学习等高级特性(X-Pack)。使用腾讯云 ES,您可以快速部署、轻松管理、按需扩展您的集群,简化复杂运维操作,快速构建日志分析、异常监控、 网站搜索、企业搜索、BI 分析等各类业务。"}}]}}
2.5 执行向量搜索
通过 Search API 执行向量搜索,在 Search API 中指定 knn 查询模式:
GET my_vector_index/_search{"knn": {"field": "message_embedding","query_vector_builder": {"text_embedding": {"model_id": "tencentcloudapi_bge_base_zh-v1.5","model_text": "腾讯云Elasticsearch Servie(ES)基于开源引擎"}},"k": 10,"num_candidates": 100}}
参数说明:
参数名称 | 参数说明 |
knn | 开启 k-Nearest Neighbors(k-NN)检索模式,适用于语义检索、向量检索场景 |
field | 指定要搜索的向量字段名称 |
query_vector_builder | 动态生成查询向量,而不是手动提供一个向量组,该参数的意思是在该查询请求中通过 model_id 动态对文本进行 embedding |
text_embedding | query_vector_builder 的一种内置实现,专门用于文本转向量 |
model_id | 指定使用哪个模型将文本转换为向量,这里需要和写入时指定的模型保持一致 |
model_text | 提供需要生成向量的原始文本,一般为查询语句 |
k | 指定返回最相似的 k 条文档记录 |
num_candidates | 在检索过程中,ES 会先从索引的各个分片中选出 num_candidates 条相似的候选文档,再从中精选出 k 条最相关的文档返回 |
因此,执行该 API 背后的流程为:
输入文本 ->模型向量化 -> 向量检索 -> 候选文档筛选 -> topk 返回。3.调用 Rerank 服务
Rerank 服务是和 Embedding 类似的。
3.1 创建 Rerank 模型服务
PUT _inference/rerank/tencentcloudapi_bge-reranker-large"{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxxx","secret_key": "xxxx","url": "https://es.internal.tencentcloudapi.com","model_id": "bge-reranker-large","region": "ap-beijing","language": "zh-CN","action": "RunRerank","version": "2025-01-01"},"task_settings": {"top_n": 10,"return_documents": true}}
3.2 调用 Rerank 服务排序
POST _inference/rerank/tencentcloudapi_bge-reranker-large"{"query": "长城","input": ["美国","中国","英国"]}
4.调用 LLM 生成服务
4.1 创建内容生成模型服务
因为大模型支持流式输出,这里的域名在原基础上加了 AI,建议填写:
es.ai.tencentcloudapi.com。这里选择的 LLM 是 hunyuan-large,模型服务可选,同时支持 DeepSeek 系列。
PUT _inference/completion/hunyuan-large{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://es.ai.internal.tencentcloudapi.com","model_id": "hunyuan-large","region": "ap-beijing","language": "zh-CN","action": "ChatCompletions","version": "2025-01-01"}}
4.2 执行对话
使用非流式输出,更适合离线操作。
POST _inference/completion/hunyuan-large?timeout=300s{"input": "介绍下腾讯云ES产品"}
使用流式输出,更适合在线对话。
POST _inference/completion/hunyuan-large/_stream{"input": "介绍下腾讯云ES在混合检索场景中的优势"}
三、小结
本文介绍了腾讯云 ES Inference API 的基本原理和用法,以及详细分享了如何通过 ES Inference API 来与腾讯云 ES 原子服务进行交互,从而完成从文本 Embedding 后写入 ES,到向量搜索,以及 LLM 交互的完整过程。ES 提供的原子服务都可以通过上面类似方法在 Inference API 中进行无缝集成,由此我们也看到 ES 在 AI 搜索场景中的强大之处。 如果您也有 AI Search 相关需求,欢迎与我们联系,我们可以提供完备的技术支持。



